

通用的时空预测学习框架实现高效视频预测案例
人工智能
描述
本文介绍CVPR2023的中稿论文:Temporal Attention Unit: Towards Efficient Spatiotemporal Predictive Learning。这篇论文介绍了一种用于高效时空预测的时间注意力单元(Temporal Attention Unit,TAU)。该方法改进了现有框架,对时间和空间上的依赖关系分别学习,提出了时间维度上的可并行化时序注意力单元,实现了高效的视频预测。

代码开源在我们的时空预测学习框架OpenSTL中。OpenSTL是一个全面的时空预测学习基准,涵盖了广泛的方法和不同的任务,从合成的移动物体轨迹到现实世界的场景,如人类运动、驾驶场景、交通流和天气预报。欢迎大家关注!
引言
时空预测学习是一种通过学习历史帧来预测未来帧的自监督学习范式,可以利用海量的无标注视频数据学习丰富的视觉信息,在气象预测、交通流量预测、人体姿势变化估计等领域有着广泛的应用场景。时空预测学习需要考虑视频中的空间相关性和时间演变规律,这是一项具有挑战性的任务。传统的方法主要基于循环神经网络来建模时间依赖关系,但是RNN有着计算效率低、难以捕捉长期依赖、容易出现梯度消失或爆炸等缺点。因此,如何设计一个高效、准确、稳定的时空预测学习模型,是一个亟待解决的问题。为了解决这个问题,我们首先研究现有的方法,并提出时空预测学习的通用框架,如下图所示。
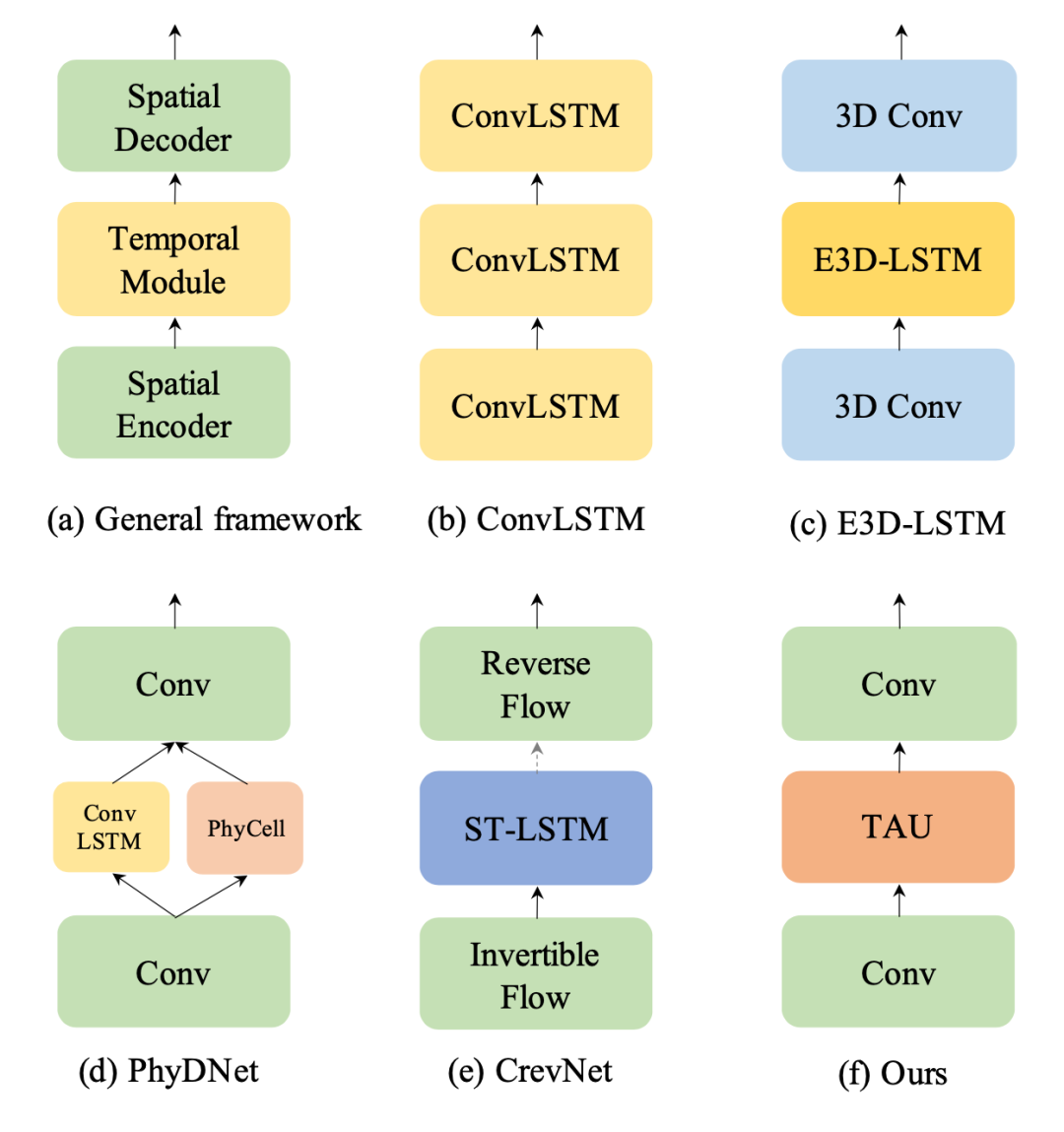
TAU
如下图所示,TAU模型不使用循环神经网络,而是使用注意力机制来并行化地处理时间演变。TAU模型将时空注意力分解为两个部分:帧内静态注意力和帧间动态注意力。帧内静态注意力使用小核心深度卷积和扩张卷积来实现大感受野,从而捕捉帧内的长距离依赖关系。帧间动态注意力使用通道间注意力的方式来学习不同帧之间的通道权重,从而捕捉帧间的变化趋势。
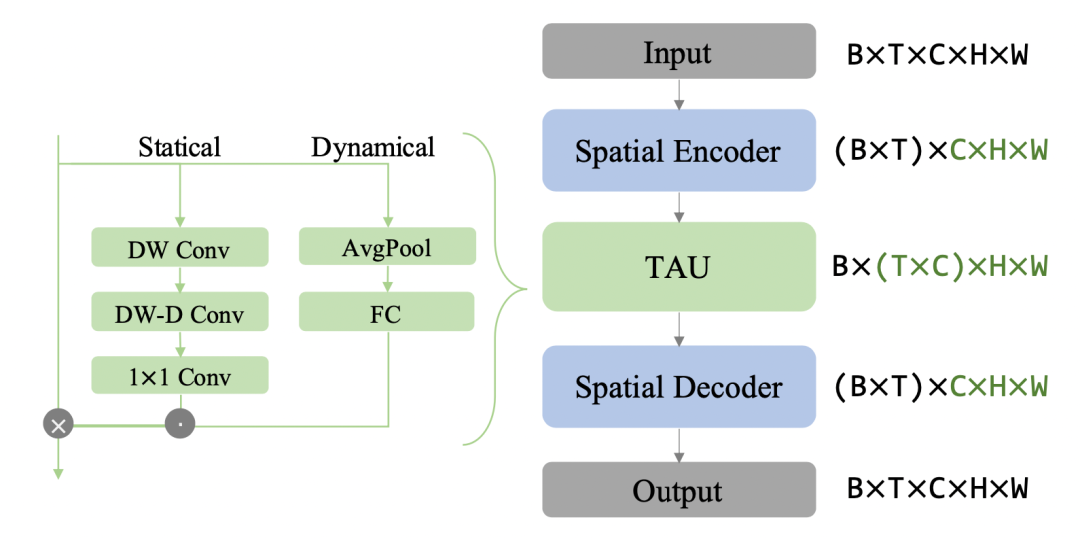
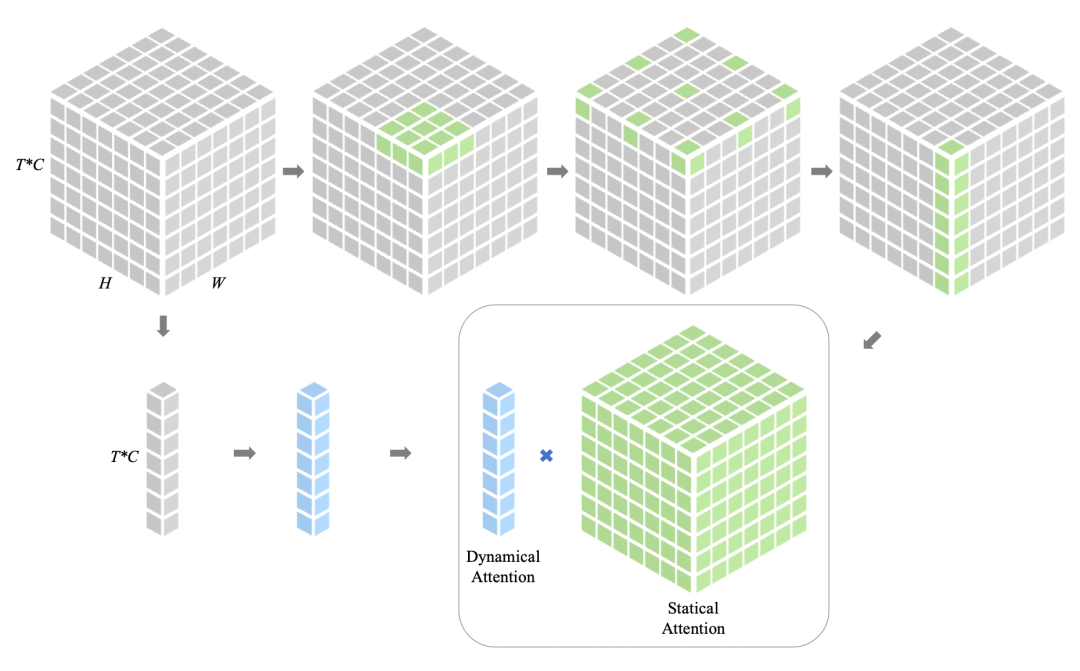
