

深度解析数据中心的通讯连接方式
移动通信
描述
1. 网络的价值在于延续了集群算力摩尔定律
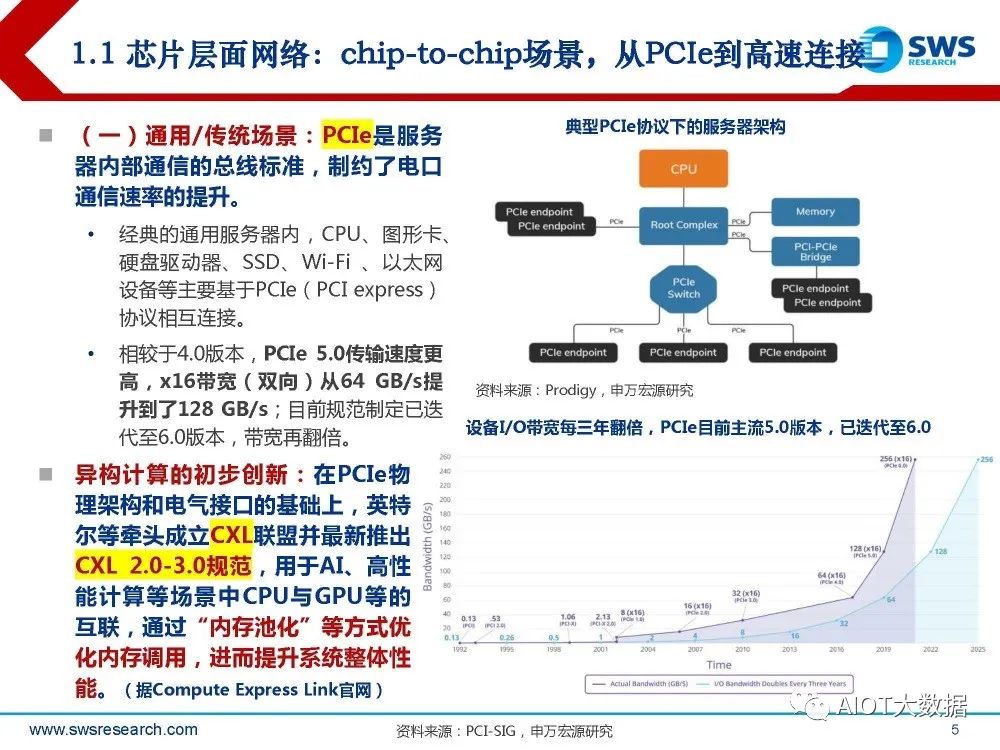
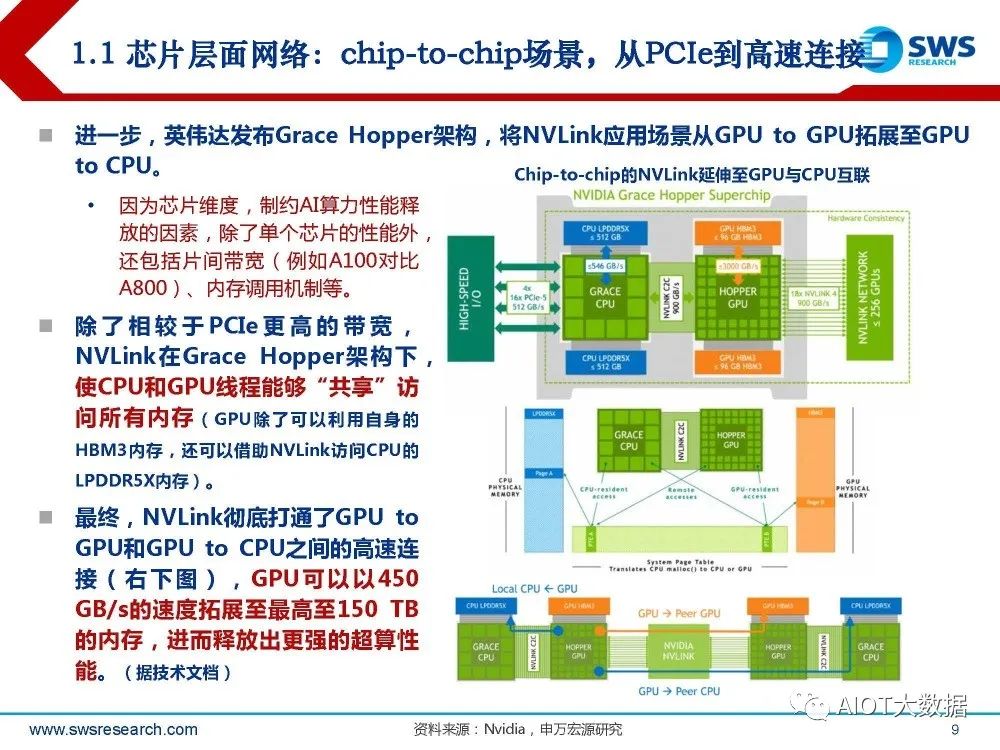
芯片层面网络:chip-to-chip场景,从PCIe到高速连接
(一)通用/传统场景:PCIe是服务 器内部通信的总线标准,制约了电口 通信速率的提升。 经典的通用服务器内,CPU、图形卡、 硬盘驱动器、SSD、Wi-Fi 、以太网 设备等主要基于PCIe(PCI express) 协议相互连接。 相较于4.0版本,PCIe 5.0传输速度更 高,x16带宽(双向)从64 GB/s提 升到了128 GB/s;目前规范制定已迭 代至6.0版本,带宽再翻倍。
异构计算的初步创新:在PCIe物 理架构和电气接口的基础上,英特 尔等牵头成立CXL联盟并最新推出 CXL 2.0-3.0规范,用于AI、高性 能计算等场景中CPU与GPU等的 互联,通过“内存池化”等方式优 化内存调用,进而提升系统整体性 能。
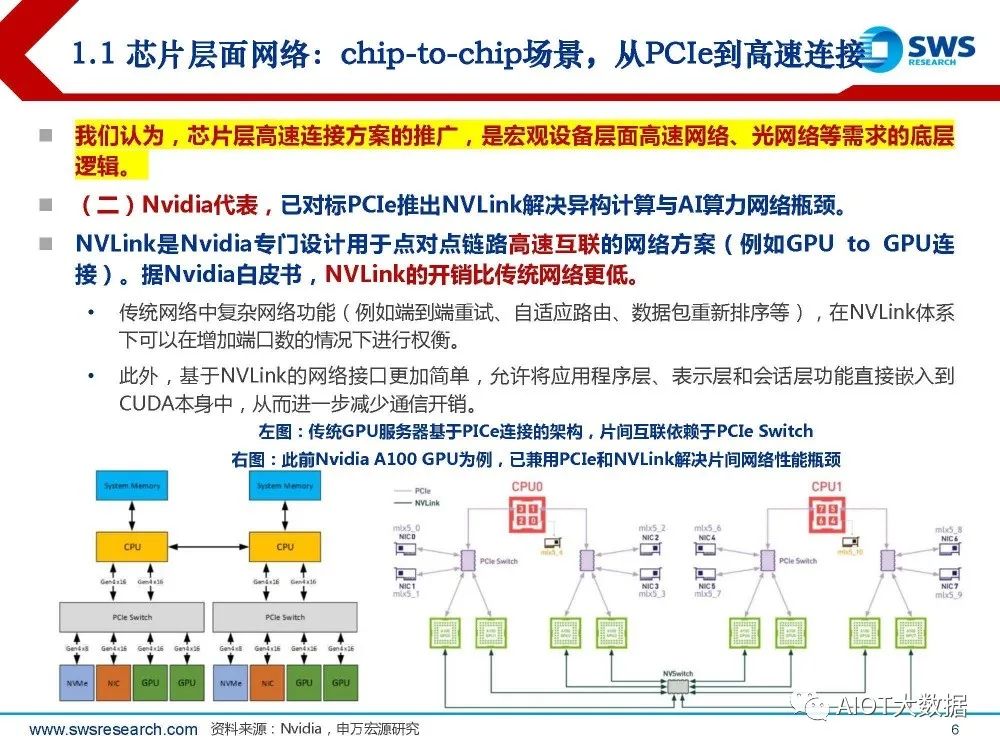
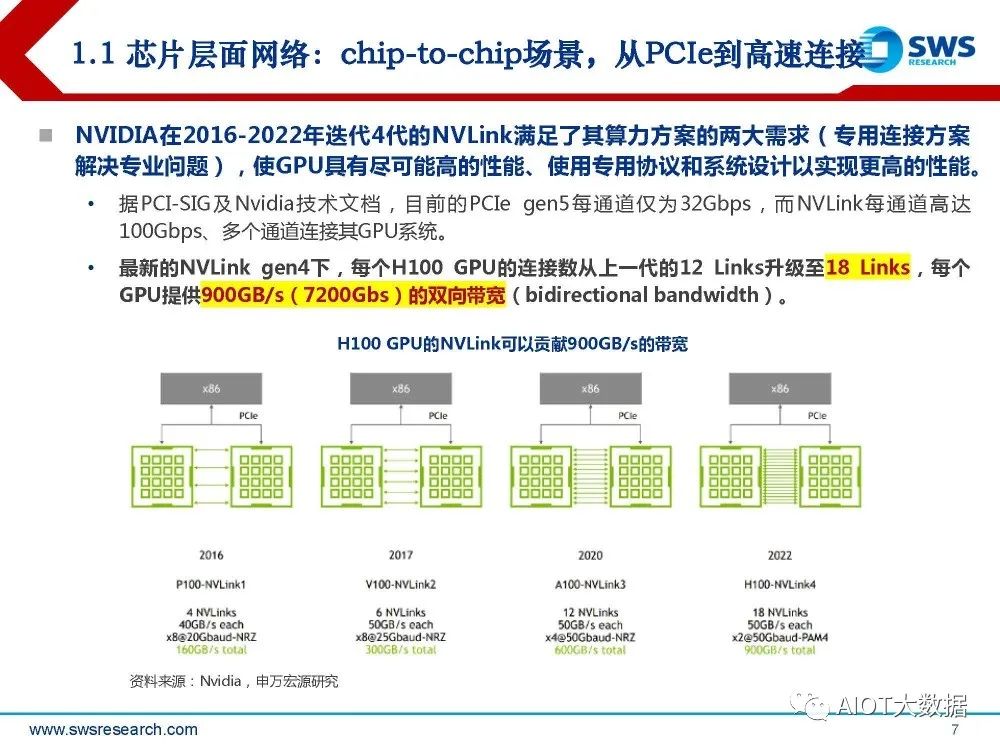
(二)Nvidia代表,已对标PCIe推出NVLink解决异构计算与AI算力网络瓶颈。 NVLink是Nvidia专门设计用于点对点链路高速互联的网络方案(例如GPU to GPU连 接)。据Nvidia白皮书,NVLink的开销比传统网络更低。 传统网络中复杂网络功能(例如端到端重试、自适应路由、数据包重新排序等),在NVLink体系 下可以在增加端口数的情况下进行权衡。 此外,基于NVLink的网络接口更加简单,允许将应用程序层、表示层和会话层功能直接嵌入到 CUDA本身中,从而进一步减少通信开销。
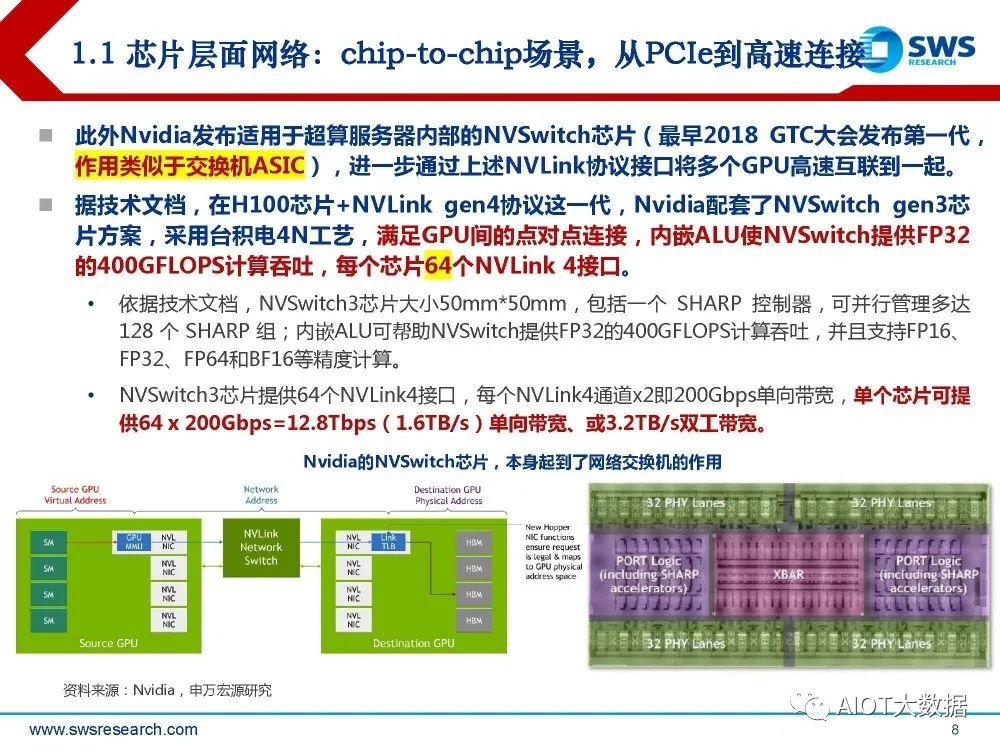
