

HPM6750 LVGLеҲ·еұҸжҖ§иғҪеҶҚжҸҗеҚҮпјҹеӨ§зҘһзҪ‘еҸӢејҖиҫҹзүҮеҶ…ж–°еӨ©ең°
жҸҸиҝ°
е…ҲжҘ«дҪ“йӘҢе®ҳвҖңRSCNвҖқиҜ„жөӢдәҶHPM6750зҡ„coremarkи·‘еҲҶеҗҺ(еҺҹж–ҮиҜ·иҮіEEWORLDжҗңзҙўRSCNпјүеҸҲеҮәе№Іиҙ§пјҒиҝҷж¬ЎвҖңRSCNвҖқе°ҶдёәжҲ‘们演зӨәеҰӮдҪ•дјҳеҢ–иҮӘе·ұжүӢдёӯзҡ„HPM6750дҪҝе®ғжҖ§иғҪжҸҗеҚҮгҖӮ
В
д»ҘдёӢжӯЈж–ҮиҪ¬иҮӘEEWORLD @RSCN
д№ӢеүҚзҡ„coremarkи·‘еҲҶжөӢиҜ„дёӯпјҢеңЁflashе’ҢramиҝҗиЎҢзҡ„жҖ§иғҪеӨ§иҮҙдёҖж ·пјҢдё»иҰҒзҡ„еҺҹеӣ иҝҳжҳҜд»Јз Ғз©әй—ҙе°ҸдәҺ32KпјҢиҝҷеҲҡеҘҪжҳҜcacheзҡ„з©әй—ҙиҢғеӣҙеҶ…пјҢHPM6750жңү32K ICACHEе’Ң32K DCACHEпјҢжҖ§иғҪдёҠжҳҜжңҖй«ҳзҡ„пјҢжүҖд»Ҙи·‘еҲҶдёҠпјҢдёӨиҖ…并没жңүеӨӘеӨ§зҡ„е·®и·қгҖӮ
В
дҪҶжҳҜпјҢеҰӮжһңд»Јз Ғз©әй—ҙи¶…иҝҮдәҶ32KпјҢиҝҷж—¶еҖҷcacheжҖ»дјҡжңүз”Ёж»Ўзҡ„ж—¶еҖҷпјҢд№ҹдјҡжңүдёҚе‘Ҫдёӯзҡ„жғ…еҶөдёӢпјҢиҝҷж—¶еҖҷйңҖиҰҒиҖғиҷ‘зҡ„жӯЈжҳҜзі»з»ҹиө„жәҗе’Ңзј–иҜ‘ж•ҙеҗҲеҲ©з”ЁгҖӮ
В
дёӢйқўд»Ҙlittlevglзҡ„benchmarkи·‘еҲҶдҫӢеӯҗиҰҒиҝӣиЎҢжҖ§иғҪжҸҗеҚҮзҡ„дёҖдёӘйӘҢиҜҒж–№жі•пјҢеҪ“然иҝҷд»…д»…дҪңдёәеҸӮиҖғпјҢ并дёҚиғҪеҶіе®ҡеӨ§еӨҡж•°еә”з”ЁеңәжҷҜгҖӮ