TAU模块将时间注意力分为两部分:帧内静态注意力和帧间动态注意力。前者通过获得的大感受野捕捉帧内的长期依赖关系;而后者以挤压和激发的方式学习通道的注意力权重,以捕捉时间线上的时序演变。最后的注意力是动态注意力和静态注意力结合的产物。受ViTs和大核卷积的启发,研究者使用了深度卷积(DW Conv)、深度扩张卷积(DW-D Conv)和1x1通道卷积来建模大核卷积。
此外,我们还提出了一种新颖的差分散度正则化方法,用于优化时空预测学习的损失函数。该方法同时考虑了帧内误差和帧间变化量。通过将预测帧和真实帧之间的差分转换为概率分布,并计算它们之间的KL散度,来强制模型学习到视频中固有的变化规律。差分散度正则化(differential divergence regularization)是预测帧与其对应的真实帧之间的Kullback-Leibler(KL)散度。具体而言,它是预测帧差分和真实帧差分之间的KL散度。
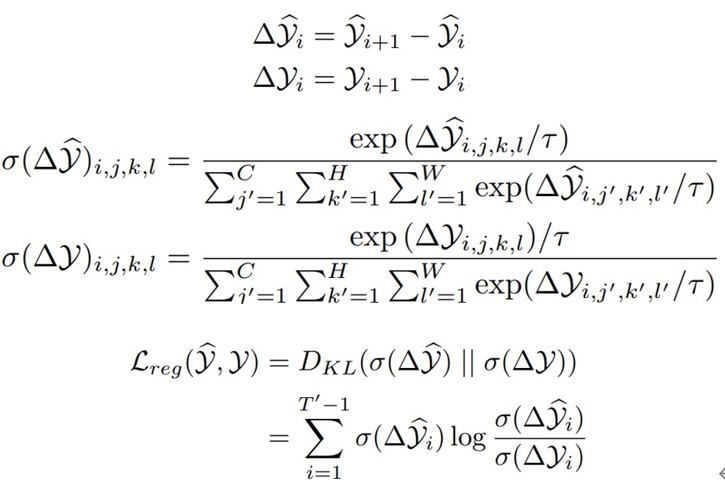
τ 代表温度参数,经验性地将其设置为0.1以增强概率分布的差异。直观来说,均方误差损失(MSE)仅考虑帧内误差,而差分散度正则化克服了这一缺点,迫使模型学习连续帧之间的差异并意识到固有的变化,以改善模型的预测。