此外Nvidia发布适用于超算服务器内部的NVSwitch芯片(最早2018 GTC大会发布第一代, 作用类似于交换机ASIC),进一步通过上述NVLink协议接口将多个GPU高速互联到一起。 据技术文档,在H100芯片+NVLink gen4协议这一代,Nvidia配套了NVSwitch gen3芯 片方案,采用台积电4N工艺,满足GPU间的点对点连接,内嵌ALU使NVSwitch提供FP32 的400GFLOPS计算吞吐,每个芯片64个NVLink 4接口。 依据技术文档,NVSwitch3芯片大小50mm*50mm,包括一个 SHARP 控制器,可并行管理多达 128 个 SHARP 组;内嵌ALU可帮助NVSwitch提供FP32的400GFLOPS计算吞吐,并且支持FP16、 FP32、FP64和BF16等精度计算。 NVSwitch3芯片提供64个NVLink4接口,每个NVLink4通道x2即200Gbps单向带宽,单个芯片可提 供64 x 200Gbps=12.8Tbps(1.6TB/s)单向带宽、或3.2TB/s双工带宽。
设备层面网络:InfiniBand、NVLink等正迭代通用 算力下的以太网需求
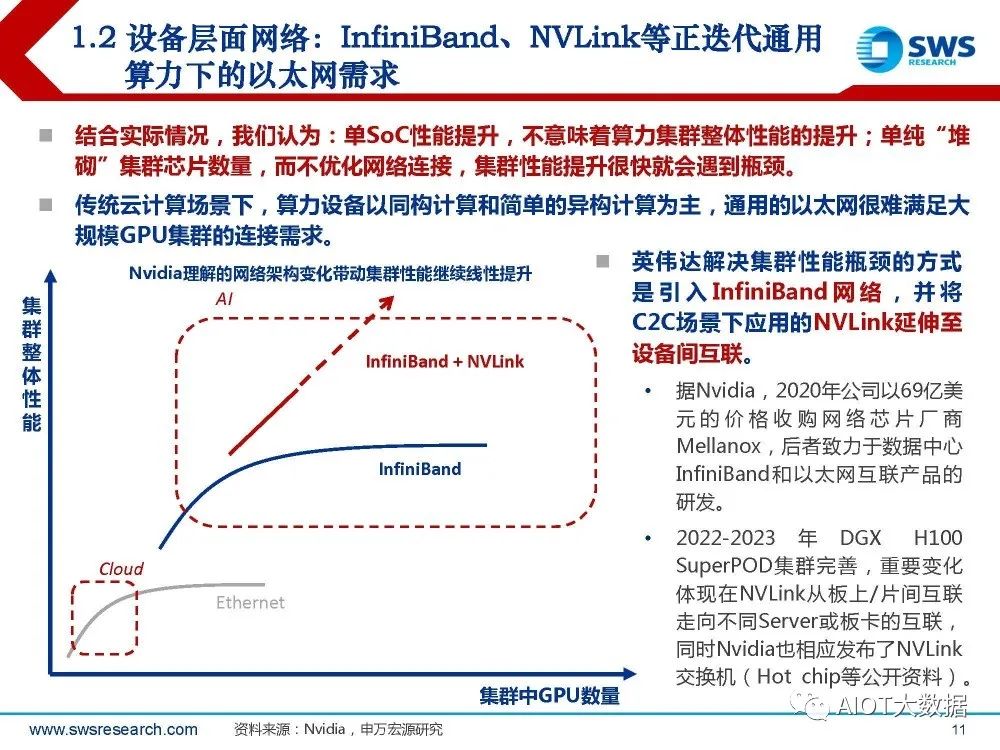
结合实际情况,我们认为:单SoC性能提升,不意味着算力集群整体性能的提升;单纯“堆 砌”集群芯片数量,而不优化网络连接,集群性能提升很快就会遇到瓶颈。 传统云计算场景下,算力设备以同构计算和简单的异构计算为主,通用的以太网很难满足大 规模GPU集群的连接需求。
英伟达解决集群性能瓶颈的方式 是引入 InfiniBand 网 络 , 并 将 C2C场景下应用的NVLink延伸至 设备间互联。据Nvidia,2020年公司以69亿美 元 的 价 格 收 购 网 络 芯 片 厂 商 Mellanox,后者致力于数据中心 InfiniBand和以太网互联产品的 研发。 2022-2023 年 DGX H100 SuperPOD集群完善,重要变化 体现在NVLink从板上/片间互联 走向不同Server或板卡的互联, 同时Nvidia也相应发布了NVLink 交换机(Hot chip等公开资料)。