В
з”ұдәҺдёҠдёӘиҙҙеӯҗиҜҙжҳҺдәҶSPIзҡ„дёҖзӮ№зјәйҷ·пјҢдјҡеҜјиҮҙDMAзҡ„иҫ…еҠ©еҠҹиғҪжҸҗеҚҮ并дёҚеӨ§пјҢеңЁе®һйҷ…и·‘lvglзҡ„ж—¶еҖҷпјҢcodeж”ҫеңЁflashпјҢзј–иҜ‘еҷЁдҪҝз”ЁseggerпјҢд»Јз ҒзјәзңҒдјҳеҢ–пјҢд№ҹе…¶е®һжІЎдјҳеҢ–зҡ„жғ…еҶөдёӢпјҢз”ҹжҲҗзҡ„д»Јз ҒеҰӮдёӢпјҡ
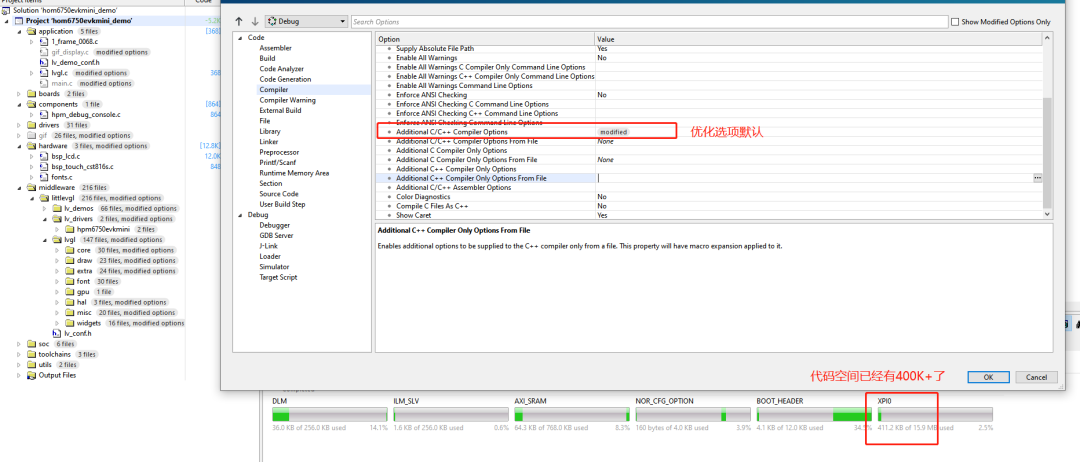
В
йӮЈд№ҲжҢүз…§иҝҷж ·зғ§еҪ•иҝӣеҺ»пјҢweightied fpsеӨ§жҰӮжҳҜ120еӨҡе·ҰеҸі
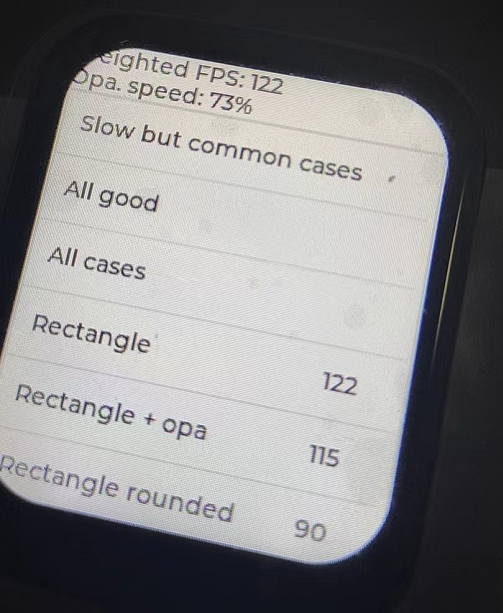
В
иҝҷжҳҜжңүзӮ№дҪҺдәҶпјҢе…Ҳд»Һlvglзҡ„й…ҚзҪ®дёҠеҺ»дјҳеҢ–пјҢlvglзҡ„еҲ·ж–°е‘ЁжңҹпјҢд»Һ30fpsжңҖеӨ§еҲ·ж–°зҺҮж”№дёә100fpsеҲ·ж–°зҺҮпјҢжҸҗеҚҮдёҠд№ҹ并дёҚжҳҜеҫҲеӨ§пјҢеӨ§жҰӮеңЁ160е·ҰеҸіеҸҳеҠЁгҖӮ

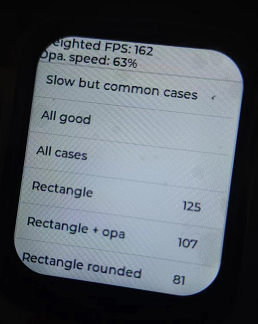
В
йӮЈд№ҲејҖO3дјҳеҢ–зҡ„ж•ҲжһңеҸҲжҳҜеҰӮдҪ•пјҢеҶҚж¬Ўзғ§еҪ•иҝӣеҺ»пјҢweightied fpsеӨ§жҰӮжҳҜ174еӨҡе·ҰеҸі
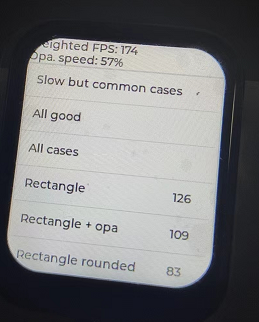
В
еҪ“然д№ҹиҜ•дәҶд»ҘдёӢж–№жі•пјҢе®һйӘҢиҝҮзЁӢд№ҹеҝҳдәҶжӢҚз…§пјҢдҪҶжҳҜе…¶е®һж•ҲжһңжҖ§иғҪ并没жңүжҸҗеҚҮеӨҡе°‘пјҢд№ҹе°ұ180е·ҰеҸіеҸҳеҠЁ
