

怎么使用Go重构流式日志网关呢?
描述
项目背景
分享之前,先来简单介绍下该项目在流式日志处理链路中所处的位置。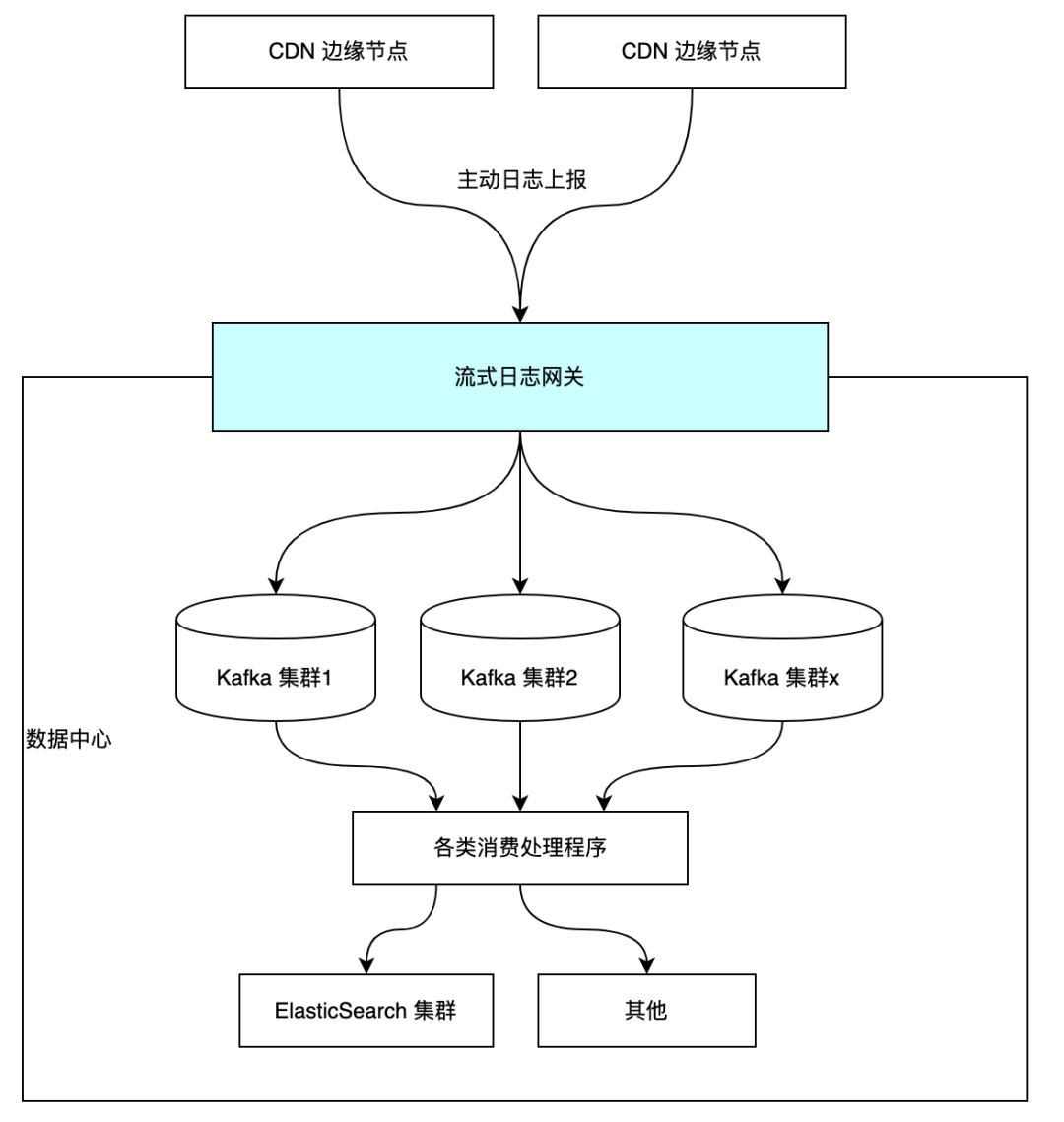
流式日志网关的主要功能是提供 HTTP 接口,接收 CDN 边缘节点上报的各类日志(访问日志/报错日志/计费日志等),将日志作预处理并分流到多个的 Kafka 集群和 Topic 中。
越来越多的客户要求提供实时日志支持,业务量的增加让机器资源的消耗也与日俱增,最先暴露出了流式日志处理链路的一大瓶颈——带宽资源。 可以通过给集群扩充更多的机器来提升集群总传输带宽,但基于成本考量,重中之重是先优化网关程序。
旧版网关项目
项目代号 Chopper ,其基于另一个内部 OpenResty 项目框架来开发的。其亮点功能有:支持从 Consul 、Redis 等其他外部系统热加载配置及动态生效;能够加载 Lua 脚本实现灵活的日志预处理能力。 其 Kafka 生产者客户端基于 doujiang24/lua-resty-kafka 实现。经过实践考验,Chopper 的吞吐量是满足现阶段需求的。
存在的问题
1. 关键依赖库的社区活跃度低 lua-resty-kafka 的社区活跃度较低,至今仍然处在实验阶段;而且它用作 Kafka 生产者客户端目前没有支持消息压缩功能,而这在其他语言实现的 Kafka 客户端中都是标准的选项。
2. 内存使用不节制 单实例部署配置 4 核 8 G,仅少量请求访问后,内存占用就稳定在 2G 而没有释放。
3. 配置文件可维护性差 实际线上用到 Consul 作为配置中心,采用篇幅很长的 JSON 格式配置文件,不利于运维。另外在 Consul 修改配置没有回退功能,是一个高风险操作。 好在目前日志网关的功能并不复杂,所以我们决定重构它。
新项目启动
众所周知, Go 语言拥有独特的高并发模型、较低的上手难度和丰富的第三方生态。而且我们小组成员都有 Go 项目的开发经验,所以我们选择使用基于 Go 语言的技术栈来重新构建 Chopper 项目,所以新项目命名为 chopper-go 。
需求梳理及概要设计
重新构建一个线上项目的基本原则是,功能上要完全兼容,最好能够实现线上服务的无缝升级替换。
原版核心模块的设计
Chopper 的核心功能是将接收到的 HTTP 请求分流到特定 Kafka 集群及其 Topic 中。
一、HTTP 接口部分
只开放了唯一一个对外的 API ,功能很简单:
请求方式:POST 请求路径:/log/repo/{repo_name}请求体: 多行日志,满足 JSONL 格式(即每行一条 JSON ,多行按换行符 分隔)。相应状态码:- 200:投递成功。- 5xx:投递失败需要重试。参数解释: - repo_name: 对应 repo 配置名称。
二、业务配置部分