因此目标损失函数:
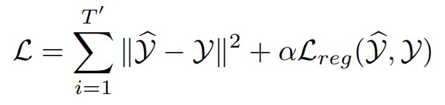
实验
Moving MNIST
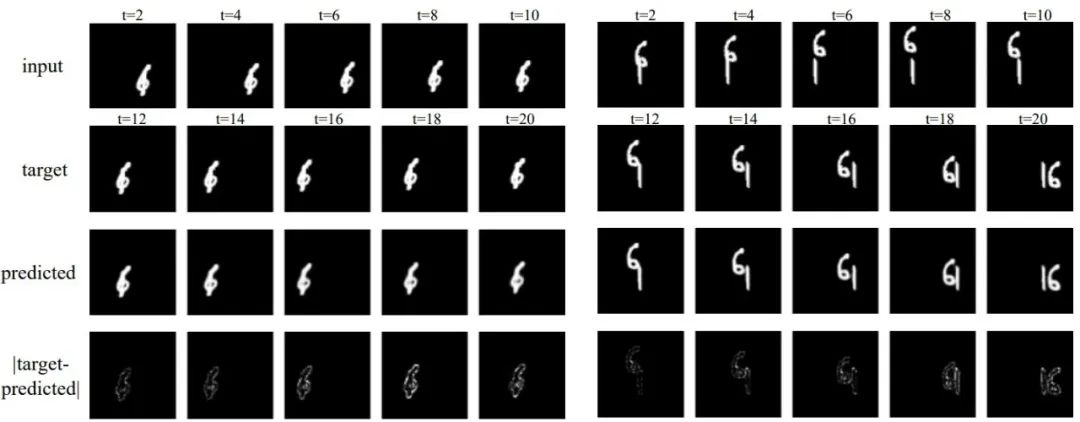
下图是在Moving MNIST上测试的两个实例,对于随机运动的数字,预测与目标的绝对差异很细微,说明TAU能很好地处理时空预测:
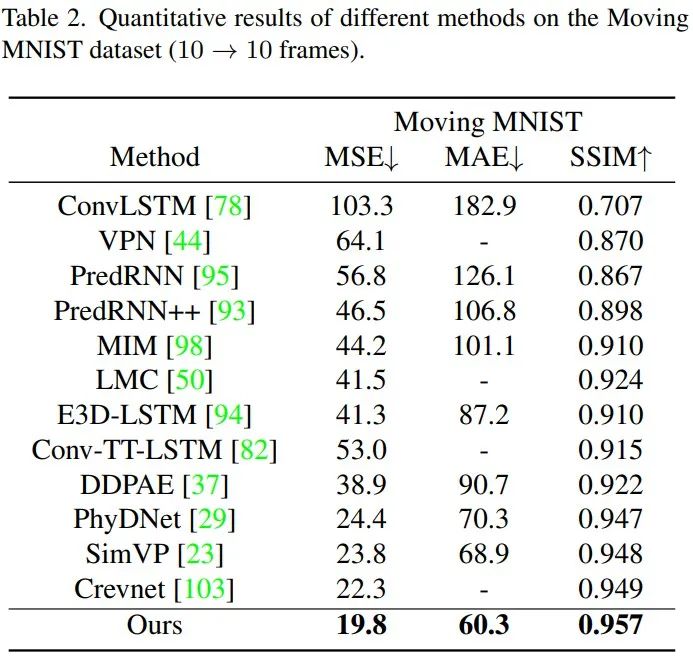
相对于SOTA的循环模型,TAU的性能增益是较大的,在三个度量指标下,TAU的表现都超越了其他方法:
TaxiBJ
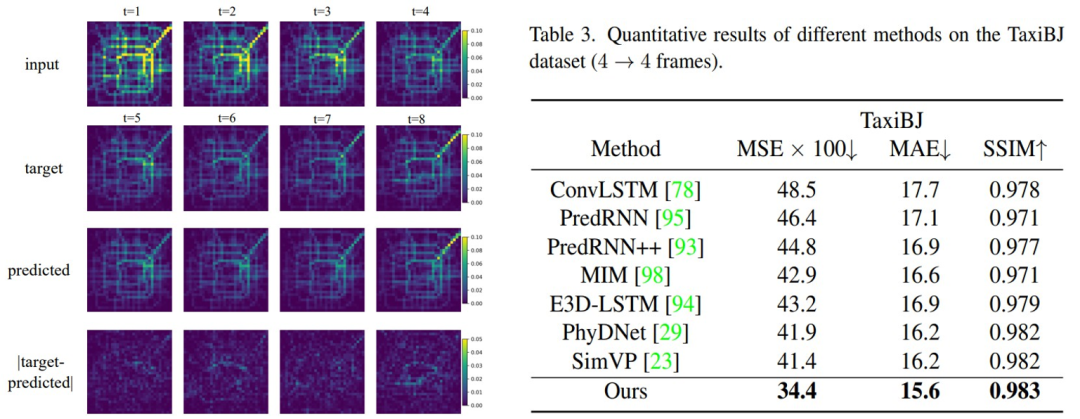
在真实复杂环境的交通流量数据集上,TAU具有良好的表现:
不同数据的泛化
为了检验模型的泛化能力,我们先在KITTI原始数据上进行训练,接着使用Caltech dataset进行评估,评估时输入前十帧预测下一帧。

灵活长度的预测
