

为保证数字电路时序裕量所做的努力
电子说
描述
由于以太网测试使用的开发板是淘宝购买的某款开发板,开发人员在电路设计时没有考虑到将以太网芯片的接收时钟、发送时钟通过FPGA的专用时钟管脚接入到到全局时钟网络;其实这对时序裕量有影响,按照官方的说法,经过全局时钟网络的信号其延时最小,驱动能力大;而且只有专用时钟管脚引入的信号才能接入到PLL;
这个千兆网芯片使用的是RGMII接口,收发时钟达到了125MHz,但是却没有经过专用时钟管脚进入全局时钟网络,为了保证能在125MHz时序下,电路能够稳定的跑通,我在时序裕量上做出了一些的努力。
参考该块开发板给出的例程
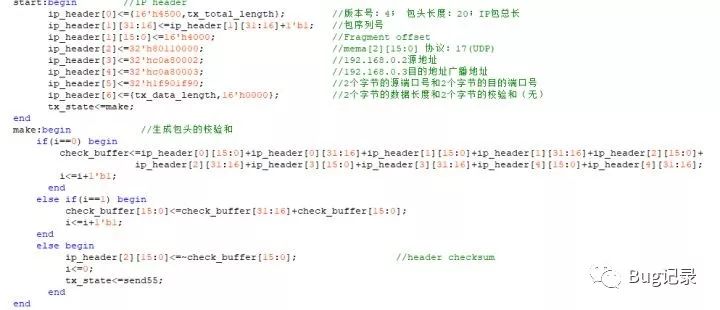
开发板所带例程的部分
这一部分是在生成IP数据包的首部,并且计算首部的校验和;
但是综合之后,可以从时序报告看到下图
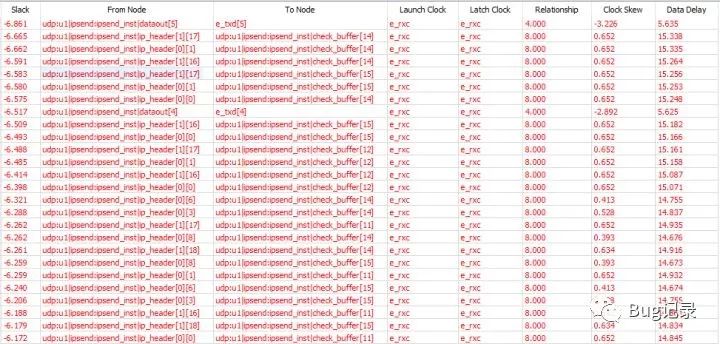
可以看到"ip_header"与"check_buffer"之间的有很多标红警告,这造成时序分析报告里面e_rxc(接收时钟)的max_frequency远远小于我们想要的125MHz;
为此,我修改了make状态,在计算check_buffer的过程中加入了多个寄存器,起到缓冲作用;如下图

原来10个16进制的1周期加法计算可能会造成大的延时,现在将10个16进制的加法计算拆分成3周期的加法计算,从时序报告看缓解了这部分的slack不足。
其实这里使用的是使用面积换取时间的方法,参考的例程里面由于需要在1个周期内计算过多的数据量造成太大的延时,所以这部分的时序不会太高,而我们在这个过程插入寄存器,分级计算,每个阶段的时序提高了,整体部分的时序也达到了设计要求;
这种做法是很多人推崇的FPGA设计中的流水线设计一个实例,其原理就相当于将一堆复杂的操作分割成几个简单的操作,增加了电路面积但是由于每个部分的操作相对简单,所以运行频率可以得到相对的提升。
其实我这里发现有进一步的改进方案,可以在以太网芯片发送8个前导码的同时,组成IP数据包头并计算checksum,这样的话checksum的计算是1周期还是3周期都不会影响发送流程的整体过程,修改的结果如下图:

第二个改进的地方如下图,例程中发送以太帧首部信息采用了下图这种方法;

这种写法看着很有C语言循环写法的风格,感觉并不好,而且这个部分的时序报告也不太好;我起初想到的修改方法是类似如下的方法:
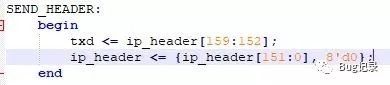
这个修改的方法的意图是这样的,在SEND_HEADER状态下,txd每次都发送ip_header的高八位,同时ip_header向左移动8位,在发送完ip_header后,状态机会跳出SEND_HEADER状态。
但是,可能ip_header宽度过大,每次做移位操作造成较大延时,这么修改仍有部分时序标红,于是我又做出了如下修改:

通过状态机和计数器的配合,解决了发送端口应该在什么时候发送什么信息,避免做判断和移位操作。
通过以上两个措施,解决了一部分的时序裕量不足的问题,但一波未平一波又起;在这个过程中在很多地方用了cnt寄存器作为计数器,于是时序报告中又产生了cnt寄存器与txd等信号的时序裕量不足的报告。
分析这个现象产生的原因,我们不难发现,在状态跳转,比如从发送MAC地址的状态跳转到发送IP首部信息的状态,就是使用计数器技术到某一数值作为跳转条件;而每次在状态机使用计数器和阈值作比较,由于cnt寄存器的宽度较大,在比较的过程中也有延时,在高速时钟下这点延时也会造成一定的影响。
又又又为了解决这个问题,采用了如下图的解决方案:


用wire类型的flagxx信号代替原来的"cnt >= xxx",看似没什么变化,但是原来的比较方案中,当电路运行到判断条件时,会进行多bit的比较,在时钟频率较高时,也会对时序电路有所影响;而使用flag单bit信号做判断之后,对时序电路的影响较小,时序电路的max_frequency可以有所提高。
由于接收时钟没有经专用时钟管脚引进;全局时钟信号驱动下,其他的物理输入输出信号延迟较小;而此处接收时钟被当做一个普通IO信号引入,可能会造成其他的物理输入输出信号相对时钟信号有较大延迟;又因为时钟信号在时序电路中是驱动其他信号工作,所以这个时钟信号(从普通IO口引入)的扇出一定很大,这也会造成一定的意料之外的延时。而这部分问题,我还没有找到一个很好的解决方法,可能时钟信号没有从专用时钟管脚引入就是一个错误,而我没找到解决它的好办法。
总结:
- 将计算量较大,较多,较复杂的地方分级处理,中间插入寄存器,这样可以提高时序裕量。
- 使用状态机代替循环和移位等操作。
- 避免多比特信号的判断比较,用单比特信号代替多比特信号的比较。
- FPGA的随路时钟要通过专用时钟管脚引入。
-
数字电路主要应掌握哪些概念2023-03-24 3135
-
数字电路设计的基本流程2022-07-10 10038
-
数字电路与逻辑设计电路的分析和方法2021-08-06 1713
-
时序在数字电路中的作用2021-08-02 2245
-
数字电路设计之同步时序逻辑电路2020-12-25 7018
-
数字电路教程之时序逻辑电路课件的详细资料免费下载2018-12-28 1432
-
新编数字电路与数字逻辑2018-10-28 3507
-
数字电路基础教程之时序逻辑电路的详细资料概述2018-10-17 1754
-
数字电路该怎么学_数字电路的学习方法(要点、注意事项)2018-03-23 36679
-
数字电路之时序电路2016-08-01 19865
-
优化高速接口的时序裕量2012-03-20 7876
-
同步时序数字电路的分析2008-10-20 971
全部0条评论

快来发表一下你的评论吧 !
