

全面介绍小目标检测的各种解决方案
人工智能
描述
作者丨CVHub 来源丨派派星
导读
本文将从小目标的定义、意义和挑战等方面入手,全面介绍小目标检测的各种解决方案。
导读
小目标检测是计算机视觉领域中的一个极具挑战性的问题。随着深度学习和计算机视觉领域的不断发展,越来越多的应用场景需要对小目标进行准确的检测和识别。本文将从小目标的定义、意义和挑战等方面入手,全面介绍小目标检测的各种解决方案。
定义
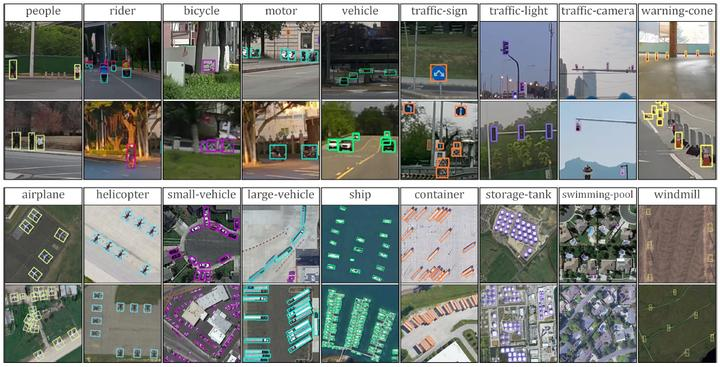
小目标检测广义是指在图像中检测和识别尺寸较小、面积较小的目标物体。通常来说,小目标的定义取决于具体的应用场景,但一般可以认为小目标是指尺寸小于 像素的物体,如下图 COCO 数据集的定义。当然,对于不同的任务和应用,小目标的尺寸和面积要求可能会有所不同。
在 COCO 数据集中,针对三种不同大小(small,medium,large)的图片提出了测量标准,其包含大约 41% 的小目标(area<32×32), 34% 的中等目标(32×32
意义
小目标检测的意义在于它可以提高技术的应用范围,同时可以帮助大家更好地理解图像中的细节信息。此外,小目标检测其实在我们日常生活中的许多领域均有广泛的应用,例如交通监控、医学影像分析、无人机航拍等。举个例子:
在交通监控领域,小目标检测可用于识别交通信号灯、车牌等。
在医学影像分析领域,小目标检测可用于识别微小的肿瘤细胞等。
在自动驾驶领域,小目标检测可用于识别微小的障碍物,以弥补激光雷达难以探测的窘况。
挑战
做过检测任务的同学应该很清楚这一点,那便是小目标检测其实一直是一个极具挑战性的问题。下面随便举几个小例子给大家感受下:
小目标通常在图像中占据很小的区域,深度学习算法其实很难提取到有效的信息,更别提传统的特征提取方法。举个例子,对于一个室内会议场景,假设我们的摄像头装在左上角的上方区域,如果此时你训练完一个检测模型应用上去,会观察到在远离镜头的对角线区域其检测效果相对其它区域来说一般会差很多的,特别容易造成漏检和误检。
小目标并不具备常规尺寸目标的纹理、颜色等丰富的细节特征,这使得小目标的检测更加困难,而且容易被模型误认为是“噪声点”。
小目标其实有时候不好定义,以最简单的行人和车辆为例,不妨看下面这张图片:
大致划分了下,其中绿色框范围的目标其实是很容易标注的,主要是红色方框范围内的目标。大部分目标像素占比很小,标也不是,不标也不是,当然你可以采用ignore标签不计算损失或者干脆直接将这块区域mask掉,但现实就是很多情况下这种“小目标”其实很大概率会被漏打标,太多的话很容易造成训练曲线“抖动”。
