

ROS平台下三种常用的自主探索算法原理
机器人
描述
1 前言
探索是指当机器人处于一个完全未知或部分已知环境中,通过一定的方法,在合理的时间内,尽可能多的获得周围环境的完整信息和自身的精确定位,以便于实现机器人在该环境中的导航,并实现后续工作任务。探索是移动机器人实现自主的关键功能,是移动机器人的一项重要任务,也是一个重要的研究领域。在许多潜在的应用中,建筑物、洞穴、隧道和矿山内的搜索操作有时是极其危险的活动。使用自主机器人在复杂环境中执行这些任务,降低了人类执行这些任务的风险。
本文主要讲解ROS平台下三种常用的自主探索算法原理。
2 frontier_exploration
frontier_exploration是基于边界的自主探索算法,边界定义为已知空间和未知空间之间的区域(Frontiers are regions on the boundary between open space and unexplored space),在原文献[1]中,作者通过BFS(深度优先搜索)算法从机器人当前位置搜索边界。
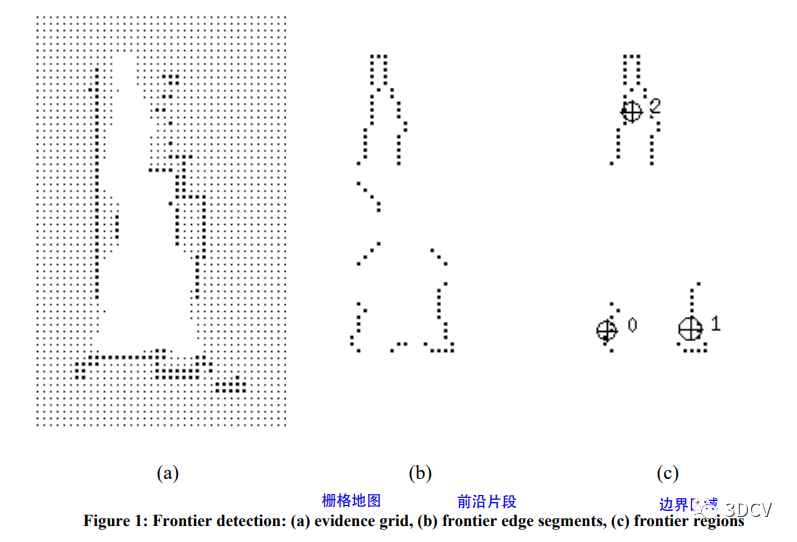
图a是在栅格地图中检测到了边界,图b是提取出来的属于边界的栅格点,然后使用一种“滤波”方法,滤除一些过小的边界(因为这些边界往往不需要特意去探索,机器人在行进过程中会构建出这里的地图,或者它小到不影响导航和后续功能),一般这个阈值可以取机器人的自身尺寸(原文中是这样的),就得到了图c中的边界区域。
这一系列边界区域,需要通过某种方法选择最合适的一个作为首先要前往的一个边界区域,在frontier_exploration算法中仅选择距离机器人当前位置(欧氏距离)最近的一个作为首先要前往的目标。
在文献[2]中提出了选择这些目标点的方法,根据作者的结论,在单机器人探索中,Nearest Frontier Approach(选择最近点)和Behaviour-Based Coordinated Approach(基于行为,融合了距离最近、避开障碍物、避开其他机器人三个惩罚项)两个方法使用的时间相近都是最短,其中Nearest Frontier Approach用时更短。
在地图质量方面,使用Hybrid Integrated Coordinated Approach(该方法设计比较复杂,融合了SLAM算法,提高了定位精度,会在系统中评估并存储精度较高的上一次位姿,当机器人定位精度下降时,会回溯上一次精度较高的位姿,导致耗时严重)它的耗时严重超过其他方法,虽然总的来说,减少探索时间的目标和良好的地图质量是相互冲突的,但我认为综合来看这种方法是不实用的,而地图精度仅次于Hybrid Integrated Coordinated Approach的算法是Nearest Frontier Approach和 Cost-Utility Approach,分为成本函数(Cost)和效用函数(Utility),采用加权的思想,作者给出的表达式如下:
