

Meta开源I-JEPA,“类人”AI模型
描述
Meta 宣布推出一个全新的 AI 模型 Image Joint Embedding Predictive Architecture (I-JEPA),可通过对图像的自我监督学习来学习世界的抽象表征,实现比现有模型更准确地分析和完成未完成的图像。
目前相关的训练代码和模型已开源,I-JEPA 论文则计划在下周的 CVPR 2023 上发表。
根据介绍,I-JEPA 结合了 Meta 首席 AI 科学家 Yann LeCun 所提倡的类人推理方式,帮助避免 AI 生成图像常见的一些错误,比如多出的手指。
I-JEPA 在多项计算机视觉任务上表现出色,且计算效率比其他广泛使用的计算机视觉模型高得多。
I-JEPA 学习的表征也可以用于许多不同的应用程序,而无需进行大量微调。
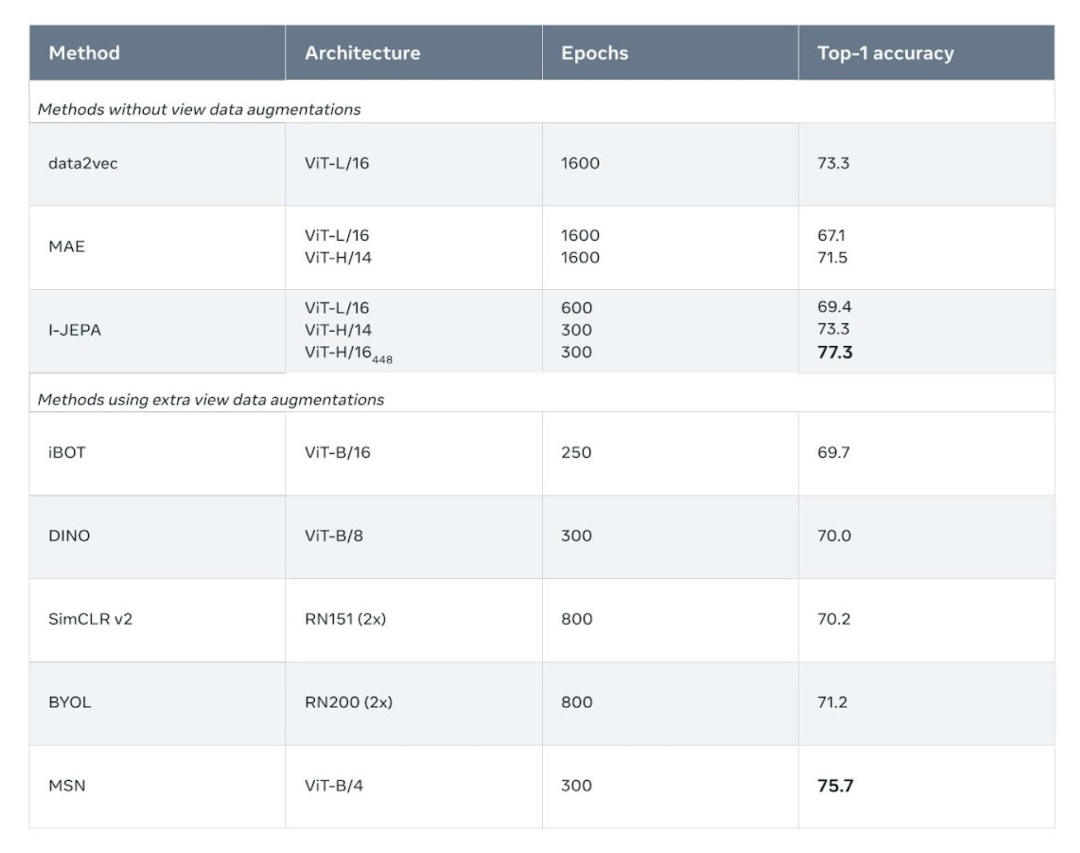
例如,项目团队在 72 小时内使用 16 个 A100 GPU 训练了一个 632M 参数的视觉转换器模型,I-JEPA 在 ImageNet 上的 low-shot 分类中性能表现最优,每个类只有 12 个标记示例。
其他方法通常需要 2 到 10 倍的 GPU 时间,并且在用相同数量的数据进行训练时错误率更高。 I-JEPA 背后的想法是以更类似于人类一般理解的抽象表示来预测缺失的信息。
I-JEPA 使用抽象的预测目标,潜在地消除了不必要的 pixel-level 细节,从而使模型学习更多语义特征。
另一个引导 I-JEPA 产生语义表征的核心设计选择是多块掩码策略。
具体来说,项目团队证明了使用信息丰富的(空间分布的)上下文来预测包含语义信息(具有足够大的规模)的大块的重要性。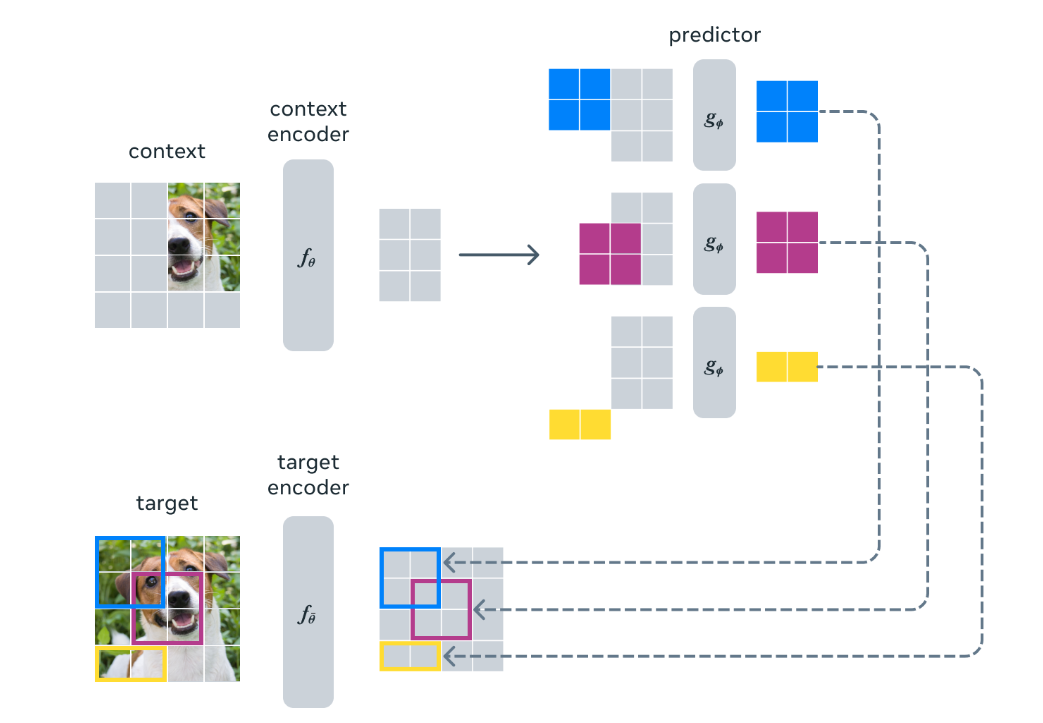
I-JEPA 中的预测器可以看作是一个原始的(和受限的)世界模型,它能够从部分可观察的上下文中模拟静态图像中的空间不确定性。
更重要的是,这个世界模型是语义的,因为它预测图像中不可见区域的高级信息,而不是 pixel-level 细节。