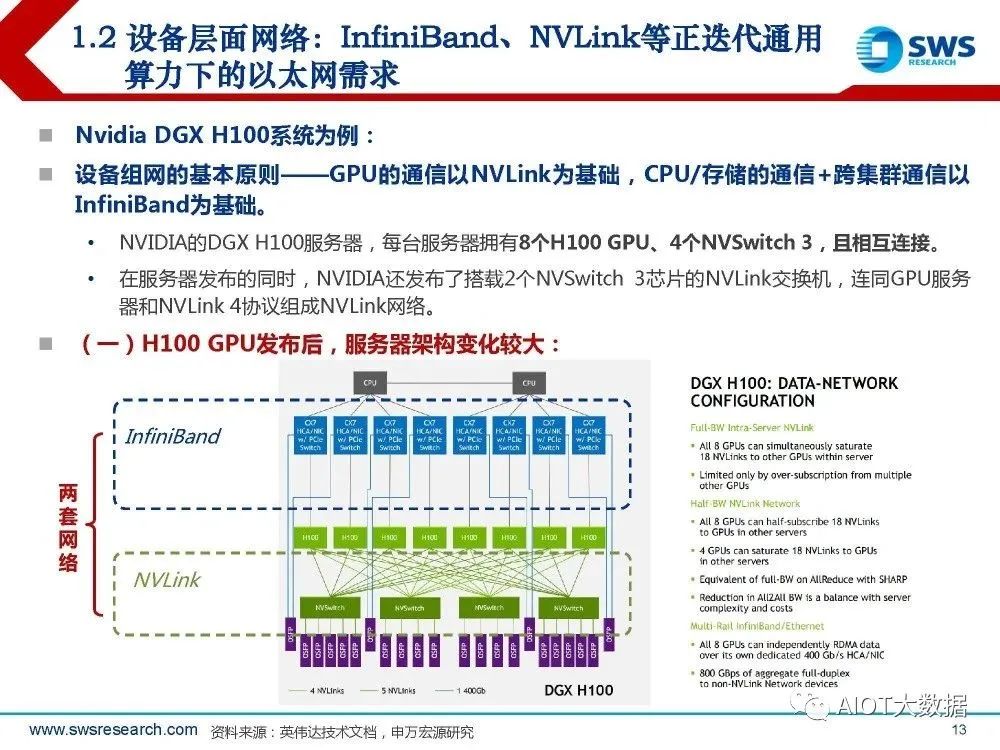
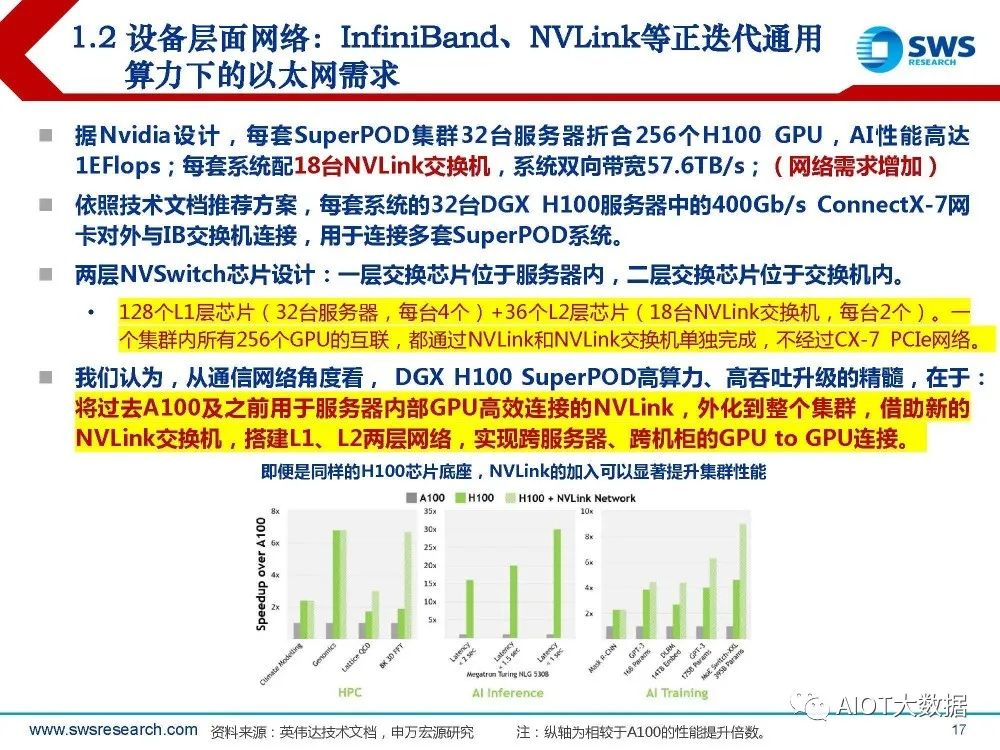
据Nvidia设计,每套SuperPOD集群32台服务器折合256个H100 GPU,AI性能高达 1EFlops;每套系统配18台NVLink交换机,系统双向带宽57.6TB/s;(网络需求增加) 。依照技术文档推荐方案,每套系统的32台DGX H100服务器中的400Gb/s ConnectX-7网 卡对外与IB交换机连接,用于连接多套SuperPOD系统。 两层NVSwitch芯片设计:一层交换芯片位于服务器内,二层交换芯片位于交换机内。128个L1层芯片(32台服务器,每台4个)+36个L2层芯片(18台NVLink交换机,每台2个)。一 个集群内所有256个GPU的互联,都通过NVLink和NVLink交换机单独完成,不经过CX-7 PCIe网络。 我们认为,从通信网络角度看, DGX H100 SuperPOD高算力、高吞吐升级的精髓,在于: 将过去A100及之前用于服务器内部GPU高效连接的NVLink,外化到整个集群,借助新的 NVLink交换机,搭建L1、L2两层网络,实现跨服务器、跨机柜的GPU to GPU连接。
IDC层面网络:AI与通用云计算架构核心差异在于组网
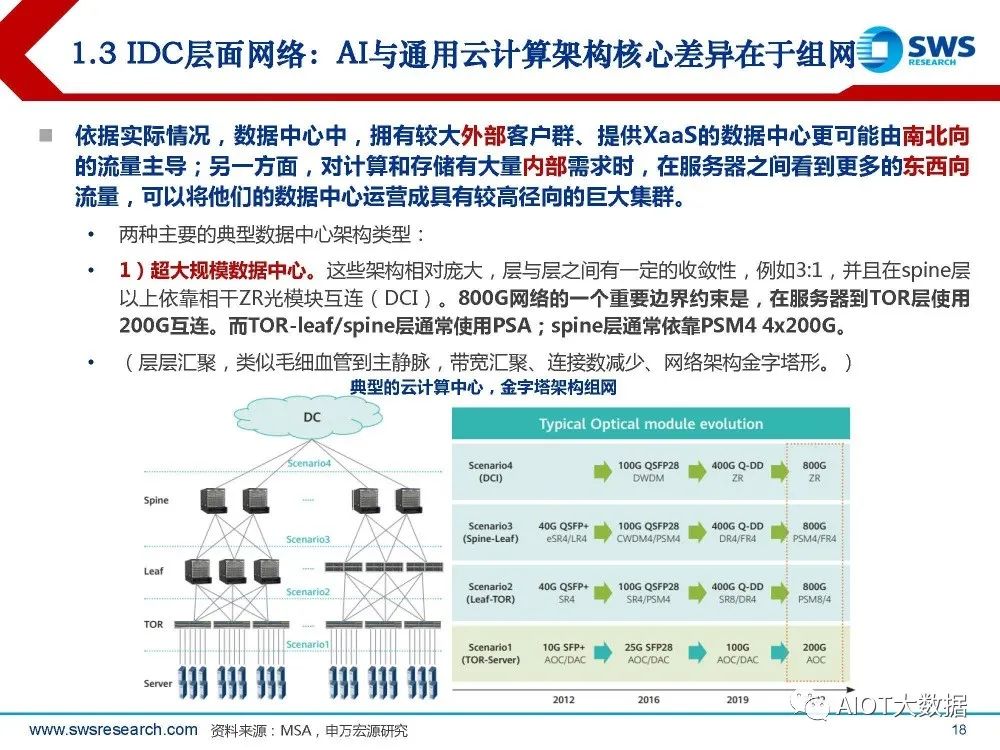
依据实际情况,数据中心中,拥有较大外部客户群、提供XaaS的数据中心更可能由南北向 的流量主导;另一方面,对计算和存储有大量内部需求时,在服务器之间看到更多的东西向 流量,可以将他们的数据中心运营成具有较高径向的巨大集群。 两种主要的典型数据中心架构类型: 1)超大规模数据中心。