

基于EQ6HL130实现FIR功能测试
描述
FIR(Finite Impulse Response)滤波器:有限长单位冲激响应滤波器,又称为非递归型滤波器,是数字信号处理系统中最基本的元件,它可以在保证任意幅频特性的同时具有严格的线性相频特性,同时其单位抽样响应是有限长的,因而滤波器是稳定的系统。因此,FIR滤波器在通信、图像处理、模式识别等领域都有着广泛的应用。由于 FIR 滤波器处理的是数字信号,所以模拟信号在进入 FIR 滤波器前,需要先经过 AD 器件进行模数转换将模拟信号转化为数字信号,而为了让信号处理不发生失真,信号的采样速度必须满足奈奎斯特采样定理,一般取信号最高频率的 4 到 5 倍作为采样频率。
1 、FIR结构介绍
2 、EQ6HL130可编程逻辑芯片介绍
3 、eLinx工具介绍
4 、使用Verilog建立混频波形
5 、matlab工具参数配置
6 、FIR结构程序设计
7 、FIR IP核使用
8 、仿真验证
9 、开发板试用
10、公司情况
1
FIR结构介绍
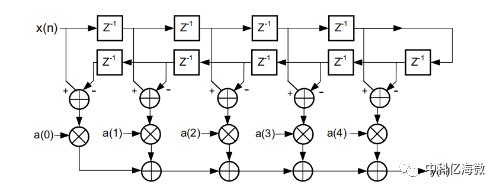
FIR 滤波器信号处理如下公式所示,其中 x(n)是输入的信号,a(n)为 FIR 滤波系数,y(n)为滤波后的信号。N为FIR滤波器的抽头数,滤波器阶数为 N-1。
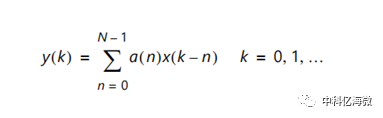
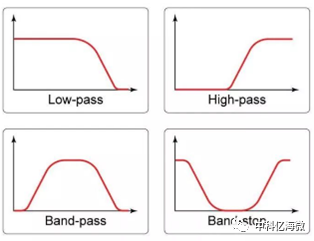
低通滤波器:低通滤波器是容许低于截止频率的信号通过,但高于截止频率的信号不能通过的滤波。
高通滤波器:高通滤波器,又称低截止滤波器,低阻滤波器,允许高于某一截频的频率通过,而大大衰减较低频率的一种滤波器 ,它去掉了信号中不必要的低频成分或者说去掉了低频干扰。
带通滤波器:是指能通过某一频率范围内的频率分量,但将其他范围的频率分量衰减到极低水平的滤波器,与带阻滤波器的概念相对。
带阻滤波器:是指能通过大多数频率分量,但将某些范围的频率分量衰减到极低水平的滤波器,与带通滤波器的概念相对。
2
EQ6HL130可编程逻辑芯片介绍
EQ6HL130是中科亿海微自主研发的可编程逻辑芯片,有效系统门容量达到1360万门;
芯核电压1.1V,I/O标准电压3.3V,支持多种I/O标准;
具有1200个4.5K嵌入式存储器单元,最大存储容量5.4M bit;
具有192个高速18bit×18bit乘法器;
具有8个可编程PLL,最高时钟管理频率可达500MHz;
最多可提供16路全局时钟信号;
最大可提供338个可编程用户I/O, 最多提供169对LVDS差分端口;
支持片上数字控制终端电阻(Digital Control Termination,DCT);
支持主动串行、被动串行、主动并行、被动并行、JTAG、SPI等配置模式;
ESD大于2000V。
3
eLinx工具介绍
亿灵思设计套件(eLinx Design Suite)是中科亿海微研发的一款拥有国产自主知识产权的大规模可编程逻辑芯片开发软件,可以支持千万门级以上可编程逻辑芯片器件的设计开发。eLinx软件不仅可以支持工业界标准的开发流程,即从RTL综合到配置码流生成下载的全套操作,而且可以提供面向嵌入式可编程电路IP核定制开发的评估流程,帮助用户定制嵌入式可编程电路IP核资源的规模和排布,并生成相应的芯片数据库,为终端用户提供与可编程逻辑芯片成片相同的EDA全流程服务。
产品特点:
从 RTL到Bitstream的全正向自主可控融合架构EDA工具;
集成了IP核生成器,包含丰富的IP软硬核资源,帮助用户快捷地实现复杂设计;
除传统流程外,还支持嵌入式可编程电路 IP 核的评估以及定制流程;
高效的时序装箱布局布线算法,在延时/面积方面有着高质量的QoR;
支持工业标准SDC文件作为时序约束来满足时序要求;
集成了在线逻辑分析Bitprobe,可提供方便的在线调试手段;
支持各类码流下载模式,包括PROM/Flash片外下载;
支持第三方的仿真工具ModelSim;
基于TCL脚本环境的自动化流程控制;
软件界面兼容国际主流商业工具,容易上手;
直观的图形化管脚分配以及Floorplan功能;
三模冗余(TMR)软件抗辐照加固措施。
4
使用Verilog建立混频波形
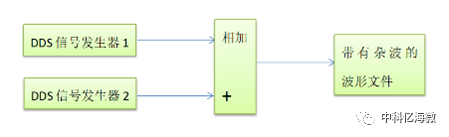
程序介绍:分别使用两个rom输出不同频率,进行相加。
频率计算:使用时钟/采样点=真实频率。
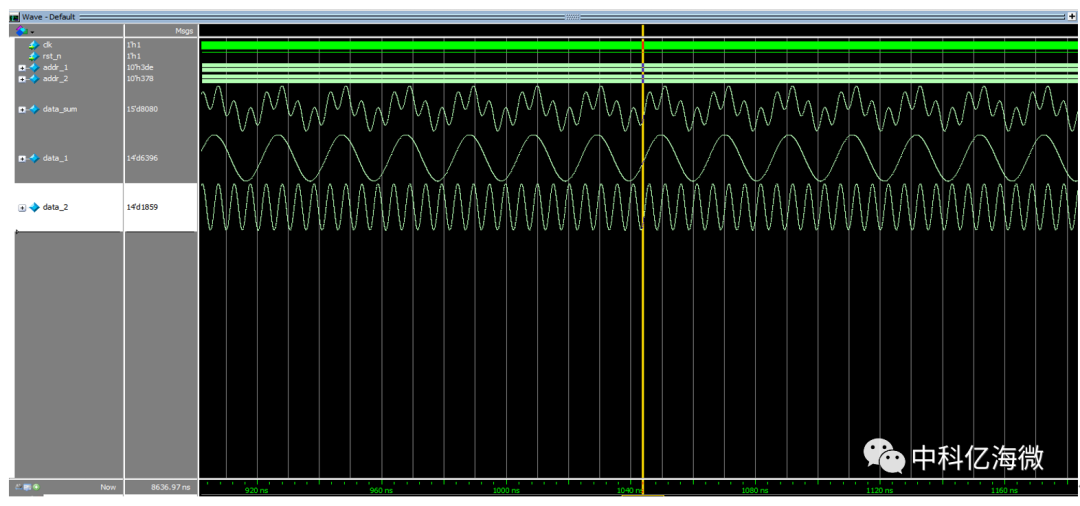
仿真结果:data_sum为相加后的结果!