В
1гҖҒж”№дёәе…Ёе°әеҜёеҸҢзј“еҶІпјҢдҪҶжҳҜе…¶е®һиҝҷз§ҚеҜ№MCUеұҸ幕жңүз”ЁпјҢеҜ№дәҺSPIеұҸ幕дёҠпјҢж•Ҳжһң并没еӨҡе°‘гҖӮ
2гҖҒж”№дёәйқһе…Ёе°әеҜёеҸҢзј“еҶІпјҢеӨ§жҰӮдә”еҲҶд№ӢдёҖеұҖйғЁеҲ·ж–°гҖӮ
3гҖҒж”№дёәеҚ•зј“еҶІеұҖйғЁеҲ·ж–°е’ҢеҚ•зј“еҶІе…Ёе°әеҜёеҲ·ж–°пјҢж•ҲжһңеқҮдёҚеӨ§гҖӮ
В
дәҺжҳҜиҜ•зқҖжүҫдәҶе®ҳж–№зҡ„жҠҖжңҜпјҢж”ҫеҒҮжңҹй—ҙзҡ„пјҢжҠҖжңҜд№ҹеңЁдёӯеҚҲи·ҹзқҖжҲ‘иҝңзЁӢи°ғиҜ•дәҶдёӢпјҢжҚўдёәGCCзј–иҜ‘еҷЁпјҢд»ҘеҸҠејҖеҗҜдәҶзӣёе…ідјҳеҢ–пјҢдјҳеҢ–жҸҗеҚҮд№ҹдёҚжҳҺжҳҫпјҢеӨ§жҰӮд№ҹжҳҜ180fpsеҸҳеҠЁгҖӮ
В
еңЁи°ғиҜ•зҡ„иҝҮзЁӢдёӯпјҢжңүдёӘideaи®©жҘјдё»иҢ…еЎһйЎҝејҖпјҢд№ҹе°ұжҳҜе®ҳж–№жҠҖжңҜе»әи®®жҠҠдёӯж–ӯisrж”ҫеңЁramиҝҗиЎҢпјҢдҪҶе®һйҷ…жҸҗеҚҮд№ҹдёҚеӨ§гҖӮ
В
дәҺжҳҜжҘјдё»з…§зқҖиҝҷдёӘжҖқи·ҜжқҘзңӢдёӢжҖ§иғҪжңүжІЎжңүеўһеҠ пјҢд№ҹе°ұжҳҜжҠҠж ёеҝғзҡ„д»Јз ҒеҠ иҪҪеҲ°ramдёӯиҝҗиЎҢгҖӮеҘҪеңЁHPM6750жңүи¶іеӨҹзҡ„RAMжқҘеҠ иҪҪпјҢж №жҚ®жүӢеҶҢеҸҜзҹҘйҒ“пјҢдёӨж ёеҝғжңүSLVеҗ„512KпјҢSRAMдёҖе…ұ1MпјҢиҝҷжҳҜи¶іеӨҹеҠ иҪҪеҫҲеӨҡж ёеҝғд»Јз ҒгҖӮ
