

纹理分析以及结合深度学习来提升纹理分类效果
描述
来源:AI公园,作者:Trapti Kalra
编译:ronghuaiyang
导读
纹理分析的介绍,各种纹理分析方法,并结合深度学习提升纹理分类。
人工智能的一个独特应用领域是帮助验证和评估材料和产品的质量。在IBM,我们开发了创新技术,利用本地移动设备,专业的微型传感器技术,和AI,提供实时、解决方案,利用智能手机技术,来代替易于出错的视觉检查设备和实验室里昂贵的设备。
在开发质量和可靠性检查的人工智能能力的同时,产品和材料的图像需要是高清晰度的或者是微观尺度的,因此,设计能够同时代表采样图像的局部和全局独特性的特征变得极为重要。利用来自纹理分析方法的特征来丰富基于深度CNN的模型是一种非常有效的方法来实现更好的训练模型。
为了更好地理解纹理分析方法在深度学习中的应用,我们先来了解一下什么是纹理分析。
什么是纹理?
纹理是粗糙度、对比度、方向性、线条相似性、规则性和粗糙度的度量,有助于我们理解图像中颜色或强度的空间排列。纹理是图像强度中局部变化的重复模式(图1)。

图1,纹理图像示例 (a)原始图像,(b)纹理重复模式
纹理由纹理原语或纹理元素组成,有时被称为元纹理。元纹理用于从图像中找到对象的色调和纹理。图像的色调取决于元纹理的像素强度属性,而纹理处理元纹理之间的空间连接。
例如,如果元纹理之间的色调差异很大,而元纹理的尺寸很小,它就像一个精细的纹理,如果一个元纹理包含很多像素,那么它就像一个粗糙的纹理。
我们需要了解不同类型的纹理才能正确地分析它们。在开始任何与纹理相关的项目之前,最好知道你将处理什么样的纹理。
不同类型的纹理
纹理的分类是困难的,因为它的一些属性,如规律性、随机性、均匀性和变形没有得到适当的定义,以及纹理类型是广泛的和复杂的。
通常,纹理像粗糙,凹凸,干燥,光泽,沙质,硬,尖锐等,属于粗糙类别,而纹理像细,光滑,湿,皱,丝滑,软,暗等,属于光滑类别。
广义上,纹理分为两类,即触觉和视觉纹理。
触觉指的是一个表面的直接有形的感觉,即触觉纹理就像一个真实的对象。当一个物体被触摸时,我们可以感觉到它的质地。手感可以是光滑、柔软、坚硬、黏滑、粗糙、粘滑、丝滑等。自然纹理的例子有木头、岩石、玻璃、金属、树叶等,如图2所示。

图2,自然纹理的例子
视觉纹理被定义为纹理产生给人类观察者的视觉印象,也就是说,它不是真正的纹理,但它是人从图像中检查纹理的方法。照片中的物体可能看起来很粗糙,但是,照片的感觉总是平坦和光滑的。
根据视觉纹理的随机性程度,可以进一步将视觉纹理分为规则纹理和随机纹理。
将简单可识别的小尺寸的部分平贴到固体周期模式中,形成“规则纹理”(图3),而随机模式中较难识别部分组成“随机纹理”(图4)。

图3,规则纹理的例子

图4,随机纹理的例子
那么,现在最大的问题是,纹理分析在提高计算机视觉任务中深度学习的有效性方面的意义是什么?
纹理分析用在哪里?