5
matlab工具参数配置
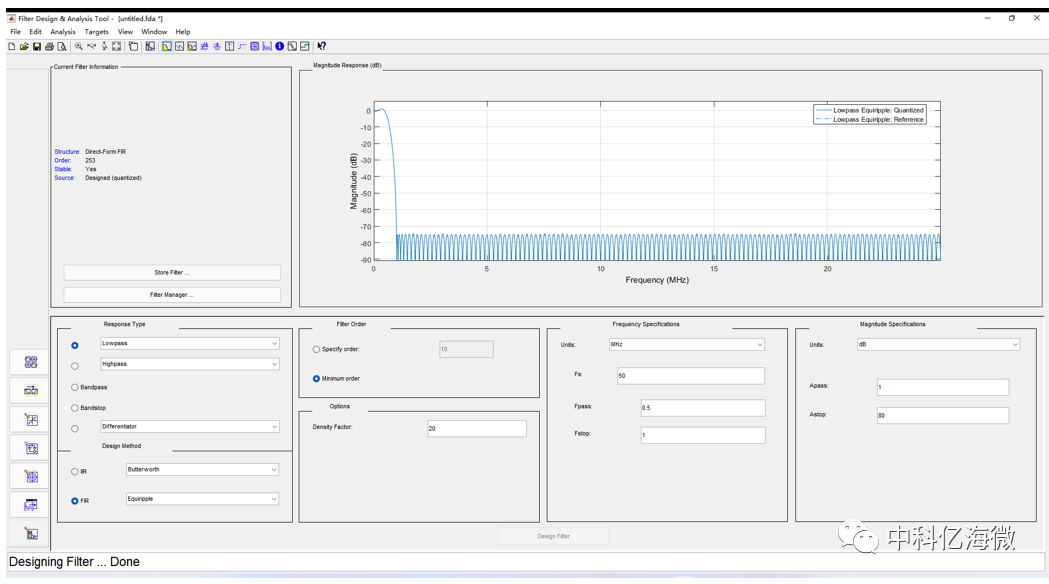
设计一个16阶的低通滤波器
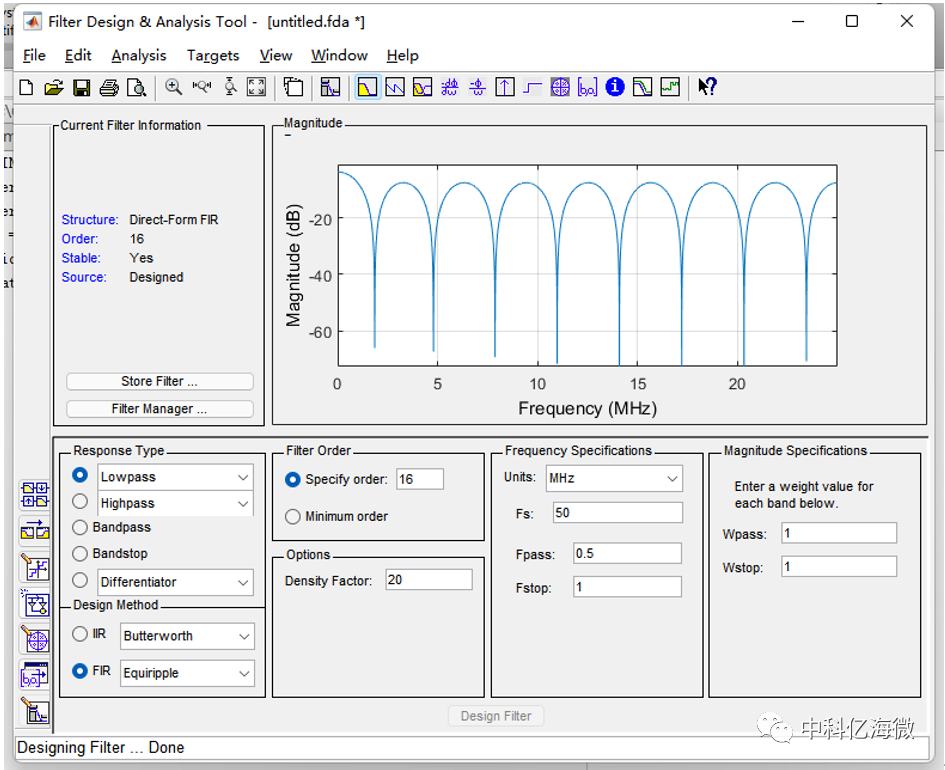
参数选择:选用低通滤波器,使用波纹设计法,阶数自定义了16个(当然阶数越多滤波效果越好),FS的采样频率是50M,通过频率0.5M,截至频率为1M。
Response Type:选择FIR滤波器的类型:低通、高通、带通和带阻等。
Design Method:FIR滤波器设计方法有多种,最常用的是窗函数设计法(Window)、等波纹设计法(Equiripple)和最小二乘法 (Least-Squares)等。其中窗函数设计法在学校课堂中是重点讲解的,提到FIR滤波器肯定会想到hamming、kaiser窗,但是实际应用中却很少使用,因为如果采用窗函数设计法,达到所期望的频率响应,与其它方法相比往往阶数会更多;而且窗函数设计法一般只参照通频带wp、抑制频带ws 和理想增益来设计滤波器,但是实际应用中通频带和抑制带的波纹也是需要考虑的,那在这种情况下,采用等波纹设计法就非常适用了。
Frequency Specification:设置频率响应的参数,包括采样频率Fs、通带频率Fpass和阻带频率Fstop。
Filter Order:设置滤波器的阶数,这个选项直接影响滤波器的性能,阶数越高,性能越好,但是相应在可编程逻辑芯片实现耗用的资源需要增多。在这个设置中提供2个选项:Specify order和Minimum order,Specify order是工程师自己确定滤波器的阶数,Minimum order是让工具自动确定达到期望的频率相应所需要的最小阶数,因此具体选择哪个选项得视实际情况而定了,(这里我选用16阶)。
将配置完成后的数据导出 :
File ---> Export ---> Export ;
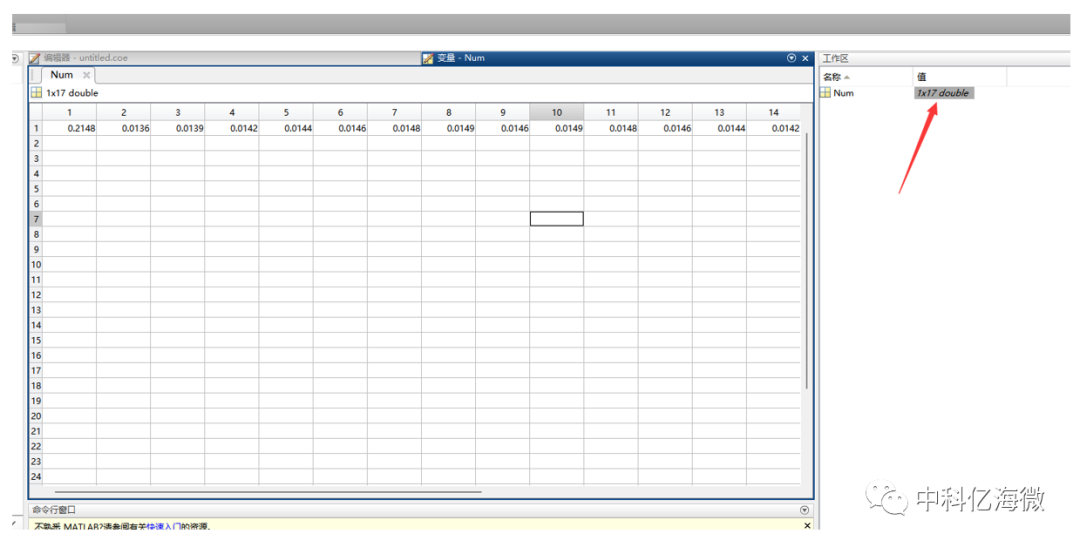
输入: > Num=round(Num*400) 取整数
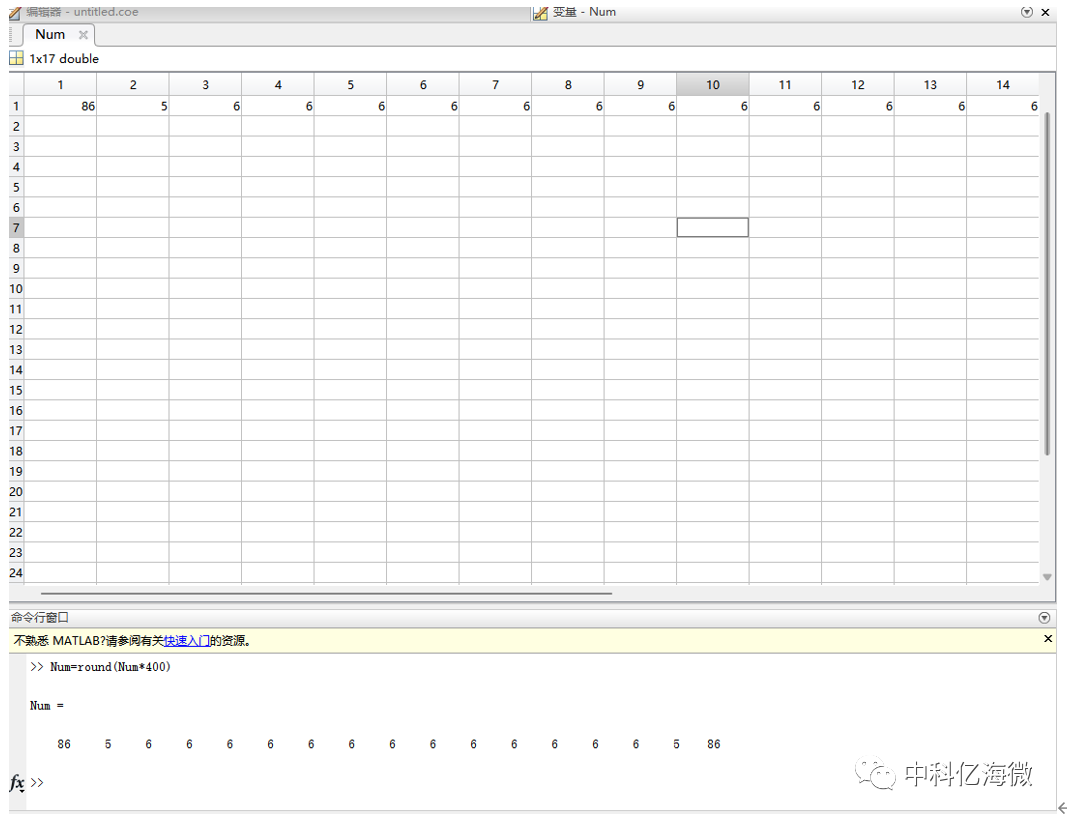
将上方数据代入到verilog进行乘累加滤波。
6
FIR结构程序设计
module top (
input wire clk,
input wire rst_n