U(a)表示当前往这个边界点a时,能扩大多少未知区域,以a为圆心,以一定长度Rs为半径(一般设置为传感器探测半径)的圆覆盖的未知栅格。
C(a) 表示当前位置到边界点的距离。
目前来看选择距离最近的方法虽然很呆很简单,但确实好用。另外,一个边界区域由很多栅格点组成,这时就需要通过一些算法选择目标边界点,作者在源代码中列举了三种常用方法:closest(BFS第一个检测到的点)、middle(中点)、centroid(质心)。-frontier_search.cpp的buildNewFrontier()函数中
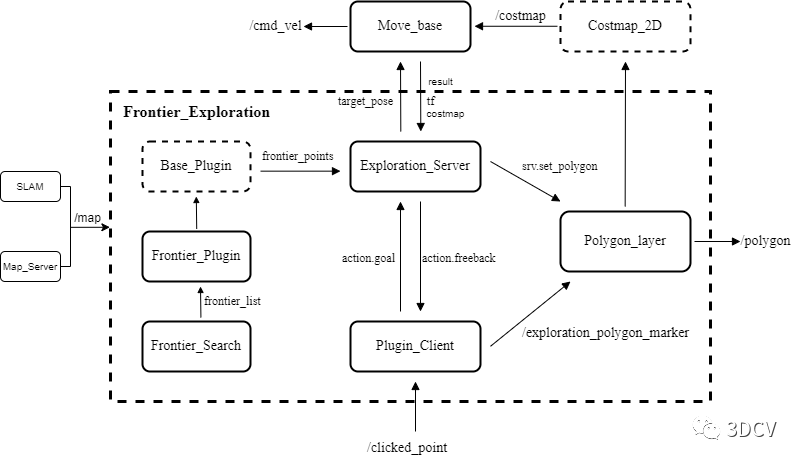
另外,可应采用插件的形式管理自主探索的算法,在源代码中提供了两个example插件,通过Base_Plugin接口类将自主探索算法集成到Exploration_Server中,便于修改,算法流程图如下所示。
3 explorate_lite
explorate_lite的代码是基于frontier_exploration16.04版本写的,但是经过作者几次更新代码有了很大的改进,改进点如下:
(1)它添加了一个frontierCost函数用来判断计算边界区域的代价,对 到边界的距离 + 边界大小 (+前沿方向分量) 几个项加权后,排序,选择代价最小的边界的质心作为目标点。
(2)在frontier_exploration中对于边界点Frontier的定义放在了Frontier.msg消息里面,而它定义为结构体形式,其中也包含了更多信息。
(3)它添加了tf校验机制,确保了 map_frame-robot_base_frame 的通畅
(4)添加了rosconsole记录器记录Debug信息
(5)添加了更多接口方便通过launch文件对这些参数进行修改
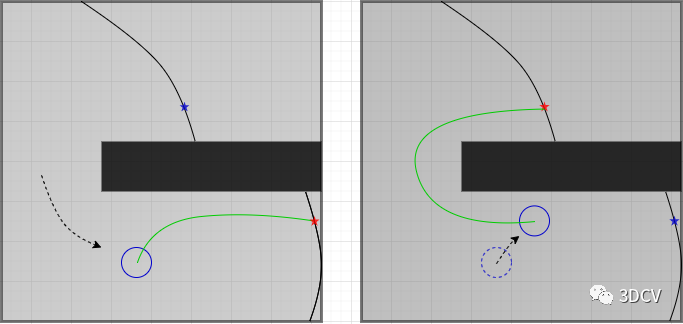
(6)这个修改的优劣有待讨论:explorate_lite在发布目标边界点时,使用的是定时发布,如下图,当机器人选择了一个当前的“最近点”时,行进过程中遇到更近的会不会换一个目标点,这样会增加路径重复率,也会造成机器人的频繁起停。比如下图所示,机器人运行至左图情况时选择了红色五角星为目标点,但运行过程中发现左图中蓝色五角星更优,有可能会出现右图所示更新选择的情况,造成路径重复和机器人的频繁起停。