如今,纹理分析是许多任务的重要组成部分,从医学影像到遥感,也被用于大型图像数据库的内容查询。
在工业检测中,当现有的技术无法解决的时候,纹理分析是一个强大的工具。让我们以木材制造为例,在这种情况下,不使用纹理分析很难检测裂纹。
纹理检测还用于对地毯进行分级中,根据地毯因磨损引起的外观变化。纹理分析用于皮革检查,通过评估颜色、厚度和灰度变化。有缺陷的碎片通常会在皮革上留下疤痕或褶皱。
纹理分析的应用范围包括纹理分类,如遥感(图5),纹理分割,如生物医学成像(图6)。它还被用于图像合成和模式识别任务,如从照片中识别绘画。
当图像中的物体是通过纹理属性而不是强度进行分类,或者阈值技术无法对其进行正确分类时,纹理分析就发挥了重要作用。

图5,利用纹理分析的遥感图像。由遥感领域的专家对这些纹理模式进行聚类识别和标记
下图(图6)显示了二流腔静脉的超声图像(图的下三分之一处为钝区)。肝脏的分割,被白色斑点包围的区域,显示出与周围组织相比独特的纹理。
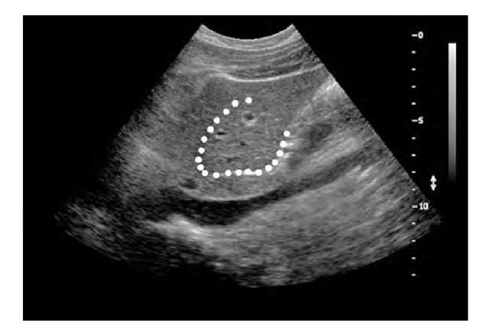
图6,利用纹理分析的医学图像
如今,纹理分析也被用于食品制造行业,以了解食品的质量。硬糖、耐嚼的巧克力曲奇、脆饼干、粘稠的太妃糖、脆芹菜、嫩牛排等食物都含有多种纹理。纹理分析在这一领域有很大的应用,例如食物的口感特性可以通过纹理分析很容易地测量出来。
它也被用于一项名为“流变学”的研究,这是一门研究物质变形和流动的科学,换句话说,是研究物体受到外力作用时的反应。
除了所有这些,纹理分析可以用来测量/评估许多产品的质量,如粘合剂,药品,皮肤/头发护理产品,聚合物等。
到目前为止,我们已经了解了纹理分析可以应用在哪里,在下一节让我们看看如何根据纹理对图像进行分类。
纹理分析如何应用到分类问题中以及为何它如此重要?
到目前为止,我们已经了解了不同类型的纹理,并看到了现实生活中纹理分析很有用的例子。让我们了解如何在分类问题中使用它,分类器的主要目标是通过为每个图像提供描述符来对纹理图像进行分类。换句话说,
分配一个未知的样本到一个预定义的纹理类被称为纹理分类
在进行纹理分类时,考虑了图像的图案和纹理内容。基于纹理的分类是基于纹理特征(如粗糙度、不规则性、均匀性、平滑度等)进行的。任何图像数据集中的每个类都很可能具有不同的纹理,这使得它成为一个独特的属性,有助于模型更准确地对图像进行分类。
提取纹理的不同技术和方法
有多种方法用于从图像中提取纹理。在本文中,我们将讨论最常用和最重要的纹理提取方法。
GLCM (Grey Level Co-occurrence Matrix,灰度共生矩阵)是一种常用的、基本的纹理分析统计方法。GLCM特征基于二阶统计量,用于从均匀性、同质性等角度了解像素间的平均相关程度。
LBP是一种结合了结构和统计方法的方法,使纹理分析更有效。现实中LBP的一个重要特征是它对不同光照条件引起的单调的灰度变化的容忍度。它的简单计算允许在实时场景中使用。
小波是一种基于变换的方法,可以捕捉局部的频率和空间信息。GLCM和LBP关注的是纹理的空间排列,但纹理的关键要素是尺度,根据一项心理-视觉研究,我们的大脑处理图像的方式是多尺度的。我们的大脑会进行不同的空间频率分析来识别纹理。基于这一思想,小波分析关注的是频率和空间信息。
分形是图像自相似性和粗糙度的重要度量。它能够表征其他纹理分析方法所不能表征的纹理。有各种各样的技术来测量图像的平滑度、均匀度、平均值和标准差,但分形方法主要关注图像纹理的“粗糙度”,并相应地对纹理进行分类。
图像梯度是一种检测图像边缘的完美技术,因为它变得更容易识别纹理时,边缘高亮。纹理边界用于自然边界的有效划分,一旦这些边界被正确识别,基于这些边界的纹理区分就很简单了。