);
//Registers Declarations
reg [9:0] addr_1;
reg [9:0] addr_2;
reg [14:0] data_sum;
reg [14:0] delay_pipeline1 ;
reg [14:0] delay_pipeline2 ;
reg [14:0] delay_pipeline3 ;
reg [14:0] delay_pipeline4 ;
reg [14:0] delay_pipeline5 ;
reg [14:0] delay_pipeline6 ;
reg [14:0] delay_pipeline7 ;
reg [14:0] delay_pipeline8 ;
reg [14:0] delay_pipeline9 ;
reg [14:0] delay_pipeline10 ;
reg [14:0] delay_pipeline11 ;
reg [14:0] delay_pipeline12 ;
reg [14:0] delay_pipeline13 ;
reg [14:0] delay_pipeline14 ;
reg [14:0] delay_pipeline15 ;
reg [14:0] delay_pipeline16 ;
reg [14:0] delay_pipeline17 ;
reg signed [22:0] multi_data1 ;//乘积结果
reg signed [22:0] multi_data2 ;
reg signed [22:0] multi_data3 ;
reg signed [22:0] multi_data4 ;
reg signed [22:0] multi_data5 ;
reg signed [22:0] multi_data6 ;
reg signed [22:0] multi_data7 ;
reg signed [22:0] multi_data8 ;
reg signed [22:0] multi_data9 ;
reg signed [22:0] multi_data10 ;
reg signed [22:0] multi_data11 ;
reg signed [22:0] multi_data12 ;
reg signed [22:0] multi_data13 ;