每一类业务抽象为一个 repo 配置。Repo 配置由三部分构成:constraint、processor、kafka。 constraint 是一个对象,可以配置对日志字段的一些约束条件,不满足条件的日志会被丢弃。 processor 是一个列表,可以组合多个处理模块,程序将按顺序依次对请求中的每条日志进行处理。实现了如下几种 processor 类型:
decoder , 配置原始数据按哪种格式反序列化到 Lua table ,但只实现了 JSON decoder。
splitter,配置分隔日志字段的字符。
assigner,配置一组字段名映射关系,需要与 spliter 配合。
executer, 配置额外的 lua 脚本名称,通过动态加载其他 lua 脚本实现更灵活的处理逻辑。
kafka 是一个对象,可以配置当前业务相关联的 Kafka 集群名,默认投递的 Topic ,以及生产者客户端的工作模式(同步或者异步)。 新版本的改动 HTTP 接口沿用原先的设计,在业务配置部分做了一些改动:
processor 改名为 executers ,实现几个通用功能的日志处理模块,方便组合使用。
kafka 配置中关联的不再是集群名,而是 Kafka 生产者客户端的配置标签。
原先保存 kafka 集群连接配置信息的配置块,改为保存 kafka 生产者客户端的配置块,统一在一个配置块区域初始化所有用到的 kafka 生产者客户端。
一点妥协(做减法)
为了缩短新项目的开发周期,对原始项目的一些不太重要的特性我们做了一些取舍。
取消动态脚本功能
Go 是静态语言没有 Lua 动态语言那么灵活,要加载执行动态脚本有一定的实现难度,且日志处理性能没有保障。 线上只有极少数业务在 processor 中配置了 executor,且这些 executor 的 Lua 脚本实现相近,完全可以抽取出通用的代码。
不支持外部配置中心
为了让发布和回退有记录可回溯,从 Consul 等配置中心热加载服务配置的功能我们也去掉了。利用好容器平台的金丝雀发布功能,就能将服务更新的影响降到最低。
不支持复杂的路由重写
OpenResty 项目内置 Nginx 可以利用 Nginx 强大的配置实现丰富的路由 rewrite 功能,就具体使用场景而言,我们只需要简单的路由映射即可。况且更复杂的需求也可以由上一级网关完成。
选择合适的开源库
Web 框架的选择
最终我们选择了 Gin 。原因是用得多比较熟,而且文档看着舒服。
Kafka 生产者客户端的选择
社区中热度最高的几款 Go Kafka 客户端库:
segmentio/kafka-go
Shopify/sarama
confluentinc/confluent-kafka-go
实际上三款客户端库我们在历史项目中都使用过,其中 kafka-go 的 API 是三者中最简洁易用的,我们的多个消费端程序都是基于它实现的。
但是在 chopper-go 中仅需要用到生产者客户端,我们没有选择 kafka-go 。