这五种方法对不同的纹理数据集都取得了满意的结果。每种技术都强调纹理的独特属性。在下面的部分中,我们将研究这些技术的特征构造方法。
灰度共生矩阵 (GLCM):
GLCM提供了关于图像像素之间如何相互关联的信息,这种关系帮助我们根据从GLCM中提取的多个特征对纹理进行分类。矩阵给出了具有相似强度的像素的位置信息。可能的强度值集合是二维数组的行和列标签(P)
GLCM的P[i,j]首先通过指定一个位移向量= (dx, dy),并在位移向量的角度上统计由分隔的所有像素对,并进行初始化,灰度级别为j和i(其中j是列,i是行)。
一般来说,GLCM表示为P[i,j] = nᵢⱼ,其中nᵢⱼ是图像中位于距离处的像素值(i,j)的出现次数。共生矩阵P的维数为n*n,其中n是图像中的灰度级数。
GLCM是根据位移矢量中提到的距离和角度计算的。对于一个像素x,我们可以计算8个不同方向的GLCM值,如图7所示。
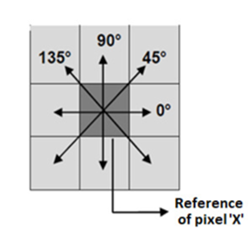
图7,像素x的最近邻像素
为了更好地理解下面的例子(图8),一个4x4的图像是由4个灰度级组成的。这里,在图8中,0°角下,i=2, j=3, d=1的GLCM值为4。图8中顶部的矩阵表明,在我们的图像中有4个实例,灰度级别3的像素与灰度级别2的像素水平分离(即0°)。
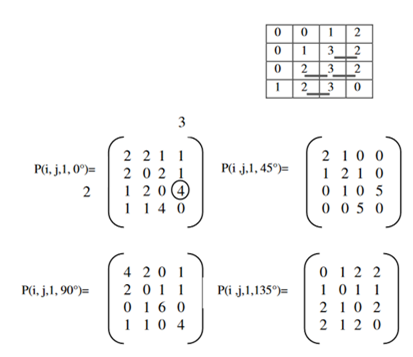
图8,共生矩阵的例子,4个灰度级别的4x4的图像
该矩阵可以进一步用于数值计算全局纹理特征,如相关性、能量、熵、同质性、对比度、显著性和阴影。为了进一步了解这些特征是如何从GLCM中提取的,请查看这篇论文:http://www.ijsrp.org/research-paper-0513/ijsrp-p1750.pdf,其中详细讨论了GLCM。
Local Binary Pattern (LBP):
GLCM侧重于从整体图像获取信息,而LBP侧重于局部特征而非全局特征。因为纹理是模式的重复,所以LBP尝试根据这些模式对纹理进行分类。纹理的局部表示是通过比较一个像素与其邻域的所有像素来计算的。
在构造LBP之前,我们需要将图像转换为灰度。对于灰度中的每个像素,我们在中心像素周围选择一个大小为r的邻域。通过将相邻像素标记为0和1来确定中心像素的LBP值,只要像素的强度等于或大于中心像素,它就标记为1,否则标记为0(如图9所示,其固定的邻域为3 x 3)。
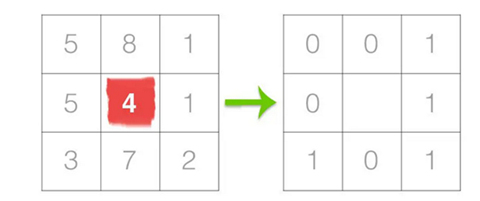
图9,构建LBP的第一步
在下一步计算LBP中,我们从任何相邻的像素开始,顺时针或逆时针方向工作,这个顺序必须对数据集中所有图片的所有像素保持相同。这个输出保存在一个8位数组中,它被转换成小数,如图10所示。以8个周围像素为例,LBP码的潜在组合为2 - 256种。
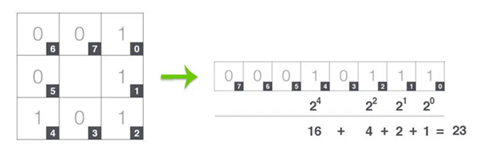
图10,中心像素的8位二进制邻域,并将其转换为十进制表示
一旦我们对图像的所有像素重复上述方法,我们就得到了LBP图像。仅供参考,参见图11原始图像(左)的LBP表示示例(右)。

图11,原始图(左)LBP转换后的图(右)
在使用LBP之后,将提取纹理,以便捕获纹理的极细粒度细节,并且对纹理进行分类要简单得多。
小波
在此之前,纹理分析的基本问题是缺乏满意的工具来描述不同尺寸的纹理。多分辨率分析的进步,如Gabor和小波变换方法有助于解决这一缺陷。小波变换作用于图像的频域。你可能想知道图像的频域是什么?