我们的模型可以通过模仿RNN,将预测的帧作为输入并递归产生预测来处理灵活长度的预测。对于KTH数据集,人体运动预测任务的难点不仅在于预测帧的灵活长度,还在于涉及人类意识随机性的复杂动力学,这增加了任务的困难程度。TAU可以从给定的10帧中预测接下来的20或40帧,也有出色的表现。
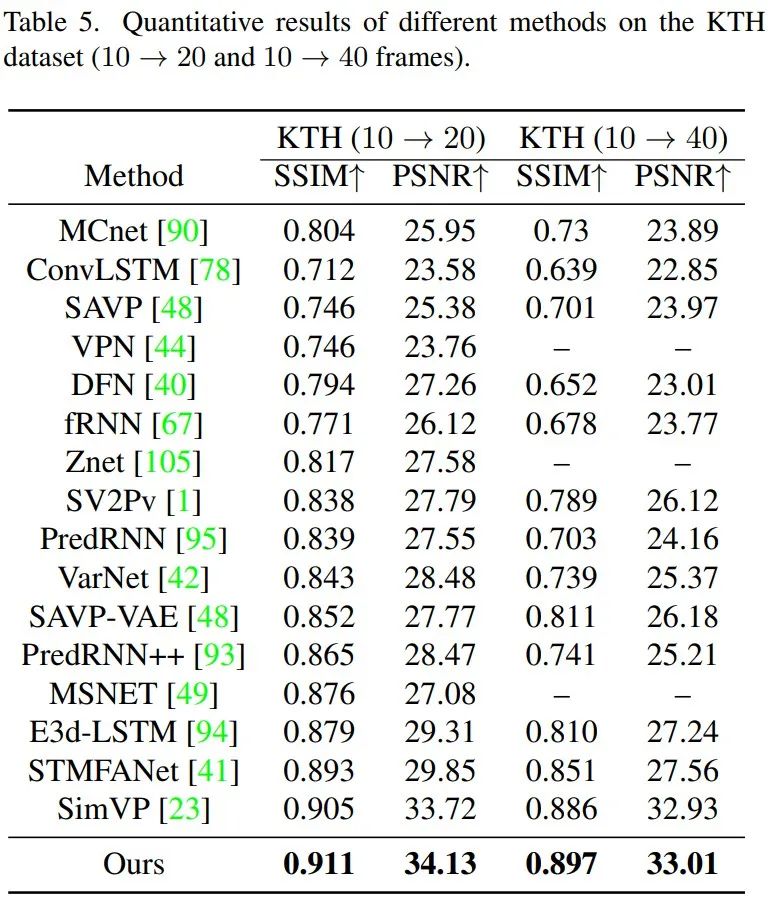
运行效率
此外,我们的模型不仅可以提高视频生成质量,还可以提高计算效率和训练速度。如下图所示,收敛速度极快,50轮训练即可达到MSE 35.0的水准。在相同实验环境下,TAU模型在基准数据集上每个周期只需要2.5分钟,而此前的SOTA方法需要7到30分钟不等。
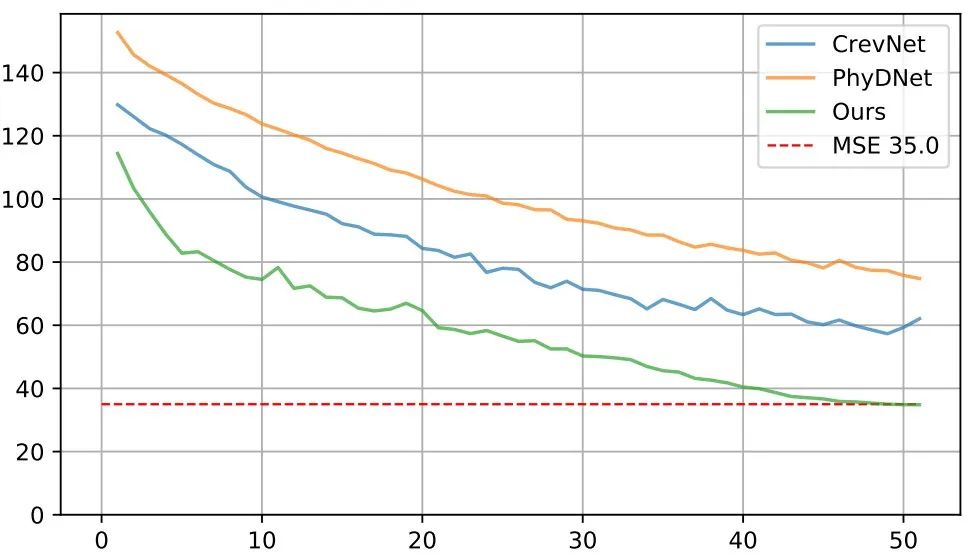
总结
本文提出了一个通用的时空预测学习框架,使用基于静态和动态结合的时间注意力模块替代循环单元,还引入了差分散度正则化方法来解决仅考虑帧内误差的MSE损失的问题,为高效的时空预测学习提供了新的范式。
编辑:黄飞
- 相关推荐
- 热点推荐
- 神经网络
-
基于全局预测历史的gshare分支预测器的实现细节2025-10-22 393
-
Labview如何实现预测2016-05-03 2968
-
矿山地质灾害3种超前预测技术2018-12-26 2650
-
集成学习之工业蒸汽量预测2021-07-07 1155
-
深度学习在预测和健康管理中的应用2021-07-12 1981
-
使用keras搭建神经网络实现基于深度学习算法的股票价格预测2022-02-08 1888
-
基于机器学习的车位状态预测方法2023-09-21 663
-
如何实现高速公路大数据的短时流量预测方法2020-07-27 1386
-
一种用于交通流预测的深度学习框架2021-04-14 1368
-
基于时空特性的ST-LSTM网络位置预测模型2021-06-11 1449
-
基于预测分析的时空众包在线任务分配算法2021-06-27 903
-
基于时空相关属性模型的公交到站时间预测算法2022-02-28 1504
-
时空图神经网络预测学习应用解析2023-05-11 4922
-
一个通用的时空预测学习框架2023-06-19 3029
-
PVT++:通用的端对端预测性跟踪框架2023-07-30 3193
全部0条评论

快来发表一下你的评论吧 !
