

基于QT+OpenCV的人脸识别-米尔iMX8M Plus开发板的测评
描述
本篇测评由电子工程世界的优秀测评者“流行科技”提供。此次测试的开源项目,是基于QT+OpenCV的人脸识别打卡项目。本次体验使用的是开源的代码,此代码本来是运行在WIN下的,为了测试稍微进行了修改,让其运行在米尔iMX8M Plus开发板上。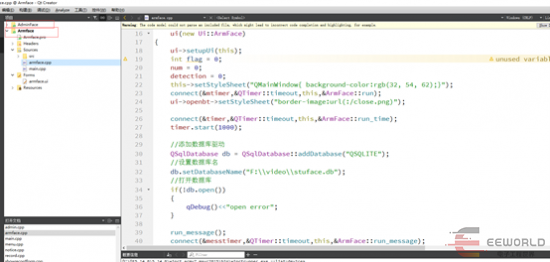 测试项目实际是分了两个工程,一个工程是作为管理员控制功能使用,添加人脸信息。同时也可以查询到打卡记录,对从机进行下发通知等等。人脸识别我们主要需要用到opencv的人脸检测分类器。
测试项目实际是分了两个工程,一个工程是作为管理员控制功能使用,添加人脸信息。同时也可以查询到打卡记录,对从机进行下发通知等等。人脸识别我们主要需要用到opencv的人脸检测分类器。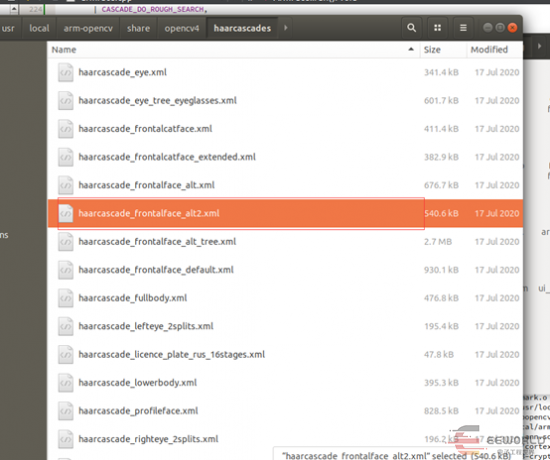 OpenCV编译完成后已经提供好了的。因为这里还需要涉及到训练模型,有了模型后才能更好的识别,所以还是简单介绍下怎么训练的吧。
OpenCV编译完成后已经提供好了的。因为这里还需要涉及到训练模型,有了模型后才能更好的识别,所以还是简单介绍下怎么训练的吧。
- CascadeClassifier cascada;
- //将opencv官方训练好的人脸识别分类器拷贝到自己的工程目录中
- cascada.load("F:\\video\\ccc\\haarcascade_frontalface_alt2.xml");
- VideoCapture cap(1); //0表示电脑自带的,如果用一个外接摄像头,将0变成1
- Mat frame, myFace;
- int pic_num = 1;
- while (1) {
- //摄像头读图像
- cap >> frame;
- vector faces;//vector容器存检测到的faces
- Mat frame_gray;
- cvtColor(frame, frame_gray, COLOR_BGR2GRAY);//转灰度化,减少运算
- cascada.detectMultiScale(frame_gray, faces, 1.1, 4, CV_HAAR_DO_ROUGH_SEARCH, Size(70, 70), Size(1000, 1000));
- printf("检测到人脸个数:%d\n", faces.size());
- //识别到的脸用矩形圈出
- for (int i = 0; i < faces.size(); i++)
- {
- rectangle(frame, faces, Scalar(255, 0, 0), 2, 8, 0);
- }
- //当只有一个人脸时,开始拍照
- if (faces.size() == 1)
- {
- Mat faceROI = frame_gray(faces[0]);//在灰度图中将圈出的脸所在区域裁剪出
- //cout << faces[0].x << endl;//测试下face[0].x
- resize(faceROI, myFace, Size(92, 112));//将兴趣域size为92*112
- putText(frame, to_string(pic_num), faces[0].tl(), 3, 1.2, (0, 0, 225), 2, 0);//在 faces[0].tl()的左上角上面写序号
- string filename = format("F:\\video\\%d.jpg", pic_num); //图片的存放位置,frmat的用法跟QString差不对
- imwrite(filename, myFace);//存在当前目录下
- imshow(filename, myFace);//显示下size后的脸
- waitKey(500);//等待500us
- destroyWindow(filename);//:销毁指定的窗口
- pic_num++;//序号加1
- if (pic_num == 11)
- {
- return 0;//当序号为11时退出循环,一共拍10张照片
- }
- }
- int c = waitKey(10);
- if ((char)c == 27) { break; } //10us内输入esc则退出循环
- imshow("frame", frame);//显示视频流
- waitKey(100);//等待100us
- }
- return 0;
通过上面代码,完成图像采集。
//读取你的CSV文件路径.
//string fn_csv = string(argv[1]);
string fn_csv = "F:\\video\\ccc\\at.txt";
// 2个容器来存放图像数据和对应的标签
vector images;
vector<int> labels;
// 读取数据. 如果文件不合法就会出错
// 输入的文件名已经有了.
try
{
read_csv(fn_csv, images, labels); //从csv文件中批量读取训练数据
}