В

В
иҜҙе№Іе°ұе№ІпјҢеңЁд»Јз ҒдёҠеҺ»е®һзҺ°зҡ„иҜқпјҢеҸҜд»ҘдҪҝз”ЁATTR_RAMFUNCдҝ®йҘ°з¬Ұж”ҫеңЁе®ҡд№үзҡ„еҮҪж•°еүҚйқўпјҢиҝҷж ·зј–иҜ‘зҡ„ж—¶еҖҷе°ұдјҡеҠ иҪҪеҲ°RAMиҝҗиЎҢгҖӮ
В
еңЁе®һйҷ…и°ғиҜ•дёӯпјҢеҚ•зәҜеҮ дёӘеҮҪж•°зҡ„дҝ®йҘ°е№¶дёҚиғҪи§ЈеҶій—®йўҳгҖӮд№ҹдёҚеҸҜиғҪеҺ»жүӢеҠЁдёҖдёӘдёҖдёӘдҝ®йҘ°пјҢеҘҪеңЁдёҺSESеҸҜд»ҘеҸҜи§ҶеҢ–еҺ»ж“ҚдҪңеҠ иҪҪгҖӮд»ҺATTR_RAMFUNCпјҢLinkж–Ү件еҸҜзңӢеҲ°гҖӮ
В
ATTR_RAMFUNCжҳҜжҠҠеҮҪж•°ж”ҫеңЁдәҶsectionзҡ„.fastдёӯ
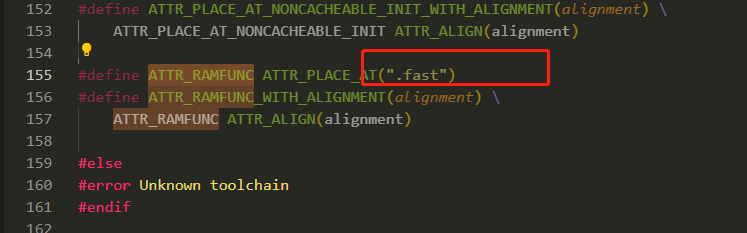
В
д»ҺLinkеҸҜзңӢеҲ°пјҢfastжҳҜж”ҫеңЁдәҶILM_SLVзҡ„256Kз©әй—ҙдёӯгҖӮ

В
дәҺжҳҜжҲ‘们еҸҜд»ҘеҸӮиҖғLinkпјҢиҮӘе·ұеңЁcopyдёӘlink,жҠҠfastж”ҫеңЁжӣҙеӨ§зҡ„RAMдёҠпјҢд№ҹе°ұжҳҜSRAMдёҠ

В
йӮЈд№ҲsesеҰӮдҪ•еҺ»еҠ иҪҪиҝҷдәӣеҮҪж•°еҲ°RAMдёҠдәҶпјҢи·ҹkeilзұ»дјј
В
еҸій”®зӮ№еҮ»йңҖиҰҒеҠ иҪҪзҡ„ж–Ү件еӨ№пјҢйҖүжӢ©options
В
В
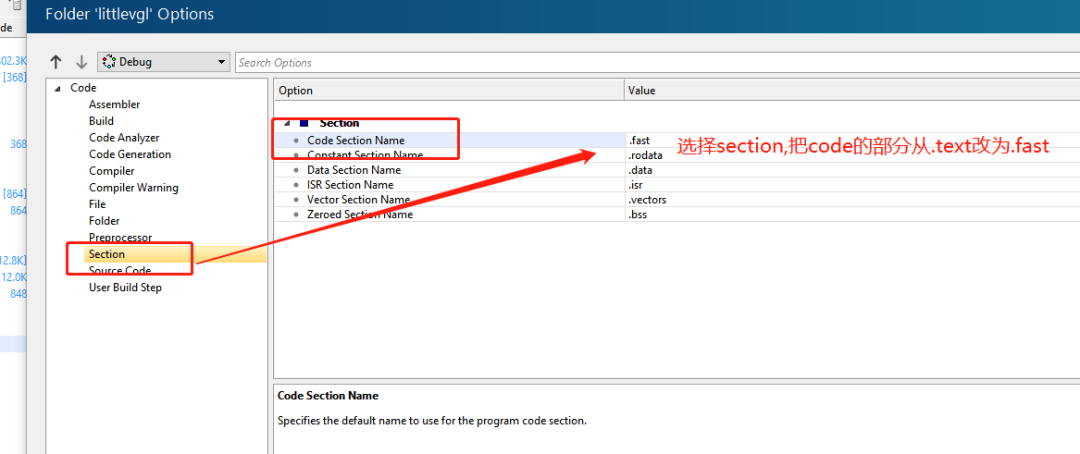