(7)设置了容忍时间,超时会把这个点加到黑名单中,可以类似仿照限定程序总运行时间
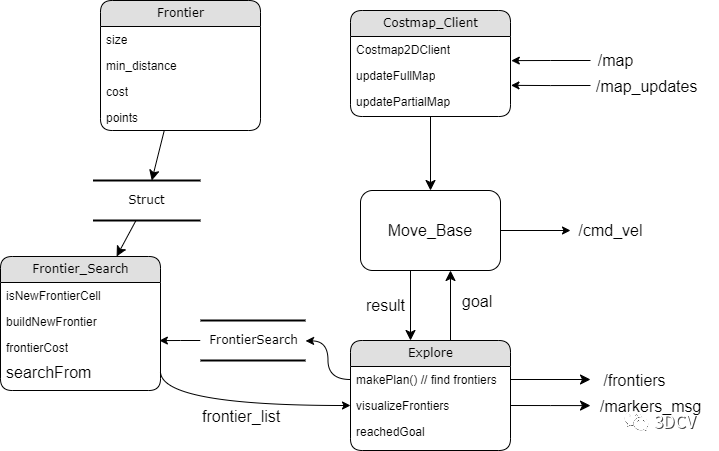
explore_lite程序的框图如下:
4 rrt_exploration
rrt_exploration[4]分为四个主要部分:Global Frontier Detector、Local Frontier Detector、Filter、Assigner。
(1)Global Frontier Detector、Local Frontier:使用全局和局部边缘检测点去选择下一步应该探索的边界点,生长的RRT数到达的点如果位于未知区域,则这个的被认为是边界点,全局边缘检测是一种从初始位置开始一直执行的RRT搜素,全局RRT树不重置,随着时间不断生长、细化,主要是防止机器人错过在地图上探索小角落的机会,也确保原理机器人当前位置的点被检测和探索[rrt_exploration],而局部边缘检测是以机器人当前位置为起始点拓展的RRT树,这个局部树搜索到一个边界点后会重置树。
这里存在一些问题:
全局RRT树的生长速度随着树的生长而变慢
RRT是一种渐进最优的算法,理论上时间足够长可以覆盖整个地图,但其具有随机性,有限时间内很可能无法完全探测所有未知区域,特别是实际应用中往往是有时间要求的
RRT本身的生长问题:当一个分支无法生长延伸时,需要回溯到之前的未知,这会增加搜索时间和重复区域
如下图,RRT具有随机性,可能在机器人前往一个目前“最优”的目标点时,突然发现了一个更好的点,机器人需要折返,尽管这种可能性很小,但可能会出现这种情况,会增加时间和重复度,而frontier_exploration这种算法往往有更好的倾向性和启发性,而且在探索过程中使用了BFS虽然时间较慢(我认为是微小的),但是可以搜索到所有可能的边界,并通过权重合理选择探索顺序。
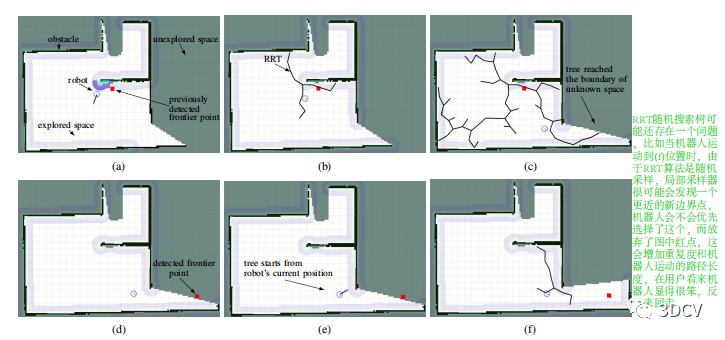
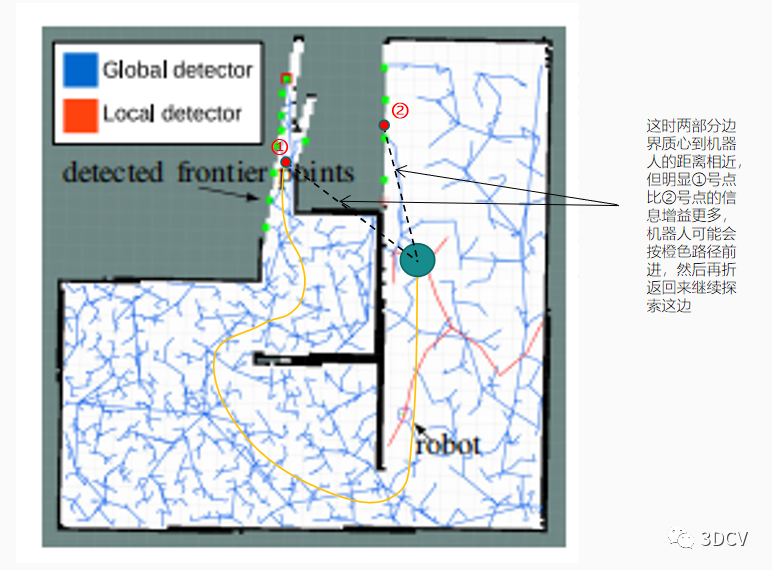
RRT源代码中提供了使用opencv进行边界检测的方法作为比较,将使用cv2.findContours()方法检测出来的边界序列求质心后打包发送,发送给Filter滤波后再发送给Assigner,在Assigner中求出最终的得分,选择得分高的节点发送个Move_base节点,这就出现一个情况在每一次检测节点轮询,目标点是不断发生变化的(很具有随机性),也就是说有可能还没到当前发布的位置时,随着地图更新,又会产生新的目标点,如果向一个方向即将(还没)探索完(这时它的信息增益I很小了),还是可能会被其他位置的目标边界点吸引,这样会增加重复性和探索时间,及时作者加了滞回增益h,也不能避免发生这种情况。