那是因为我们做了一些基准测试,发现 kafka-go 的生产者客户端存在性能风险:启用 async 模式时尽管消息发送特别快,但是内存占用也增长特别快。
最终我们选择 sarama ,一方面是性能很稳定,另一方面是它开放的 API 较多,但是用起来确实有点费劲。
测试框架的选择
程序的可靠性,一定需要测试来保证。除了编写小模块中编写单元从测试,我们对整个日志网关服务还要做集成测试。集成测试涉及到一些外部服务依赖,此项目中主要的外部依赖是 Kafka 和 Zookeeper 。
利用 Docker 可以很方便的拉起测试环境,我们注意到了两款可以用来在 Go test 中编写集成测试的库:
ory/dockertest
testcontainers/testcontainers-go
使用下来,我们最终选择了 testcontainers-go,简单介绍下原因: 在编写集成测试时,我们需要有个等待机制来确保依赖服务的容器是否准备就绪,并以此控制测试流程,以及测试结束后需要把测试开启的临时容器都清理干净。 testcontainers-go 的设计要优于 dockertest 。
testcontainers-go 提供一个 wait 子包,可以配置多种等待策略来确保依赖服务就绪,以及测试结束时它会调用一个特殊的名为 Ryuk 的容器来确保测试容器都被关闭。
相对而言,dockertest 要简陋不少。 需要注意的是,在 CI 环境运行集成测试都需要确保 ci-runner 支持 DinD ,否则运行 go test 会失败。
项目开发
项目开发过程中基本按照需求来实现没有太多难点。这里分享踩到的几个坑。
循环中变量的引用问题
在测试中发现,Kafka 生产者没有按期望把消息投递到指定的 Kafka 集群。 经过排查到如下代码:
func New(cfg Config) (*Manager, error) {
var newProducers = make(NewProducerFuncs)
for name, kCfg := range cfg.Mapping {
newProducers[name] = func() (kafka.Producer, error) { return kafka.New(kCfg) }
}
// 略
}
其作用是将配置每个 Kafka 生产者配置先保存为一个函数闭包,待后续初始化 repo 的时候再初始化生产者客户端。经验丰富的同学可以发现,for 循环的 kCfg 变量其实是指向迭代对象的地址,整个循环下来所有的函数闭包中用到的 kCfg 都指向 cfg.Mapping 的最后一个迭代值。 解决办法很简单,先做一遍变量拷贝即可:
func New(cfg Config) (*Manager, error) {
var newProducers = make(NewProducerFuncs)
for name, kCfg := range cfg.Mapping {