一幅图像有两个域,一个是空间域,另一个是频率域。用像素矩阵表示的图像称为空间域,而频域表示像素值在空间域中变化的速率。
频率指的是图像中颜色成分的变化速率,频率高的地方颜色变化快,频率低的地方颜色变化慢。
高频分量对应图像边缘,低频分量对应平滑区域。小波分析用于将图像中的信息分成两个离散的部分-近似和细节。
一旦将小波变换应用于图像,它将产生四个象限(如图12所示)的图像。每个象限代表以下内容:
LL (low - low):左上象限沿图像的行和列使用低通滤波器滤波。这个子块拥有原始图像的一半分辨率。
HL(高-低)/LH(低-高):右上和左下象限沿行和列使用高通滤波器和低通滤波器交替过滤。HL子块显示图像的水平边缘,而LH子块显示原始图像的垂直边缘。
HH (high - high):右下象限使用高通滤波器沿图像的行和列进行滤波。该子块沿着对角线方向描述了原始图像的边缘。
然后再对一半分辨率的图像做小波变换,这是递归地完成的,这样原始图像的邻近像素越来越不相关。
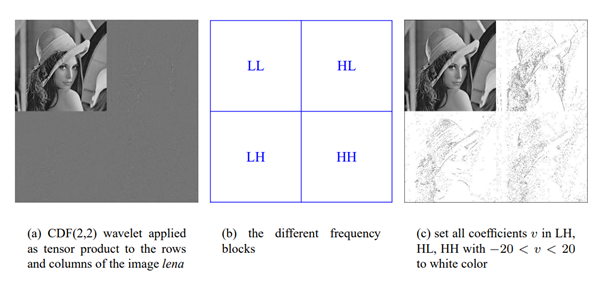
图12
参考图13了解小波变换的不同层次。
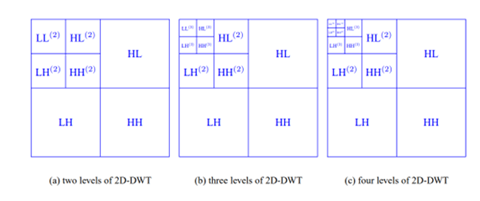
图13,经过几级小波变换,得到了多分辨率图
上述图像分解后的表示方法被称为多尺度表示和多分辨率方案。经过小波变换(小波图像分解)后的输出很容易解释。图像的每个子部分都提供了方向和特定尺度的信息,这些信息很容易分离出来。小波变换后的子图像保留了空间信息。
分形
利用分形维数可以识别图像的纹理粗糙度、平滑度、固体度和面积等特征。
在欧几里得n空间中,如果闭集X是Nᵣ不同的不相交副本的并集,Nᵣ的每个元素按比例r缩小都与X相同,则X被称为自相似。我们可以用下面的表达式为X写出分形维数D:
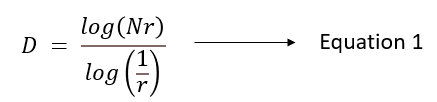
盒计数法计算分形维数的算法如下:
目的:分形维数(FD)的计算。
输入:二维图像I
输出:FD
1. Read a 2-D input image I
2. [P, Q] = SIZE[I]
3. If P>Q then r = p
Else r = q
4. Compute fractal dimension using Equation 1