catch (cv::Exception& e)
{
cerr << "Error opening file \"" << fn_csv << "\". Reason: " << e.msg << endl;
// 文件有问题,我们啥也做不了了,退出了
exit(1);
}
// 如果没有读取到足够图片,也退出.
if (images.size() <= 1) {
string error_message = "This demo needs at least 2 images to work. Please add more images to your data set!";
CV_Error(CV_StsError, error_message);
}
for (int i = 0; i < images.size(); i++)
{
//cout<
if (images.size() != Size(92, 112))
{
cout << i << endl;
cout << images.size() << endl;
}
}
// 下面的几行代码仅仅是从你的数据集中移除最后一张图片,作为测试图片
//[gm:自然这里需要根据自己的需要修改,他这里简化了很多问题]
Mat testSample = images[images.size() - 1];
int testLabel = labels[labels.size() - 1];
images.pop_back();//删除最后一张照片,此照片作为测试图片
labels.pop_back();//删除最有一张照片的labels
// 下面几行创建了一个特征脸模型用于人脸识别,
// 通过CSV文件读取的图像和标签训练它。
// T这里是一个完整的PCA变换
//如果你只想保留10个主成分,使用如下代码
// cv::createEigenFaceRecognizer(10);
//
// 如果你还希望使用置信度阈值来初始化,使用以下语句:
// cv::createEigenFaceRecognizer(10, 123.0);
//
// 如果你使用所有特征并且使用一个阈值,使用以下语句:
// cv::createEigenFaceRecognizer(0, 123.0);
//创建一个PCA人脸分类器,暂时命名为model吧,创建完成后
//调用其中的成员函数train()来完成分类器的训练
Ptr model = face::create();
model->train(images, labels);
model->save("MyFacePCAModel.xml");//保存路径可自己设置,但注意用“\\”
Ptr model1 = face::create();
model1->train(images, labels);
model1->save("MyFaceFisherModel.xml");
Ptr model2 = face::create();
model2->train(images, labels);
model2->save("MyFaceLBPHModel.xml");
// 下面对测试图像进行预测,predictedLabel是预测标签结果
//注意predict()入口参数必须为单通道灰度图像,如果图像类型不符,需要先进行转换
//predict()函数返回一个整形变量作为识别标签
int predictedLabel = model->predict(testSample);//加载分类器
int predictedLabel1 = model1->predict(testSample);
int predictedLabel2 = model2->predict(testSample);
// 还有一种调用方式,可以获取结果同时得到阈值:
// int predictedLabel = -1;
// double confidence = 0.0;
// model->predict(testSample, predictedLabel, confidence);
string result_message = format("Predicted class = %d / Actual class = %d.", predictedLabel, testLabel);
string result_message1 = format("Predicted class = %d / Actual class = %d.", predictedLabel1, testLabel);
string result_message2 = format("Predicted class = %d / Actual class = %d.", predictedLabel2, testLabel);
cout << result_message << endl;
cout << result_message1 << endl;
cout << result_message2 << endl;
getchar();
//waitKey(0);
return 0;
通过上面的代码进行训练,训练使用了python。所以系统环境需要配置好。