reg signed [22:0] multi_data14 ;
reg signed [22:0] multi_data15 ;
reg signed [22:0] multi_data16 ;
reg signed [22:0] multi_data17 ;
reg signed [22:0] FIR_OUT;
//---Wiredsignaldeclaration
wire [13:0] data_1;
wire [13:0] data_2;
wire[7:0] coeff1 =8'd86; //滤波器系数
wire[7:0] coeff2 = 8'd5;
wire[7:0] coeff3 = 8'd6;
wire[7:0] coeff4 = 8'd6;
wire[7:0] coeff5 = 8'd6;
wire[7:0] coeff6 = 8'd6;
wire[7:0] coeff7 = 8'd6;
wire[7:0] coeff8 = 8'd6;
wire[7:0] coeff9 = 8'd6;
wire[7:0] coeff10 = 8'd6;
wire[7:0] coeff11 = 8'd6;
wire[7:0] coeff12 = 8'd6;
wire[7:0] coeff13 = 8'd6;
wire[7:0] coeff14 = 8'd6;
wire[7:0] coeff15 = 8'd6;
wire[7:0] coeff16 = 8'd5;
wire[7:0] coeff17 = 8'd86;
always @ (posedge clk or negedge rst_n) begin
if (!rst_n)
begin
addr_1<= 10'd0;
addr_2<= 10'd0;
end
else
begin
addr_1<= addr_1+10'd41; //2m
addr_2<= addr_2+10'd20; //1m
end
end
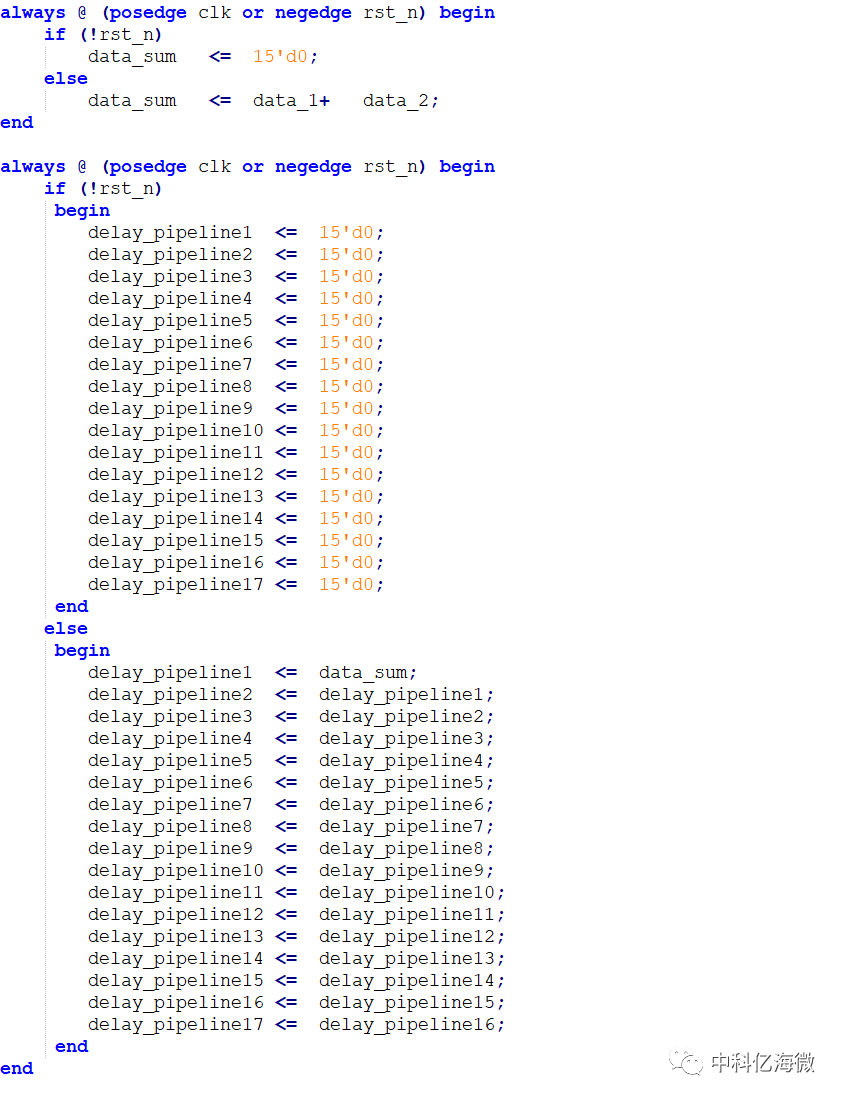
always @ (posedge clk or negedge rst_n) begin
if (!rst_n)
data_sum <= 15'd0;
else
data_sum <= data_1+ data_2;
end