5. Stop
采用盒计数算法计算所有图像的分形维数。图14中lena、bird和rice的图像是为了说明问题。下表1中列出了分形维数得到的结果。

图14,原图:(a) Lena (b) bird (c ) rice;40% 损坏的图:(d) Lena (e) bird (f)rice

表1,使用盒计数法得到的分形维数
在不同的噪声水平下,计算了被破坏的Lena, bird和rice图像的分形维数。其结果见表2
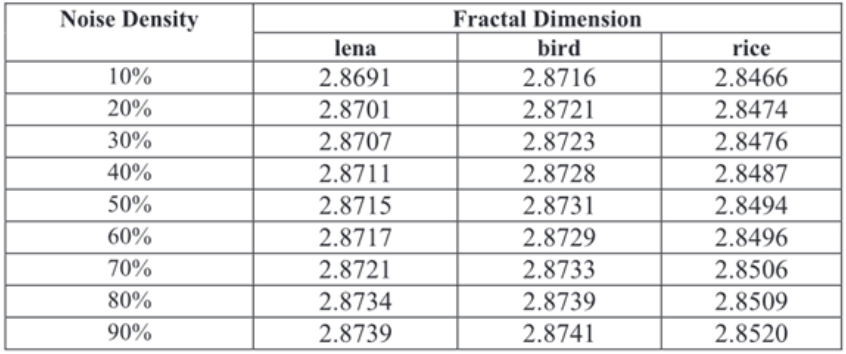
表2,Lena, bird和rice的损坏图像的分形维数
由表2可知,图像的分形维数与粗糙度成正比增加。图像的粗糙度与噪声密度成正比,在这种情况下,由于椒盐噪声的增加,粗糙度增加了。
由以上结果可知,分形维数是比较图像粗糙度的一种合适的度量。
由于粗糙度在纹理分析中起着重要的作用,分形是一种很好的基于粗糙度的纹理分类方法。
图像梯度
图像梯度是许多计算机视觉任务的基本组成部分之一,也是纹理分类的一项重要技术。图像梯度的主要应用是在边缘检测中。当纹理在不合适的光照下被捕获时,边缘检测对于寻找纹理的边界是很有用的。
由于图像梯度是图像强度的方向变化,为了计算图像的梯度,我们需要大小和方向,即梯度大小:图像强度变化的强度的度量,和梯度方向:图像强度变化的方向的度量。
为了测量大小,我们计算垂直变化(Gᵧ)和水平变化(Gₓ),
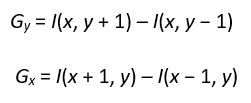
现在梯度大小(G)和梯度方向(θ)可以用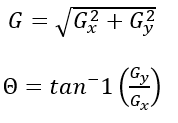 Sobel方法是一种用于寻找图像梯度的技术。在这种技术中,所有图像的垂直和水平核都是预先定义的,它们被用来计算图像梯度(结果显示在图15中)。
Sobel方法是一种用于寻找图像梯度的技术。在这种技术中,所有图像的垂直和水平核都是预先定义的,它们被用来计算图像梯度(结果显示在图15中)。

图15,左:原始lena图像,右:Sobel实现的图像梯度
现在这个图像梯度已经突出了所有的边缘,以类似的方式,图像梯度识别所有图像的边缘,这将确保不同的纹理区域将被有效分割。
在深度学习中使用这些技术
到目前为止,我们已经了解了各种纹理提取特征。让我们看看如何将这些技术与深度学习相结合,这样我们越来越接近使用纹理分类解决现实生活中的用例。
