

语音领域的GPT时刻:Meta 发布「突破性」生成式语音系统,一个通用模型解决多项任务
描述
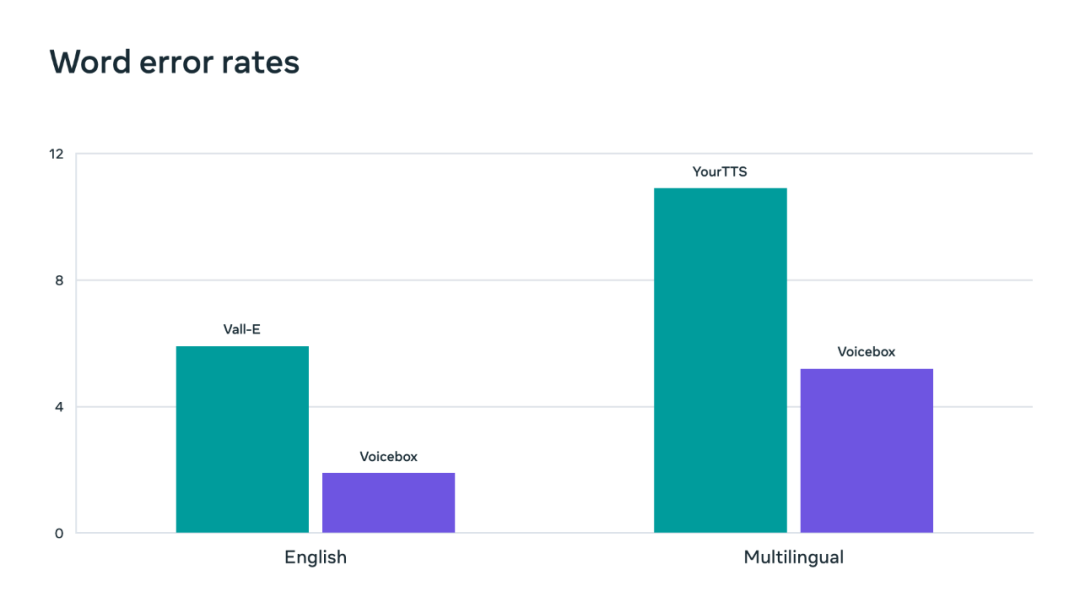
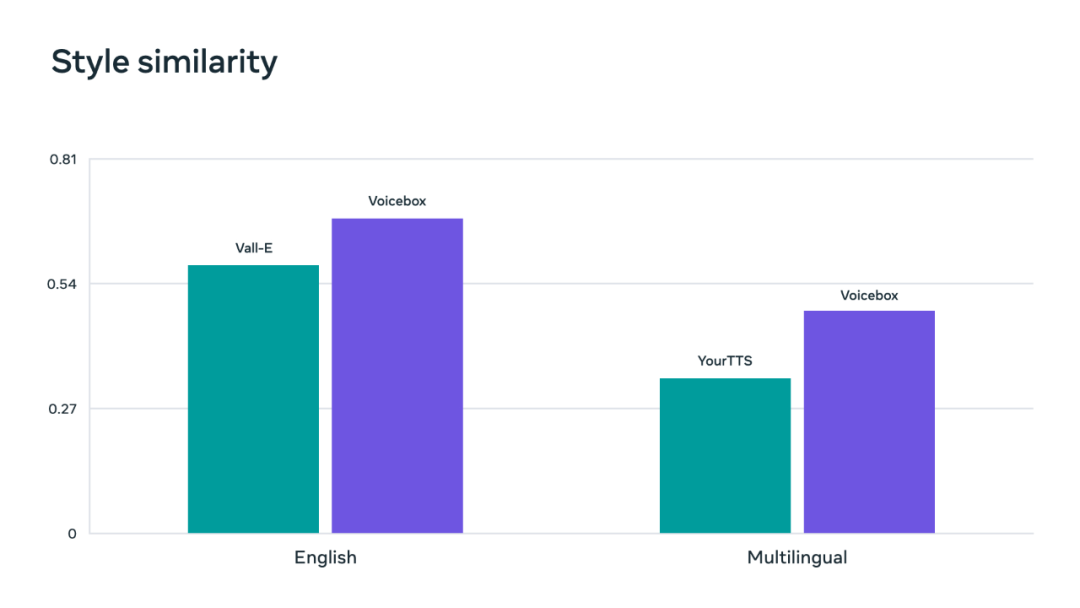
我们知道,GPT、DALL-E 等大规模生成模型彻底改变了自然语言处理和计算机视觉研究。这些模型可以生成高保真文本或图像,而且它们有个重要特点就是「通才」,可以解决没训过的任务。相比之下,语音生成模型在规模和任务泛化方面一直没有「突破性」成果。 今日,Meta 介绍了一种「突破性」的生成式语音系统,它可以合成六种语言的语音,执行噪声消除、内容编辑、转换音频风格等。Meta 称之为最通用的语音生成 AI。继开源 LLaMA 之后,Meta 在生成式 AI 方向又公布一项重大研究。

原文标题:语音领域的GPT时刻:Meta 发布「突破性」生成式语音系统,一个通用模型解决多项任务
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- 热点推荐
- 物联网
-
【大语言模型:原理与工程实践】揭开大语言模型的面纱2024-05-04 891
-
2018全球十大突破性技术发布2018-03-27 4204
-
基于labview的语音识别2019-03-10 12989
-
电源突破性的新技术2019-07-16 4348
-
基于MSP432 MCU的语音识别设计概述2019-07-30 2282
-
语音识别的现状如何?2019-10-08 3432
-
嵌入式语音识别系统与PC机语音识别系统相比有什么优点?2019-11-07 4559
-
怎样去搭建一个基于kaldi的在线语音识别系统2021-07-29 2220
-
Meta发布一款可以使用文本提示生成代码的大型语言模型Code Llama2023-08-25 2769
-
基于深度学习的语音合成技术的进展与未来趋势2023-09-16 2519
-
语音数据集:AI语音技术的灵魂2023-12-14 2071
-
中国电信发布首个支持30种方言混说语音大模型2024-05-28 1403
-
Transformer模型在语音识别和语音生成中的应用优势2024-07-03 3019
-
Meta发布Imagine Yourself AI模型,重塑个性化图像生成未来2024-08-26 1640
-
广和通发布自研端侧语音识别大模型FiboASR2025-08-04 1908
全部0条评论

快来发表一下你的评论吧 !