always @ (posedge clk or negedge rst_n) begin
if (!rst_n)
begin
delay_pipeline1 <= 15'd0;
delay_pipeline2 <= 15'd0;
delay_pipeline3 <= 15'd0;
delay_pipeline4 <= 15'd0;
delay_pipeline5 <= 15'd0;
delay_pipeline6 <= 15'd0;
delay_pipeline7 <= 15'd0;
delay_pipeline8 <= 15'd0;
delay_pipeline9 <= 15'd0;
delay_pipeline10 <= 15'd0;
delay_pipeline11 <= 15'd0;
delay_pipeline12 <= 15'd0;
delay_pipeline13 <= 15'd0;
delay_pipeline14 <= 15'd0;
delay_pipeline15 <= 15'd0;
delay_pipeline16 <= 15'd0;
delay_pipeline17 <= 15'd0;
end
else
begin
delay_pipeline1 <= data_sum;
delay_pipeline2 <= delay_pipeline1;
delay_pipeline3 <= delay_pipeline2;
delay_pipeline4 <= delay_pipeline3;
delay_pipeline5 <= delay_pipeline4;
delay_pipeline6 <= delay_pipeline5;
delay_pipeline7 <= delay_pipeline6;
delay_pipeline8 <= delay_pipeline7;
delay_pipeline9 <= delay_pipeline8;
delay_pipeline10 <= delay_pipeline9;
delay_pipeline11 <= delay_pipeline10;
delay_pipeline12 <= delay_pipeline11;
delay_pipeline13 <= delay_pipeline12;
delay_pipeline14 <= delay_pipeline13;