纹理分类可以使用卷积神经网络(CNN)实现。一个基本的CNN如图16所示。CNN具有非凡的感知模式的能力,很可能是最精通的深度学习方法。唯一的缺点是,找到不同超参数的理想值仍然是一个主要的挑战。
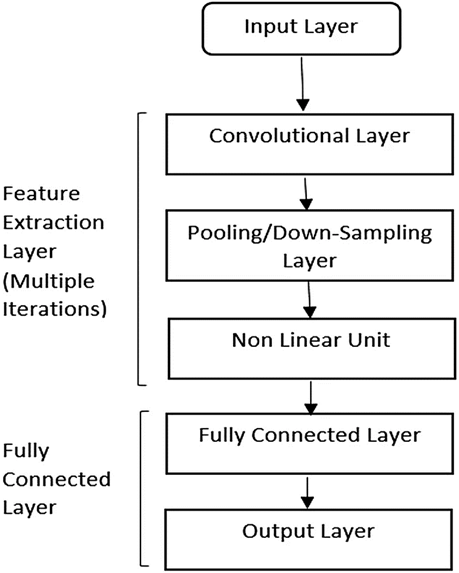
图16,基本CNN模型
由于纹理分类是一项复杂的任务,基本的CNN模型可能不适用于高度基于纹理的数据集。因此,如图17所示,我们在做实验时使用了一个稍微高级的架构。该架构是2-D卷积层、池化(最大、最小或平均)和批归一化层的组合,使模型能够有效地训练。我们利用2D卷积层,以便更好地进行特征提取。根据数据集的复杂性,我们可以有更多的层。
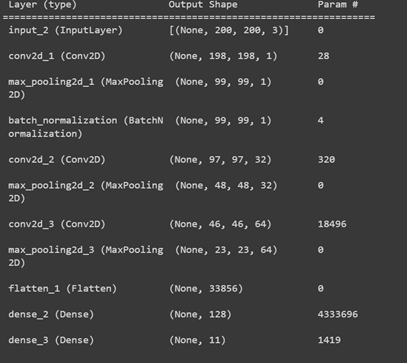
图17,一个输入的纹理分类的CNN模型
我们还尝试了另一种方法,如图18所示,我们将输入图像与纹理(转换)图像结合起来,并使用共享权重机制将它们传递到卷积层。通过使用这种方法,更容易从变换后的图像中提取特征,因为它们有预先计算的特征值,并给网络关于图像代表什么的想法。无论是一个GLCM矩阵,或一个LBP矩阵,或一个图像梯度矩阵,或两个转换后的输入的组合,或三者的组合都可以作为输入的一部分与原始图像一起传递。
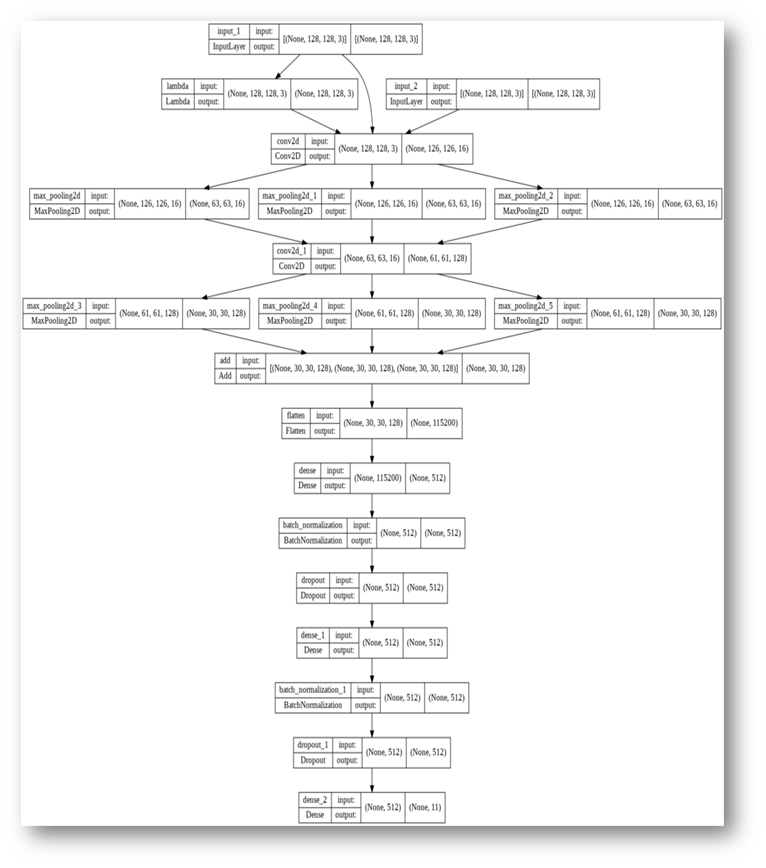
图18,3个输入的CNN纹理分类模型
在图18中,原始图像的一个输入后面跟着一个lambda层,用于第二个输入和转换后的图像的第三个输入。在它们旁边是卷积层,输入大小为128×128,输出大小为126×126。卷积层的输出被送入三个Max-Pooling层,一个Max-Pooling层用于每个输出大小为63×63的输入。遵循相同的过程,直到使用Add层来连接所有三个输出,并产生30×30大小的输出。Flatten层用于115200个输出,然后是输出为512的dense层,随后是批归一化和Dropout层,以相同的顺序添加了两次。最后,添加一个有11个输出神经元的dense层。
我们在基于纹理的KTH数据集,包含11个材质的图像上进行了纹理分类任务的实验。
表3,不同的方法的对比
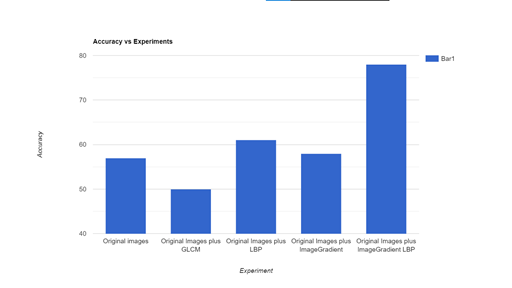
