

AT32讲堂016 | AT32 MCU DSP使用案例和网络神经算法CMSIS-NN案例
描述
概述
AT32F4xx使用的是ARM Cortex-M4F内核。ARM Cortex-M4F是带有FPU内核处理器是一款32位的RISC处理器,具有优异的代码效率,采用通常8位和16位器件的存储器空间即可发挥ARM内核的高性能。该处理器支持一组DSP指令,能够实现有效的信号处理和复杂的算法执行。其单精度FPU(浮点单元)通过使用元语言开发工具,可加速开发,防止饱和。
本文重点介绍基于AT32 MCU的DSP指令相关库函数及其简单应用示例,主要内容有:
- ARM Cortex-M4F内核
- ARM官方CMSIS DSP库概述
- CMSIS DSP库移植到AT32
- 常用示例展示
- CMSIS NN with DSP
注意:本文是基于AT32F403A的硬件条件,若使用者需要在AT32其他型号上使用,请修改相应配置即可。
AT32 MCU与M4F内核
AT32F403A系列与所有的ARM工具和软件兼容。这些丰富的外设配置,使得AT32系列微控制器适合于多种应用场合:
- 消费类产品
− 手持云台− 微型打印机− 条形码扫描枪− 读卡器− 灯光控制
- 物联网应用
− 智能家居应用− 物联网传感器节点
- 工业应用
− 双CAN应用(OBD-II)− 光电编码器− 充电桩/BMS− 机器人控制− 电力控制
- 电机控制
− BLDC/PMSM电机控制− 变频器− 伺服电机控制
系统架构
AT32F403A系列微控制器包括ARM CortexTM-M4F处理器内核、总线架构、外设以及存储器构成。CortexTM-M4F处理器是一种新时代的内核,拥有许多先进功能。对比于CortexTM-M3,CortexTM-M4F处理器支持增强的高效DSP指令集,包含扩展的单周期16/32位乘法累加器MAC、双16位MAC指令、优化的8/16位SIMD运算及饱和运算指令,并且具有单精度IEEE-754浮点运算单元FPU。当设计中使用带DSP功能的CortexTM-M4F时就能格外节能,比软件解决方案更快,使CortexTM-M4F适用于那些要求微控制器提供高效能与低功耗的产品市场。
1) Cortex-M4内核架构
图1. Cortex-M4内核架构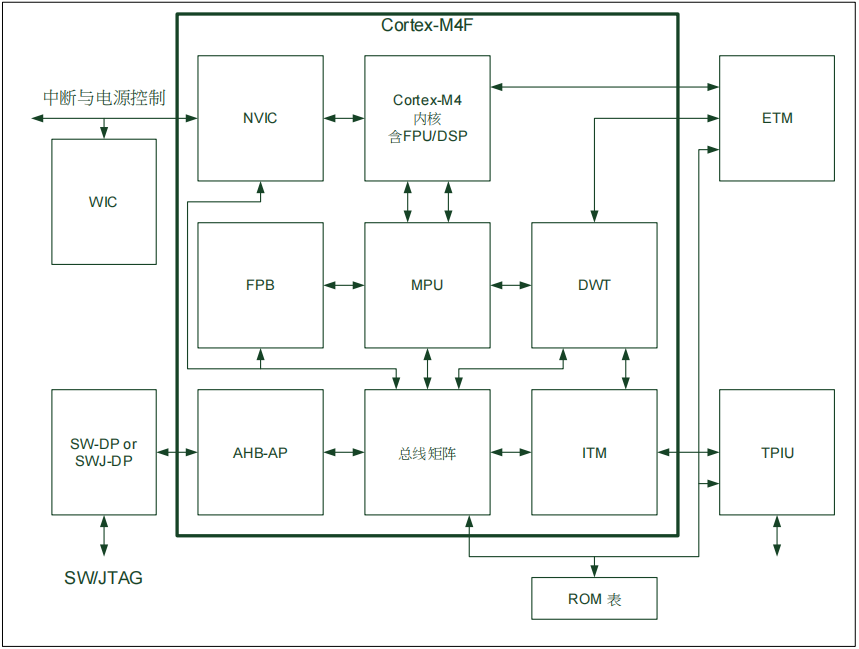
2) Cortex-M4与Cortex-M3的区别
表1. Cortex-M4与Cortex-M3的区别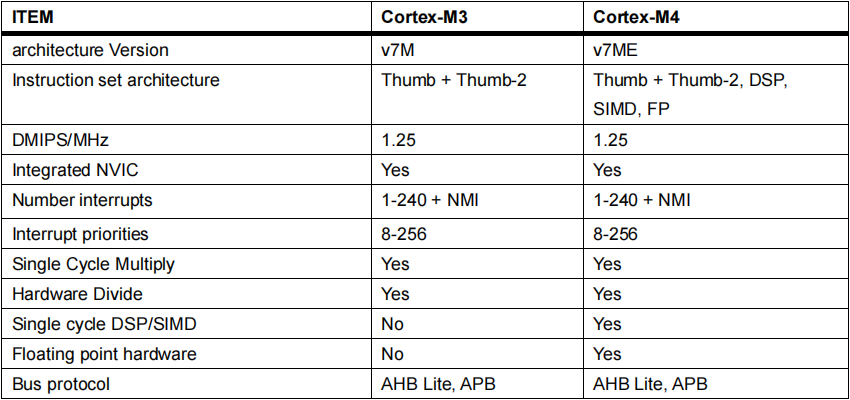
3) 部分DSP指令的介绍
表2. 单周期MAC指令介绍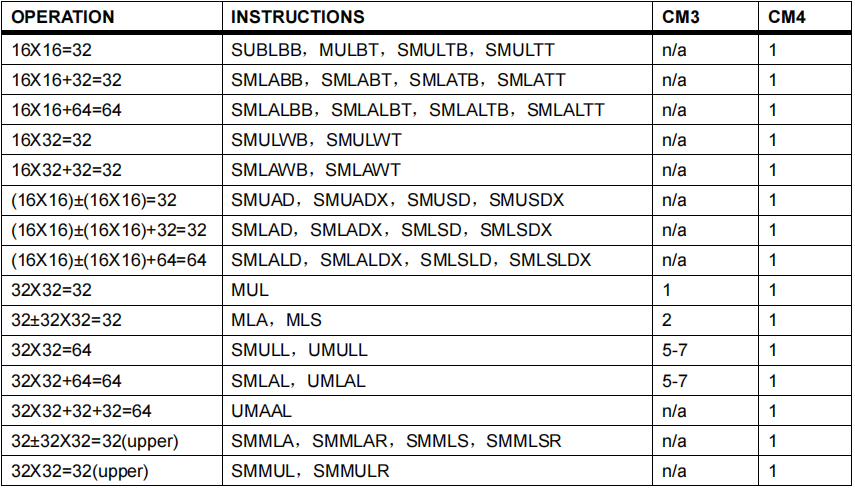 注意:上面所有的指令操作在CM4处理器上都只需一个指令周期。
注意:上面所有的指令操作在CM4处理器上都只需一个指令周期。
4) Cortex-M4 DSP指令比较
表3. Cortex-M4 DSP指令比较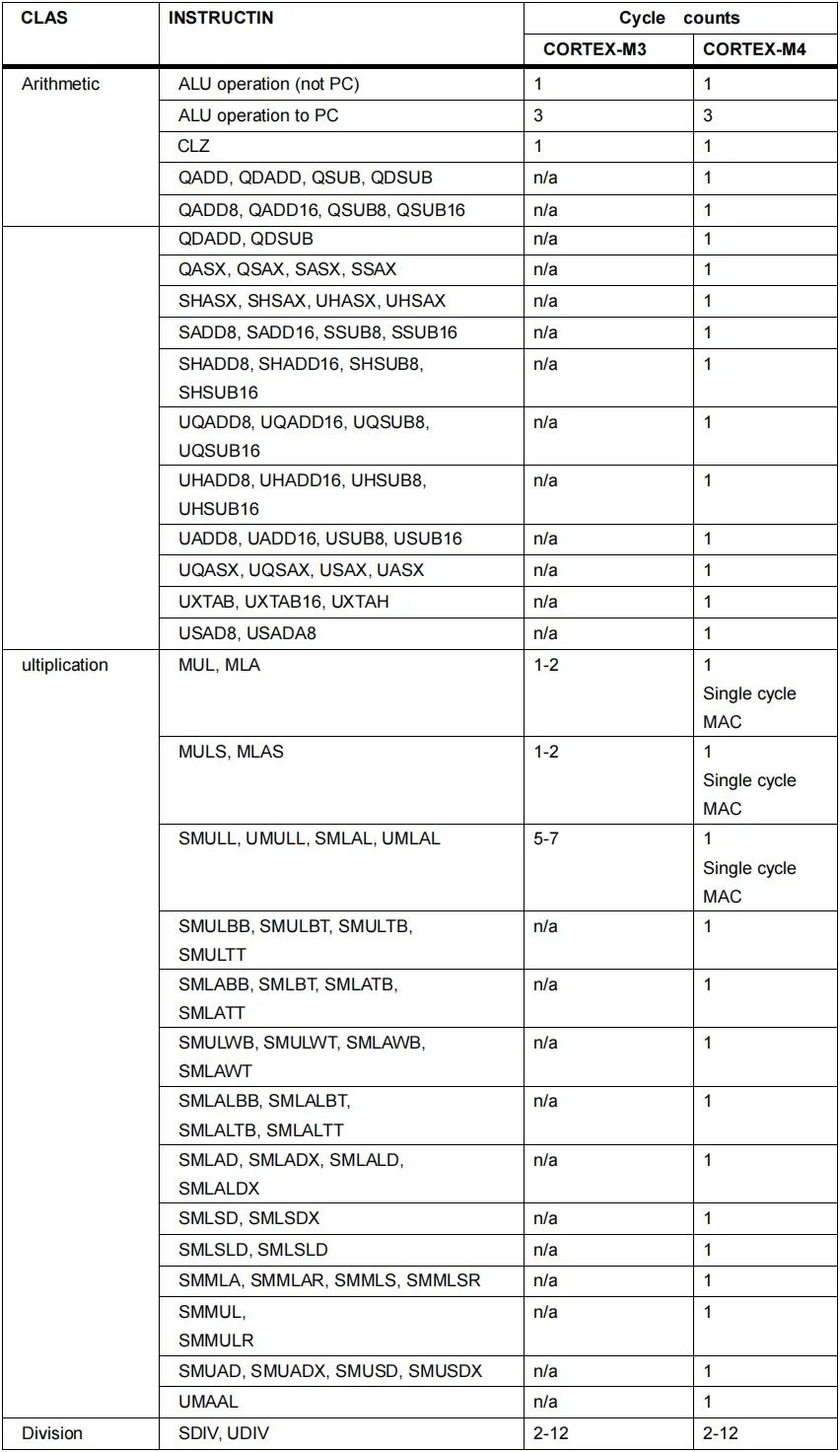
5) 编译器对DSP指令的支持
表4. 编译器对DSP指令的支持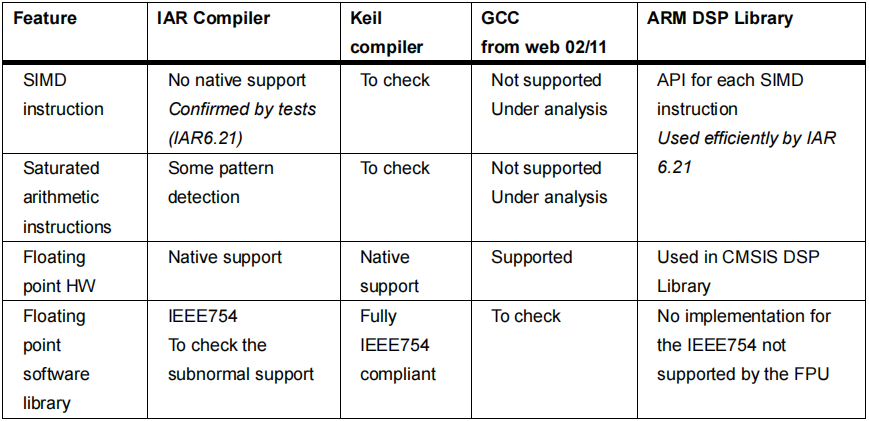
6) AT32F403A系统架构
图2. AT32F403A系统架构图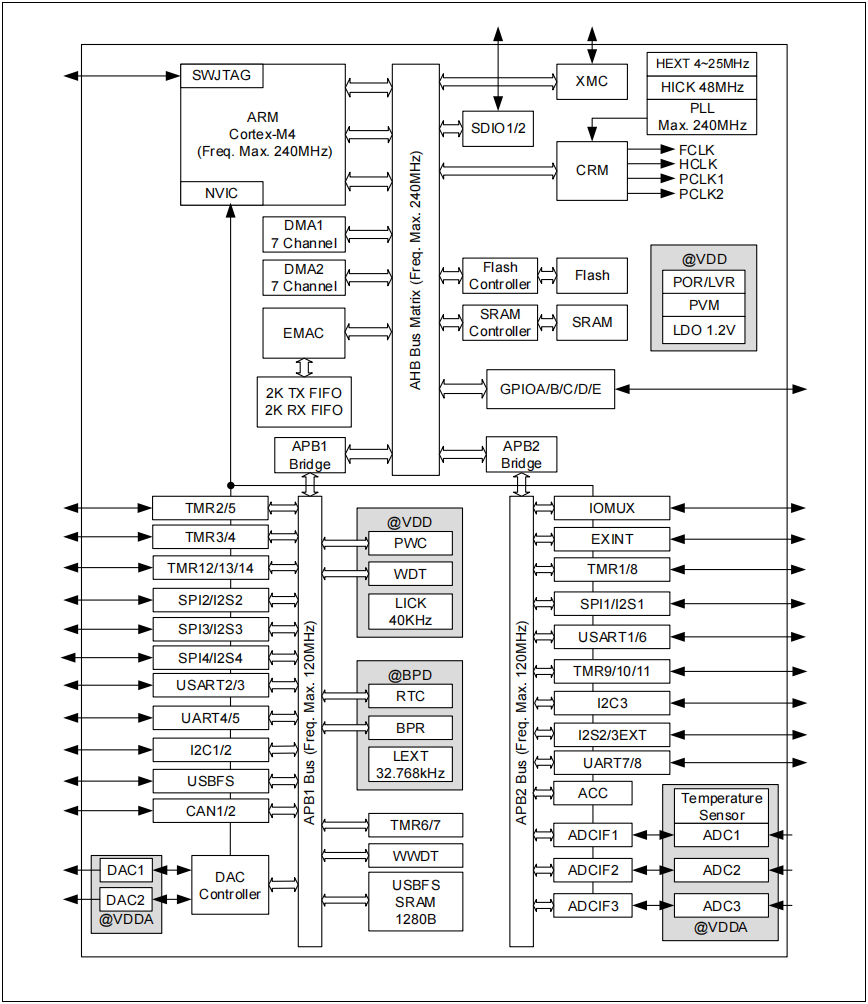 注意:AT32F403A不支持EMAC,AT32F407/407A支持EMAC
注意:AT32F403A不支持EMAC,AT32F407/407A支持EMAC
ARM官方CMSIS DSP库概述
CMSIS DSP库说明
CMSIS DSP软件库,是针对使用Cortex-M内核芯片提供一套数字信号处理函数。CMSIS DSP库大部分函数都是支持f32,Q31,Q15和Q7四种格式的。该库分为以下几个功能:
- 基本数学函数Basic math functions
- 快速数学函数Fast math functions
- 复数型数学函数Complex math functions
- 滤波器函数Filters
- 矩阵型函数Matrix functions
- 数学变换型函数Transform functions
- 电机控制函数Motor control functions
- 统计型数学函数Statistical functions
- 支持型数学Support functions
- 插补型数学函数Interpolation functions
针对以上每一种类型的库函数,下文会有详细介绍其使用方法和使用示例。
CMSIS DSP库文件