这些架构相对庞大,层与层之间有一定的收敛性,例如3:1,并且在spine层 以上依靠相干ZR光模块互连(DCI)。800G网络的一个重要边界约束是,在服务器到TOR层使用 200G互连。而TOR-leaf/spine层通常使用PSA;spine层通常依靠PSM4 4x200G。 (层层汇聚,类似毛细血管到主静脉,带宽汇聚、连接数减少、网络架构金字塔形。)
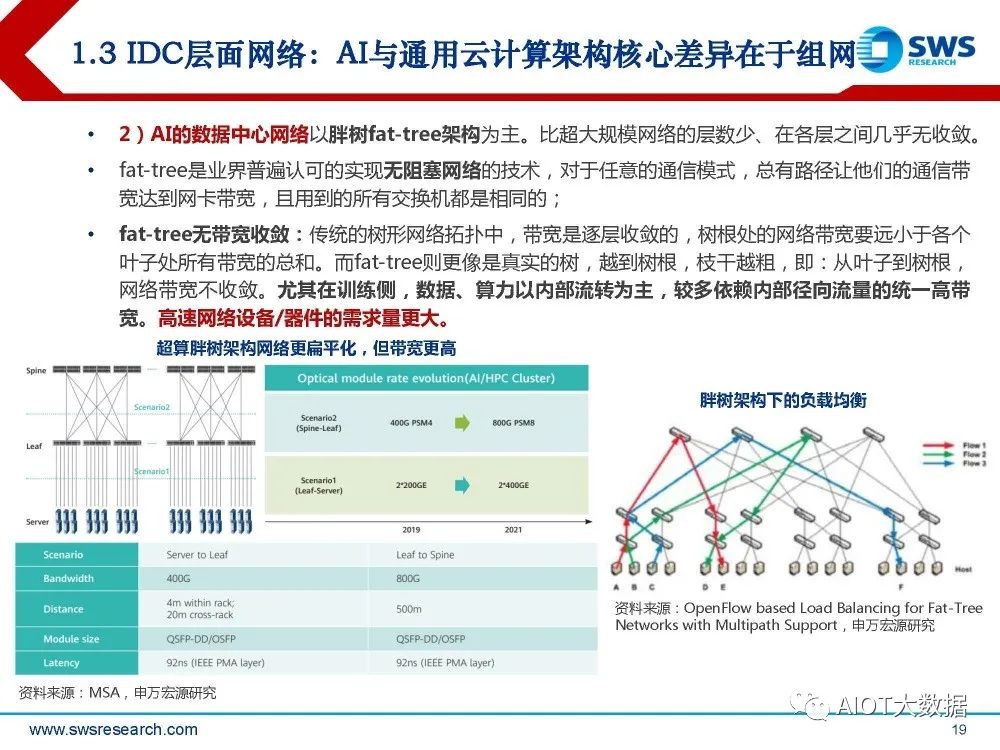
2)AI的数据中心网络以胖树fat-tree架构为主。比超大规模网络的层数少、在各层之间几乎无收敛。 fat-tree是业界普遍认可的实现无阻塞网络的技术,对于任意的通信模式,总有路径让他们的通信带 宽达到网卡带宽,且用到的所有交换机都是相同的;fat-tree无带宽收敛:传统的树形网络拓扑中,带宽是逐层收敛的,树根处的网络带宽要远小于各个 叶子处所有带宽的总和。而fat-tree则更像是真实的树,越到树根,枝干越粗,即:从叶子到树根, 网络带宽不收敛。尤其在训练侧,数据、算力以内部流转为主,较多依赖内部径向流量的统一高带 宽。高速网络设备/器件的需求量更大。
2. Nvidia:H100到GH200,网络价值陡增
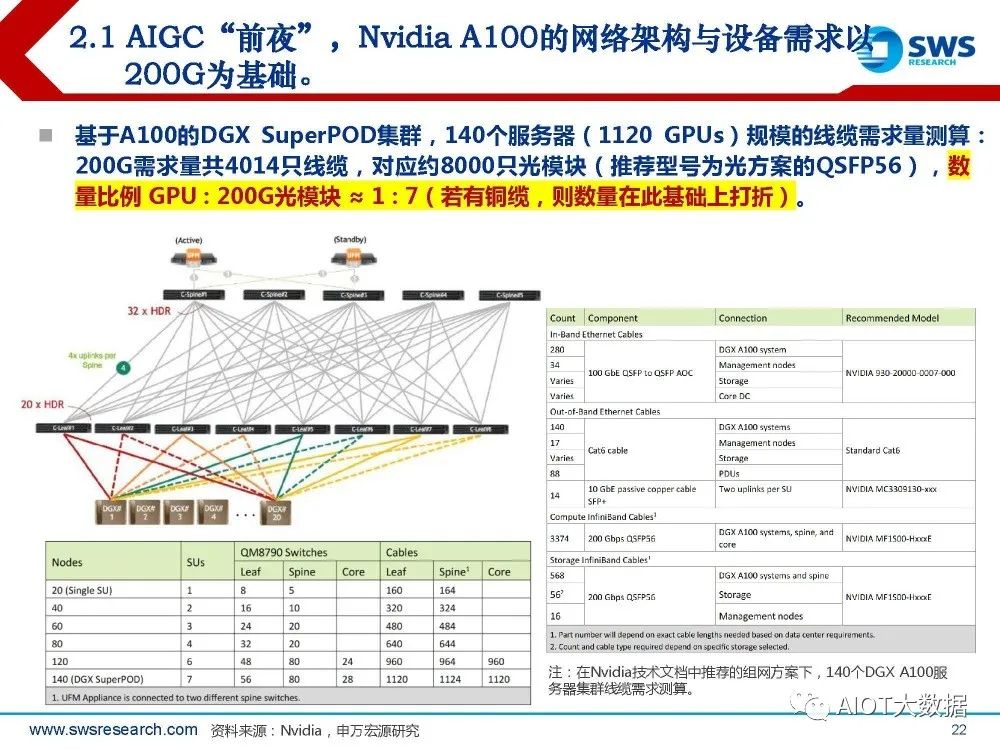
AIGC“前夜”,Nvidia A100的网络架构与设备需求以 200G为基础。
Nvidia的A100体系是典型的200G网络结构。 DGX A100的核心网卡Mellanox ConnectX-6主要基于200Gb/s HDR InfiniBand网络。因此底层 网络带宽即200G。DGX A100服务器背板明确拥有8个用于Compute的200G QSFP56接口。另外 拥有2个用于Storage的接口。 据技术文档,A100的DGX SuperPOD集群,服务器与交换设备数量之比大致在1 : 1左右。 A100 SuperPOD设计单集群20台DGX A100,搭配12台用于Compute的IB交换机以及6 台用于Storage的IB交换机(IB交换机QM8790为40 ports x 200 Gb规格)。