图19,对表3的可视化图
从表3和图19中,我们可以看到,当更相关(纹理丰富)的信息作为输入传递给深度学习模型时,准确率显著提高。这些技术包括两个以上的特征作为输入,如GLCM矩阵、LBP矩阵、小波和分形维数,以及原始输入图像。
这主要是因为模型也从纹理特征中学习,证明了监督预训练和几个转换后的特征矩阵的直接相关性,可以提高精度。
一般来说,信息转换后的输入代表相关特征,从而导致更好的准确性。然而,在这种关系中也有一些例外——例如,当原始输入与GLCM结合时,在特定情况下,精度会下降一小部分(图19)。
在本博客中,我们详细解释了纹理特征的主要类型及其分析,并演示了提供更多信息数据(以纹理特征的形式)的方法可以有助于提高CNN模型的性能。我们将在接下来的文章中进一步探讨这个概念。
英文原文:https://medium.com/@trapti.kalra_ibm/texture-analysis-with-deep-learning-for-improved-computer-vision-aa627c8bb133
- 相关推荐
- 热点推荐
- 深度学习
-
虚幻引擎的纹理最佳实践2023-08-28 747
-
讨论纹理分析在图像分类中的重要性及其在深度学习中使用纹理分析2022-10-26 2970
-
如何在深度学习结构中使用纹理特征2022-10-10 2134
-
如何在深度学习中使用纹理分析2022-09-29 1981
-
为什么传统CNN在纹理分类数据集上的效果不好?2022-09-23 1639
-
基于cnn的纹理分类以及常用的纹理数据集2022-09-14 4234
-
图像纹理的特征与分类2019-04-30 1822
-
纹理映射原理的介绍和标准纹理映射等的方程详细概述2018-05-05 5810
-
结合颜色和纹理特征的图像检索算法2017-12-18 992
-
纹理与轮廓结合的行人检测2017-11-27 1209
-
基于纹理几何结构的纹理描述图像分割2017-11-22 1120
-
离散傅里叶变换和组合能量熵的纹理图像分析2011-12-16 918
-
基于纹理分析的笔迹鉴别系统2009-06-03 521
-
纹理特征分析及特征量计算2009-03-01 2311
全部0条评论

快来发表一下你的评论吧 !
