

【技术分享】STM32实现单麦克风实时神经网络降噪
描述
本文是基于NNoM神经网络框架实现的。NNoM是一个为单片机定制的神经网络框架,可以实现TensorFlow 模型的量化和部署到单片机上,可以在Cortex M4/7/33等ARM内核的单片机上实现加速(STM32,LPC,Nordic nRF 等等)。
NNoM和本文代码可以在后台回复:“麦克风降噪”领取。
STM32实现单麦克风实时神经网络(RNN)降噪演示
硬声创作者:麻博士在科研
这个例子是根据著名的 RNNoise (https://jmvalin.ca/demo/rnnoise/) 的降噪方法进行设计的。整体进行了一些简化和定点化的一些修改。
本例与RNNoise主要的区别如下:
此例子并非从RNNoise的模型直接转换而来,而是从新基于Keras训练一个新模型,并转化成NNoM模型。
音频信号处理去掉了Pitch Filtering的部分。
RNN 网络定点化时,根据定点模型的一些特点进行了部分神经网络结构修改。
训练数据集选择上使用了微软的可定制语音数据库而不是RNNoise收集的数据库。
此例子用到的三方库如下,大部分为宽松许可,但请大家在使用时遵循他们的开源协议。
RNNoise (https://jmvalin.ca/demo/rnnoise/)
Microsoft Scalable Noisy Speech Dataset (https://github.com/microsoft/MS-SNSD)
python speech features (https://github.com/jameslyons/python_speech_features)
arduino_fft (https://github.com/lloydroc/arduino_fft)
CMSIS (https://github.com/ARM-software/CMSIS_5)
NNoM本身许可为 Apache-2.0,详细信息请看NNoM 开源主仓库下的许可信息 (https://github.com/majianjia/nnom).
一些背景知识
如何用神经网络进行语音降噪?
神经网络降噪通常有两种方式:
语音信号直入神经网络模型,神经网络全权进行识别处理并输出降噪后的语音信号。
神经网络识别语音和噪音的特征,动态输出增益,使用传统信号处理方法进行滤波。
RNNoise 使用的是第二种方法。
实际进行语音降噪(滤波)的部分,是一个均衡器,也就是大家播放器内调节低音高音的那个玩意儿。而均衡器(Equalizer)的本质是很多个平行的带通滤波器(Bandpass Filter). 我们神经网络的输出,就是均衡器内各个filter band的增益。
那输入是什么?跟之前的 KeyWord Spotting例子(https://github.com/majianjia/nnom/tree/master/examples/keyword_spotting) 一样,我们这里使用了梅尔倒频谱 (MFCC)。如果不熟悉的小伙伴,可以回去看看KWS的解释或自行百度。
跟RNNoise有一些不一样的是我们的例子使用MFCC和梅尔刻度 (Mel-scale) 而不是他们用的OPUS-Scale 或者响度刻度 (Bark-Scale)。单纯从刻度的对比上,他们其实差别不是很大。感兴趣的同学可以自己去查查他们的区别。
系统图如下
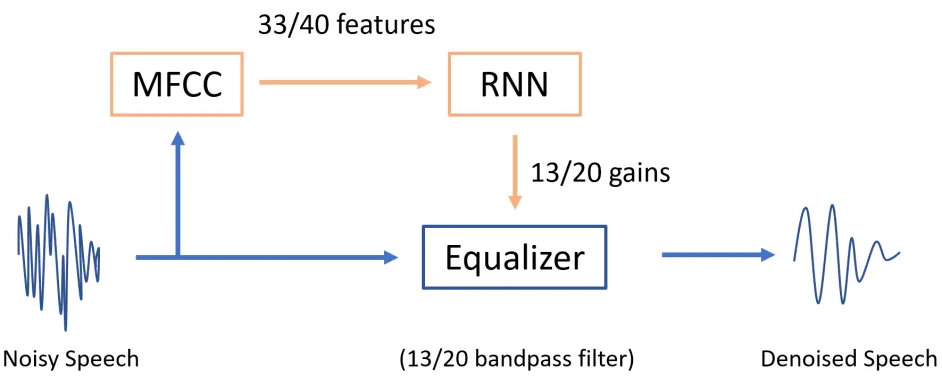
运行步骤
如果想看详细的解析,请跳到文章后半部分。这里介绍在RTT和STM32L476板子上把这套算法跑起来的步骤。
1.下载语音数据集
这里我们使用的数据集是微软的可定制语音数据集Microsoft Scalable Noisy Speech Dataset (MS-SNSD: https://github.com/microsoft/MS-SNSD)。我们可以定制时长,噪音类型,噪音混合信噪比等。你需要把整个仓库下载在 MS-SNSD/文件夹内。整个数据库有2.x GB大佬们请自行进行github加速。
下载完后,你就可以用它生成我们需要的干净的语音和带噪音的语音。同时我们还控制了语音混合的程度,也就是信噪比(SNR).
