

无图像单像素目标检测方法可用于自动驾驶汽车
汽车电子
描述
据麦姆斯咨询报道,近期,北京理工大学边丽蘅研究员(通讯作者)、彭林涛(第一作者)等人提出一种无图像单像素目标检测(SPOD)方法,无需获取图像或进行复杂场景重建,即可检测多个目标的位置、大小和类别。该方法采用单像素探测器,极大地降低了目标检测所需的计算能力,能同时执行目标分类、识别和跟踪,可用于驾驶时的危险识别。相关研究成果以“Image-free single-pixel object detection”为题发表在Optics Letters期刊。

图1 北京理工大学边丽蘅研究团队提出一种无图像单像素目标检测(SPOD)方法,可用于多目标位置、大小和类别检测
该研究团队负责人边丽蘅表示,利用无图像单像素目标检测(SPOD)技术可以直接从少量二维(2D)耦合测量值中实现高效、稳健的多目标检测,这种无图像传感技术有望解决现有视觉感知系统通信负载大、计算开销大和识别率低等问题。
这种高效的无图像SPOD技术由三个步骤组成,包括小尺寸图像优化调制、2D耦合测量采集和端到端传感。SPOD技术的优势在于以下三个方面。首先,建立端到端感知网络,通过2D耦合测量直接感知多个目标,与传统的基于图像的方法相比,可以减轻通信、计算和存储负担。其次,所提出的小尺寸优化图像采样方法能以更少的图像参数实现更好的无图像传感性能,并与传感网络一起通过两阶段进行训练和优化,从而保证了以最少的测量实现最优的感知效率。第三,基于transformer结构设计的SPOD可以增强网络对场景中目标的关注,并提取有效特征,从而提高目标检测性能。
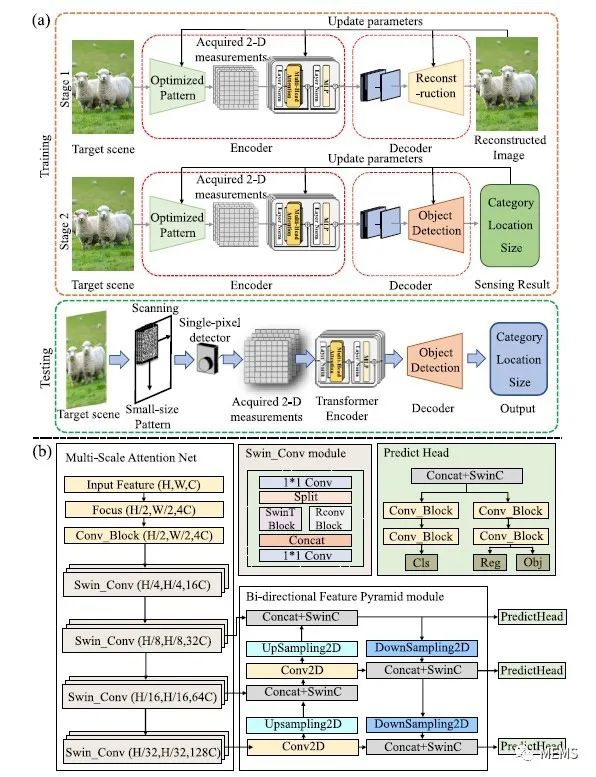
图2 (a)SPOD两阶段训练策略及主要框架;(b)负责解析高维语义特征和实现无图像目标检测的解码器的详细结构
利用SOPD方法获得目标2D测量值时,测量值会被输入基于transformer的编码器(一种深度学习模型),并提取场景中的高维语义特征。这些特征被输入基于多尺度注意力网络的解码器中,该解码器可同时输出场景中所有目标的类别、位置和大小信息。
自动化高级视觉任务通常需要场景的详细图像,以提取识别物体所需的特征。但这通常需要复杂的成像硬件或者复杂的重构算法,会导致计算成本高、运行时间长、数据传输负载大。因此,传统的“先图像后感知”方法并非目标检测的最佳选择。
基于单像素探测器的SPOD方法能够减少目标检测所需的计算能力。这是因为单像素探测技术不使用CMOS图像传感器或CCD图像传感器,而是用一系列结构光模式照亮场景,然后记录透射光强度,以获取物体的空间信息,从而计算重建目标或其属性。
研究人员认为,SPOD采用的小尺寸优化图像采样比传统的图像采样方法少一个数量级的图像参数,能实现较高的无图像传感精度。