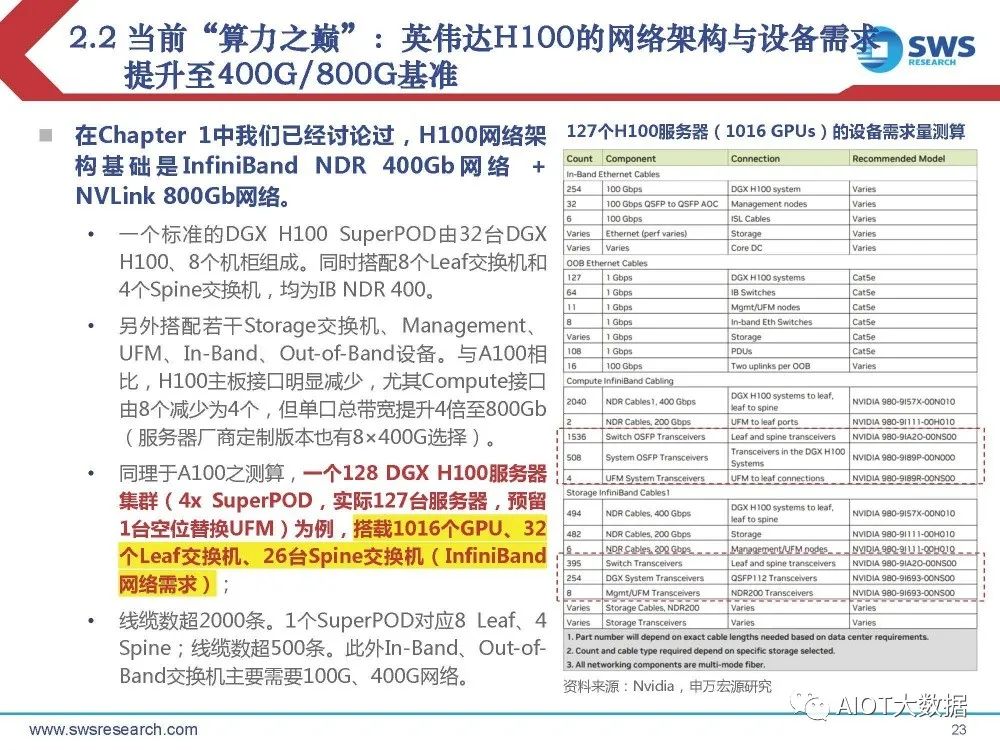
当前“算力之巅”:英伟达H100的网络架构与设备需求 提升至400G/800G基准
在Chapter 1中我们已经讨论过,H100网络架 构基础是 InfiniBand NDR 400Gb 网 络 + NVLink 800Gb网络。 一个标准的DGX H100 SuperPOD由32台DGX H100、8个机柜组成。同时搭配8个Leaf交换机和 4个Spine交换机,均为IB NDR 400。 另外搭配若干Storage交换机、Management、 UFM、In-Band、Out-of-Band设备。与A100相 比,H100主板接口明显减少,尤其Compute接口 由8个减少为4个,但单口总带宽提升4倍至800Gb (服务器厂商定制版本也有8×400G选择)。 同理于A100之测算,一个128 DGX H100服务器 集群(4x SuperPOD,实际127台服务器,预留 1台空位替换UFM)为例,搭载1016个GPU、32 个Leaf交换机、26台Spine交换机(InfiniBand 网络需求); 线缆数超2000条。1个SuperPOD对应8 Leaf、4 Spine;线缆数超500条。此外In-Band、Out-ofBand交换机主要需要100G、400G网络。
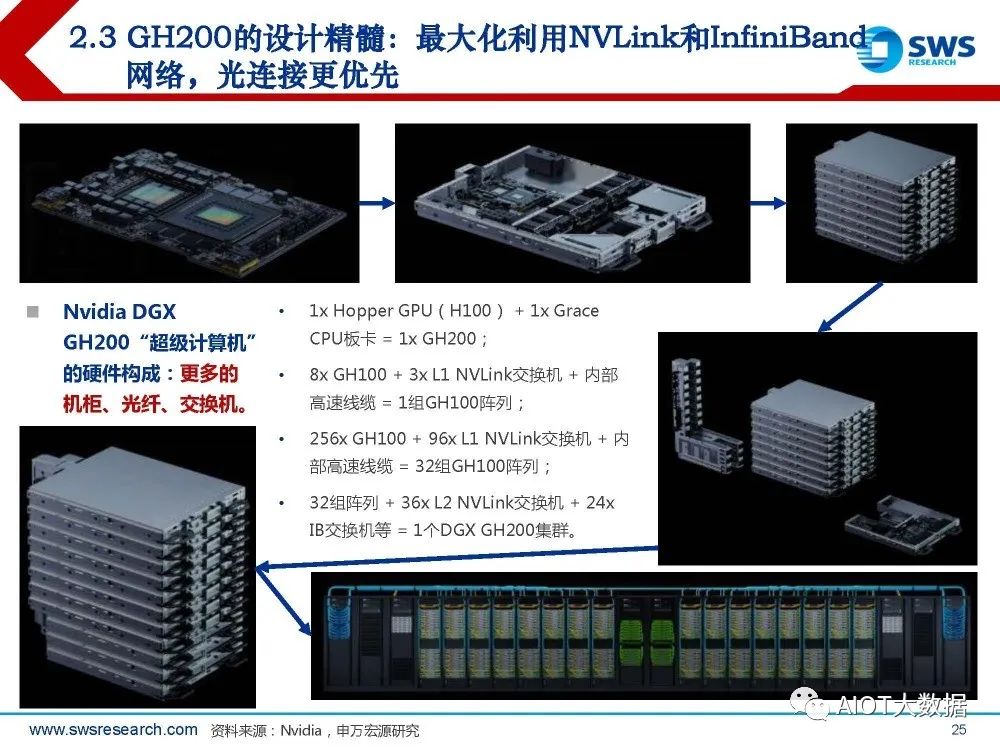
GH200的设计精髓:最大化利用NVLink和InfiniBand 网络,光连接更优先
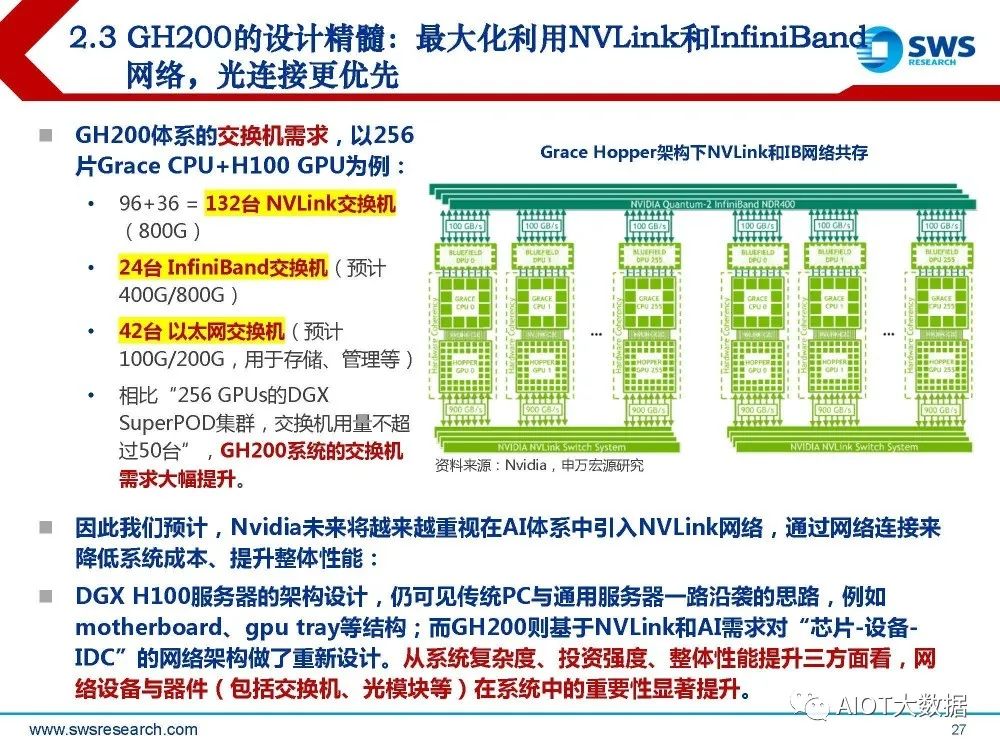