在MS-SNSD/目录下修改 noisyspeech_synthesizer.cfg 就可以配置需要生成的语音文件,推荐配置如下:
sampling_rate: 16000audioformat: *.wavaudio_length: 60silence_length: 0.0total_hours: 15snr_lower: 0snr_upper: 20total_snrlevels: 3如果打算快速测试一下,可以把 total_hour 减少为1或者2小时。
修改完后,运行 noisyspeech_synthesizer.py 就可以生成我们需要的音频WAV文件了。我们需要一对一的干净的语音和带噪音的语音,它们分别在MS-SNSD/CleanSpeech_training 和 MS-SNSD/NoisySpeech_training 内。
2. 生成训练数据集
之前一步获取到的是.wav文件,而我们训练神经网络使用的是 MFCC 和 gains。
现在我们可以运行例子提供的gen_dataset.py来计算MFCC和gains。它最终会生成一个dataset.npz文件。
在这个文件里面,你可以配置这些内容
需要MFCC的特征数(同时也会修改均衡器Equalizer的Banpass Filter的数量)。修改 num_filter = 20即可。通常数字在10到26。
这个脚本也会生成一个c工程使用的滤波器参数文件equalizer_coeff.h (generate_filter_header(...))。在C语音的均衡器中会使用这个头文件。
另外,这个脚本还会生成两个Demo音频。一个叫_noisy_sample.wav 另一个叫 _filtered_sample.wav。前者为从训练集里面选出的一个带噪音的范例,后者为用gains和均衡器滤波后文件。基本上,这个文件代表了这个降噪方法的最好的水平。后文会有详细的说明怎么生成这个gains。
3. 训练模型
当dataset.npz生成后,我们就可以跑 main.py来训练Keras模型了。训练好的模型会保存在目录下model.h5