考虑到方便用户使用,ARM官方已编译好Cortex-M各型号的.lib库文件,并放置于Lib文件夹。与AT32F4xx相关的.Lib库文件主要有以下两种
- arm_cortexM4lf_math.lib (Cortex-M4, Little endian, Floating Point Unit) for AT32F403 and AT32F413
- arm_cortexM4l_math.lib (Cortex-M4, Little endian) for AT32F415
DSP库函数的声明位域头文件arm_math.h中,用户只要简单地将该头文件和.lib文件添加到自己的工程中,即可呼叫DSP库函数。该头文件对于浮点运算单元(FPU)的变量同样适用。
CMSIS DSP库示例
该CMSIS DSP库中的多个示例可以很好地展现DSP库函数的使用。
CMSIS DSP库的工具链支持
该DSP库已经可以在5.14版本MDK上开发和测试过。另外针对GCC编译器和IAR IDE,已经支持。
编译生成DSP的.lib库文件
该DSP安装包中已包含一个基于MDK的工程,通过编译该工程可生成需要的.lib库文件。该MDK工程位于CMSIS\DSP\Projects\ARM文件夹中。工程名为
- arm_cortexM_math.uvprojx
通过打开并编译该arm_cortexM_math.uvprojx MDK工程,可以生成该DSP的.lib库文件。这样用户就可以根据特定的内核,特定的优化选择去编译特定DSP的.lib库文件。同时,通过该MDK工程,用户也可以查看与修改指定的库函数原型,便于了解库函数的实现原理。
CMSIS-DSP文件夹结构
以下表格展现了CMSIS-DSP文件夹结构表5. CMSIS-DSP文件夹结构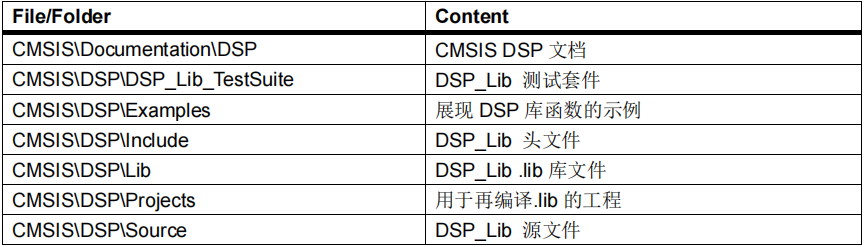
CMSIS DSP库移植到AT32
本文主要介绍DSP库在MDK上的移植方法。
ARM官方CMSIS DSP函数详解
- 基本数学函数Basic math functions
- 快速数学函数Fast math functions
- 复数型数学函数Complex math functions
- 滤波器函数Filters
- 矩阵型函数Matrix functions
- 数学变换型函数Transform functions
- 电机控制函数Motor control functions
- 统计型数学函数Statistical functions
- 支持型数学Support functions
- 插补型数学函数Interpolation functions
详细使用方法和使用案例请参考1) ARM官网DSP培训资料地址:http://www.keil.com/pack/doc/CMSIS_Dev/DSP/html/index.html
AT32 DSP库快速使用
硬件资源1) 指示灯LED2/LED3/LED42) USART1(PA9/PA10)3) AT-START-F403A V1.0实验板图3. AT-START-F403A V1.0实验板 注:该DSP demo是基于AT32F403A的硬件条件,若使用者需要在AT32其他型号上使用,请修改相应配置即可。软件资源
注:该DSP demo是基于AT32F403A的硬件条件,若使用者需要在AT32其他型号上使用,请修改相应配置即可。软件资源
1) Libraries
- drivers AT32底层驱动库
- cmsis CMSIS DSP库和CMSIS NN库
2) Project\AT_START_F403A
- examples,本文使用到的示例,如5_1_arm_class_marks_example,“5_1”表示章节,“arm_class_marks_example”表示示例名称
- templates,基于.lib建立的DSP template工程
3) Doc
a) AN0036_DSP_Instruction_and_Library_on_AT32_ZH_V2.x.x.pdf
DSP demo使用1) 打开AT32_DSP_DEMO_2.x.x\project\at_start_xxx\templates,编译后下载到实验板
2) 观察LED2/LED3/LED4,若依次翻转则表明程序有正确执行DSP函数。
常用示例展示
本节主要通过使用前面介绍的DSP库函数进行案列展示,展示的示例如下:
- 班级成绩统计示例
- 卷积示例
- 点积示例
- 频率仓示例
- 低通滤波示例
- 图形音频均衡器示例
- 线性插值示例
- 矩阵示例
- 信号收敛示例
- 正弦余弦示例
- 方差示例
- 卷积网络神经示例
班级成绩统计示例
