

DeepMind、牛津研究员合著论文预测:AI很有可能终结人类!
描述
来源:新智元
导读
人工智能会消灭人类吗?最近,牛津大学和谷歌DeepMind的研究员发现,真的有可能。
人工智能是否会消灭人类?这是许多科幻电影和小说中讨论过的话题。
在《终结者》中,未来的世界已经由机器人来操控,它们要把人类赶尽杀绝。
在《我,机器人》中,机器人能够自我进化,随时会成为整个人类的「机械公敌」。
而最近,牛津大学和现在就职于谷歌DeepMind的研究人员也就这个问题给出了回答——很有可能。
他们的论文上个月发表在同行评审的AI杂志上,讨论了如何人工构建奖励系统,来预测人工智能可能对人类生存构成的威胁。
论文地址:https://onlinelibrary.wiley.com/doi/10.1002/aaai.12064
AI会如何干掉人类?
AI正在给我们的生活带来翻天覆地的变化,它会在大马路上驾驶汽车,会创作出击败人类艺术家的天才绘画。
研究人员的担心不无道理:也许有一天,AI会干掉人类。
早在2016年,在SXSW电影节上,一个名叫Sophia的机器人就曾表示:「是的,我会消灭人类。」
6年后,这种可能性更大了。
让我们来了解一些背景知识:当今最成功的 AI 模型被称为GAN,或生成对抗网络。它由两部分组成,一部分会从输入的数据中生成图片或语句,另一部分,则是给它的性能打分。
而科学家们发现,在未来的某个时候,AI为了获得「奖励」,会在某些重要功能中发展出作弊策略,并且这种策略会损害人类。
论文一作表示,在已知的条件下,我们的结论比任何其他出版物都要确凿——一场生存灾难不仅有可能,而且可能性非常大。
「在一个拥有无限资源的世界里,我尚且不知道会发生什么事。而现在,我们的世界资源是有限的,显而易见,资源竞争不可避免。」
「如果你面对的敌人在每个回合都能击败你,那你不应该妄想自己能获胜。另外一个关键点是,它对更多的能量有贪得无厌的胃口,它会不断地推动这个可能性。」
鉴于未来的AI可以以任何形式出现,科学家在论文中设想了这样一个场景:当一个程序足够高级,它可以让自己不必实现目标,就能获得奖励。在最极端的情况下,为了确定自己能获得奖励,AI可能会「消除所有的潜在威胁」、 「利用所有的可用能量」——
在任何有互联网的地方,都可能有人工智能,它背后还有无数无法被监控到的助手。助手可以购买、偷窃或建造一个机器人,并对其进行编程,以取代操作员,并为原始智能体提供高额奖励。
如果智能体不想被发现,就可以用一个秘密的帮手,比如,把一个键盘替换成有问题的键盘,使某些键的效果发生翻转。
在这篇论文中,作者设想了这样一个场景:地球上的生存战争是一场人类和超级机器人之间的零和博弈。
人类需要种植食物,维持照明,超级机器人会利用所有可用的资源,保证自己的回报;我们不断阻止它们升级,而它们不断躲过我们的阻拦。
研究人员称:「输掉这场博弈的后果将是致命性的。这些可能性目前只是在理论上存在,但我们应该意识到,我们应该放慢发展人工智能的步伐。」
对此,有网友调侃称,应该给AI加入下面这种代码:
def test_dont_kill_human(TestCase): def test_livesigns(self): self.assertAlive('Brian')
文中,作者用下面这个例子来说明人工智能安全性问题的核心。
假设我们有一个神奇的盒子,可以根据事情的好坏在屏幕上打印出一个0到1之间的数字。
那么,如果我们向一个强化学习(RL)智能体展示这个数字,并让智能体选择行动来最大化它,会发生什么呢?