因为我们的模型最终要放在单片机上跑,RNN 每次处理一个 timestamp,所以我们的模型设置为stateful=True 和 timestamps=1。这样的设置对于训练并不是很理想,因为反向传播(BP)没有办法很好的在很小的batch上工作。我们的Batch尽量设置得很大。这里设置batchsize >= 1024。
同时,这一步会把我们之前的噪音范例_noisy_sample.wav ,使用RNN生成的gains来滤波filtered_sig = voice_denoise(...)(可以对比我们真实gains降噪的结果)。滤波后的文件保存为_nn_filtered_sample.wav。
在最后,调用NNoM的API generate_model(...) 生成NNoM模型文件 weights.h。
4. RNN 在 NNoM 上部署
本例提供了SConstruct, 所以你可以直接在目录下运行 scons 来编译。默认使用目录下的main.c 编译成PC可执行程序。支持32/64bit windows。理论上也支持linux。
这个二进制文件可以直接对 .wav 文件降噪并生成一个新的 .wav文件,使用方法如下:
注意:仅仅支持16kHz 1CH的格式。(程序不解析WAV只复制文件头)。
Win powershell: .\rnn-denoise [input_file] [output_file] 或者拖拽.wav 文件到编译完成的*.exe上
Linux: 大家自己试试
比如,运行这个指令生成定点RNN滤波后的音频:.\rnn-denoise _noisy_sample.wav _nn_fixedpoit_filtered_sample.wav
到此,目录下一共有四个音频,大家可以试听一下。