解决方案
今天,让我们重点来聊聊如何解决小目标检测的难题。大家应具备批判性思维,根据实际情况针对性的采取合适的方式。
需要注意的是,双阶段目标检测算法由于存在RoI Pooling之类的操作, 因此小目标的特征会被放大,其特征轮廓也更为清晰,因此检出率通常也会更高。但本文还是主要围绕发展比较成熟的单阶段目标检测算法展开。
增大输入图像分辨率
图像分辨率,当之无愧是最大的罪魁祸首,想象一下,一张图像如果分辨率太小,假设我们就下采样32倍,理论上小于这个像素的目标信息基本就会完全丢失。因此,当处理小目标检测时,由于目标物体尺寸过小,通常需要将输入图像的分辨率提高,以便更好地捕捉目标的细节。通过提升输入图像分辨率,可以提高小目标检测的准确性和召回率,从而更好地识别和跟踪目标物体。
增大模型输入尺寸
图像缩放是另一种常用的解决方案,同样可以提高小目标检测的精度。常见的做法便是直接开启“多尺度训练”,设置比较大的尺寸范围。不过,增大模型输入尺寸可能会导致模型计算量的增加和速度的降低。因此,大家在使用时需要权衡精度和效率之间的平衡。通常需要根据实际需求和可用资源进行调整,以找到最佳的模型输入尺寸。
同样地,在推理时也可以视情况开启测试时增强Test Time Augmentation, TTA,特别是打比赛的时候。
特征融合
多尺度特征融合
由于小目标的尺寸较小,其特征信息往往分布在图像的多个尺度中,因此需要在多个尺度的特征图中进行融合,以提高模型对小目标的感知能力。常见的多尺度特征融合方法包括 Feature Pyramid Networks, FPN 和 Path Aggregation Network, PAN 等。
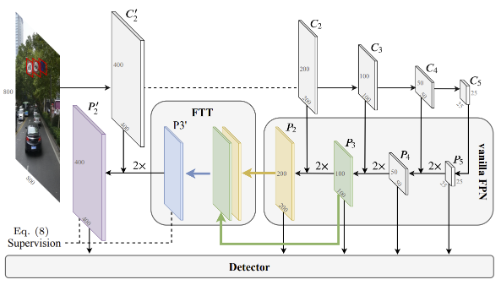
Extended Feature Pyramid Network for Small Object Detection
长跳跃连接
长跳跃连接是指将不同层级的特征图进行融合的一种方法,可以帮助模型更好地捕捉不同层级的特征信息。众所周知,浅层特征图的细节信息丰富但语义信息较弱,深层特征图则与之相反。因此,在小目标检测中,可以将低层级的特征图和高层级的特征图进行融合,以增强对小目标的定位能力。
注意力机制
注意力机制是一种能够将模型的注意力集中到重要区域的技术,可以通过对特征图进行加权处理,将更多的注意力集中到小目标所在的区域,从而提高对小目标的检测能力。常见的注意力机制包括SENet、SKNet等。
数据增强
数据增强是在保持数据本身不变的前提下,通过对数据进行随机变换来增加数据样本的数量和多样性,从而提高模型的泛化能力和鲁棒性。对于小目标检测任务,数据增强可以通过以下几种方式来解决:
尺度变换
对于小目标而言,其尺寸往往较小,因此可以通过对原始图像进行缩放或放大的操作来增加数据样本的尺度变化。例如,可以将原始图像缩小一定比例,从而得到多个尺寸较小的图像样本。
随机裁剪
对于包含小目标的图像,在不改变目标位置的情况下,可以通过随机裁剪的方式得到多个不同的图像样本,以增加数据的多样性。此外,可以使用非矩形的裁剪方式,例如多边形裁剪,来更好地适应小目标的不规则形状。
高级组合
这一块大家伙最熟悉的可能是 YOLO 中的 Mosaic 增强,其由多张原始图像拼接而成,这样每张图像会有更大概率包含小目标。此外,我们还可以通过诸如 Copy-Paste 的办法将各类小目标充分的“复制-黏贴”,从而增加小目标的“曝光度”,提升他们被检测的概率。
大图切分
Tiling
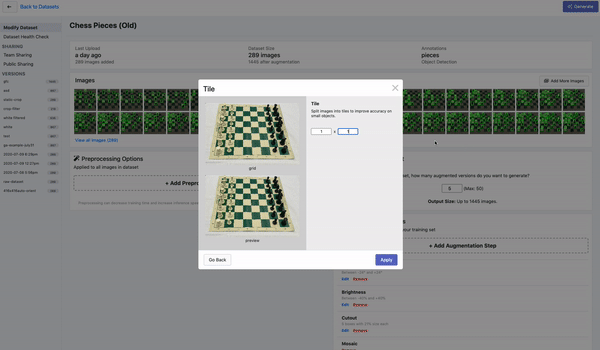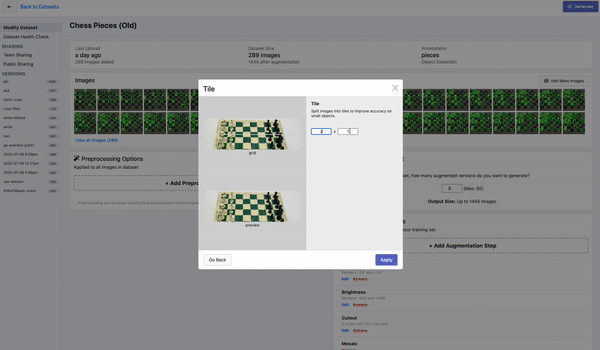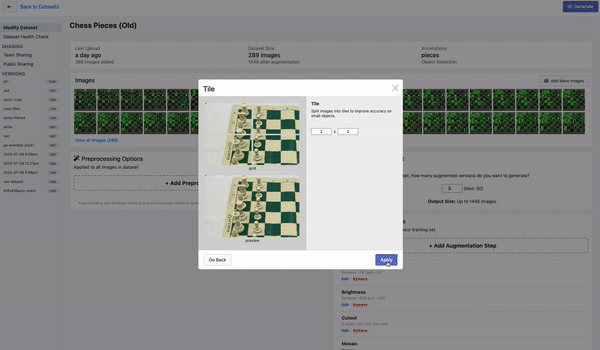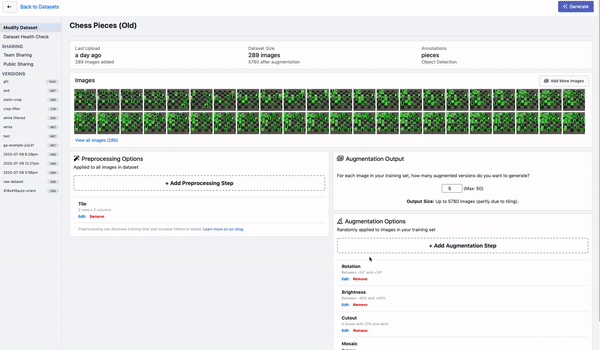
Tiling是一种对大图进行切分的有效预处理操作,上图为在Roboflow平台上的演示。通过tile可以有效地让目标检测网络更好的聚焦在小物体上,同时允许我们保持所需的小输入分辨率,以便能够运行快速推断。不过需要注意的是,在推理时也理应保持输入的一致性。
SAHI
Tiling 算是比较老旧的技术,目前笔者强烈推荐的还是Slicing Aided Hyper Inference, SAHI,即切片辅助超级推理,是一个专用于小目标检测的推理框架,理论上可以集成到任意的目标检测器上,无需进行任何微调。该方法目前已被多个成熟的目标检测框架和模型集成进去,如YOLOv5、Detectron2和MMDetection等。
损失函数
加权求和
这个非常好理解,就是我们可以自行定义小目标检测的尺寸,由于我们有 GT,因此在计算 Loss 的时候可以人为地对小目标施加更大的权重,让网络更加关注这部分。
Stitcher
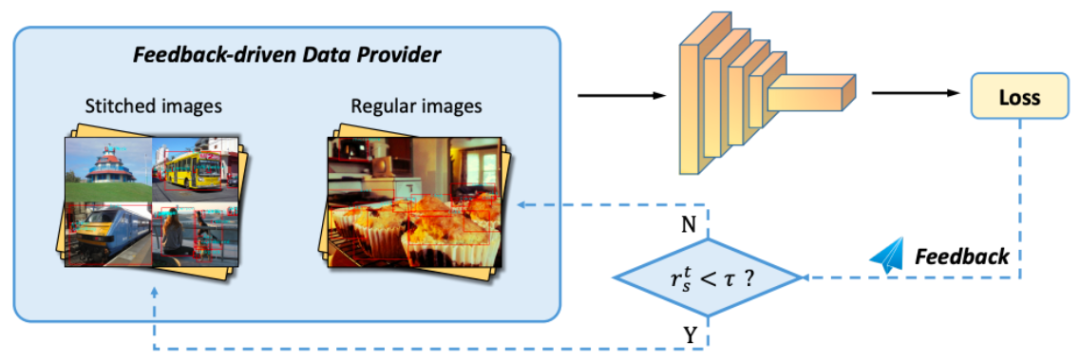
Stitcher是早几年出的产物,其出自《Stitcher: Feedback-driven Data Provider for Object Detection》一文。作者通过统计分析观察到,小目标之所以检测性能很差是因为在训练时对损失的贡献很小(要么漏检要么漏标)。因此,文章中提出了一种基于训练时动态反馈的机制,即根据计算出来的损失,自动决定是否要进行图像拼接的操作。