GH200体系的交换机需求,以256 片Grace CPU+H100 GPU为例: 96+36 = 132台 NVLink交换机 (800G) ;24台 InfiniBand交换机(预计 400G/800G) ;42台 以太网交换机(预计 100G/200G,用于存储、管理等); 相比“256 GPUs的DGX SuperPOD集群,交换机用量不超 过50台”,GH200系统的交换机 需求大幅提升。
因此我们预计,Nvidia未来将越来越重视在AI体系中引入NVLink网络,通过网络连接来 降低系统成本、提升整体性能: DGX H100服务器的架构设计,仍可见传统PC与通用服务器一路沿袭的思路,例如 motherboard、gpu tray等结构;而GH200则基于NVLink和AI需求对“芯片-设备IDC”的网络架构做了重新设计。从系统复杂度、投资强度、整体性能提升三方面看,网 络设备与器件(包括交换机、光模块等)在系统中的重要性显著提升。
3. 谷歌:TPU v4背后,是OCS与更激进的光 网络设计
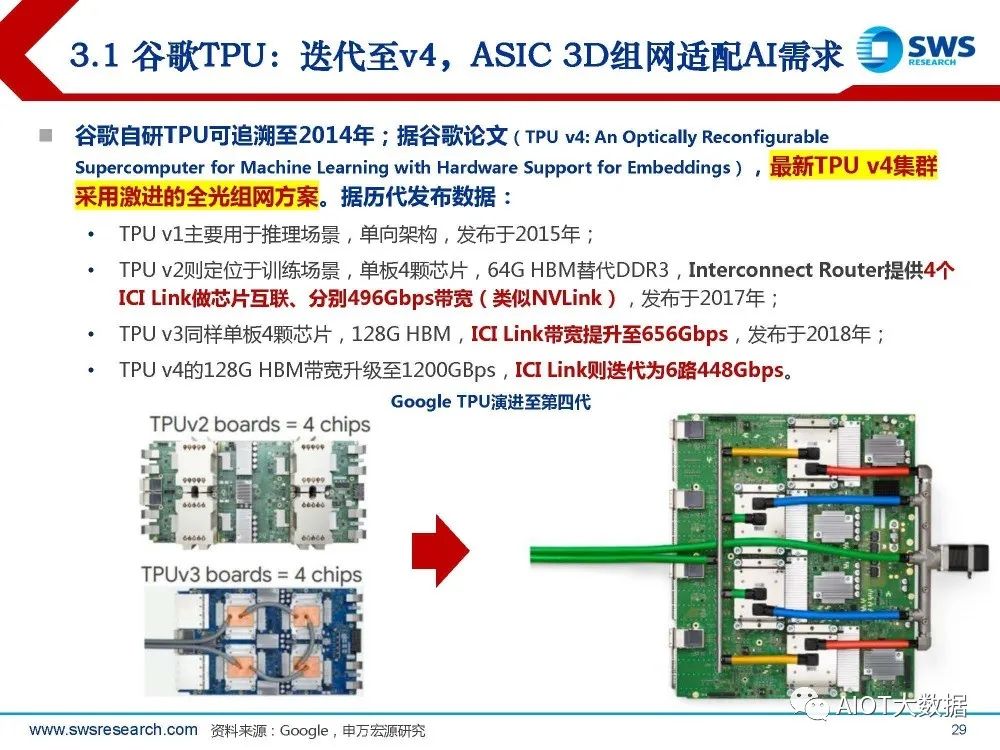
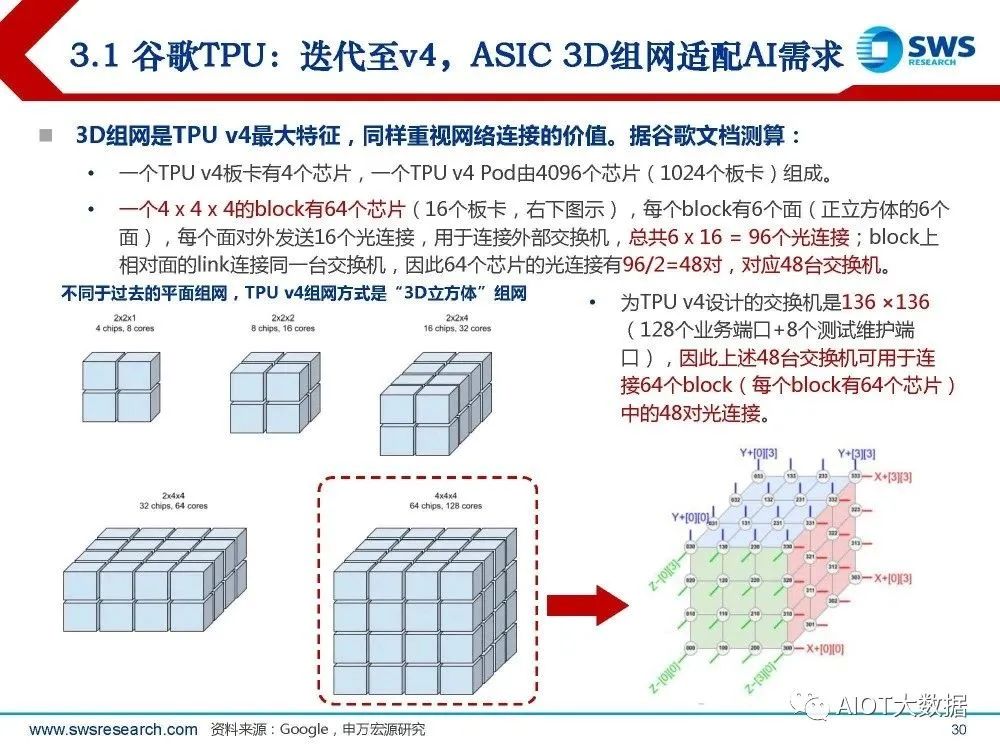
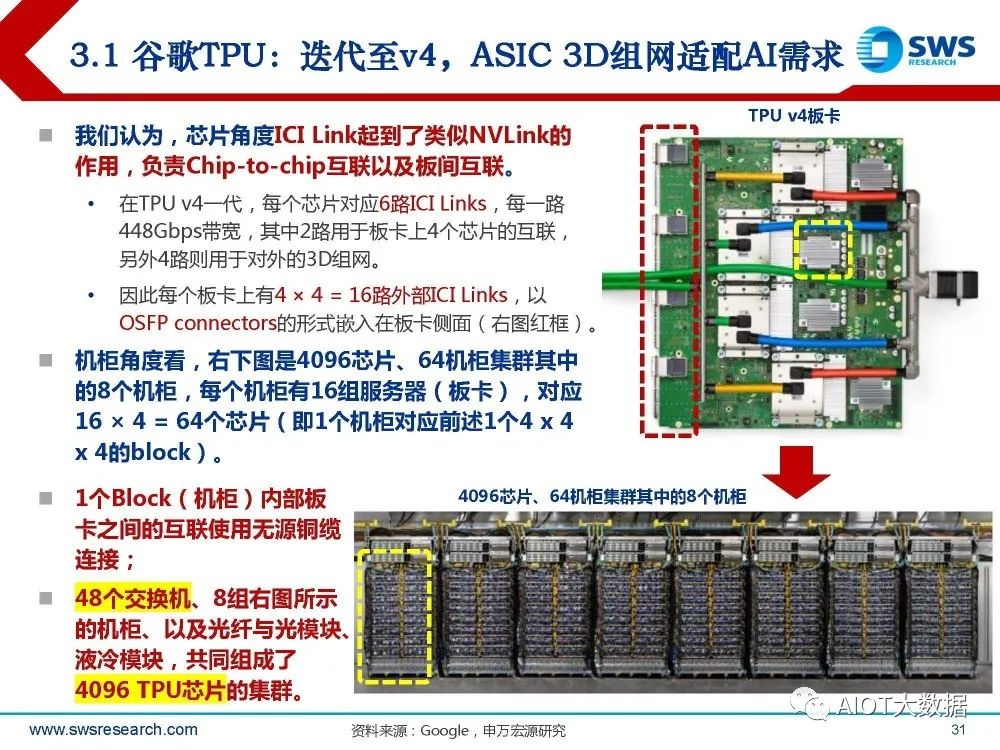
谷歌TPU:迭代至v4,ASIC 3D组网适配AI需求
谷歌自研TPU可追溯至2014年;据谷歌论文(TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings),最新TPU v4集群 采用激进的全光组网方案。据历代发布数据: TPU v1主要用于推理场景,单向架构,发布于2015年; TPU v2则定位于训练场景,单板4颗芯片,64G HBM替代DDR3,Interconnect Router提供4个 ICI Link做芯片互联、分别496Gbps带宽(类似NVLink),发布于2017年; TPU v3同样单板4颗芯片,128G HBM,ICI Link带宽提升至656Gbps,发布于2018年; TPU v4的128G HBM带宽升级至1200GBps,ICI Link则迭代为6路448Gbps。
