

Linux内核实现内存管理的基本概念
嵌入式技术
描述
摘要:
本文概述Linux内核实现内存管理的基本概念,在了解基本概念后,逐步展开介绍实现内存管理的相关技术,后面会分多篇进行介绍。
0、引言
Linux内核主要由进程管理、内存管理、文件系统和设备驱动四个子系统组成。内存管理是内核最复杂同时也是最重要的一部分。
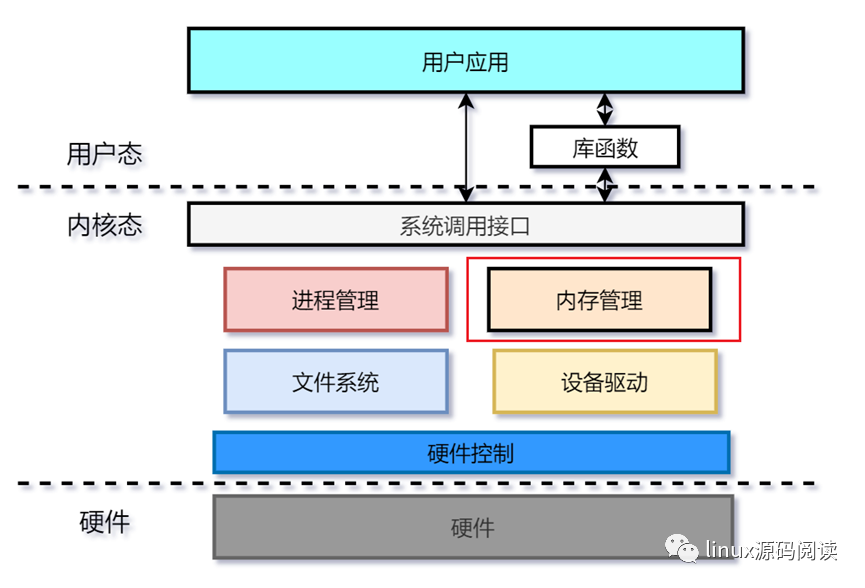
1、物理地址的分布
ARM体系结构的物理地址映射是预定义的,并且规定好了哪个位置应该使用哪条总线。芯片制造商在集成ARM core的时候,只需按照预定义的物理地址映射分配内存、外设等即可。
ARM体系结构的物理地址都是从0地址开始的线性组合,下面分别简介ARM cortex-M3/M4、ARMv7和ARMv8系列芯片的物理地址映射。
1.1 ARM cortex-M3/M4的物理地址分布
ARM cortex-M3/M4的地址分布如下,由于该系列的core没有MMU,所以其使用内存都是一一对应的,虽然不是我们介绍的重点,可以了解下。其理论地址空间范围是0~4GB。

手册中详细介绍了每memory region的用途。

1.2 Cortex-A(ARMv7)系列芯片的地址映射
ARMv7作为32位的微处理器,下图展示的是使能MMU后物理地址和虚拟地址之间的概览,其理论地址空间范围是0~4GB。

1.3 Cortex-A(ARMv8)系列芯片的地址映射
ARMv8作为64位的微处理器,使能MMU后物理地址和虚拟地址之间的概览如下,其理论地址空间范围是0~4*(2^32)GB(0xFFFFFFFF_FFFFFFFF),这个地址空间范围异常之大,是用不完的,所以中间有大量的Reserved区域。

2、Linux 虚拟地址空间分布
Linux内核一般将处理的虚拟地址空间划分成两个部分:用户态和内核态。
在32位系统上,最大寻址空间是4GB,所以最大虚拟地址空间也是4GB,其中1GB分给内核,3GB分为用户。
在64位系统上,最大寻址空间是0xFFFFFFFFFFFFFFFF,这个地址非常大,对于当前的技术,用完几乎是不可能的,针对不同的芯片架构有不同的分法,比如x86 64位系统给内核和用户各分了128TB的地址空间,ARM 64位系统给内核和用户各分了256TB的地址空间,由于我们主要研究ARM体系结构,后续讲到内存和芯片架构相关的统一默认为ARM系统结构。

2.1 内核态地址空间
简单地从ARM 32位系统分析。

2.2 用户态地址空间
每个用户进程都有自己独立的虚拟地址空间,仿佛该进程独占了整个内存。

Linux C/C++编译之后的可执行文件常使用ELF(全称:Executableand Linking Format)文件格式,可执行文件是按照段(segment)组织的。我们就以进程的可执行文件为ELF下的内存布局。
(1)text段:存放程序代码
(2)data段:存放初始化后的全局变量、局部静态变量
(3)bss段:存放未初始化的全局变量、局部静态变量
(4)堆:存放动态分配的内存,比如melloc函数申请的内存
(5)内存映射区(MemoryMapping Segment):存放mmap函数映射内容和动态链接库等内容
(6)栈:存放函数运行时的参数、局部变量等
(7)内核空间:每个用户进程都共享同一份内核空间,用户进程不能直接访问内核空间,必须使用系统调用来保证安全性。
3、虚拟地址和物理地址转换MMU
在进程执行中,CPU不能直接操作物理地址,必须要经过MMU转换后才能访问真正的物理地址。
Memory Management Unit(MMU)最主要的功能是管理任务作为独立的程序,每个程序具有私有的虚拟内存空间。虚拟内存系统的关键特性是地址重映射和实现虚拟地址与物理地址之间的转换。
3.1 ARM core、MMU与内存之间的关系