为了解模型捕获的内容,团队还训练了一个随机解码器,将 I-JEPA 预测的表征映射回像素空间。
这种定性评估表明该模型正确地捕获了位置不确定性并生成了具有正确姿势的高级对象部分(例如,狗的头、狼的前腿)。
简而言之,I-JEPA 能够学习对象部分的高级表示,而不会丢弃它们在图像中的局部位置信息。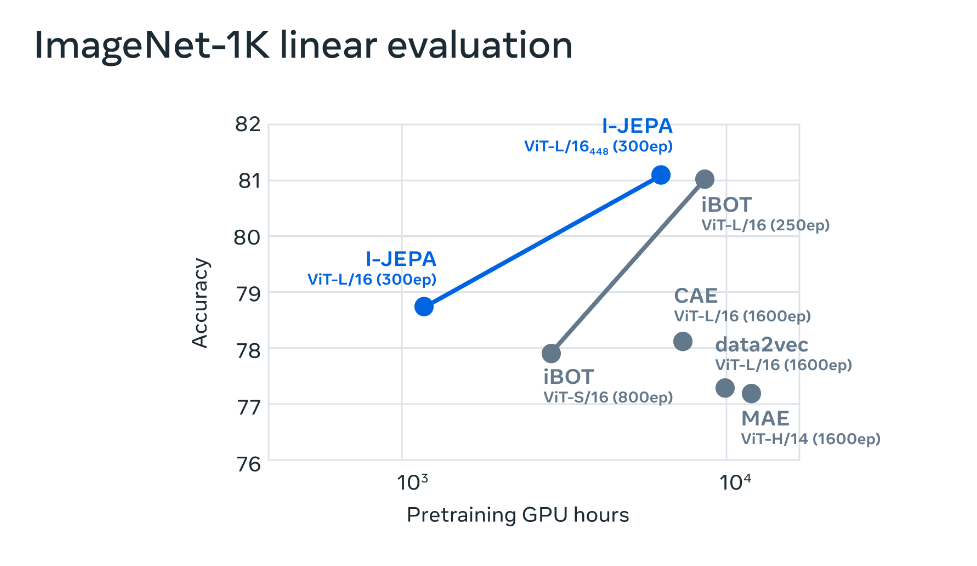
审核编辑:刘清
-
Meta重磅发布Llama 3.3 70B:开源AI模型的新里程碑2024-12-18 1189
-
Meta发布新AI模型Meta Motivo,旨在提升元宇宙体验2024-12-16 1728
-
扎克伯格:联想运用Meta Llama大模型打造个人AI助手AI Now2024-10-16 1842
-
Meta发布多模态LLAMA 3.2人工智能模型2024-09-27 1170
-
Meta发布全新开源大模型Llama 3.12024-07-24 2281
-
Meta即将发布超强开源AI模型Llama 3-405B2024-07-18 1775
-
英特尔AI产品助力其运行Meta新一代大语言模型Meta Llama 32024-04-28 1378
-
Meta推出最强开源模型Llama 3 要挑战GPT2024-04-19 1777
-
Meta发布新型无监督视频预测模型“V-JEPA”2024-02-19 1907
-
Meta发布开源大模型Code Llama 70B2024-01-31 1928
-
IBM 计划在 watsonx 平台上提供 Meta 的 Llama 2 模型2023-08-09 1127
-
AI大模型的开源算法介绍2023-08-08 3450
-
阿里云开源AI大模型,挑战Meta、OpenAI2023-08-04 1634
-
LeCun世界模型首个研究!自监督视觉像人一样学习和推理!2023-06-15 946
全部0条评论

快来发表一下你的评论吧 !
