

python自动化测试攻城记
描述
随着软件开发在造车行业中占有越来越重要的地位,敏捷开发的思想在造车领域中也逐渐地被重视起来,随之而来的是整车厂对自动化测试需求越来越强烈。本文结合北汇信息在自动化测试方面的丰富经验,简单介绍一下实施自动化测试可能需要具备的技能及具体实践流程。
自动化测试城门-Python
要实现完全的自动化测试,我们首先要做的是先实现半自动化测试,即编写自动化测试脚本。俗话说Life is short,I use Python,Python作为一种简单易上手的高级编程语言,凭借其“无所不包”的库,成为测试脚本开发的不二之选。这里简单介绍一下,测试脚本开发常用的一些Python标准库。
城门士卒-os库
在编写测试脚本时,不可避免地会遇到对文件路径的获取及编辑,os库里的path函数可以方便地实现这些操作,如绝对路径获取os.path.abspath()、路径拼接os.path.join()、路径存在判断os.path.exist()等;如果你需要在Python中运行测试工具提供的命令,那么os库的system函数或popen函数可以让你方便地调用cmd(Windows)或shell(Linux)。
城门士卒-sys库
如果你所编写的测试脚本有跨平台运行的需求,那么你可以通过sys库的platform函数获取脚本的运行环境。根据运行环境的不同,编写不同的批处理命令;sys库中的argv函数,还可以为你的测试脚本提供简单的命令行接口,当你的脚本需要接收外部传递的参数时,你可以通过sys.argv[]方便地获取。而如果你需要编写更复杂更友好的命令行接口,你需要使用Python的另外一个标准库argparse来实现。
城门队长-re库
正则表达式是编写测试脚本的必备技能,因为有时我们会遇到复杂的文本处理,如在工程文件中查找需要修改的配置,并将其修改为我们所需要的内容。此时一般的查找替换函数就很难实现这个功能,我们只能借助强大的re库(正则表达式)来解决这个棘手的问题。re库提供的函数有:
re.compile():编译正则表达式,生成一个 Pattern 对象;
re.findall():搜索所有满足条件的字符串;
re.match():从第一个字符开始匹配模式;
re.search():搜索第一个满足条件的字符串,查找到第一个停止;
re.sub():替换满足条件的字符串。
在使用re模块时,我们一般先用re.compile()将正则表达式编译生成为一个Pattern对象,然后再基于这个对象进行findall、match等操作,这样既可以提高代码的可读性,也可以提高代码的运行效率。
使用正则表达式进行查找替换是很方便的,但是在很多时候我们需要在匹配的字符串前后添加内容,并且保留匹配的内容,这时普通的查找替换是难以实现的。