delay_pipeline15 <= delay_pipeline14;
delay_pipeline16 <= delay_pipeline15;
delay_pipeline17 <= delay_pipeline16;
end
end
always @ (posedge clk or negedge rst_n) begin
if (!rst_n)
begin
multi_data1 <= 23'd0;//乘积结果
multi_data2 <= 23'd0;
multi_data3 <= 23'd0;
multi_data4 <= 23'd0;
multi_data5 <= 23'd0;
multi_data6 <= 23'd0;
multi_data7 <= 23'd0;
multi_data8 <= 23'd0;
multi_data9 <= 23'd0;
multi_data10 <= 23'd0;
multi_data11 <= 23'd0;
multi_data12 <= 23'd0;
multi_data13 <= 23'd0;
multi_data14 <= 23'd0;
multi_data15 <= 23'd0;
multi_data16 <= 23'd0;
multi_data17 <= 23'd0;
end
else
begin
multi_data1 <= delay_pipeline1 * coeff1;//乘积结果
multi_data2 <= delay_pipeline2 * coeff2;
multi_data3 <= delay_pipeline3 * coeff3;
multi_data4 <= delay_pipeline4 * coeff4;
multi_data5 <= delay_pipeline5 * coeff5;
multi_data6 <= delay_pipeline6 * coeff6;
multi_data7 <= delay_pipeline7 * coeff7;
multi_data8 <= delay_pipeline8 * coeff8;
multi_data9 <= delay_pipeline9 * coeff9;
multi_data10 <= delay_pipeline10 * coeff10;