在MMU使能前,地址转换表必须写入内存,将地址转换表指针写入TTBR寄存器,然后通过ARM 的CP15协处理器使能打开MMU,具体操作代码如下:

使能MMU后的操作系统,ARM core不能直接访问内存,必须经过MMU进行地址转换。
上图可知,MMU主要包含两个部分:TLBs和Table Walk Unit。
TLB(Translation Lookaside Buffer)用于缓存最近执行的转换页表。当ARM core访问每一个内存时,MMU首先检查是否缓存在TLB,如果查询的到,则地址转换非常迅速。如果没有在TLB里查询到,产生了一个TLB miss,同时需求Table Walk Unit介入,去系统的Cache或内存中取新的页表,并将取回的页表缓存进TLB待被使用。

3.2 MMU的地址映射
ARM Cortex-A(armV7)支持两级映射,分为:
一级映射:16MB or 1MB sections(分段)
二级映射:64KB or 4KB page sizes(分页)
3.3 一级映射为1MB sections
一级映射表将4GB的地址空间(32bit-core)分成4096个相同大小的secions,每一个section描述1MB的虚拟内存空间。
(1)一级页表基地址为Translation Table Base Address,写入TTBR寄存器中。
(2)由于一级映射为1MB,所以一共有4096个页表项。虚拟地址从Translation Table Base Address,找到对应的页表项。
(3)一级页表Section Base Address Descriptor寄存器的[31 : 20]bits + Virtual Address的[19 : 0]bits,便可得到物理地址。


3.4 二级映射为4KB page size
二级映射表具有256个4字节的entries,需要占用1KB,同时必须是1KB对齐。
(1)一级页表基地址为Translation Table Base Address,写入TTBR寄存器中。
(2)由于一级映射为1MB,所以一共有4096个页表项。虚拟地址从Translation Table Base Address,找到对应的页表项。一级页表Section Base Address Descriptor寄存器的[31 : 20]bits 。
(3)一级页表Section Base Address Descriptor寄存器的[1 : 0]bits表示是否开启二级页表,此处为01b,表示打开了二级页表。
(4)虚拟地址的[19 : 12]bits寻找二级页表的页表项。
(5)最后根据二级页表项的[31 : 12]bits + Virtual Address的[11 : 0]bits,便可得到物理地址。
4、进程内存空间管理
进程该如何管理内存呢?我们分别从用户进程和内核进程两个角度去分析。

4.1 用户空间内存管理
用户空间使用malloc()申请内存,使用free()释放内存,malloc()和free()函数是Glibc库内的内存分配器ptmalloc提供的接口函数。
ptmalloc通过Linux的系统调用brk或mmap向内核申请内存,为了保持高效的分配,内核中申请内存是以页为单位,而不是以字节为单位,然后返回给给用户空间的分配器,分配器通过某种算法管理这块内存,来满足用户空间的内存分配要求;当用户free()释放内存时,并不是立即返回给操作系统,而是分配器管理这块要被释放的内存。也就是说,Glibc库内的内存分配器ptmalloc既要管理分配的内存,也要管理释放的内存。
上述ptmalloc是Glibc提供的内存分配器,Google也提供了tcmalloc(全称: Thread-caching malloc)内存分配器,FreeBSD提供了jemalloc内存分配器。
4.2 内核空间内存管理
虚拟内存管理负责从进程的虚拟地址空间分配虚拟页,内核函数sys_brk用来扩大或缩小进程的堆,sys_mmap用来在内存映射区域分配虚拟页,sys_munmap用来释放虚拟页。

内核使用延时分配内存的策略,进程第一次访问不存在的虚拟页时,会触发页错误异常,此时,页错误异常处理程序会从页分配器中申请物理页,在进程的页表中把虚拟页和物理页进行映射。
伙伴系统(Buddy System)是以页为单位管理和分配内存,提供的内存的接口是vmalloc()和vfree()。当以字节为单位分配内存时,伙伴系统内存利用率极低,而且伙伴系统内存分配效率低,分配路径比较长,遇到内存不足时,还会进行内存压缩或回收,同时,由于伙伴系统至少分配一个页框,访问内存很容易出现cache miss。
所以,Linux提供了分配小内存的SLAB分配器可以解决上述问题,提供的内存的接口是kmalloc()和kfree()。
另外,还有SLUB分配器和SLOB分配器,SLOB分配器可以简单理解为SLAB的缩小版,专门用于内存较少的嵌入式设备,SLUB分配器是SLAB的增强版。
5、本小节完
-
Linux应用编程的基本概念2024-10-24 1508
-
linux驱动程序如何加载进内核2024-08-30 2100
-
Linux内核内存管理架构解析2024-01-04 2206
-
Linux 内存管理总结2023-11-10 1568
-
Linux内核的内存管理详解2023-08-31 1504
-
关于Linux内存管理的详细介绍2023-03-06 1540
-
Linux的内存管理是什么,Linux的内存管理详解2022-05-11 7600
-
内存的基本概念以及操作系统的内存管理算法2021-08-14 5014
-
Linux内核架构--基本概念2020-05-20 1250
-
Linux内核设计与实现,先从哪些书学?2019-07-08 1818
-
linux内存管理机制浅析2011-12-19 1065
-
嵌入式Linux内核实时性研究及改进2009-07-30 586
-
Linux的内核教程2009-04-10 584
全部0条评论

快来发表一下你的评论吧 !