如:希望将hour: minute格式后添加:00,形成hour: minute: seconds这种格式。此时可以采用如下方式来实现:
查找的正则表达式:

替换为:

这里,我们在替换的字符中使用\1,来引用正则表达式中第一个分组匹配到的内容,如果正则表达式中有多个分组,可以依次使用\2\3等进行引用,可以使用\0来引用整个正则表达式的内容。
小结
在掌握了Python基础语法和这三个标准库后,自动化测试的大门就为我们敞开了。但是想要编写一个可以驱动测试工具进行测试的脚本,我们还需要了解测试工具在headless模式[1]下的接口情况,如果工具提供的接口丰富,可以实现在headless模式(这里的headless模式是指在不使用工具GUI的情况下,以纯命令行的方式进行工具使用的模式)下对测试工程进行配置和执行等操作,那么我们的测试脚本开发工作将会顺利地进行。
但是如果工具提供的headless模式接口有限,无法满足测试脚本的需求,那么进入自动化测试大门后,等待我们的就是另一个棘手的问题:如何对工程文件进行解析与修改。考虑到大部分的工程文件都是XML格式的,因此后续我们就简单介绍一下如何通过Python解析和修改XML文件。
自动化测试瓮城——XML文件
瓮城守备——XML解析
在Python的标准库中,有专门处理XML文件的库,无需安装第三方库就可以使用Python进行XML文件的解析,但是要想准确地从XML文件中解析出想要的信息,我们首先需要简单了解一下XML的文件结构。如下是一个简单的XML文档。

其中Harry Potter元素的结构如下图所示:
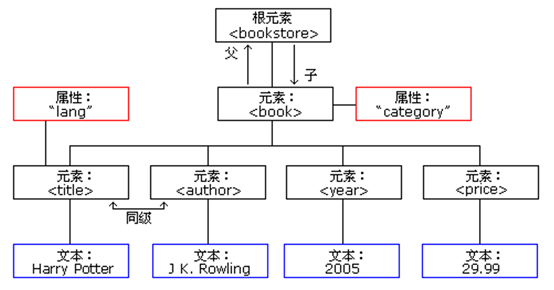
注:图片来源于w3school
在该XML文本中,根元素是 <2;bookstore>,文档中的所有 <2;book> 元素都被包含在 <2;bookstore> 里。<2;book> 元素有 4 个子元素:<2;title>、< author>、<2;year>、<2;price>。每个子元素都包含一个文本内容,但只有子元素title和元素book拥有属性。
我们在解析XML时,一般需要获取的就是元素的属性值以及元素的文本内容。以下我们就简单介绍一下,如何通过python获取元素的属性值及文本内容。
Python的XML库提供了一个通过标签名称获取元素的函数getElementsByTagName(),该函数返回的是一个包含元素对象的list,通过调用元素对象的attributes方法,我们就可以方便地获取元素的属性值。如,我们可以使用如下命令获取XML文件中第一个标签为title的lang属性值:
root.getElementsByTagName("title")[0].attributes.getNamedItem("lang").nodeValue
获取第一个标签为title的元素的文本信息的代码如下:
root.getElementsByTagName("title")[0].firstChild.data
瓮城参将——XML修改
XML元素的属性和文本内容修改很简单,在上小节中获取对应的元素信息后,直接对其进行赋值即可。但是,修改后的信息保存在XML对象中。要完成对实际XML文件的修改,我们还需要用XML对象中的内容覆盖原有的XML文件,这一步存在很多棘手的问题。
在XML文件中,为了避免元素文本内容中存在的特殊字符引起解析器错误,在文本内容中引入实体引用来替代可能导致错误的字符,如回车 、双引号"、单引号'。如果使用python的xml.dom.minidom库解析并使用writexml输出XML文件,该库会将这些实体引用转义为其实际字符进行保存。如果不对XML对象中的内容进行处理,导出的XML文件将会存在很多错误。
为了避免这个情况的出现,我们需要使用之前小节介绍的正则表达式将这些字符再替换为其实体引用。这个过程需要我们能熟练使用正则表达式进行文本查找与替换。
除了XML文件中的实体引用外,如果XML文件中存在中文字符,那么还有一个需要注意的事情:不要使用with open as的方式读写XML文件,要使用open指定文件的编码为'utf-8’ 的方式,对XML文件进行写入。如下所示:
f = open(self.JenkinsJobXMLPath, 'w', encoding="utf-8")
dom.writexml(f, indent='', addindent='\t', newl='', encoding='utf-8')
f.close()
小结
上述两个问题是修改XML文件时普遍会遇到的问题。解决了这两个问题,我们基本上就可以完美实现XML文件的修改了。此时,我们就可以编写自动化程度更高的测试脚本,然而我们依然无法实现完全的自动化测试,因为我们仍然需要手动地去执行测试脚本。那么,我们该如何实现测试脚本的自动执行呢?这就需要我们打通自动化测试的最后一个关卡,Jenkins。
自动化测试总兵——Jenkins
Jenkins 是一个开源、免费的可扩展持续集成引擎,主要用于:
- 持续、自动地构建/测试软件项目;
- 监控一些定时执行的任务。
为了实现测试脚本的自动化运行,我们需要配置Jenkins Job,使Jenkins在设置的触发条件满足时,自动搭建测试脚本的运行环境,然后执行测试脚本,最后将测试结果发送给相关人员。因此我们需要了解Jenkins的源码管理、构建触发器、构建及邮件通知等设置。