multi_data11 <= delay_pipeline11 * coeff11;
multi_data12 <= delay_pipeline12 * coeff12;
multi_data13 <= delay_pipeline13 * coeff13;
multi_data14 <= delay_pipeline14 * coeff14;
multi_data15 <= delay_pipeline15 * coeff15;
multi_data16 <= delay_pipeline16 * coeff16;
multi_data17 <= delay_pipeline17 * coeff17;
end
end
always @ (posedge clk or negedge rst_n) begin
if (!rst_n)
FIR_OUT <= 23'd0;
else
FIR_OUT <=multi_data1+multi_data2+multi_data3+multi_data4+multi_data5+multi_data6+multi_data7
+multi_data8+multi_data9+multi_data10+multi_data11+multi_data12+multi_data13+multi_data14+multi_data15
+multi_data16+multi_data17;
end
rom_1 u_rom_1(
.address (addr_1 ),
.clock (clk ),
.q (data_1 )
);
rom_1 u_rom_2(
.address (addr_2 ),
.clock (clk ),
.q (data_2 )
);
endmodule

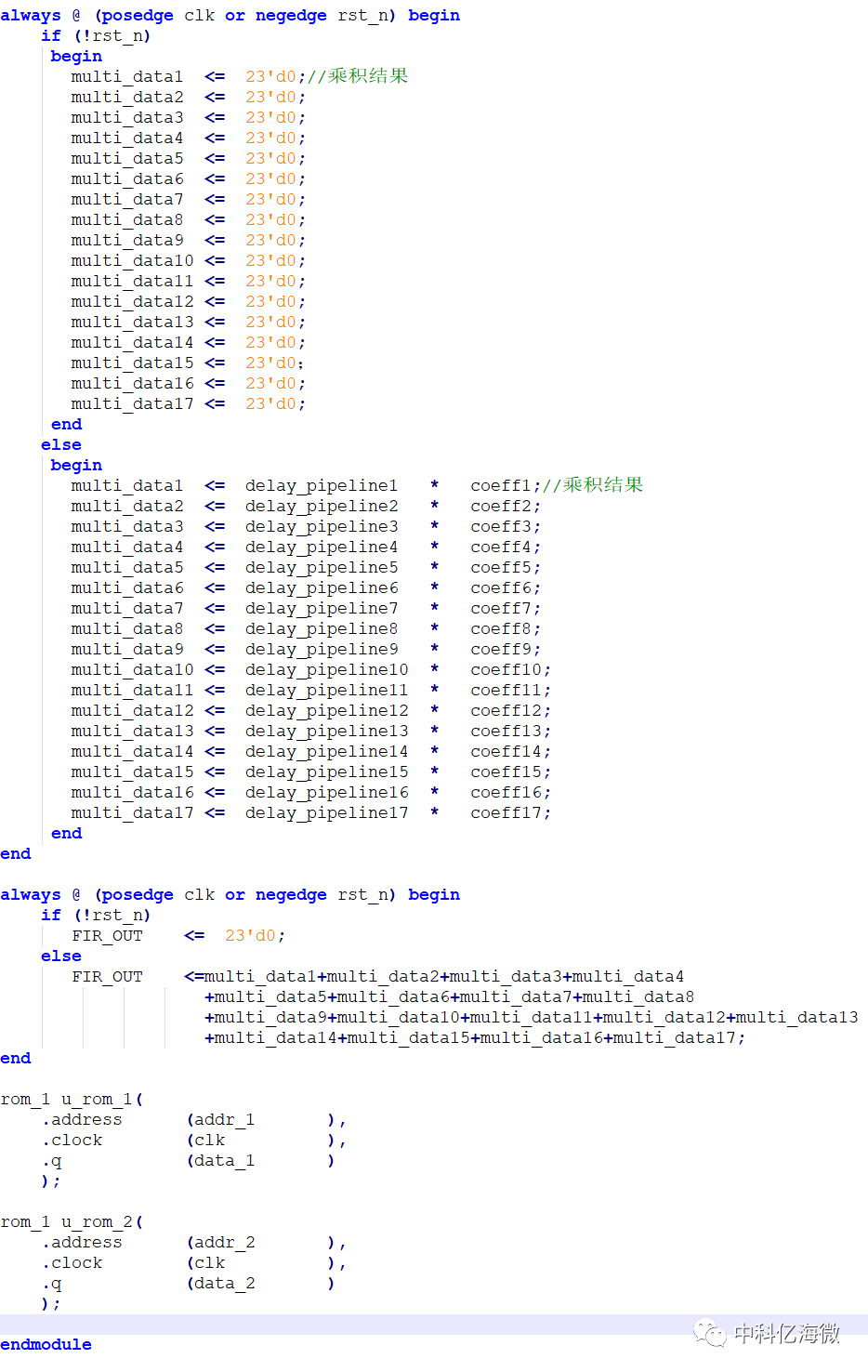
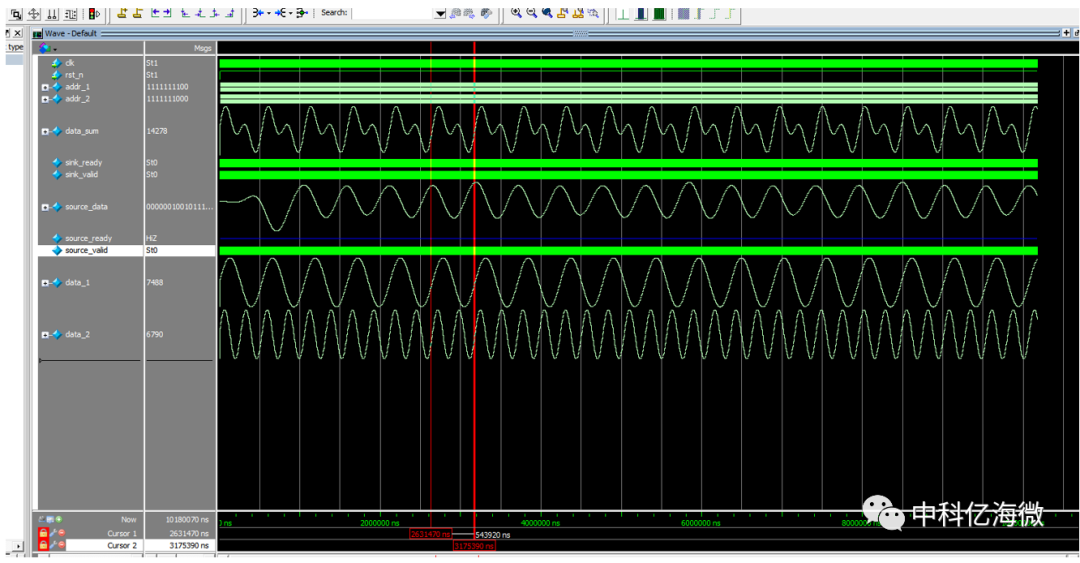
仿真结果:FIR_OUT 为滤波后的效果。
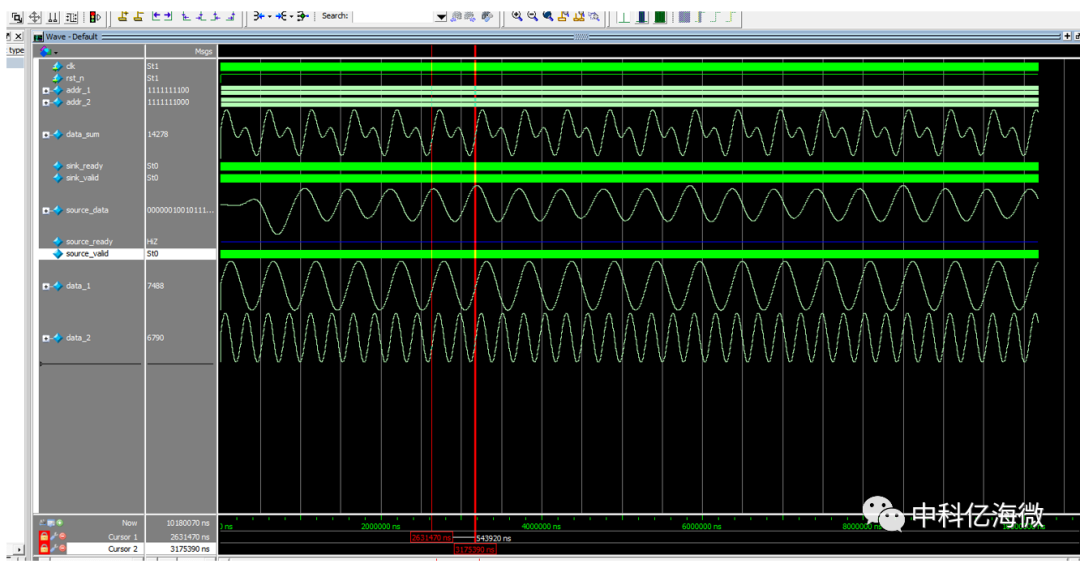
7
FIR IP核使用
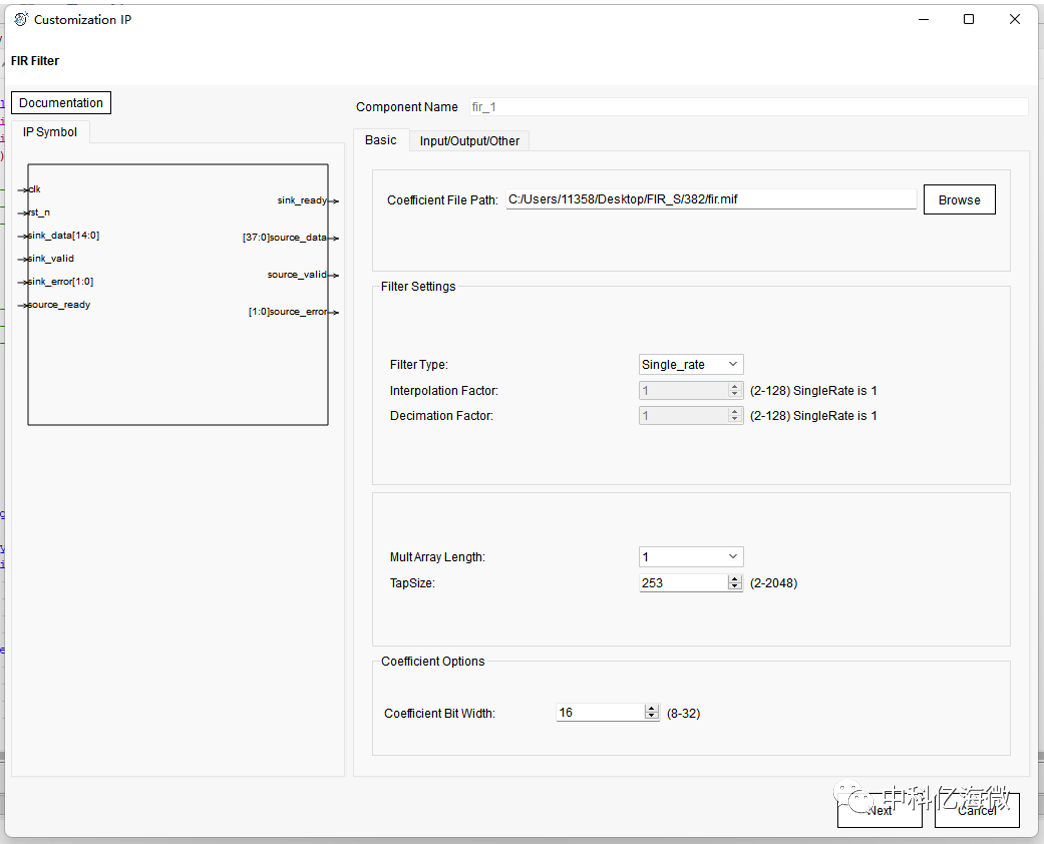
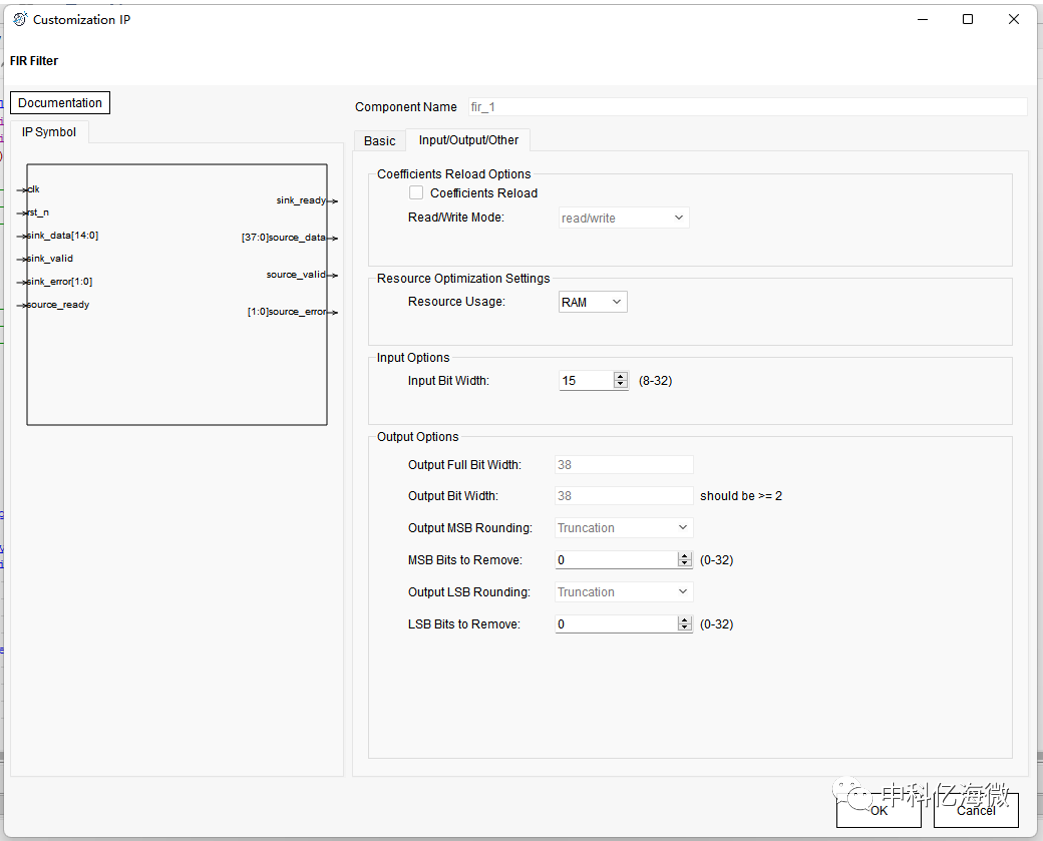
