

如何使Linux网络协议栈中RFS功能优化 MPSoC APU 的并行处理能力
描述
本文介绍如何使能 Linux 网络协议栈中的 RFS(receive flow steering)功能以优化 MPSoC APU 的并行处理能力,解决丢包问题。
问题描述:
在测试 ZCU102 PL 10G Ethernet with MCDMA 设计的性能时,遇到 UDP 接收丢包率很高的情况,测试使用的工具是 iperf3。
测试过程:
Board side:在 core1~3 上各开一个 iperf3 服务端用于收包,命令如下:

Server side:使用与 zcu102 用光纤相连的服务器发送 UDP 帧,命令如下:

双方的网卡都工作在 MTU1500 模式下,故数据段长度设为 1472B,总带宽暂设为 2400M。
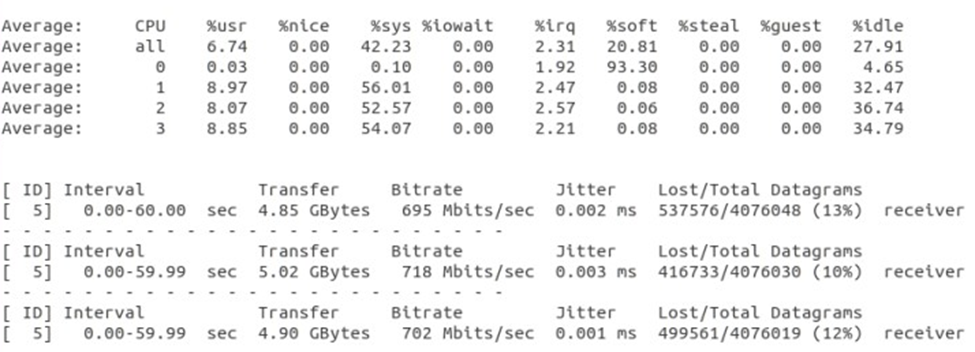
测试结果如上图所示,丢包率超过了百分之十,故实际传输速度也达不到设定的带宽,使用 mpstat 命令观察 CPU 使用状况,发现接收工程中 CPU0 的软中断占用达到93.3%。
解决方案:
使用 RFS 接收流导向,RFS 是 Linux 网络协议栈提供的一项辅助性功能,RFS 的目标是通过将数据包在内核中的处理引导到使用该数据包的应用程序线程对应的 CPU 来提高数据缓存的命中率,详情可参考 Linux 内核文档https://www.kernel.org/doc/html/latest/networking/scaling.html
在本文的测试中 Board side 上运行了三个 iperf 服务端在三个 CPU 上,RFS 可以将发给某个服务端的数据包的部分处理工作交给这个服务端对应的 CPU 执行,以此平衡工作负载。
按照文档中的说明,rps_sock_flow_entries 设置为32768,本文使用的设计中 MCDMA 共有16个接收通道,所以 rps_flow_cnt 为32768/16=2048,另外共开启了三个 iperf 服务端,所以暂时只设置 rx-0~rx-2,综上,执行命令如下:

重新测试后结果如上图所示,丢包率大大降低,实际传输速度也达到了设定值,使用 mpstat 命令监控传输期间的 CPU 状况,发现 CPU0 的软中断占用时间降低,而 CPU1~3 的软中断占用升高,可以看出实现了负载的分配,但是从总体来看,四个 CPU 的总负载升高,说明 RFS 还是有一定的额外工作开销。
总结:
使用 RFS 可以一定程度上解决 MPSoC 10G 以太网应用(使用 MCDMA 时)中的 UDP 接收丢包问题,但是会产生额外的 CPU 开销,如果丢包率在接受范围内可以选择不开启。
责任编辑:彭菁
-
结合pppoe协议分析Linux网络栈的实现方式2020-10-26 3580
-
基于精简版协议栈代码开放的ZigBee网络节点研究介绍2019-06-14 2114
-
网络协议栈-lwip2.1.2移植2021-08-16 2444
-
使能Linux内核中的SCSI协议2021-12-16 421
-
介绍RL-TCPnet网络协议栈2022-03-02 1870
-
基于网络处理器的VxWorks高层协议栈开发2009-03-29 651
-
LINUX网络协议栈实现分析-SKBUFF的实现2011-04-07 714
-
Linux平台双协议栈主机网络管控系统设计与实现2017-01-07 947
-
关于MPSoC的中断处理介绍2021-05-07 5085
-
Linux网络技术中最核心的部分--TCP/IP协议栈2021-06-29 3194
-
如何解决MPSoC万兆以太网应用中UDP接收丢包问题2023-06-14 2261
-
tcpip协议栈是什么?tcpip协议栈有哪些协议?tcpip协议栈中报文封装和解封装过程2023-08-01 11316
-
Linux网络技术栈的相关知识2023-08-24 1482
-
CAN协议栈与LIN协议栈介绍2023-10-27 4863
-
Linux网络协议栈的实现2024-09-10 2566
全部0条评论

快来发表一下你的评论吧 !