newProducers[name] = func() (kafka.Producer, error) { return kafka.New(kCfg) }
}
// 略
}
Sarama 客户端的一点坑
对于重要的日志数据,我们希望在 HTTP 请求返回时明确反馈是否成功写入 Kafka 。那么最好将 Kafka 生产者客户端配置为同步模式。
而同步模式的生产者要提高吞吐量,批量发送是必不可少的。 批量发送的配置位于 sarama.Config.Producer.Flush
cfg := sarama.NewConfig() // 单次请求中消息数量的绝对上限 cfg.Producer.Flush.MaxMessages = batchMaxMsgs // 能够触发请求发出的消息数量阈值 cfg.Producer.Flush.Messages = batchMsgs // 能够触发请求发出的消息字节大小阈值 cfg.Producer.Flush.Bytes = batchBytes // 批量请求的触发间隔时间 cfg.Producer.Flush.Frequency = batchTimeout实践中发现,如果配置了 Flush.Bytes 而没有配置Flush.Frequency 就存在问题。如果消息大小始终未达阈值就不会触发批量请求,故 HTTP 请求就会阻塞直到客户端请求超时。 所以在配置参数的读取上,我们把这两个配置项做了关联,只有配置了 Flush.Frequency 才能让 Flush.Bytes 的配置生效。
项目上线
容器平台上的灰度技巧
原本图方便我们的路由转发规则配置的是全部路由直接转给同一组 Chopper 实例。 前面介绍了,每一个业务对应一个 repo,也就对应一个独立的请求路径。如果要灰度新的服务,需要对不同业务单独灰度,所以我们需要将不同业务的流量去分开。
好在容器平台的 k8s-ingress 使用的是 APISIX 作为接入网关,其路由匹配的优先级是:绝对匹配 > 前缀匹配。 只需要针对特定业务增加一条绝对匹配规则,就可以分离出特定业务的流量。
举个例子: 原本的转发规则是:/* -> workers-0 我们新建一条转发规则:/log/repo/cdn-access -> workers-1 workers-0 和 workers-1 两组服务的配置完全相同。 然后我们对 workers-1 这组服务灰度发布新版程序。
逐步扩大
每灰度一条路由,我们可以从监控 Dashboard 上观察 HTTP 请求是否有异常,观察 Kafka 对应的 topic 的写入速率是否有异常抖动。
一旦观测到异常,立即停止灰度,然后检查程序运行日志,修正问题后重新开始灰度。 如果无异常,则逐步扩大灰度比例,直到完成服务更新。
总结起来就是灰度、观测、回退、修改循环推进,确保升级对每个业务都无感知。
完成发布
对比服务端资源占用情况