采用IP核的形式完成滤波实验,需要使用MATLAB配置参数,以MIF格式的文件放置到IP中进行配置。
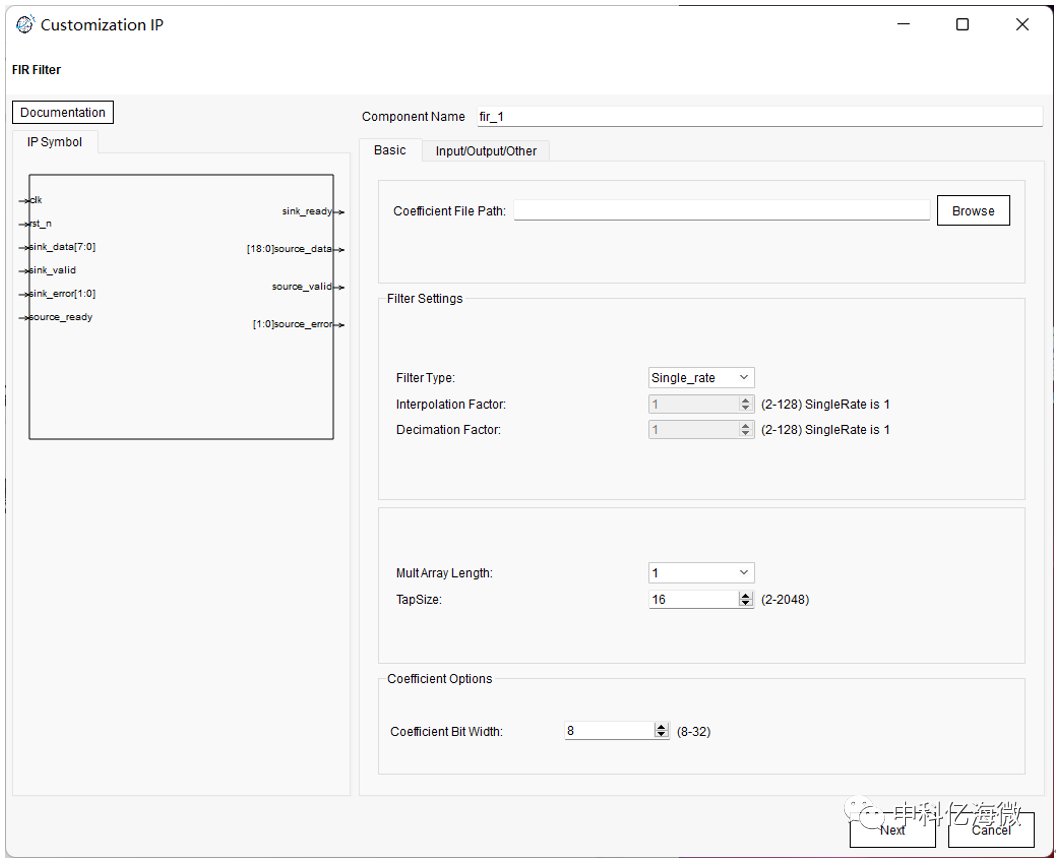
Docunmentation : FIR的IP核使用手册。
Coefficient File Path : 防止配置后的MIF文件。
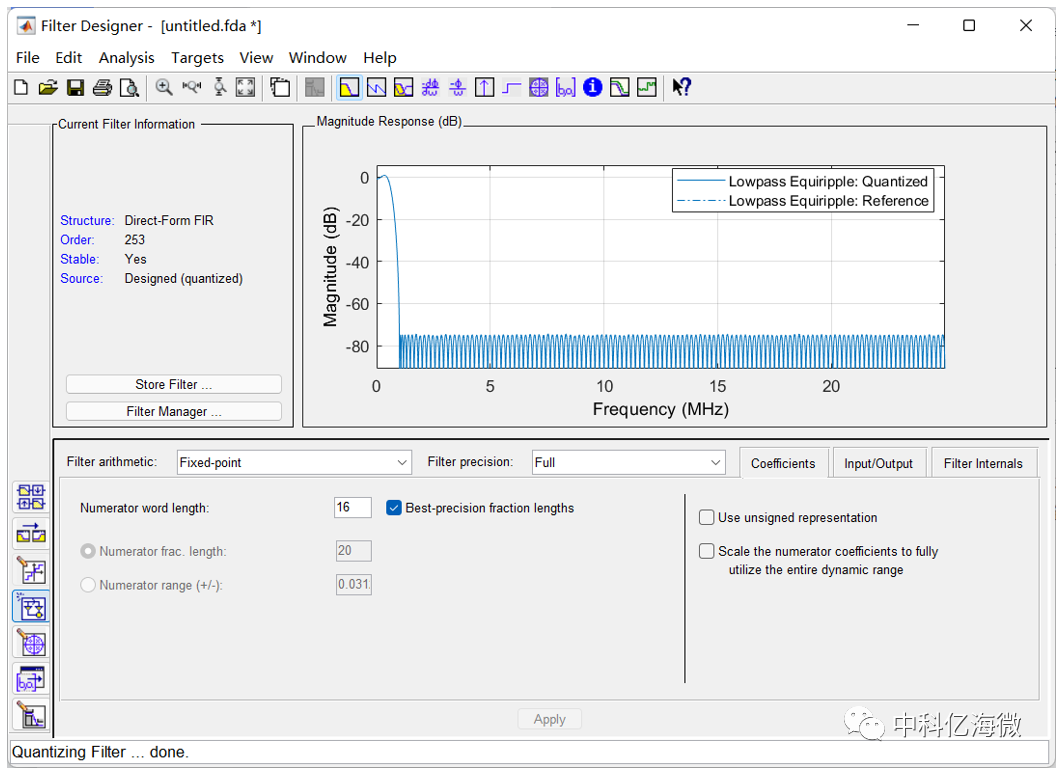
因为可编程逻辑芯片并不支持浮点数的运算,所以需要对抽头系数进行量化处理,在 Filter arithmetic 中选择 Fixed-point, Number word length 中可以输入的是字长,当输入 8 时,点击 Apply,可以看到有较大的偏差。所以将数值改为 16。
导出需要配置的数据 :
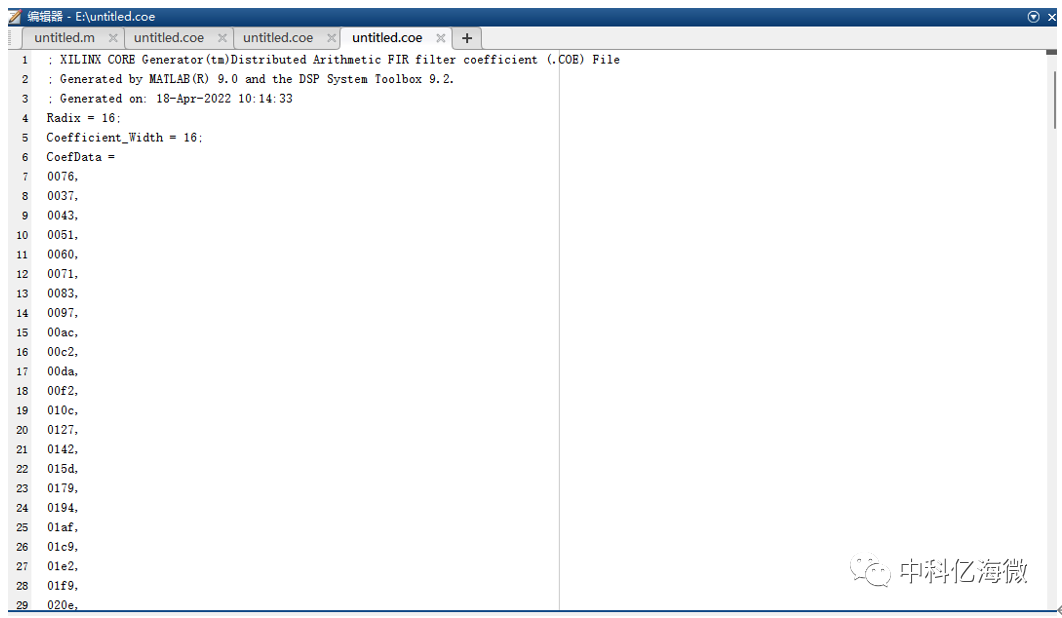
将数据文件改成.MIF文件格式,给予eLinx软件使用。

此处存储为十六进制数据 , 我们建议使用二进制进行存储,数据更加稳定。
IP核配置页面 :
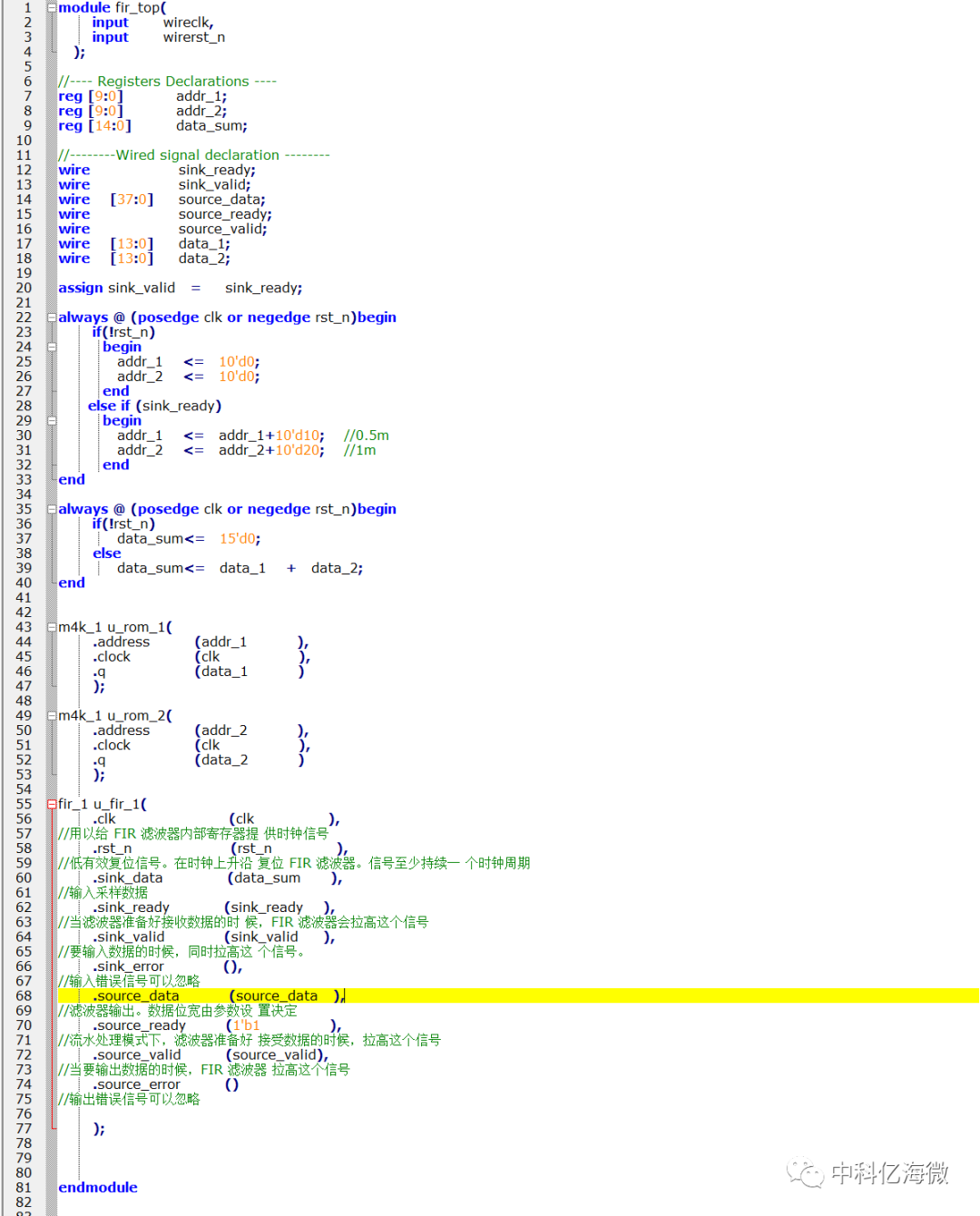
测试程序:
8
仿真验证
-
EQ均衡器的学习记录心得2019-02-20 6227
-
中科亿海微EQ6HL45型可编程逻辑芯片开发平台免费试用2022-03-08 3226
-
中科亿海微EQ6HL45型FPGA开发板开箱试用视频2022-05-14 9637
-
中科亿海微与龙芯中科实现产品兼容互认2022-01-12 2024
-
EQ6HL45高性价比低功耗425万门级FPGA原位替换XILINX/赛灵思:SPARTAN6系列FPGA2022-02-28 5083
-
2021年度最佳FPGA芯片-EQ6HL130原位替换XILINX/赛灵思:SPARTAN6系列XC6SLX1502022-03-01 7062
-
中科亿海微与飞腾公司实现产品兼容适配认证2022-08-26 1694
-
EQ6HL130 Device User Guide2022-02-16 1514
-
中科亿海微SoM模组——基于EQ6HL9S的单轴光纤陀螺板卡2025-06-30 808
-
中科亿海微SiP微系统——EQ6HL45S-M1CSG400芯片2025-10-10 899
全部0条评论

快来发表一下你的评论吧 !