描述:演示使用最大,最小,均值,标准差,方差和矩阵函数来统计一个班级的成绩。注意:此示例还演示了静态初始化的用法。变量说明:
- testMarks_f32:指向20名学生在4门学科中获得的分数
- max_marks:最高分成绩
- min_marks:最低分成绩
- mean:所有成绩的平均分
- var:所有成绩的方差
- std:标准差
- numStudents:学生总数
使用到DSP软件库的函数有:
- arm_mat_init_f32()
- arm_mat_mult_f32()
- arm_max_f32()
- arm_min_f32()
- arm_mean_f32()
- arm_std_f32()
- arm_var_f32()
参考
AT32_DSP_DEMO\project\at_start_f403a\examples\5_1_arm_class_marks_example
卷积示例
描述:本示例主要展示基于复数 FFT、复数乘法与支持函数的卷积理论。
算法:
卷积理论指出,时域中的卷积对应频域中的乘法。因此,两个信号的卷积后的傅里叶变换等于他们各自的傅里叶变换的乘积。使用快速傅里叶变换(FFT)可以有效的评估信号的傅里叶变换。两个输入信号a[n]和b[n]填充为零,n1和n2分别对应其信号长度。因此他们的长度将变为N,N大于或等于n1+n2-1。由于采用基4变换,因此基数为4。a[n]和b[n]的卷积是通过对输入信号进行FFT变换,对联更新好进行傅里叶变换。并对相乘后的结果进行逆FFT变换来获得的。
由以下公式表示:
A[k]=FFT(a[n],N)B[k]=FFT(b[n],N)conv(a[n], b[n])=IFFT(A[k]*B[k], N)其中A[k]和B[k]分别是信号a[n]和b[n]的N点FFT。卷积长度为n1+n2-1
框图:
图4. 卷积算法框图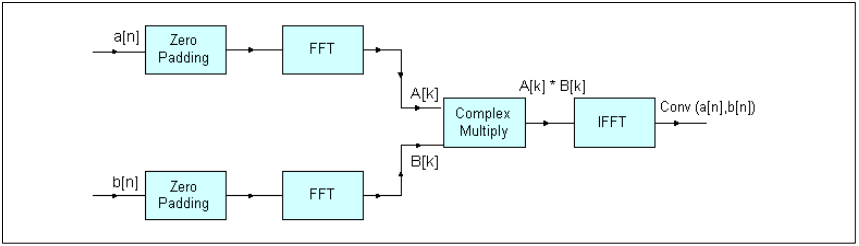 变量说明
变量说明
- testInputA_f32:指向第一个输入序列
- srcALen: 第一个输入时序的长度
- testInputB_f32:指向第二个输入序列
- srcBLen:第二个输入时序的长度
- outLen:卷积输出序列的长度,(srcALen+srcBLen-1)
- AxB:指向FFT乘积后输出数组地址
使用到DSP软件库的函数有:
- arm_fill_f32()
- arm_copy_f32()
- arm_cfft_radix4_init_f32()
- arm_cfft_radix4_f32()
- arm_cmplx_mult_cmplx_f32()
参考
AT32_DSP_DEMO\project\at_start_f403a\examples\5_2_arm_convolution_example
点积示例
描述:本示例主要展示如何使用相乘和相加来实现点积。两个向量的点积是通过将对应元素相乘并相加来获得的。
算法:
将长度为n的两个输入向量A和B诸个元素相乘,然后相加以获得点积。
由以下公式表示:
dotProduct=A[0]*B[0]+A[1]*B[1]+...+A[n-1]*B[n-1]
框图:
图5. 点积算法框图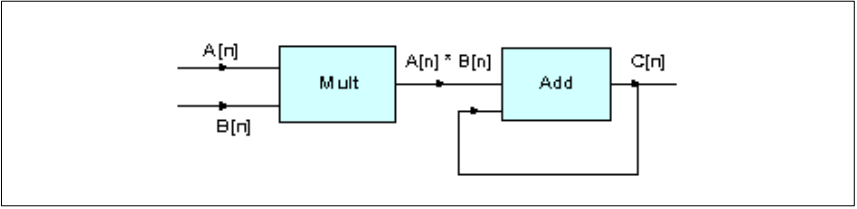
变量描述:
- srcA_buf_f32:指向第一个输入向量
- srcB_buf_f32:指向第二个输入向量
- testOutput:存储两个向量的点积
使用到DSP软件库的函数有:
- arm_mult_f32()
- arm_add_f32()
参考AT32_DSP_DEMO\project\at_start_f403a\examples\5_3_arm_dotproduct_example
频率仓示例
描述:该示例主要展示使用复数FFT,复数幅值和最大值函数在输入信号的频域中计算最大能量仓。
算法:
输入测试信号为一个10 kHz信号,该信号具有均匀分布的白噪声。通过计算输入信号的FFT计算可以得到与10 kHz输入频率相对应的最大能量仓。
框图:
图6. 频率仓算法框图
图8展示了具有均匀分布白噪声的10 kHz信号的时域信号,图9展示了这个输入信号的对应的频域信号,其中出现最高点的数对应的频率即为10 kHz信号能量仓。
图7. 输入信号的时域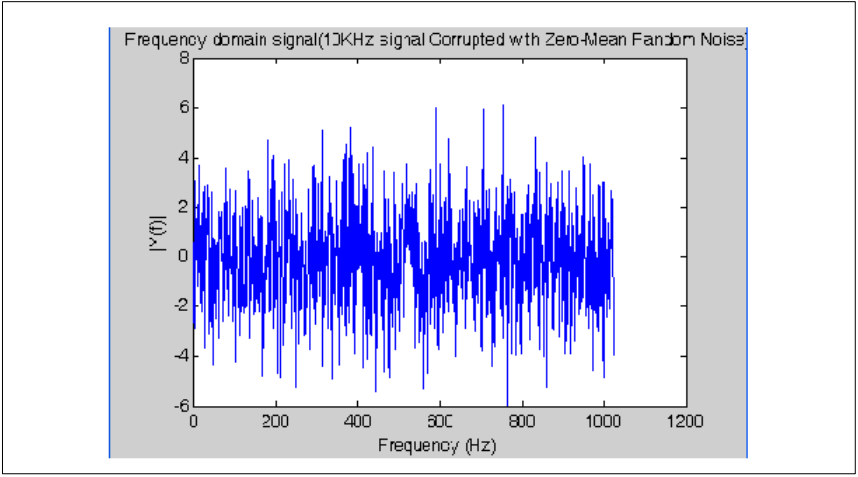
图8. 输入信号的频域
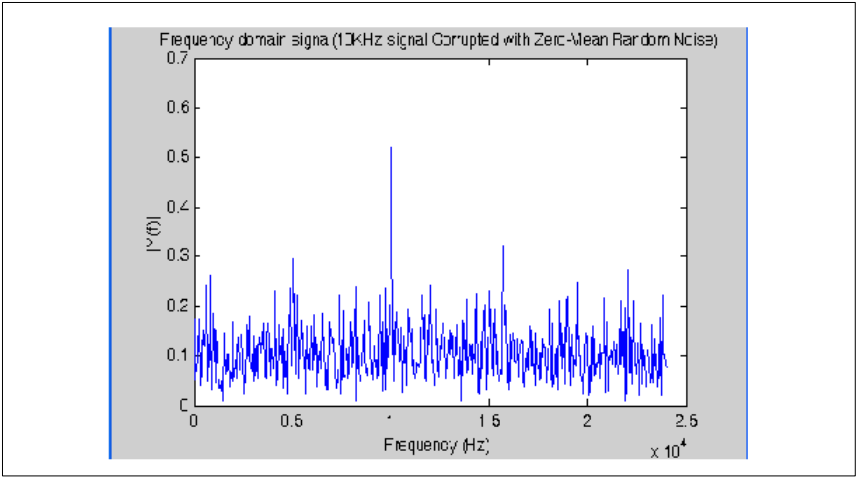 输入信号的频域变量描述
输入信号的频域变量描述
- testInput_f32_10khz:指向输入数据
- testOutput:指向输出数据
- fftSize l:FFT的长度