йҖүжӢ©codeж®өж”№дёә.fastпјҢиҝҷж ·е°ұеҸҜд»ҘдёҖж¬Ўжҗһе®ҡеҠ иҪҪжүҖжңүйңҖиҰҒеҲ°RAMиҝҗиЎҢзҡ„еҮҪж•°гҖӮ
В
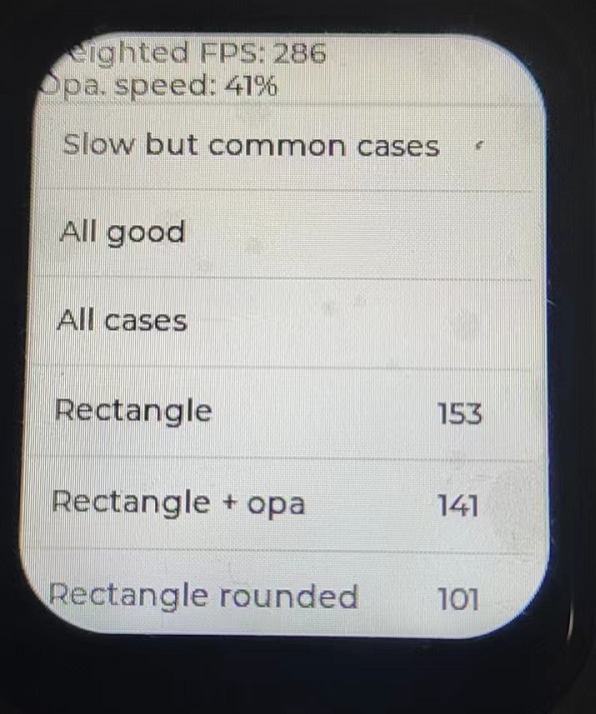
ж №жҚ®д№ӢеүҚзҡ„и°ғиҜ•жҖ§иғҪпјҢеҶҚеҠ иҪҪж ёеҝғзҡ„ж”ҫеңЁRAMдёӯиҝҗиЎҢпјҢзғ§еҪ•д»Јз ҒиҝӣеҺ»пјҢеҘҮиҝ№зҡ„ж—¶еҲ»пјҢд»Һ122fpsжҸҗеҚҮеҲ°286пјҢж•ҙж•ҙжҸҗеҚҮдәҶдёӨеҖҚжҖ§иғҪпјҢиҝҷе·Із»ҸеҜ№дәҺSPIиҝҷдёӘзЁҚеҫ®зјәйҷ·IPпјҢи¶іеӨҹжңүеё®еҠ©дәҶгҖӮ
В
дәҺжӯӨжҖ»з»“пјҡ
1гҖҒеңЁд»Һд»Јз ҒдјҳеҢ–пјҢзј–иҜ‘еҷЁдјҳеҢ–дёҠпјҢеҸҜд»ҘжҸҗй«ҳжҖ§иғҪгҖӮ
2гҖҒеңЁ1зҡ„еҹәзЎҖдёҠпјҢйҡҸзқҖд»Јз Ғз©әй—ҙзҡ„еўһеӨҡпјҢ32k cacheжҖ»жңүз”Ёе®Ңзҡ„ж—¶еҖҷпјҢxip flash д№ҹдјҡжңүжүҖжҚҹеӨұжҖ§иғҪпјҢжңҖеҘҪе°ұжҳҜеҸҜд»ҘжҠҠдё»иҰҒзҡ„д»Јз ҒеҠ иҪҪеҲ°RAMдёӯиҝҗиЎҢпјҢжӣҙеҸҜжҸҗй«ҳжҖ§иғҪгҖӮ
3гҖҒйҷӨдәҶ32K cacheзҡ„еҠ жҢҒпјҢеҶ…йғЁRAMж•ҙеҗҲд№ҹжңүи¶іеӨҹ2MпјҢеҜ№дәҺзі»з»ҹиҖҢиЁҖпјҢжҳҜи¶іеӨҹжҖ§иғҪж•ҙеҗҲзҡ„гҖӮ
В
- зӣёе…іжҺЁиҚҗ
- зғӯзӮ№жҺЁиҚҗ
- е
-
гҖҗж·ұеәҰжөӢиҜ„гҖ‘HPM6750 MCUзүҮеҶ…16дҪҚADCзІҫеәҰжөӢиҜ•2023-10-30 4581
-
HPM6750 д»Һ XPI0 CB з«ҜеҸЈеҗҜеҠЁ2023-10-21 2269