旧版 chopper (4C8G x 20) 灰度比例 10% -> 50%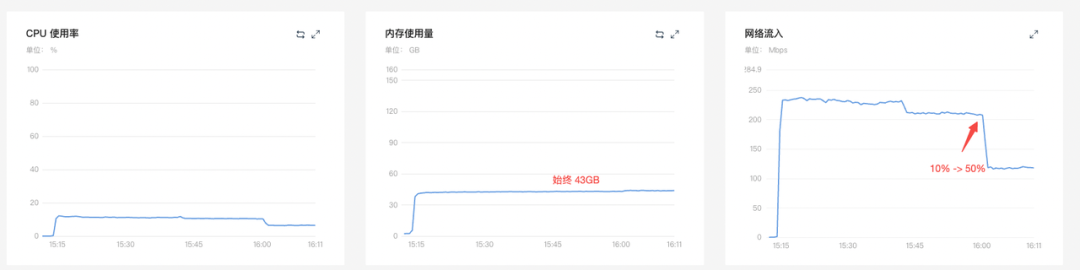
chopper-go (4C4G x 20) 10% -> 50%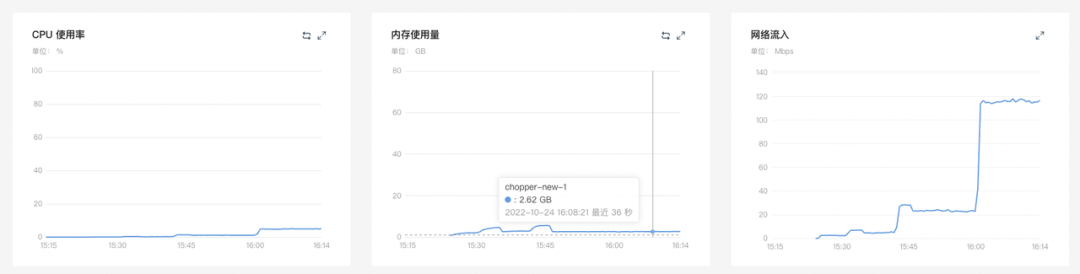
50% -> 100%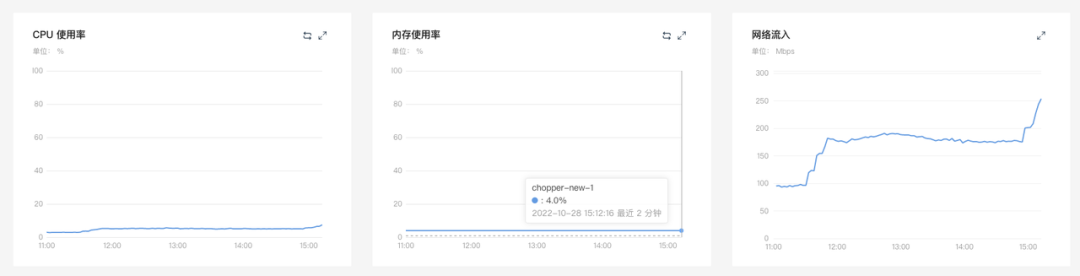
结论:新版日志网关的内存和 CPU 的资源使用都有显著降低。
服务端程序的资源占用情况
旧版 chopper 的 Kafka 客户端不支持消息压缩,chopper-go 发布中就配置了 Kafka 生产者消息的功能。 压缩算法选择 lz4 ,观察两组消费服务的资源实用率的变化: 消费服务0
内存使用率 27% -> 40%
网络流入 253Mbps -> 180Mbps
消费服务1
内存使用率 28% -> 39%
网络流入 380Mbps -> 267Mbps
结论:开启消息压缩功能后,消费实例的内存使用率普遍有增长,但内网传输带宽占用降低约 30% 。
更新计划
重构后的流式日志网关,尚有许多可优化空间,例如:
采用更节省带宽的日志传输格式;
进一步细化 Kafka topic 的分流粒度;
日志消息处理阶段多级处理执行器之间增加缓存提高字段访问速度等等。
在丰富开源生态的加持下,该项目的优化迭代也将有条不紊地进行。
审核编辑:刘清
-
Go语言开发有什么优势?怎么学?2017-12-19 4205
-
API信息全掌控,方便你的日志管理——阿里云推出API网关打通日志服务2018-02-06 2713
-
会go语言能做什么工作?2018-03-22 3182
-
如何利用ARM与FPGA设计重构控制器?2019-08-09 1625
-
有没有办法同时流式传输 A55 的 uart 日志并使用 MCUXpresso 使用 iMX93 evk 调试 M33?2023-05-18 723
-
网络取证日志分布式安全管理2009-05-11 505
-
对于大规模系统日志的日志模式提炼算法的优化2017-11-21 864
-
小米流式平台架构演进与实践2020-03-15 1387
-
PLC网关主要可以支持哪些品牌型号的PLC协议呢?2021-11-06 1456
-
工业智能网关日志有哪些?如何输出和导出网关日志查看呢?2022-10-26 1659
-
流式图计算TuGraph-Analytics技术背后的故事和技术特性2023-06-28 2127
-
FTTR主网关开通后实现主从网关组网呢?2023-07-19 9640
-
奇怪!应用的日志呢??2024-06-11 1079
-
日志篇:模组日志总体介绍2024-10-24 1268
-
Profinet转EtherCAT网关配置工作日志2026-05-12 193
全部0条评论

快来发表一下你的评论吧 !