(2)Filter
对搜索到的点进行聚类,形成边界,这里的聚类方法也是使用最简单的质心聚类法,质心聚类公式如下:
(3)Assigner
从现有的目标点中根据导航成本(N)和信息增益(I)两项选择机器人下一步需要前往的目标点
可以借鉴的一点是RRT选择点的公式,在信息增益I这一项前加了一个滞回增益项h,h也跟距离有关,防止一个很远但I过大的边界点把机器人吸引过去。
RRT相较于frontier_exploration的优势就是速度快,但作者也在文献中实验指出,探索时间比基于图像处理的时间稍长,但是优势在于可以方便的拓展到三维。
5 总结
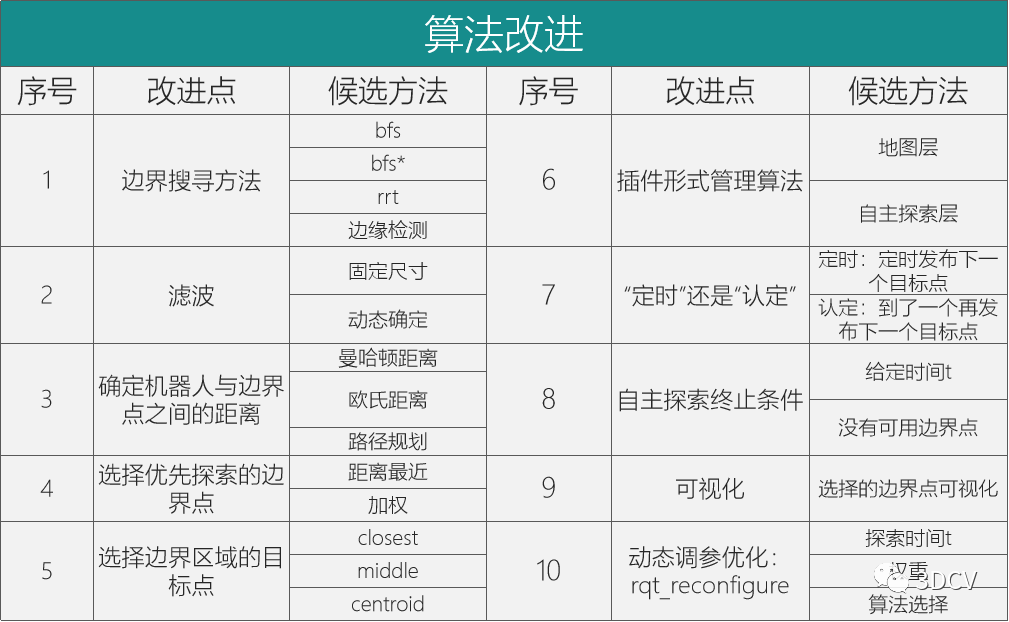
最后,就是我经过看论文和阅读源代码,分析总结的自主探索算法可以改进的点,通过我阅读一些文献,我发现对算法的改进确实就是从这几个方面入手的。
审核编辑:刘清
-
浅析FreeRTOS任务调度器的三种调度算法和应用2024-05-10 10200
-
如何在LabVIEW 平台下完成视觉算法的加速2016-12-28 5986
-
常用的FBAR模型有哪三种?2021-03-11 2658
-
可重构平台下AES算法的流水线性能怎么优化?2021-04-28 2323
-
STM32实现复位的三种常用方式问题2021-08-12 1744
-
算法的三种结构介绍2021-11-08 1463
-
什么是ROS?ROS产生、发展和壮大的原因和意义2021-12-17 2143
-
三种常用的嵌入式操作系统是什么2021-12-22 1535
-
三种不同的“防 Ping”技巧2010-04-14 1384
-
三种SPWM波形生成算法的分析与实现2016-08-24 1117
-
数控机床插补算法中最常用的三种算法源码2016-11-08 2112
-
Hadoop平台下改进的推测任务调度算法_陈明丽2017-03-19 798
-
如何提升示波器波形质量 三种波形算法的应用2018-04-28 4133
-
三种最常用的MEMS制造技术解析2020-07-29 9032
-
FPGA应用之vivado三种常用IP核的调用2023-02-02 5270
全部0条评论

快来发表一下你的评论吧 !