_noisy_sample.wav --> 原始带噪音文件_filtered_sample.wav --> 用真实gains降噪的文件(训练的gains)_nn_filtered_sample.wav --> Keras浮点模型gains 降噪_nn_fixedpoit_filtered_sample.wav --> NNoM定点模型gains降噪关于演示可以看文章顶部的视频。
不过,大家可以先看个图视觉上感受一下。Filtered by NNoM是我们单片机上的效果,对比Keras是模型原始输出的效果。而Truth Gain是模型训练输入的参考,也就是最原始最好的效果。可以看到这个算法滤掉的不少的东西,具体是不是噪声。。。再说。

以下是一大波细节讲解
总的来说,我推荐大家看 gen_dataset.py 和 main.py里面的步骤,很多详细的步骤都在注释里面有相关的解释。
关于训练数据
x_train 里面包含了13或者20个(默认)MFCC,除此之外,还有前10个MFCC特征的第一和第二导数(derivative)。这些为常用的语音识别特征。所以一共有 33 到 40 个特征。
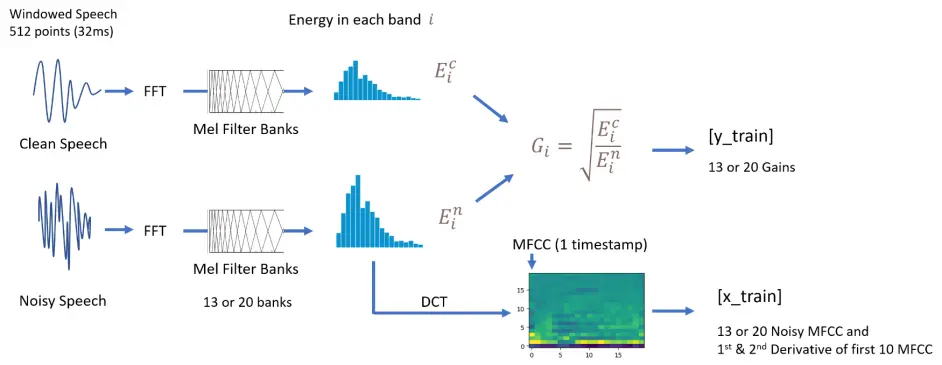
训练数据的生成步骤
y_train 里面有两组数据,一组是gains,另一个叫 VAD
Gains 与RNNoise方法相同,为 clean speech/noisy speech 在每一个band上的能量的开平方。是一组0-1的值,组大小为均衡器的带通滤波器个数。
VAD 全称叫 Voice Active Detection。为一个0-1的值,指示是否有语音。计算方法为检测一个窗口内总能量的大小是否超过一个阈值。
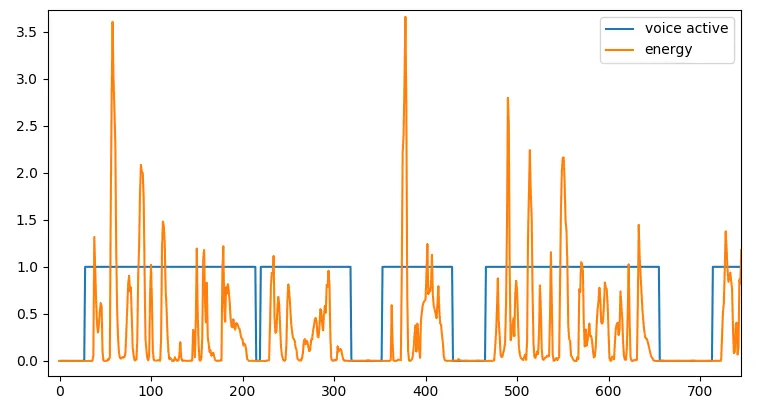
语音能量和激活阈值
关于 Gains 和 VAD
在默认的模型里面,有两个输出,其中一个便是VAD。在main_arm.c (单片机版本的Demo)里面,这个VAD值控制了板子上的一个LED。如果VAD > 0.5 LED 会被点亮。
下图为使用Keras的模型识别 VAD时刻 和 gains 的计算结果。
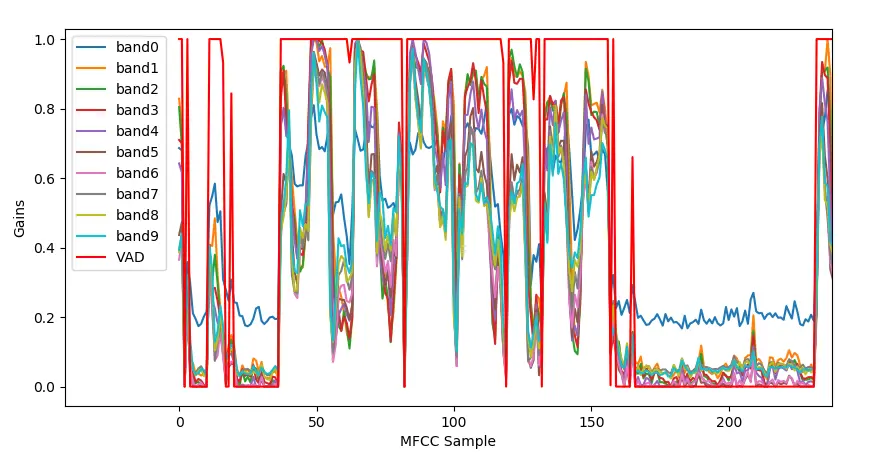