总兵的连招1——源码管理
Jenkins服务器最基本的作用是监视版本控制器,当版本库有新的更改时,检出版本库中的文件,或者,你可以选择只是定期检出版本库中最新的文件。无论哪种方式,Jenkins与版本控制软件的集成是必不可少的。
Jenkins开箱即用式支持Git、CVS和SVN,还通过插件与大量其他版本控制工具进行集成,如ClearCase、Perforce、PVCS等等。
不同的版本控制软件在Jenkins端的需要的配置并不相同,有的甚至差异很大。但是只要你熟悉你所使用的版本控制软件,那么在Jenkins端,就可以很容易地对版本库进行配置。
以SVN为例,为了从SVN仓库中获取源码,我们需要提供相应SVN版本库的URL,在完成URL输入后,Jenkins会检查URL的有效性,如果所提供的URL要求身份认证,Jenkins将会自动提示选择相应的凭据以验证账号信息,如下图所示。
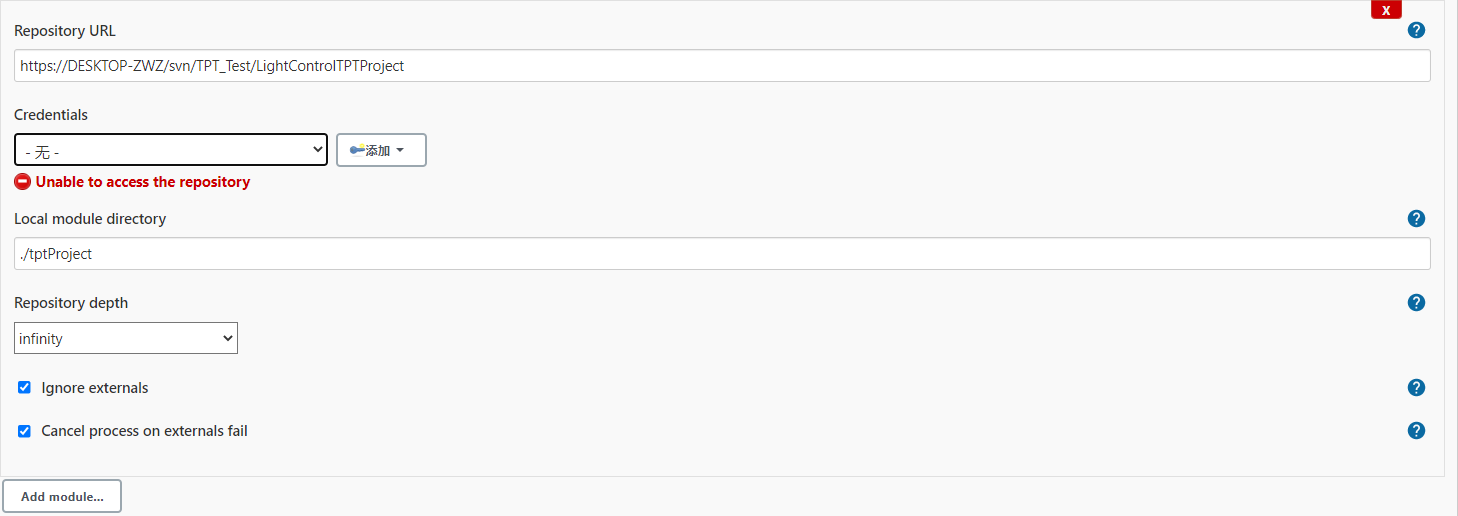
默认情况下,Jenkins会将给定的代码库中的文件检出到Jenkins Job的Workspace中。如果你需要将代码库检出到指定的目录中,你可以在Local module directory中输入你想要的目录名或相对Workspace的路径。
如果你需要从多个SVN版本库中获取文件,可以点击“Add module ...”按钮,来添加别的版本库。
总兵的连招2——构建触发器
常用的构建触发器有周期性构建和SCM轮询构建,两者都是使用相同corn风格语法进行设置,如下图所示。
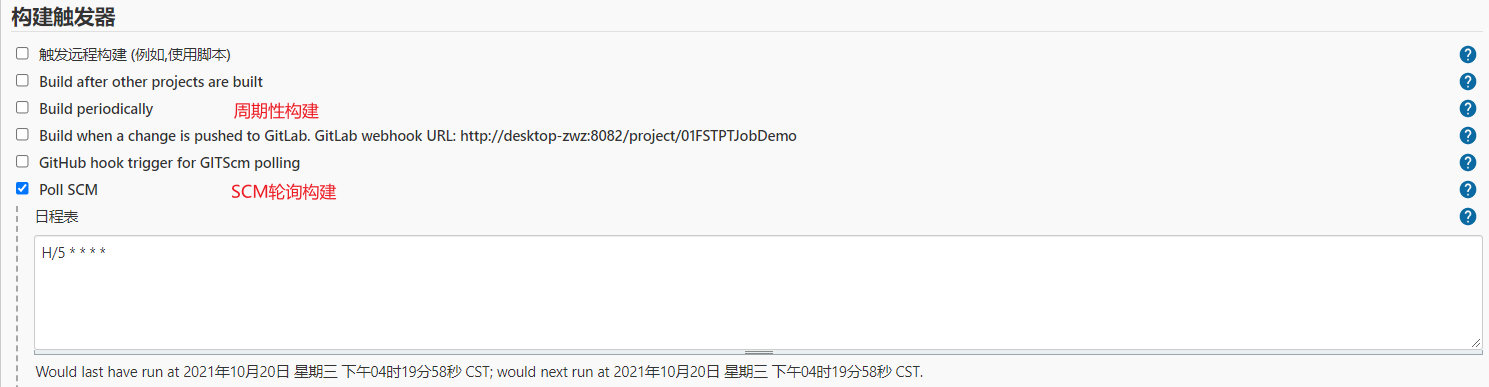
我们只需要了解corn风格的语法,就可以方便地进行构建触发器的设置。corn风格的语法包含五个由空格分隔的字段:
MINUTE HOUR DOM MONTH DOW
每个字段使用下面的值:
MINUTE 小时内的分钟数(0-59)
HOUR 一天的小时数(0-23)
DOM 本月的天数(1-31)
MONTH 月份(1-12)
DOW 本周的一天(0-7),其中0和7都是星期日。
要为一个字段指定多个值,可以使用以下操作符:
- “*”代表一个字段的所有可能的值。如,“* * * * *”表示周期为一分钟;
- 使用“M-N”定义范围。如,在DOW中“1-5”表示周一到周五;
- 使用“/”定义范围间隔时间。如,MINUTE字段“*/5”表示每5分钟;
- 逗号分隔的列表表示有效值。如,MINUTE字段“15,45”表示在每小时的第15和第45分钟运行;
通常,我们只需要在这个字段中写一行,但是对于更复杂的调度配置,我们可能需要写多行。