在此文件中,把我们采集到的图像,放进去,新建一个文件夹。
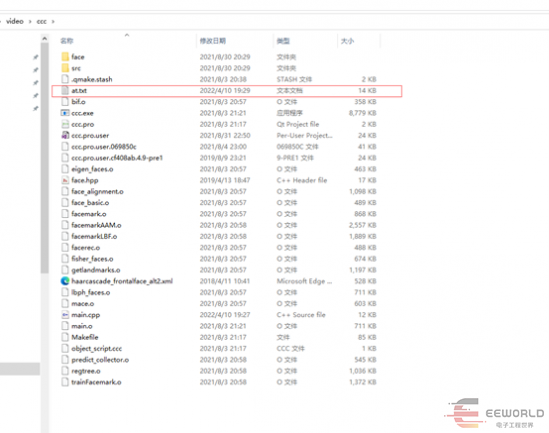
之后就是把我们的at.txt也加入我们的文件。
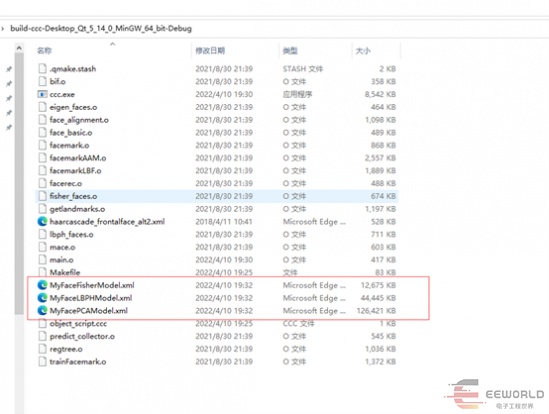
训练好后,我们就得到了我们所需要的训练文件。
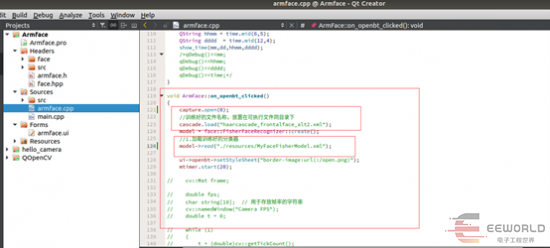
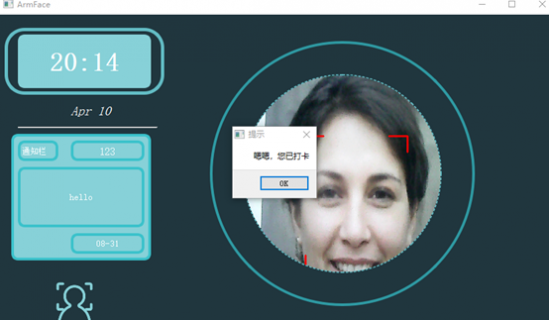
在我们打卡界面,点击打卡时就是这样的。加载训练好的东西。然后启动定时器,去获取摄像头信号,然后对比,最终和数据库一致就认为打卡成功。
上面训练部分,其实提供的另一个工程就全部完成了。
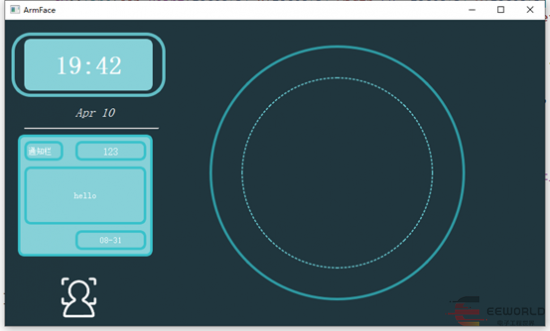
这是我们win端界面,圆框就是我们摄像头采集图像显示的位置。
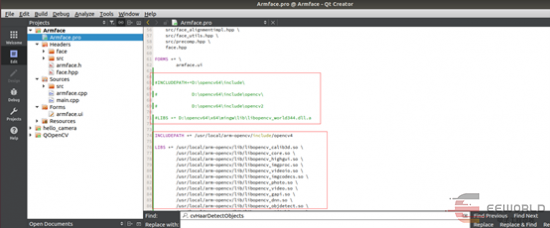
我们需要在Ubuntu下把库全部替换,这样就能编译过了,然后拷贝到开发板上运行。如下:
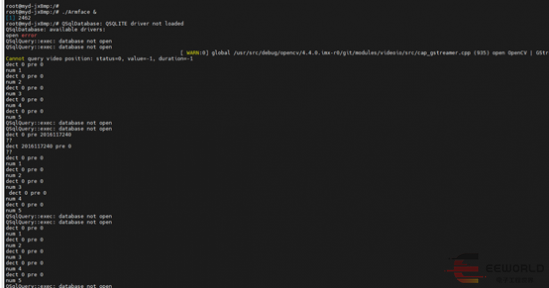
进来就提示数据库打开失败了,我们这个都是基于数据库,所以还是比较尴尬的,后期的话可以尝试自己全部编译下,然后更新吧。目前就测试,看下效果吧。