“与其它单像素探测方法使用的全尺寸图像相比,SPOD这种小尺寸优化图像能实现更好的无图像传感性能。”彭林涛说道:“SPOD解码器中的多尺度注意力网络加强了网络对场景中目标区域的注意力。这可以更有效地提取场景特征,实现最先进的目标检测性能。”
“对于自动驾驶来说,SPOD可以与激光雷达(LiDAR)一起使用,以帮助提高场景重建速度和物体检测精度。”边丽蘅表示:“我们相信,它具有足够高的自动驾驶检测率和准确性,同时还降低了物体检测所需的传输带宽和计算资源要求。”
为了证明SPOD的性能,边丽蘅研究团队构建了一个概念验证装置。从Pascal Voc 2012测试数据集中随机选择图像打印在胶片上并用作目标场景。在5%的采样率下,使用SPOD完成每个场景的空间光调制和无图像目标检测的平均时间仅为0.016 s。相较于先进行场景重建(0.05 s)然后进行目标检测(0.018 s)的方法,效率显著提升。对于测试数据集中包含的所有目标类别,SPOD的平均检测准确率为82.2%,刷新率为63帧/秒。
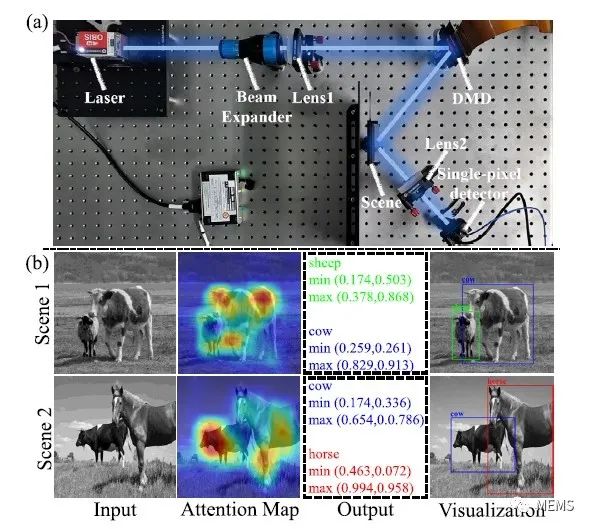
图3 (a)无图像SPOD的概念验证设置;(b)在5%采样率下,各种自然场景下的SPOD检测实验结果
“目前,SPOD还无法检测到所有可能的目标类别,因为用于训练模型的现有目标检测数据集仅包含80个类别。”彭林涛继续说道:“不过,当面对特定任务时,可以对预先训练的模型进行微调,以实现对行人、车辆或船只等新目标类别的无图像多目标检测。”
接下来,研究人员计划将无图像感知技术扩展到其它类型的探测器和计算采集系统,以实现无重建传感技术。
审核编辑:刘清
-
未来已来,多传感器融合感知是自动驾驶破局的关键2024-04-11 2419
-
FPGA在自动驾驶领域有哪些应用?2024-07-29 8402
-
谷歌的自动驾驶汽车是酱紫实现的吗?2011-06-14 4834
-
汽车自动驾驶技术2016-04-14 5610
-
自动驾驶真的会来吗?2016-07-21 14605
-
[科普] 谷歌自动驾驶汽车发展简史,都来了解下吧!2016-10-25 4372
-
AI/自动驾驶领域的巅峰会议—国际AI自动驾驶高峰论坛2017-09-13 7588
-
【威雅利 汽车】苹果最新专利曝光,要把VR和AR带进自动驾驶汽车2018-04-24 3590
-
高级安全驾驶员辅助系统助力自动驾驶2018-09-14 3474
-
可扩展图像传感器平台用于先进驾驶辅助系统和自动驾驶2018-10-11 3110
-
自动驾驶汽车的定位技术2019-05-09 3554
-
如何让自动驾驶更加安全?2019-05-13 3784
-
自动驾驶汽车的处理能力怎么样?2019-08-07 2929
-
LabVIEW开发自动驾驶的双目测距系统2023-12-19 4522
-
如何搞定自动驾驶3D目标检测!2024-01-05 1285
全部0条评论

快来发表一下你的评论吧 !