-
HPM6750 ADC EVKз”ЁжҲ·дҪҝз”ЁжүӢеҶҢ2023-09-19 678
-
HPM6750е’ҢHPM6450жҳҜPIN to PINзҡ„еҗ—пјҹ2023-06-08 1188
-
HPM6750жңүжІЎжңүејҖеҗҜLV_USE_GPU_HPM_PDMAзҡ„дҫӢзЁӢ?2023-05-26 1022
-
еҰӮдҪ•дҪҝз”ЁCodeViserи°ғиҜ•е…ҲжҘ«HPM6750ејҖеҸ‘жқҝпјҹ2023-03-21 1221
-
RT-THREADеңЁHPM6750дёӯзҡ„зі»зөұеҝғи·іеӨ„зҗҶз–‘й—®жұӮи§Ј2023-02-02 1589
-
еҜ№HPM6750зҡ„иҝҷеҮ з§Қи°ғиҜ•ж–№ејҸеұ•ејҖд»Ӣз»Қ2023-02-01 6692
-
HPM6750ејҖеҸ‘зҺҜеўғжҗӯе»әеҸҠеҝ«йҖҹдёҠжүӢ2022-12-20 5758
-
HPM6750еҚ•зүҮжңәADзҡ„еҺҹзҗҶеӣҫдёҺPCBе°ҒиЈ…еә“2022-10-21 1078
-
еҸҰиҫҹи№Ҡеҫ„пјҢзңӢеӨ§зүӣеҰӮдҪ•еңЁCLionдёӯејҖеҸ‘HPM67502022-09-22 6576
-
жөӢиҜ„еҲҶдә« | HPM6750 иғҪи·‘ openmv е•ҰпјҒ2022-09-01 3440
-
жөӢиҜ„еҲҶдә« | 150fps пјҒHPM6750 LCDC еҲ·еұҸжҜ«ж— еҺӢеҠӣ2022-08-05 4213
-
еӨ§зҘһжөӢиҜ„ | з»“жһңеҮәд№Һж„Ҹж–ҷ! е…ҲжҘ«HPM6750 CoreMark и·‘еҲҶжөӢиҜ•2022-06-13 3840
е…ЁйғЁ0жқЎиҜ„и®ә

еҝ«жқҘеҸ‘иЎЁдёҖдёӢдҪ зҡ„иҜ„и®әеҗ§ !
