

RISC-V vector intrinsic编程入门指南
嵌入式技术
描述
本文是为了帮助开发者快速入门 risc-v 架构下vector 的 intrinsic 编程,首先介绍了risc-v vector extension 的特性和 intrinsic 编程常见的数据类型与指令接口命名,然后给出一个数组/向量相加的完整例程,介绍C语言的普通实现与intrinsic向量化实现,最后展示了如何获取平头哥相关工具链编译程序并通过qemu模拟器运行。需要说明的是,本文介绍的特性与案例均以玄铁 c906 处理器为基础。
01vector extension
与ARM CPU支持的 SVE(Scalable Vector Extension) 类似,risc-v vector extension 可以通过向量化来提升程序运行速度。平头哥玄铁 c906 CPU支持 risc-v vector extension 0.7.1,新增了32个向量寄存器 v0-v31,下面对 vector extension中重要概念作介绍:
(1) 向量寄存器位宽 vlen:对于玄铁 c906,vlen = 128,即可以并行计算16个8位整数或4个32位浮点数等。
(2) 标准元素宽度 sew:sew = 8/16/32/64b,对于float计算,sew=32b;对于int8计算,sew=8b。
(3) 向量寄存器组 lmul:lmul = 1/2/4/8,多个向量寄存器可以组合在一起形成一个向量寄存器组,一条向量指令就可以对多个向量寄存器进行操作,还能提供更好的执行效率(具体的执行效率取决于执行部件的带宽)。
(4) 向量长度寄存器 vl:vl 寄存器保存一个无符号整数,指定由向量指令更新的元素个数。在向量指令执行期间,任何具有索引 ≥ vl 的目标向量寄存器组中的元素都被清零。如当 vl = 3 时,对于 float32 的运算,由于vlen=128,只会取向量寄存器中的低96位的3个float32数据进行计算,最高32位将清零,如下图所示。
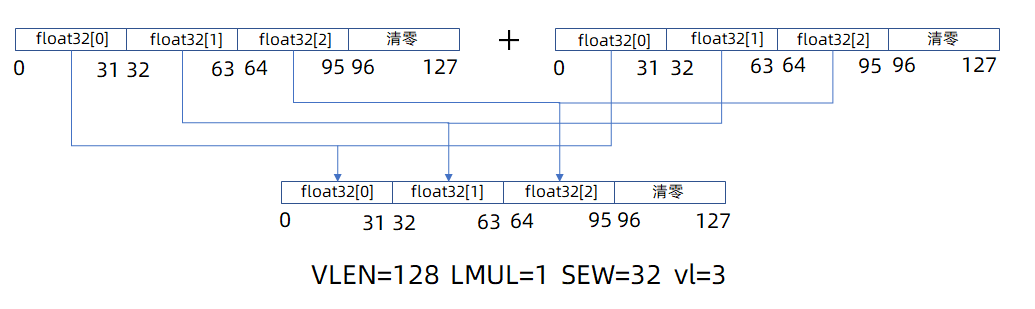
图1. c906 vl=3向量浮点相加示意图
02intrinsic
intrinsic 本质上是底层汇编指令的封装,与手工编写汇编程序相比,intrinsic 编程不需要考虑底层寄存器的分配,对于C语言用户而言更加容易上手,可维护性强,可读性更强,在跨平台的可移植性上也更加友好,配上相关编译器工具链后在性能上几乎可以媲美手工汇编。
2.1 数据类型
根据不同的 sew 和 lmul 组合,risc-v vector extension intrinsic 基本数据类型格式如下:
v<基本类型>m<向量寄存器组lmul>_t 其中:
基本类型:int8,int16,int32,int64,uint8,uint16,uint32,uint64,float16,float32
向量寄存器组 lmul:1,2,4,8
例如:
vint32m1_t:1个向量寄存器中存放 vl 个int32 数据, 0 < vl <= 4 (vlen/sew*lmul=128/32*1=4 )
vfloat32m1_t:1个向量寄存器中存放 vl 个float32数据, 0 < vl <=4
vint8m2_t:2个向量寄存器中存放 vl 个int8数据, 0 < vl <= 32
vfloat16m2_t:2个向量寄存器中存放 vl 个float16数据, 0 < vl <= 16
2.2 intrinsic命名
几乎每一条 risc-v vector 指令都有其对应的 intrinsic 函数接口,函数名格式如下:
<指令名>_<数据基本类型简写>m<向量寄存器组lmul> 其中:
指令名:vmul.vv (vmul_vv), vadd.vv (vadd_vv) 等
数据基本类型简写:i8,i16,i32,i64,u8,u16,u32,u64,f16,f32
向量寄存器组 lmul:1,2,4,8
例如:
// 2个向量寄存器中各自 vl 个float32数据逐个相乘得到 vl 个float32结果存入1个向量寄存器中,其中 0 < vl <= 4
vfloat32m1_t vfmul_vv_f32m1(vfloat32m1_t op1, vfloat32m1_t op2, size_t vl)
// 4个向量寄存器两两分组,每组寄存器中各自 vl 个int32数据逐个相加得到 vl 个int32结果存入2个向量寄存器中,其中 0 < vl <= 8
vint32m2_t vadd_vv_i32m2(vint32m2_t op1, vint32m2_t op2, size_t vl)
关于RVV intrinsic更多数据类型和指令接口可以参考附录中intrinsic手册。
03示例程序
本节通过数组相加的例子对 vector 扩展 intrinsic 使用作简单介绍;假设有长度为 ARRAY_LEN 的 float 类型数组 A,B,C,为了实现 C = A + B,有:
3.1 普通标量实现
在循环中对数组 A,B 中的浮点数逐个相加,循环的次数为 ARRAY_LEN 次。
void add(const float *a, const float *b, float *c, size_t length)
{
for (int i = 0; i < length; i++) {
c[i] = a[i] + b[i];
}
}
3.2 intrinsic 向量化实现
在循环中一次对数组 A,B 中的多个浮点数相加:
void add_vec(const float *a, const float *b, float *c, size_t length)
{
while (length > 0) {
size_t vl = vsetvl_e32m1(length); // 设置向量寄存器每次操作的元素个数