总兵的连招3——构建
在完成了之前的配置后,Jenkins应该知道在何时从何处获取测试工程及源码。现在我们需要做的事情是,告诉Jenkins在获取测试工程和源码后该如何做。一般情况下,我们会将之前编写的测试脚本放在测试工程的版本库中,或者从专门的测试脚本库中检出到Jenkins Job的Workspace中,因此我们在这里只需要执行编写好的测试脚本即可。
执行脚本的方式可以根据具体脚本的运行环境,选择执行Shell或Windows批处理命令。因此我们需要简单地了解Shell或Windows的常用批处理命令。为了避免编写复杂的批处理命令,我们应尽量把工作放在测试脚本中完成。本文以如下图所示的简单的Windows批处理为例,简单介绍一下构建步骤的编写。
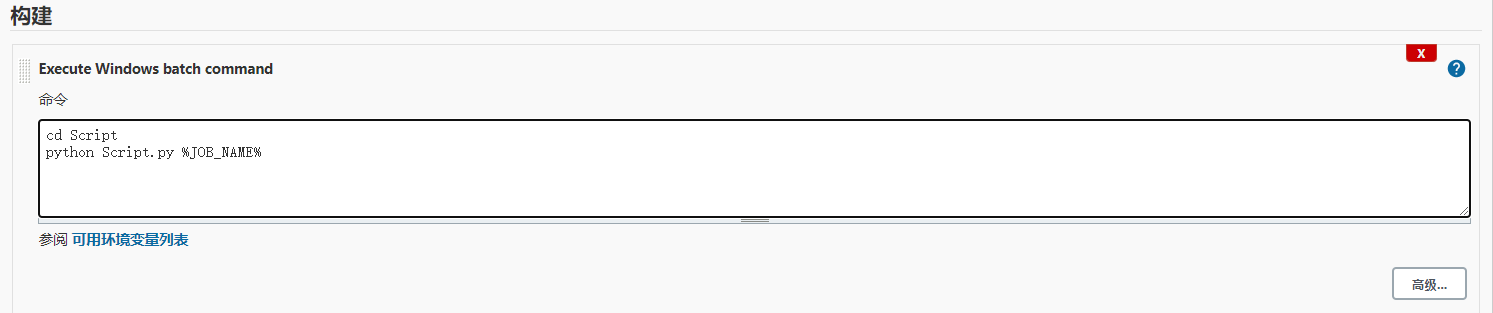
在上图中,有两行命令:
第一行的作用是将目录由初始的Workspace目录切换到Workspace下的Script目录;
第二行的作用是运行Script目录中的测试脚本Script.py,并为该脚本传递一个参数,该参数为Jenkins的环境变量JOB_NAME,即当前Jenkins Job的名称。
这样就完成了对测试脚本的调用。
总兵的连招4——邮件通知
自动化测试的一个重要环节,就是将测试结果通知到相关人员,如开发\测试人员,或项目管理人员等。Jenkins对电子邮件提供了开箱即用的支持,我们可以在构建后处理中勾选E-mail Notification,如下图所示。然后输入需要通知的人员邮箱,即可使Jenkins在构建完成后,向指定的人员发送一封友好的电子邮件。
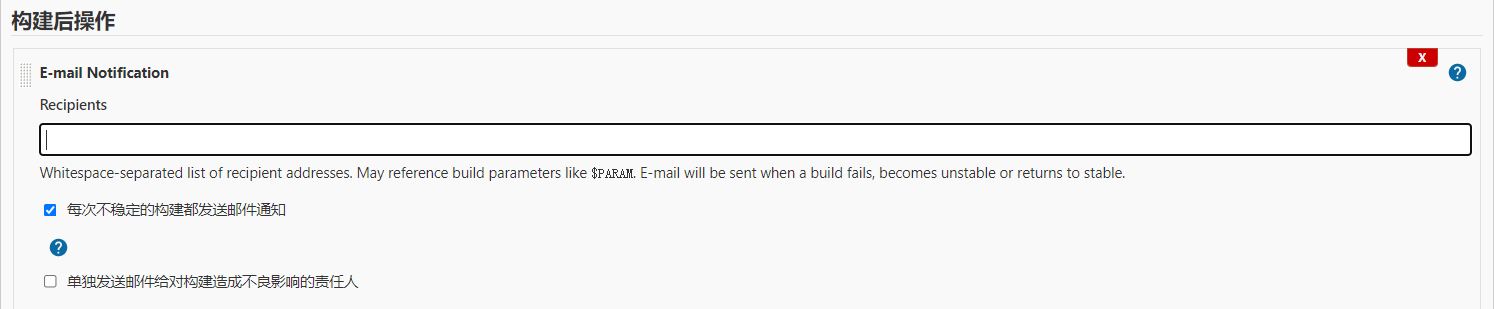
如果你想对邮件内容进行高度定制,那么E-mail Notification就无法满足需求,我们需要安装可编辑的电子邮件插件Editable Email Notification,来实现电子邮件的定制化工作。
在Editable Email Notification中,我们可以用HTML编写电子邮件的内容,并引用Jenkins的环境变量,这样我们就可以在邮件中描述当前Jenkins Job的测试执行概况,让收件人快速地了解当前的测试状态。但是这要求我们对HTML和Jenkins环境变量都有比较深的了解。
有些情况下,我们需要在邮件中执行一些数据提取等复杂工作,比如将控制台输出中的一些数据在邮件中进行展示,这时我们需要借助email-ext-plugin插件提供的Groovy接口,用Groovy编写邮件内容。
总之,Jenkins的邮件通知功能非常强大,我们可以在自动化测试的工作中不断进行探索。
小结