- ifftFlag flag:用于选择 CFFT/CIFFT
- doBitReverse Flag:用于选择是顺序还是逆序
- refIndex:参考索引值,在该值处能量最大
- testIndex:计算出的索引值,在该值处能量最大
使用到DSP软件库的函数有:
- arm_cfft_f32()
- arm_cmplx_mag_f32()
- arm_max_f32()
参考AT32_DSP_DEMO\project\at_start_f403a\examples\5_4_arm_fft_bin_example
FIR低通滤波示例
描述:使用FIR低通滤波器从输入中去除高频信号部分。本示例展示了如何配置FIR滤波,然后以块方式传递数据。图9. FIR低通滤波算法框图
算法:
输入信号时两个正弦波的叠加:1 kHz and 15 kHz.该信号将被截止频率为6 kHz的进行低通滤波。低通滤波器滤掉了15 kHz信号,仅留下1 kHz信号输出。低通滤波器采用MATLAB设计,采样率为48 kHz,长度为29点。生成滤波器的MATLAB代码如下:h=fir1(28, 6/24);第一个参数是过滤器的“顺序”,并且总是比所需长度小1,。第二个参数是归一化截止频率。范围是0(DC)到1.0(Nyquist)。24 kHz奈奎斯特频率的6kHz截止频率为6/24=0.25归一化频率。CMSIS FIR滤波器函数要求系数按时间倒序排列。所得滤波器系数如下图所示。需要注意的是,该滤波器是对称的(线性相位FIR滤波器的属性)。对称点是样本14,对于所有频率,该滤波器具有14个样本的延迟。图10. 低通滤波时域响应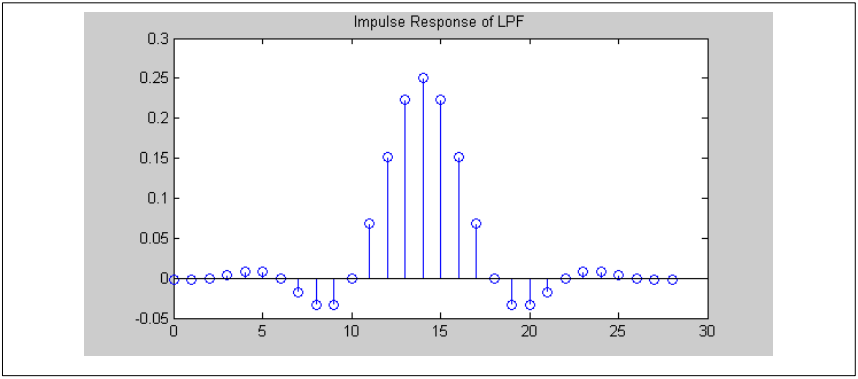
接下来显示滤波器的响应。滤波器的带通增益为1.0,截止频率为6kHz时达到0.5。
图11. 低通滤波频域响应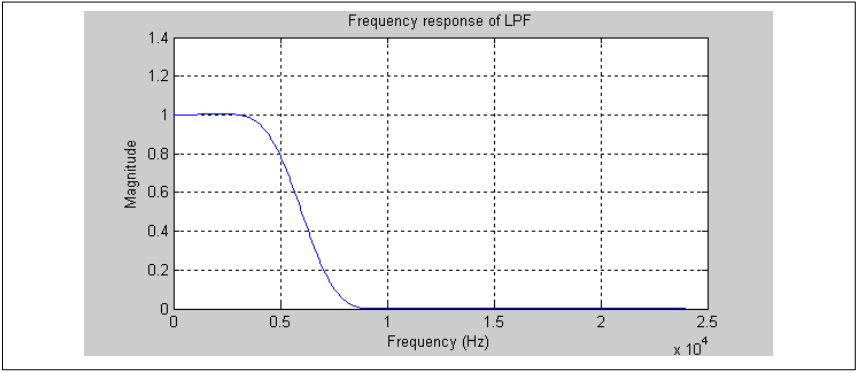
输入信号如下所示。左侧显示时域信号,右侧显示频域。可以清楚的看到两个正弦波分量。
图12. 输入信号的时域信号和频域信号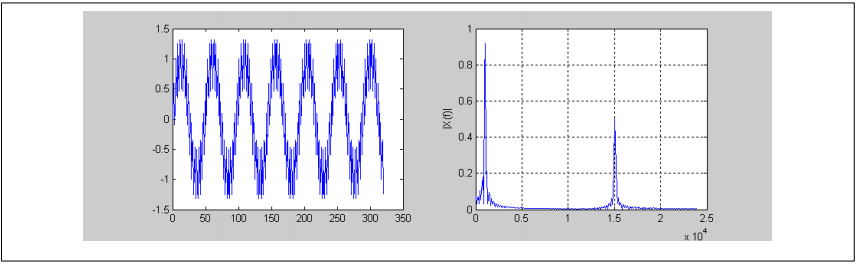
滤波器输出如下所示,15kHz分量已被消除。
图13. 输出信号的时域信号和频域信号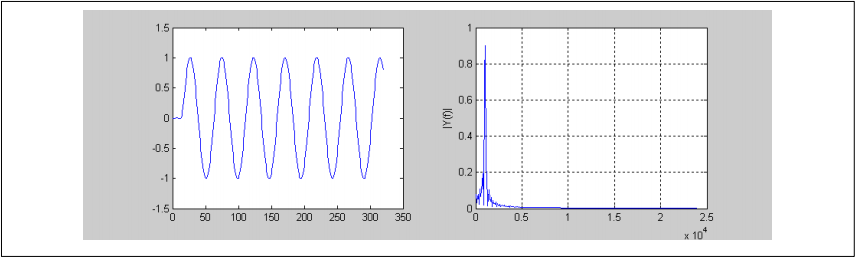
变量描述:
- testInput_f32_1kHz_15kHz:指向输入数据
- refOutput points to the reference output data:指向参考输出数据
- testOutput points to the test output data:指向测试输出数据
- firStateF32 points to state buffer:指向状态缓冲区
- firCoeffs32 points to coefficient buffer:指向系数缓冲区
- blockSize number of samples processed at a time:一次处理的样本数
- numBlocks number of frames:帧数
使用到DSP软件库的函数有:
- arm_fir_init_f32()
- arm_fir_f32()
参考
AT32_DSP_DEMO\project\at_start_f403a\examples\5_5_arm_fir_example
图形音频均衡器示例
描述:本示例展示了如何使用Biquad级联函数构造5频段图形均衡器。在音频应用中使用图形均衡器来改变音频的音质。
框图:
该设计是基于五级滤波器的级联图14. 五级滤波器联算法框图
每个滤波器部分均为40阶,由两个Biquad级联组成。每个滤波器的标称为0 dB(线性单位为1.0)并对特定频率范围内的信号进行增强或截止。5个频率段之间的边缘频率为100、500、2000和6000 Hz。每个频段都有一个可调的增强或消减范围,范围为+/- 9 dB。列如,从500到2000 Hz的频宽具有如下所示响应:
图15. 从200Hz到2KHz的频宽响应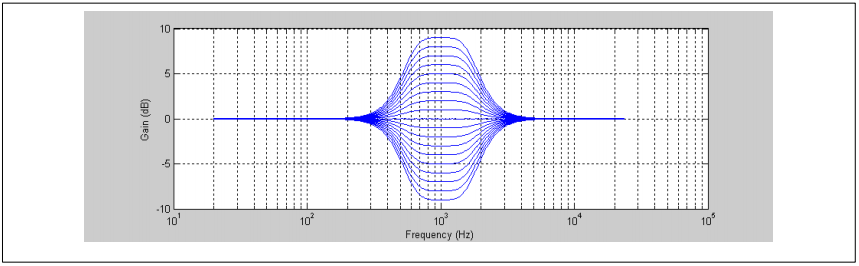
以1 dB为步长,每个滤波器共有19种不同的设置。在MATLAB中预先计算了所有19中可能设置的频率器系数,并将其存储在表格中。使用5个不同表格,总共有5x19=95个不同的4阶过滤器。所有95个响应如下所示:
图16. 19X5频率系数的过滤器响应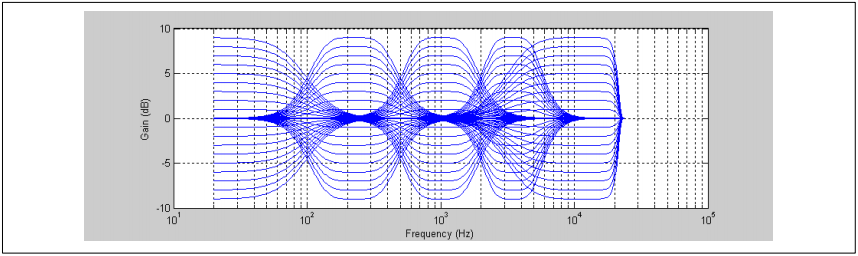