使用的硬件增加了一个摄像头。

这是打开摄像头采集的样子。

这个GIF展示了我们的人脸检测情况。
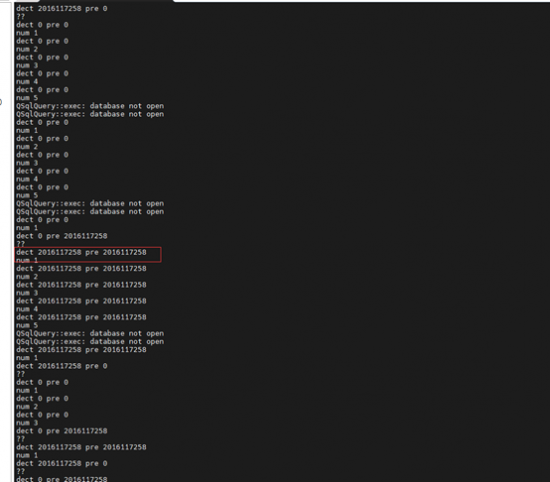
由于没有数据库,只能打印一些信息。当两个数据相等时就进入下一步,判断打卡了。由于没有数据库,就展示下电脑端的效果吧。

- 相关推荐
- 热点推荐
- 开发板
-
IMX8M Plus 板上部署立体视觉模型 CPU 回退错误 IMX8M Plus问题2026-04-29 137
-
如何用OpenCV进行手势识别--基于米尔全志T527开发板2024-12-13 2220
-
FacenetPytorch人脸识别方案--基于米尔全志T527开发板2024-11-28 1928
-
如何用OpenCV的相机捕捉视频进行人脸检测--基于米尔NXP i.MX93开发板2024-11-15 2322
-
基于OPENCV的相机捕捉视频进行人脸检测--米尔NXP i.MX93开发板2024-11-07 2111
-
imx8m plus芯片的M7内核软件开发有没有开发指南?2023-06-01 811
-
iMX8M Plus USB口快充/快充吗?2023-05-19 744
-
QT+OpenCV人脸识别—米尔iMX8MPlus开发板项目2022-05-18 3288
-
基于QT+OpenCV的人脸识别-米尔iMX8M Plus开发板的项目应用2022-05-17 2054
-
米尔电子MYS-8MMX开发板试用体验测评——卿小小_9e62021-11-09 2285
-
米尔电子MYS-8MMX开发板试用体验测评——w4941434672021-11-01 2381
-
米尔MYS-8MMX开发板试用体验测评——dql20162021-10-25 2336
-
米尔MYS-8MMX开发板试用体验测评——tobot2021-09-18 2896
-
【LeMaker Guitar申请】基于LeMaker Guitar的人脸识别系统2016-01-18 3977
全部0条评论

快来发表一下你的评论吧 !