本节简单介绍了Jenkins的传统表单类型的Freestyle Job,然而目前Jenkins的发展方向是 Pipeline Job,Jenkins将Pipeline作为优先开发项目。这就意味着Pipeline在应用程序中是作为实体被设计和支持的,而不是通过在Jenkins中连接一堆任务而形成流水线。Pipeline类型的Job可以通过编程实现,可以实现更复杂构建逻辑和工作流,更重要的是在Pipeline中有专门的用于流水线编程的结构化DSL,其可以在工作空间中轻松地实现文件共享功能。同时Pipeline具有全新的Jenkins可视化界面 ——Blue Ocean,其为Pipeline的每个阶段添加了图形化的展示,如下图所示。
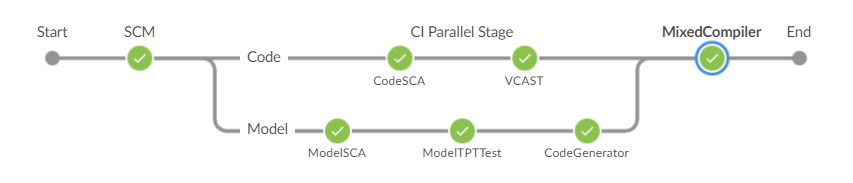
因此我们在熟悉了表单类型的 Freestyle Job后,可以尝试将其转换为Pipeline的Job,当然目前并非所有的Jenkins插件都支持Pipeline,有些老旧的插件还无法支持Pipeline,我们需要根据实际的工作情况进行Jenkins工程类型的选择。
攻城总结
古人云:知所不豫,行且通焉。虽然通过本文,我们全面地了解了自动化测试的流程,但是只有在自动化测试的实践中不断探索,我们才能真正窥得自动化测试的全貌。北汇信息作为专业的自动化测试服务供应商,也可以为客户提供优质全面的自动化测试服务。
-
Python自动化测试框架及其应用2024-04-03 1594
-
电源测试怎么自动化?电源模块自动化测试系统如何实现?2023-12-15 2403
-
Facebook群组自动化python – 网络自动化2023-07-05 706
-
使用Python实现功能测试自动化2023-05-04 1673
-
什么是自动化测试框架2023-04-18 1800
-
分享10个实用的Python自动化脚本2023-01-21 2179
-
云测试自动化中的Python2022-12-09 1631
-
10个杀手级的Python自动化脚本2022-11-28 1192
-
自动化测试框架unittes详解2022-05-20 4074
-
python控制CANoe实现自动化测试的方法2021-12-29 3994
-
ATE自动化测试系统是什么_ATE自动化测试系统介绍2018-05-23 33424
-
【上海】猎头推荐职位-自动化测试工程师(java/python)2017-06-28 2603
-
【NanoPi2申请】华为基站自动化测试2015-12-02 3670
-
OPhone自动化测试技术概述2010-05-06 2439
全部0条评论

快来发表一下你的评论吧 !