vfloat32m1_t va = vle32_v_f32m1(a, vl); // 从数组a中加载vl个元素到向量寄存器va中
vfloat32m1_t vb = vle32_v_f32m1(b, vl); // 从数组b中加载vl个元素到向量寄存器vb中
vfloat32m1_t vc = vfadd_vv_f32m1(va, vb, vl); // 向量寄存器va和向量寄存器vb中vl个元素对应相加,结果为vc
vse32_v_f32m1(c, vc, vl); // 将向量寄存器中的vl个元素存到数组c中
a += vl;
b += vl;
c += vl;
length -= vl;
}
}
设置 lmul = 1,由于 vlen = 128,向量加法每次最多能操作4个 float 数据,即循环的次数为 ceil(ARRAY_LEN / 4) 次,本例中定义ARRAY_LEN = 11,需循环计算3次,且第3次时剩余元素3个,即 vl=3,计算过程如图1所示。
从上述代码看,在使用 vector intrinsic 实现向量化时,需要手动从指定地址 load 数据到向量寄存器变量中,计算后,同样需要手动将向量寄存器变量中数据 store 回指定地址。相比于普通串行实现,利用 vector intrinsic 实现理论上有接近4倍的加速比,当设置 lmul = 2/4/8 或数据类型是short或者char时,可以取得更高的加速比。
04编译运行
4.1 获取安装工具链
从平头哥开放社区occ下载对应版本的risc-v工具链(https://occ.t-head.cn/community/download?spm=a2cl5.25411629.0.0.51b975321lplnb&id=4090445921563774976):
wget https://occ-oss-prod.oss-cn-hangzhou.aliyuncs.com/resource//1663142514282/Xuantie-900-gcc-linux-5.10.4-glibc-x86_64-V2.6.1-20220906.tar.gz
tar -zxvf Xuantie-900-gcc-linux-5.10.4-glibc-x86_64-V2.1.9-20210918.tar.gz -C {yourToolchainDir} # 解压至自己的目录
cd {yourToolchainDir}/bin
riscv64-unknown-linux-gnu-gcc -v #查看工具链版本
确保gcc工具链版本为 V2.6.1
gcc version 10.2.0 (Xuantie-900 linux-5.10.4 glibc gcc Toolchain V2.6.1 B-20220906)
4.2 编译
{yourToolchainDir}/bin/riscv64-unknown-linux-gnu-gcc -march=rv64gcv0p7xthead -static add.c -o add.elf
注:c906 只支持risc-v vector 0.7.1 扩展,需要在编译选项中加上 -march=rv64gcv0p7xthead 选项
4.3 qemu运行
从平头哥开放社区occ下载最新qemu模拟器(https://occ.t-head.cn/community/download?spm=a2cl5.25411629.0.0.51b975321lplnb&id=4168444414324183040)
wget https://occ-oss-prod.oss-cn-hangzhou.aliyuncs.com/resource//1681722863240/xuantie-qemu-x86_64-Ubuntu-18.04-20230413-0706.tar.gz
tar -zxvf csky-qemu-x86_64-Ubuntu-16.04-20210202-1445.tar.gz -C {yourQemuDir} # 解压至自己的目录
{yourQemuDir}/bin/qemu-riscv64 -cpu c906fdv add.elf
05附
(1)完整示例代码 add.c :
#include#include #include #define ARRAY_SIZE 11 float a_array[ARRAY_SIZE] = { 1.18869953, 1.55298864, -0.17365574, -1.86193886, -1.52391526, -0.36566814, 0.70753702, 0.73992422, -0.13493693, 1.09563677,1.03797902 }; float b_array[ARRAY_SIZE] = { 1.19655525, 0.23393777, -0.11629651, -0.54508896, -1.2424749, -1.54835913, 0.86935212, 0.12946646, 0.81831905, -0.42723697, -0.89793257 }; // float c_array[ARRAY_SIZE] = { // 2.38525478, 1.78692641, -0.28995225, -2.40702783, // -2.76639016 -1.91402727,1.57688914, 0.86939068, // 0.68338213, 0.66839979, 0.14004644 // }; float c_array_ref[ARRAY_SIZE]; float c_array_vec[ARRAY_SIZE]; void add(const float *a, const float *b, float *c, size_t length) { for (int i = 0; i < length; i++) { c[i] = a[i] + b[i]; } } void