谷歌OCS:全光交换、WDM等光通信技术,算力 与网络同行
OCS即Optical circuit switches,是谷歌TPU v4网络连接的核心交换机。 通常数据中心内数据交换是光电混合网络,设备之间的主要互联通过光缆/铜缆/光电转换 器件、以及交换机ASIC/Serdes/PCIE/NVLink等链路实现。 与过去在网络层之间多次将信号“从电转换为光再到电”不同,OCS是一种全光学的连接 方案,通过MEMS阵列结合光环路器、波分复用光模块实现光路的灵活切换、以达到直接 通过光信号组建交换网络的目的。
4. AMD、Amazon等:芯片亦持续迭代
AMD:MI300系列2.5D-3D封装,板上带宽显著增加
据AMD发布会,MI300系列方案内存 容量与带宽显著提升:MI300X拥有192GB的HBM3、 5.2TBps的带宽和896GBps的Infinity Fabric带宽; AMD Infinity 架构将 8 个MI300X 加 速器连接在一个系统中,提供合计1.5 TB的HBM3内存。
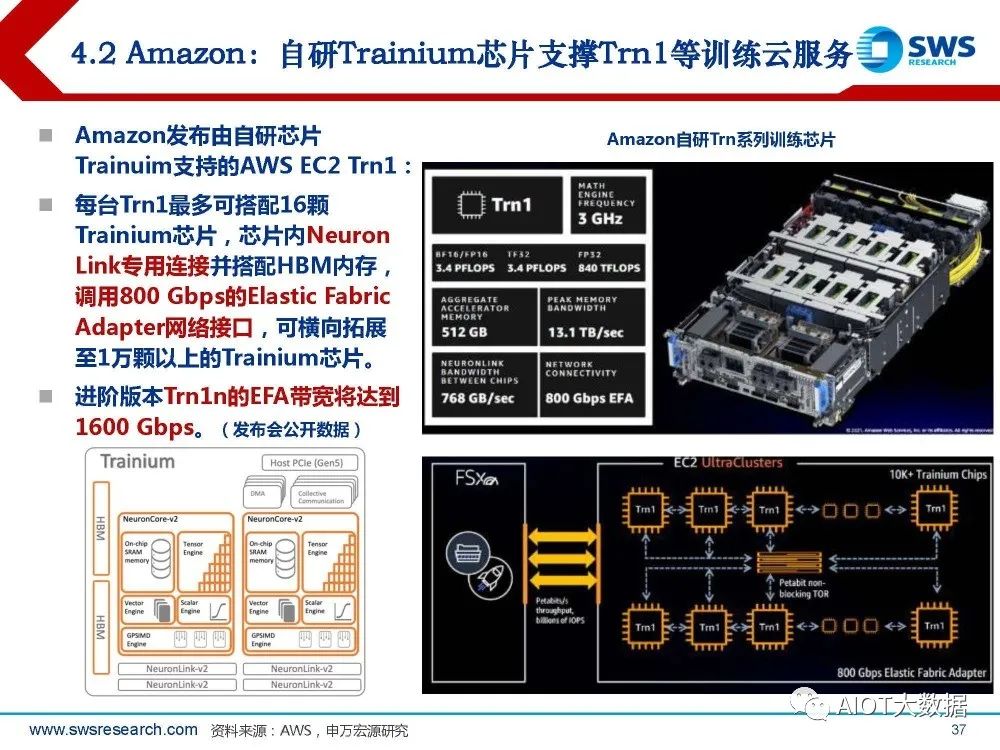
Amazon:自研Trainium芯片支撑Trn1等训练云服务
Amazon发布由自研芯片 Trainuim支持的AWS EC2 Trn1: 每台Trn1最多可搭配16颗 Trainium芯片,芯片内Neuron Link专用连接并搭配HBM内存, 调用800 Gbps的Elastic Fabric Adapter网络接口,可横向拓展 至1万颗以上的Trainium芯片。 进阶版本Trn1n的EFA带宽将达到 1600 Gbps。
5. 结论