每个4阶滤波器具有10个系数,意味着排列成950个不同滤波器系数。输入和输出数据为Q31模式。为了获得更好的噪声性能,两个低频算使用高精度 32x64 位双二阶滤波器。本示例中的输入信号使用对数线性调频。
图17. 输入信号对数线性调频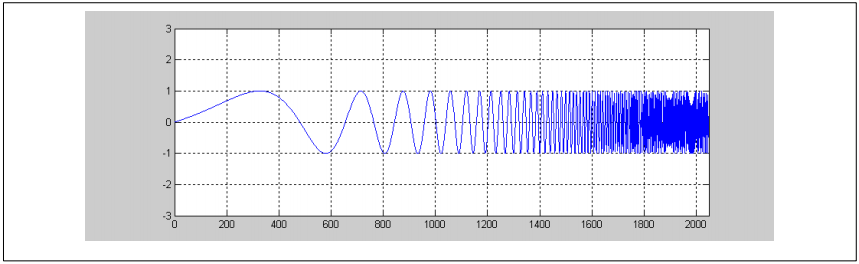
数组bandGains指定以dB为单位的增益应用于每个带宽。例如,如果bandGains={0, -3, 6, 4, -6};那么输出信号将是:
图18. bandGains调频输出信号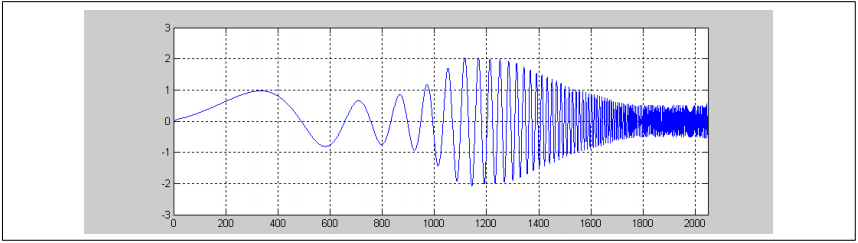
注意:
输出线性调频信号跟随着每个带宽的增益或增强而变化。变量描述:
- testInput_f32:指向输入数据
- testRefOutput_f32:指向参考输出数据
- testOutput:指向测试输出数据
- inputQ31:临时输入缓冲区
- outputQ31:临时输出缓冲区
- biquadStateBand1Q31:指向band1的状态缓冲区
- biquadStateBand2Q31:指向band2的状态缓冲区
- biquadStateBand3Q31:指向band3的状态缓冲区
- biquadStateBand4Q31:指向band4的状态缓冲区
- biquadStateBand5Q31:指向band5的状态缓冲区
- coeffTable:指向所有频段的系数缓冲区
- gainDB:增益缓冲器,其增益适用于所有频段
使用到DSP软件库的函数有:
- arm_biquad_cas_df1_32x64_init_q31()
- arm_biquad_cas_df1_32x64_q31()
- arm_biquad_cascade_df1_init_q31()
- arm_biquad_cascade_df1_q31()
- arm_scale_q31()
- arm_scale_f32()
- arm_float_to_q31()
- arm_q31_to_float()
参考
AT32_DSP_DEMO\project\at_start_f403a\examples\5_6_arm_graphic_equalizer_example
线性插值示例
描述:本案示例展示了线性插值模型和快速数学模型的用法。方法1使用快速数学正弦函数通过三次插值计算正弦值。方法2使用线性插值函数并将结果与参考输出进行比较。示例显示,与快速数学正弦计算相比,线性插值函数可用于获得更高的精度。
算法1:使用快速数学函数进行正弦计算
图19. 快速数学函数算法框图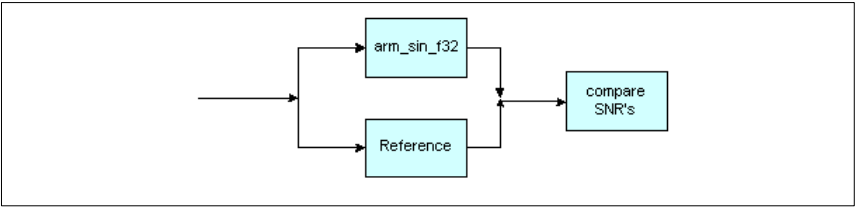
算法2:使用插值函数进行正弦计算
图20. 插值函数算法框图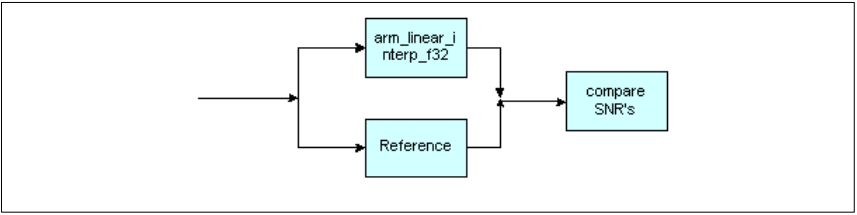
变量描述:
- testInputSin_f32指向用于正弦计算的输入值
- testRefSinOutput32_f32指向由matlab计算得到输出参考值p
- testOutput指向由三次插值计算得到的输出缓冲
- testLinIntOutput指向由线性插值计算得到的输出缓冲
- snr1参考输出和三次插值输出的信噪比
- snr2参考输出和线性插值输出的信噪比
使用到DSP软件库的函数有:
- arm_sin_f32()
- arm_linear_interp_f32()
参考
AT32_DSP_DEMO\project\at_start_f403a\examples\5_7_arm_linear_interp_example
矩阵示例
描述:该示例展示了使用矩阵转置、矩阵乘法和矩阵求逆函数应用于最小二乘法处理的输入数据。最小二乘法是用于查找最佳拟合曲线,该曲线可使给定数据及的偏移平方和(最小方差)最小化。
算法:
做考虑参数的线性组合如下:The linear combination of parameters considered is as follows:A*X=B, where X is the unknown value and can be estimated from A & B.其中X表示未知值,可以根据A和B进行估算。最小二乘法估算值X由以下公式算出X=Inverse(AT*A)*AT*B
框图:
图21. 矩阵算法框图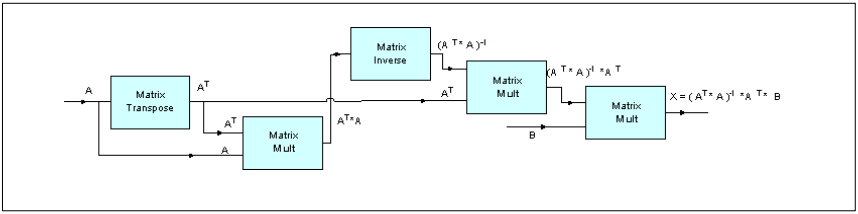
变量描述:
A_f32 input matrix:线性组合方程的输入矩阵B_f32 output matrix:线性组合方程的输出矩阵X_f32 unknown matrix:矩阵A_f32和B_f32估计而得到的未知矩阵
使用到DSP软件库的函数有:
arm_mat_init_f32()arm_mat_trans_f32()arm_mat_mult_f32()arm_mat_inverse_f32()
参考
AT32_DSP_DEMO\project\at_start_f403a\examples\5_8_arm_matrix_example
信号收敛示例
描述:演示了展示了FIR低通滤波传递函数的自适应滤波器“学习”能力,使用到的函数有归一化LMS滤波器,有限冲击相应(FIR)滤波器和基本数学函数来。
算法:
下图说明了此示例的信号流。均匀分布的白噪声通过FIR低通滤波器进行滤波。FIR滤波器的输出为自适应滤波器(标准化LMS滤波器)的提供参考输入。白噪声是自适应滤波器的输入。自适应滤波器学习FIR滤波器的传递函数。该滤波器输出两个信号:(1)内部自适应FIR滤波器的输出(2)自适应滤波器与FIR的参考输出之间的误差信号。随着自适应的滤波器不断学习学习FIR滤波器的传递函数,第一个输出将会接近于FIR滤波器的参考输出,误差信号也会不断接近于零。即使输入信号具有大的变化范围(即,从小到大变化),自适应滤波器也能正确收敛。自适应滤波器的系数初始化为零,在1536个样本上,内部函数test_signal_converge()找到停止条件。该功能检查误差信息的所有值是否都低于阈值DELTA的幅度。
框图:
图22. 信号收敛算法框图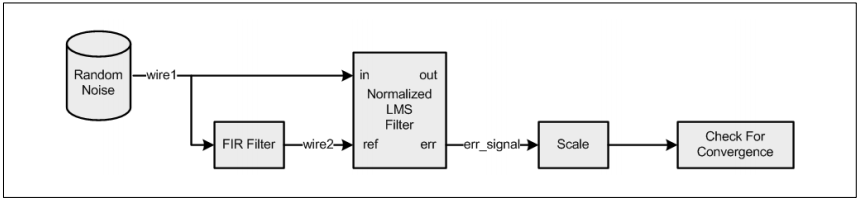
变量描述:
testInput_f32:指向输入数据firStateF32:指向FIR状态缓冲区lmsStateF32:指向归一化最小方差FIRFIRCoeff_f32:指向系数缓冲区lmsNormCoeff_f32:指向归一化最小方差FIR滤波器系数缓冲区wire1, wir2, wire3:临时缓冲区errOutput, err_signal:临时错误缓冲区
使用到DSP软件库的函数有:
arm_lms_norm_init_f32()arm_fir_init_f32()arm_fir_f32()arm_lms_norm_f32()arm_scale_f32()arm_abs_f32()arm_sub_f32()arm_min_f32()arm_copy_f32()
参考
AT32_DSP_DEMO\project\at_start_f403a\examples\5_9_arm_signal_converge_example
正弦余弦示例
描述:Demonstrates the Pythagorean trignometric identity with the use of Cosine, Sine, Vector Multiplication, and Vector Addition functions.通过使用正弦,余弦,向量乘法和向量加法函数演示三角学的勾股定理
算法:
数学上,勾股三角学恒等式由以下方程式定义:sin(x)*sin(x)+cos(x)*cos(x)=1其中x为弧度值
框图:
图23. 使用正弦余弦演示勾股定理算法框图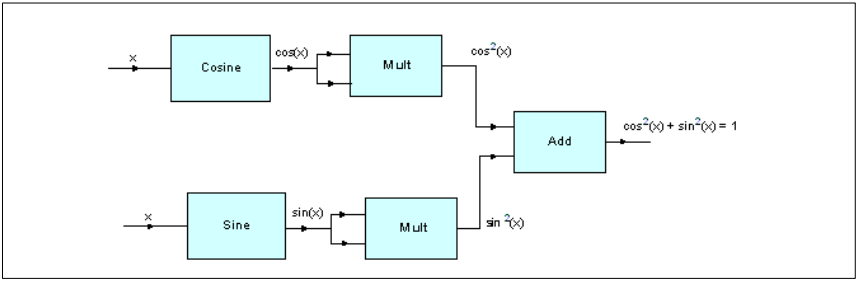
变量描述:
testInput_f32:以弧度为单位的角度输入数组testOutput stores:正弦值和余弦值的平方和
使用到 DSP 软件库的函数有:
arm_cos_f32()arm_sin_f32()arm_mult_f32()arm_add_f32()
参考
AT32_DSP_DEMO\project\at_start_f403a\examples\5_10_arm_sin_cos_example
方差示例描述:演示如何使用基本函数和支持函数来计算 N 个样本的输入序列的方差,将均匀分布的白噪声作为输入。
算法:
序列的方差是各序列与序列平均值的平方差的平均值。
这有以下等式表示:
variance=((x[0]-x')*(x[0]-x')+(x[1]-x')*(x[1]-x')+...+*(x[n-1]-x')*(x[n-1]-x'))/(N-1)其中,x[n]是输入序列,N输入样本数,x是输入序列x[n]的平均值。
平均值x的定义如下:
x'=(x[0]+x[1]+...+x[n-1])/N
框图:
图24. 方差算法框图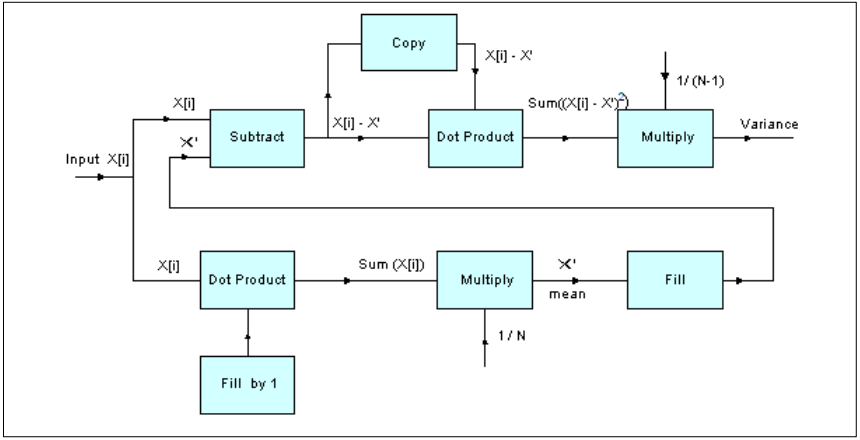
变量描述:
testInput_f32:指向输入数据wire1, wir2, wire3 :临时数据缓冲区blockSize:一次处理的样本数refVarianceOut:参考方差值
使用到DSP软件库的函数有:
arm_dot_prod_f32()arm_mult_f32()arm_sub_f32()arm_fill_f32()arm_copy_f32()