其它
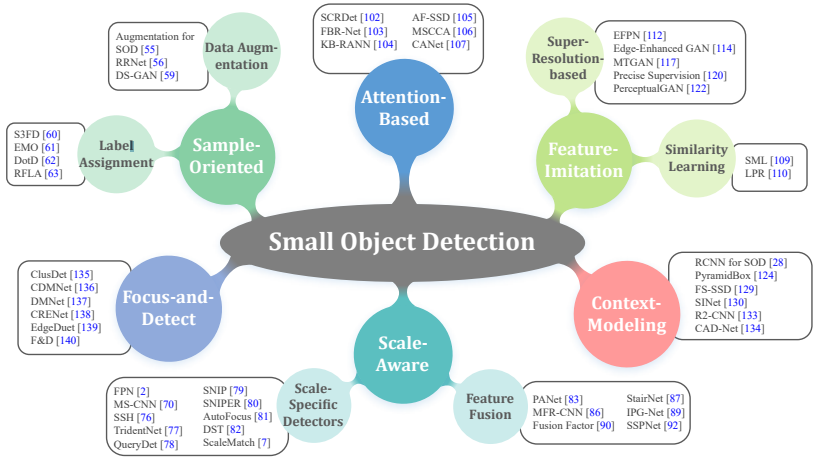
下面简单整理一些有代表性的小目标检测文章。
2023
TinyDet: Accurate Small Object Detection in Lightweight Generic Detectors
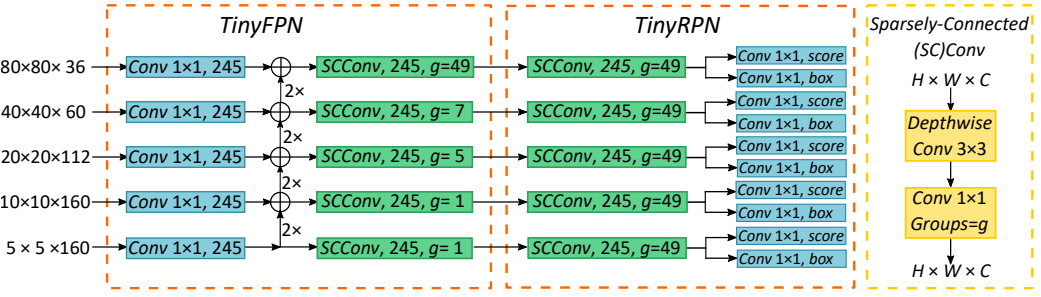
YOLO-Drone: Airborne real-time detection of dense small targets from high-altitude perspective
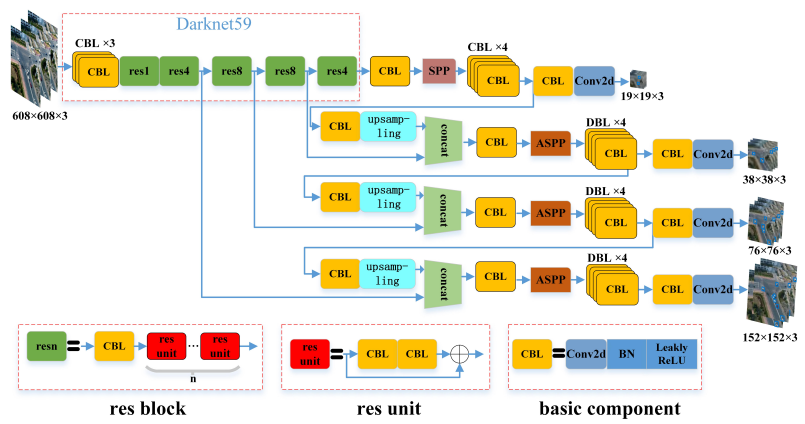
2022
Towards Large-Scale Small Object Detection: Survey and Benchmarks
2020
Small-Object Detection in Remote Sensing Images with End-to-End Edge-Enhanced GAN and Object Detector Network
2019
Augmentation for small object detection
编辑:黄飞
-
聊聊 全面的蜂窝物联网解决方案2025-03-17 771
-
功率检测解决方案2019-07-04 2557
-
采用16-bit MCU的超低功耗运动检测系统解决方案介绍2019-07-19 2600
-
WCDMA基站的测试解决方案介绍2019-07-24 1561
-
光电传感器检测黑色物体的解决方案2020-03-17 4455
-
无法检测到目标电压VDD2020-03-27 2203
-
分立电池检测的解决方案2021-02-26 1724
-
如何实现各种电机的精确控制解决方案2021-09-17 1267
-
NDIR气体检测器解决方案和PID气体检测器解决方案2020-12-29 1857
-
解析在目标检测中怎么解决小目标的问题?2021-04-26 7258
-
华为与江苏鸿程大数据研究院共同推出遥感图像目标检测解决方案2022-07-27 2429
-
非洲猪瘟检测解决方案2021-03-26 1312
-
风电传感器检测解决方案介绍2024-02-05 737
-
防雷检测应用解决方案2024-06-24 1221
-
基于iTOP-3568核心板的YOLO目标检测全栈解决方案2026-01-21 1412
全部0条评论

快来发表一下你的评论吧 !