add_vec(const float *a, const float *b, float *c, size_t length) { while (length > 0) { size_t vl = vsetvl_e32m1(length); // 设置向量寄存器每次操作的元素个数 vfloat32m1_t va = vle32_v_f32m1(a, vl); // 从数组a中加载vl个元素到向量寄存器va中 vfloat32m1_t vb = vle32_v_f32m1(b, vl); // 从数组b中加载vl个元素到向量寄存器vb中 vfloat32m1_t vc = vfadd_vv_f32m1(va, vb, vl); // 向量寄存器va和向量寄存器vb中vl个元素对应相加,结果为vc vse32_v_f32m1(c, vc, vl); // 将向量寄存器中的vl个元素存到数组c中 a += vl; b += vl; c += vl; length -= vl; } } int main() { printf("Test add function by rvv0.7.1 intrinsic "); add(a_array, b_array, c_array_ref, ARRAY_SIZE); add_vec(a_array, b_array, c_array_vec, ARRAY_SIZE); // 逐个比较普通实现与intrinsic实现的结果 for (int i = 0; i < ARRAY_SIZE; i++) { if (fabsf(c_array_ref[i] - c_array_vec[i]) > 1e-6) { printf("index[%d] failed, %f=!%f ", i, c_array_ref[i], c_array_vec[i]); } else { printf("index[%d] successed, %f=%f ", i, c_array_ref[i], c_array_vec[i]); } } return 0; }
(2)运行结果:
在 main 函数中,对普通实现与 intrinsic 实现的结果逐个进行比对,若两者绝对误差大于 1e-6,认为向量化计算结果错误,从下图运行结果看,两者输出结果完全一致,符合预期。
Test add function by rvv0.7.1 intrinsic
index[0] successed, 2.385255=2.385255
index[1] successed, 1.786926=1.786926
index[2] successed, -0.289952=-0.289952
index[3] successed, -2.407028=-2.407028
index[4] successed, -2.766390=-2.766390
index[5] successed, -1.914027=-1.914027
index[6] successed, 1.576889=1.576889
index[7] successed, 0.869391=0.869391
index[8] successed, 0.683382=0.683382
index[9] successed, 0.668400=0.668400
index[10] successed, 0.140046=0.140046
(3)riscv 编译工具链下载:https://occ-oss-prod.oss-cn-hangzhou.aliyuncs.com/resource//1663142514282/Xuantie-900-gcc-linux-5.10.4-glibc-x86_64-V2.6.1-20220906.tar.gz
(4)qemu模拟器下载:https://occ-oss-prod.oss-cn-hangzhou.aliyuncs.com/resource//1681722863240/xuantie-qemu-x86_64-Ubuntu-18.04-20230413-0706.tar.gz
(5)Xuantie 900 Series RVV-0.7.1 Intrinsic Manual.pdf 手册下载:https://occ-oss-prod.oss-cn-hangzhou.aliyuncs.com/resource//1663142187133/Xuantie+900+Series+RVV-0.7.1+Intrinsic+Manual.pdf
审核编辑:汤梓红
-
关于RISC-V学习路线图推荐2024-11-30 1967
-
RISC-V MCU入门2024-11-27 1602
-
浅谈RISC-C C Intrinsic的发展情况2024-10-16 1724
-
RISC-V Vector Intrinsic使用标准2024-10-14 1399
-
RISC-V MCU智能配置程序用户指南2024-01-30 518
-
RISC-V设计支持工具,支持RISC-V技术的基础2023-07-14 980
-
《RISC-V体系结构编程与实践》试读2023-04-03 1388
-
初探RISC-V—《RISC-V体系结构编程与实践》2023-03-28 1683
-
General Processor with RISC-V Vector ExtensionRISCV国际基金会 2022-09-02
-
RISC-V-Reader-Chinese-v2p1 RISC-V手册(中文) RISC-V开源指令集的指南2022-04-22 13106
-
从零开始写RISC-V处理器2022-03-17 3398
-
如何入门RISC-V嵌入式2022-01-07 1321
-
RISC-V快速入门指南2021-05-02 6838
-
基于 RISC-V 的微控制器入门指南2020-08-21 2466
全部0条评论

快来发表一下你的评论吧 !