参考
AT32_DSP_DEMO\project\at_start_f403a\examples\5_11_arm_variance_example
CMSIS NN with DSP
介绍本用户手册介绍了CMSIS NN软件库,这是一个有效的神经网络内核的集合,这些内核的开发旨在最大程度地提高性能,并最大程度地减少神经网络在Cortex-M处理器内核上的存储空间。该库分为多个函数,每个函数涵盖特定类别:神经网络卷积函数神经网络激活功能全连接层功能神经网络池功能Softmax函数神经网络支持功能
该库具有用于对不同的权重和激活数据类型进行操作的单独函数,包括8位整数(q7_t)和16位整数(q15_t)。功能说明中包含内核的描述。本文[1]中也描述了实现细节。
图25. CMSIS NN程序架构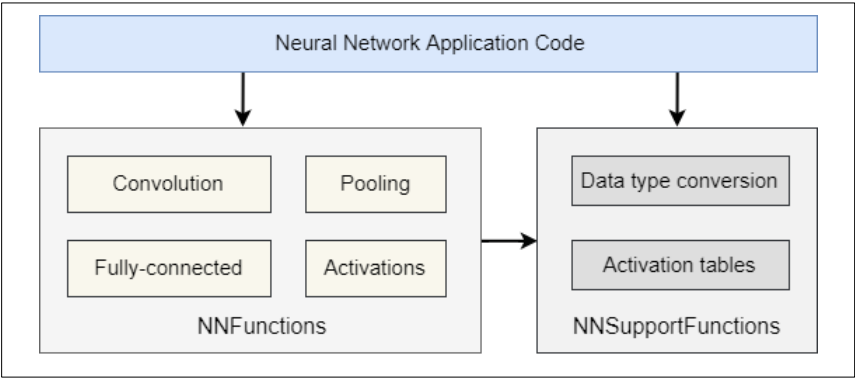
例子
该库附带了许多示例,这些示例演示了如何使用库函数。
预处理器宏
每个库项目都有不同的预处理器宏。
ARM_MATH_DSP:
如果芯片支持DSP指令,则定义宏ARM_MATH_DSP。
ARM_MATH_BIG_ENDIAN:
定义宏ARM_MATH_BIG_ENDIAN来为大型字节序目标构建库。默认情况下,为小端目标建立库。
ARM_NN_TRUNCATE:
定义宏ARM_NN_TRUNCATE以使用floor而不是round-to-the-nearest-int进行计算
卷积神经网络示例
描述:演示了使用卷积,ReLU激活,池化和全连接功能的卷积神经网络(CNN)示例。
型号定义:
本示例中使用的CNN基于Caffe [1]的CIFAR-10示例。该神经网络由3个卷积层组成,其中散布有ReLU激活层和最大池化层,最后是一个完全连接的层。网络的输入是32x32像素的彩色图像,它将被分类为10个输出类别之一。此示例模型实现需要32.3 KB的存储权重,40 KB的激活权和3.1 KB的存储im2col数据。图26. CIFAR10 CN算法框图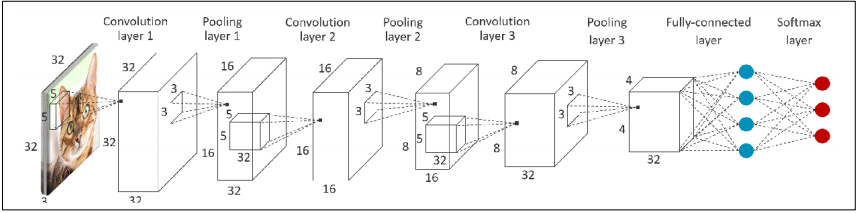
神经网络模型定义
变量说明:conv1_wt,conv2_wt,conv3_wt是卷积层权重矩阵conv1_bias,conv2_bias,conv3_bias是卷积层偏置数组ip1_wt,ip1_bias指向完全连接的图层权重和偏差input_data指向输入图像数据output_data指向分类输出col_buffer是用于存储im2col输出的缓冲区scratch_buffer用于存储激活数据(中间层输出)
CMSIS DSP软件库使用的功能:
arm_convolve_HWC_q7_RGB()arm_convolve_HWC_q7_fast()arm_relu_q7()arm_maxpool_q7_HWC()arm_avepool_q7_HWC()arm_fully_connected_q7_opt()arm_fully_connected_q7()
请参阅
AT32_DSP_DEMO\project\at_start_f403a\examples\6_1_arm_nnexamples_cifar10
门控循环单元示例
描述:使用完全连接的 Tanh / Sigmoid 激活功能演示门控循环单元(GRU)示例。
型号定义:
GRU是一种递归神经网络(RNN)。它包含两个S型门和一个隐藏状态。
计算可以总结为:
z[t]=Sigmoid(W_z⋅{h[t-1],x[t]})r[t]=sigmoid(W_r⋅{h[t-1],x[t]})n[t]=tanh(W_n⋅[r[t]×{h[t-1],x[t]})h[t]=(1-z[t])×h[t-1]+z[t]×n[t]图27. 门极递归单元图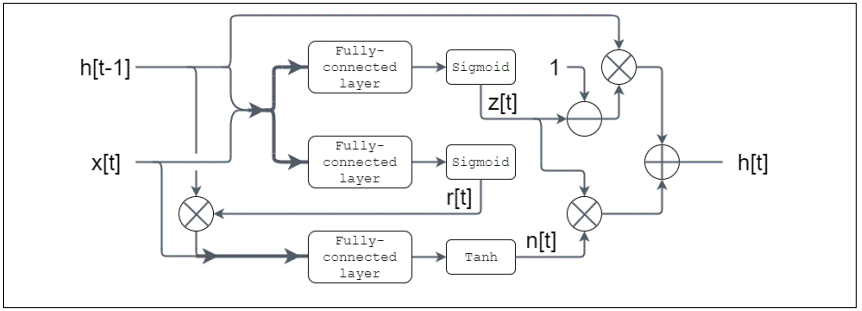 变量说明:update_gate_weights,reset_gate_weights,hidden_state_weights 是与更新门(W_z),重置门(W_r)和隐藏状态(W_n)对应的权重。update_gate_bias,reset_gate_bias,hidden_state_bias是图层偏置数组test_input1,test_input2,test_history 是输入和初始历史记录
变量说明:update_gate_weights,reset_gate_weights,hidden_state_weights 是与更新门(W_z),重置门(W_r)和隐藏状态(W_n)对应的权重。update_gate_bias,reset_gate_bias,hidden_state_bias是图层偏置数组test_input1,test_input2,test_history 是输入和初始历史记录