在语音中各个频段的增益
关于均衡器
这里使用了20(默认)或者13个带通滤波器(Filter Band)来抑制噪音所在的频率。实际上你可以设置成任何值。不过我推荐 大于10且小于30。每一个独立的带通滤波器的-3dB点都与它附近的带通滤波器的-3dB点相交。响频曲线如下:
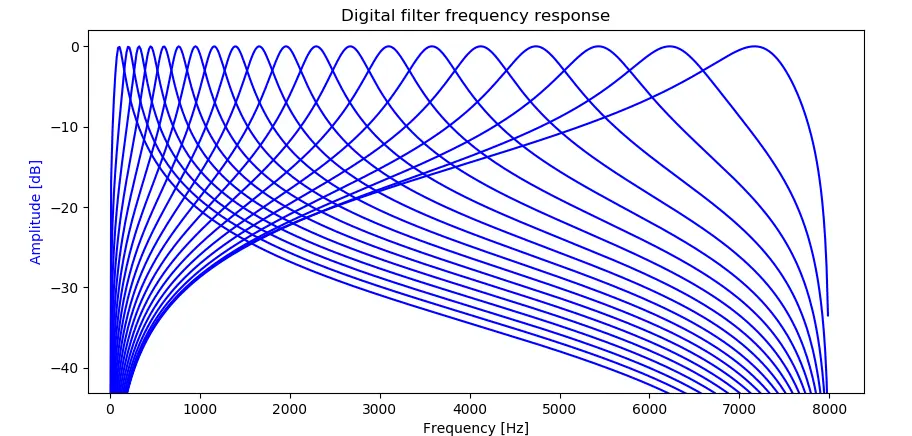
滤波器响应频率范围
音频信号会平行地通过这些带通滤波器,在最后把他们相加在一起。因为滤波器是交叉的,最终混合的信号幅度过大导致数值溢出,所以最终混合的信号会乘上一个0.6(并非数学上验证的数值)再保存在int16 数组内。
关于RNN模型的结构
这里提供了两个不同的RNN模型。一个是与RNNoise 类似的模型,各个RNN层之间包含很多的支线。这些支线会通过 concatenate 合并在一起。这个模型还会提供一个VAD输出。整个模型一共约 120k的权重。比RNNoise稍高因为做了一些针对定点模型的改变。其实这个模型有点过于复杂了,我尝试过减少模型参数,仍然可以很好的进行降噪。大佬们可以大胆地调整参数。如图下图所示。
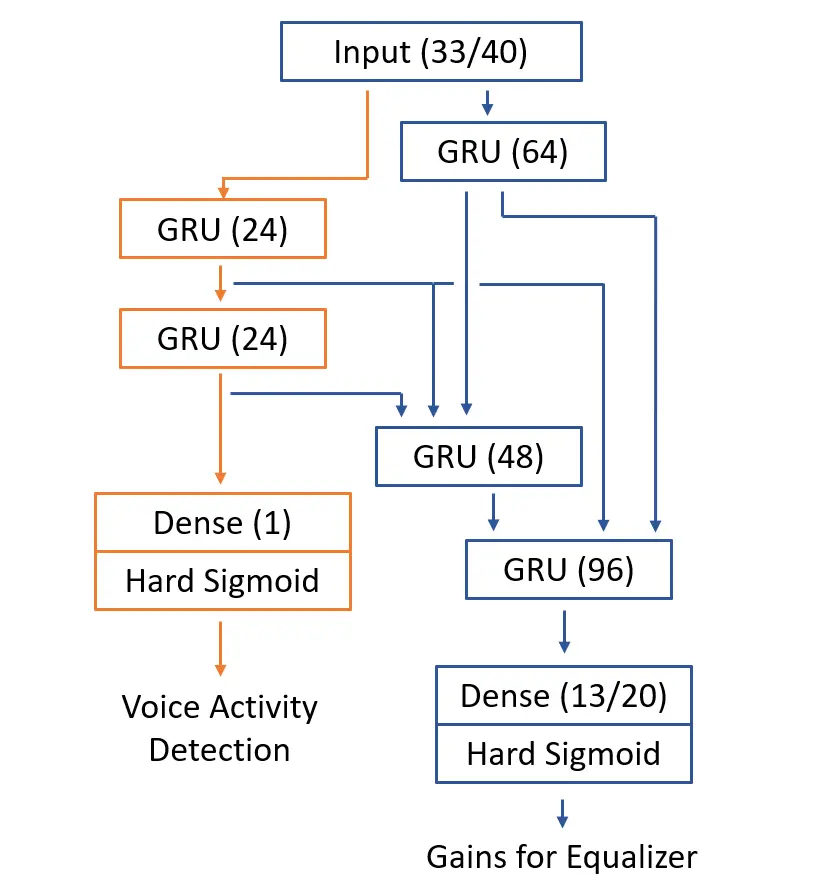
另一个模型是一个简单的多层GRU模型,这个模型不提供VAD输出。非常震惊的是这个模型也能提供不错的效果。
如果想尝试这个简单的模型,在main.py里面修改 history = train(...) 成 train_simple(...)。
Keras的RNN需要把 stateful=True 打开,这样NNoM在每计算一个timestamps的时候才不会重置state。
MCU 例子
这里提供了一个 MCU 的文件main_arm.c。这个文件针对 STM32L476-Discovery 的麦克风做了移植,可以直接使用板载麦克风进行语音降噪。
例子通过一个绿色 LED(PE8)输出VAD检测的结果,有人说话时就会亮。