结合上文: 1)系统复杂度、投资强度、整体性能提升效果三方面看,网络设备与器件(包括交换机、光模块等)在 AI系统中的重要性显著提升:Nvidia H100到GH200系统,官方标准配置下800G光模块用量可提升 30%-275%,同样256GPU集群的交换机需求从不足50台提升至150台以上。 2)谷歌自研TPU v4背后,是矩阵计算、OCS光交换与更激进的光网络设计。3D组网是TPU v4系统最 大亮点,网络起重要作用,导入全光交换、WDM等光通信技术后,算力与网络需求同步提升。 3)AMD最新MI300体系和AWS自研Trn训练芯片,同样重视带宽、拓展性的价值。
我们认为: 在AI领域,网络的价值在于延续了集群算力的摩尔定律。 1)吞吐带宽与连接架构是算力性能不可忽视的决定因素。 2)芯片层面,高速c2c连接方案(如NVLink、CXL等)的推广,是宏观设备/数据中心层高速网络、光 网络等需求爆发的底层逻辑。 3)设备层面,单SoC性能提升+芯片“堆量”,不意味着算力集群整体性能的线性提升;而Nvidia、 Google、AMD、AWS等算力大厂正应用InfiniBand、OCS等新架构替代通用算力下的以太网,带来 增量网络需求。
报告节选:













编辑:黄飞
-
数据中心连接系统:灵活连接与高效供电2022-08-04 2505
-
什么是数据中心2021-09-15 2350
-
数据中心是什么2021-07-12 2172
-
数据中心太耗电怎么办2021-06-30 1793
-
CDMA无线数传模块数据中心的的固定IP连接方式及研究2021-06-10 3435
-
大数据和物联网是如何影响数据中心的?2021-05-21 1836
-
数据中心布线之有源光缆2020-08-22 2115
-
未来数据中心与光模块发展假设2020-08-07 3044
-
深度解析数据中心的核心 电量传感器2020-07-03 1509
-
数据中心的建设也看重风水2019-08-07 3211
-
易天重点解析监控系统在数据中心机房的重要性2018-10-09 2177
-
数据中心布线五大注意要点2016-07-21 13935
-
数据中心子系统的组成2011-11-11 5879
全部0条评论

快来发表一下你的评论吧 !