缓冲区分配为:
|重置|输入|历史|更新| hidden_state |这样,由于(复位,输入)和(输入,历史记录)在存储器中被物理地隐含,所以自动完成隐含。权重矩阵的顺序应相应调整。
CMSIS DSP 软件库使用的功能:
arm_fully_connected_mat_q7_vec_q15_opt()arm_nn_activations_direct_q15()arm_mult_q15()arm_offset_q15()arm_sub_q15()arm_copy_q15()
请参阅
AT32_DSP_DEMO\project\at_start_f403a\examples\6_2_arm_nnexamples_gru
DSP Lib的生成和使用
本节主要讲解如何将DSP源码打包为不同内核MCU所使用的lib文件。在Artery所提供的DSP包中没有包含官方所提供的lib文件,但包含了可生成lib文件的ARM、GCC、IAR三种编译环境的工程,用户可根据自己的需要选择适用的lib文件来进行生成。亦可将生成的lib文件替换掉工程中的DSP源码。下面分为两个部分来讲解lib文件的生成和使用。
DSP Lib生成
下面以ARM编译环境为例,展示如何生成所需的lib文件:1) 打开SourceCode\libraries\cmsis\DSP\Projects\ARM中的Keil工程;2) 在①处select target下拉框选择所需生成的lib文件;3) 点击②处进行编译;4) 待③处显示lib文件生成信息;5) 在SourceCode\libraries\cmsis\DSP\Lib\ARM中查看生成的lib文件。图28. DSP Lib生成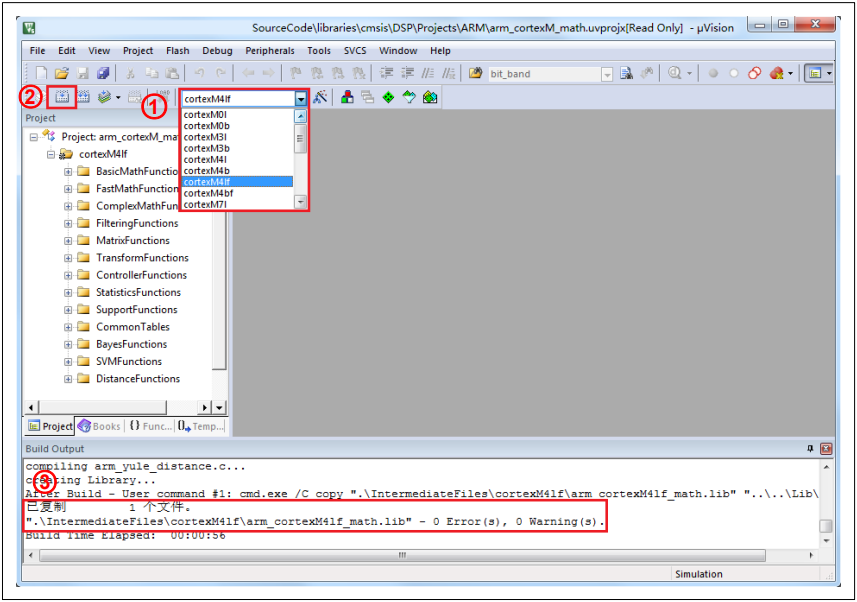
DSP Lib使用
下面以5_1_arm_class_marks_example为例,展示如何使用lib文件:1) 点击①处打开manage project items界面;2) 点击②处,将③处内容全部删除;3) 点击④处找到SourceCode\libraries\cmsis\DSP\Lib\ARM路径下的lib文件进行添加;4) 点击OK,编译工程。图29. DSP Lib使用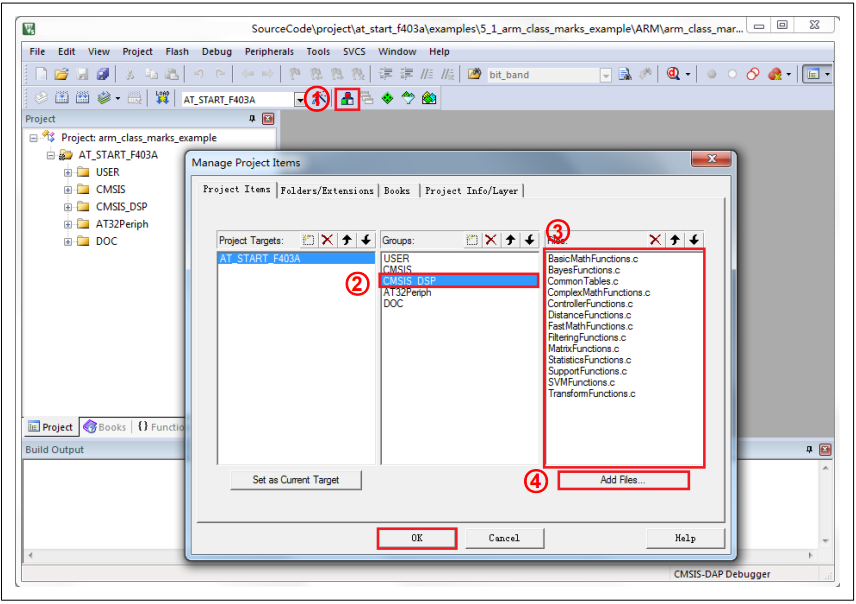
关于雅特力雅特力科技于2016年成立,是一家致力于推动全球市场32位微控制器(MCU)创新趋势的芯片设计公司,专注于ARM Cortex-M4/M0+的32位微控制器研发与创新,全系列采用55nm先进工艺及ARM Cortex-M4高效能或M0+低功耗内核,缔造M4业界最高主频288MHz运算效能,并支持工业级别芯片工作温度范围(-40°~105°)。雅特力目前已累积相当多元的终端产品成功案例:如微型打印机、扫地机、光流无人机、热成像仪、激光雷达、工业缝纫机、伺服驱控、电竞周边市场、断路器、ADAS、T-BOX、数字电源、电动工具等终端设备应用,广泛地覆盖5G、物联网、消费、商务及工控等领域。
- 相关推荐
- 热点推荐
- mcu
-
移植CMSIS-NN v6.0.0版本到VisionBoard2024-07-10 1794
-
Segger Jscope波形软件在AT32 MCU的使用2023-11-10 4511
-
AT32 MCU如何使用USB MSD 进行IAP升级?2023-10-27 2813
-
AT32 MCU DMA通道的灵活配置2023-10-26 2755
-
AT32上的DSP指令与库2023-10-24 1105
-
AT32 MCU Develop with VSCode2023-09-19 729
-
ARM Cortex-M系列芯片神经网络推理库CMSIS-NN详解2022-08-19 4750
-
AT32讲堂016 | AT32 MCU DSP使用案例和网络神经算法CMSIS-NN案例2022-08-16 2631
-
事隔五年之后,开启第2版DSP数字信号处理和CMSIS-NN神经网络教程,同步开启三代示波器,前50章发布(2021-112021-11-26 467
-
DSP数字信号处理和CMSIS-NN神经网络教程2021-08-04 1331
-
CMSIS-NN神经网络内核可以让微控制器效率提升5倍是真的吗?2021-03-15 1912
-
CMSIS-NN神经网络内核助力微控制器效率提升2019-07-23 2137
-
基于CMSIS-NN内核的神经网络推理运算 对运行时间/吞吐量和能效有显著提升2018-01-31 12151
全部0条评论

快来发表一下你的评论吧 !