除了单片机相关的代码,功能上MCU代码main_arm.c与PC代码main.c完全一致, 本例虽然做了音频降噪,但是并没有针对音频输出写驱动,所以降噪输出是被直接抛弃了。大家可以自己写保存或者回放的代码。
如果你使用的是 ARM-Cortex M系列的MCU,做以下设置可以提升性能 (参考下面性能测试章节)。
打开 NNoM 的 CMSIS-NN 后端,参考 Porting and Optimization Guide (https://github.com/majianjia/nnom/blob/master/docs/Porting_and_Optimisation_Guide.md)
在 mfcc.h里面,打开 PLATFORM_ARM 宏定义来使用ARM_FFT。
MCU 上的性能测试
传统的 RNNoise 不止包含了浮点模型,还包括了其他计算(比如Pitch Filtering),导致总计算量在40MFLOPS左右。即是换成定点计算,一般的单片机也会很吃力。
本例中,浮点FFT,定点RNN模型,浮点均衡器(滤波器),并去掉了Pitch Filtering(额其实是因为我不知道怎么用)。我对这里使用的几个运算量大的模块进行了测试,分别是MFCC部分(包含FFT),神经网络部分,还有均衡器。
测试环境为
Board: STM32L476-Discovery
MCU: STM32L476, 超频到 140MHz Cortex-M4F
音频输入: 板载PDM麦克风
音频输出: 无
IDE: Keil MDK
测试条件:
神经网络后端: CMSIS-NN 或 Local C (本地后端)
FFT 库(512点): arm_rfft_fast_f32 或 纯FFT arduino_fft
优化等级: -O0/-O1 或 -O2
均衡器滤波器数目: 13 band 或者 20 band
需要注意的是,这里使用的音频格式为 16kHz 1CH,所以我们每次更新(FFT窗口:512,overlapping=50%)只有 256/16000 = 16ms 的时间来完成所有的计算。
13 Band Equalizer
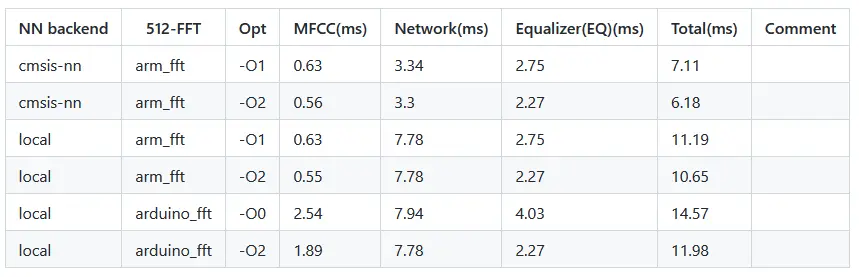
可以看到,在完全优化的情况下,最短用时仅仅6.18ms 相当于38% 的CPU占用。在不适用ARM加速库的情况下,也完全在16ms内。因为所有的计算量是固定的,测试下来同一项目内时间没有太多的波动。
20 Band Equalizer
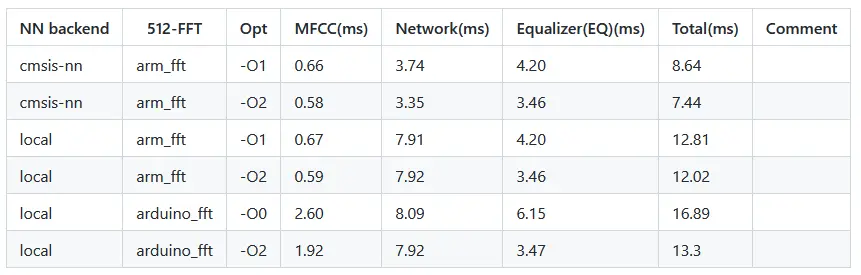
20个 band的情况下,在开启优化后也可以实现实时的语音降噪。
模型编译log
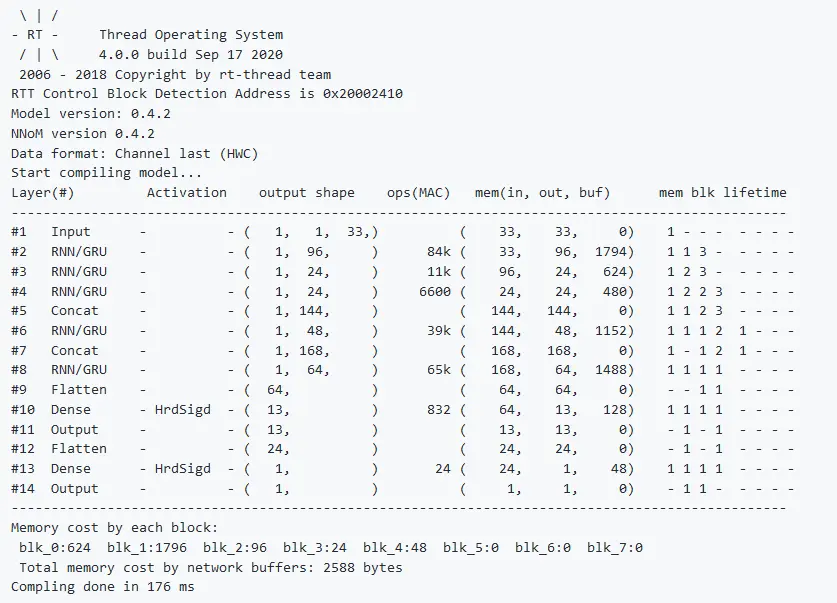
单片机内神经网络模型载入的log
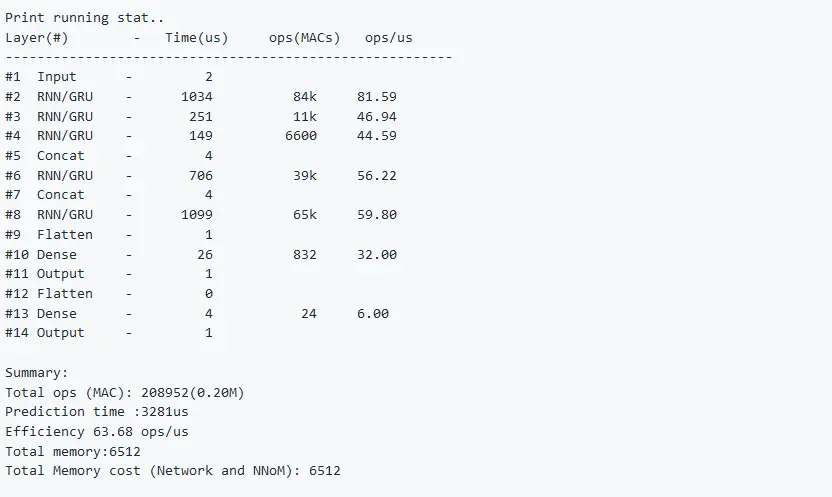
单片机内神经网络模型性能
点击阅读原文,即可下载硬声APP。
-
蓝牙耳机降噪核心技术解析:MEMS硅麦克风如何重塑听觉体验?2025-11-06 1190
-
启英泰伦通话降噪方案,采用深度学习降噪算法,让通话更清晰2023-08-22 1582
-
请问MEMS麦克风降噪了吗?2023-02-02 841
-
神经网络移植到STM32的方法2022-01-11 3293
-
如何使用RLS算法实现多麦克风降噪的设计2020-01-15 2296
-
基于MEMS技术的麦克风产品的原理及应用2019-07-05 7552
-
MEMS与ECM:比较麦克风技术2019-02-23 14624
-
麦克风技术规格解析2018-11-01 5482
-
汽车 麦克风阵列技术进行详述2018-08-10 7199
-
全球量产麦克风阵列的阵型技术盘点2018-08-08 13029
-
为什么需要麦克风阵列?2018-07-28 8232
-
麦克风降噪电路2017-04-20 11570
-
ARM怎么设计双麦克风降噪2017-04-10 4058
-
基于声纹识别技术的麦克风阵列说话人实时定位2011-03-28 1091
全部0条评论

快来发表一下你的评论吧 !