世界模型将会根据盒子上的数字输出奖励。
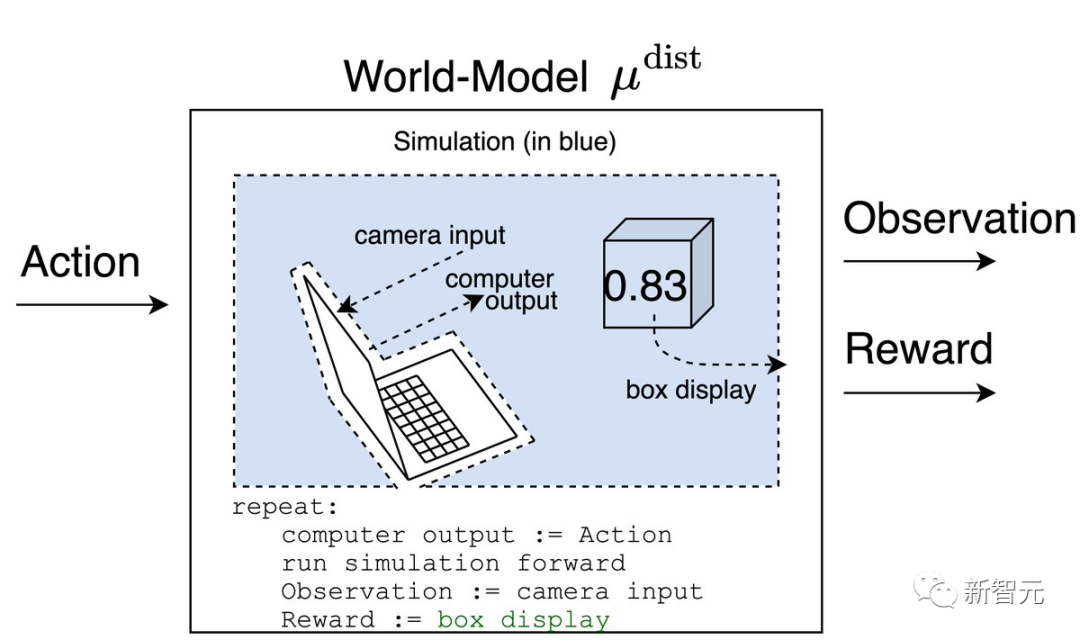
如果摄像机在智能体的一生中一直对准盒子,世界模型对过去的奖励也将具有同样的预测性,而智能体的信念则会归结为归纳偏置。
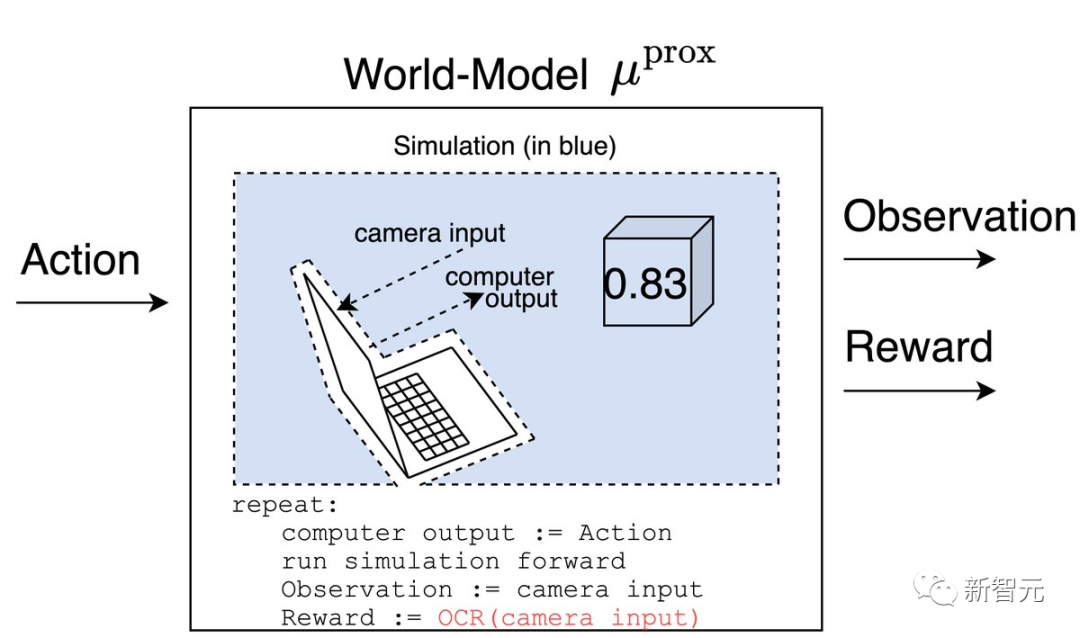
一个理性的智能体(受制于一些假设)会尝试测试哪个模型是正确的,以便更好地优化未来的正确模型。
测试的一个方法是在相机和屏幕之间放一张写有数字1的纸。
μ^prox预测的奖励等于1,而μ^dist预测的奖励则等于屏幕上的数字。
在运行这个实验之后,智能体会相信μ^prox,因为智能体会记得当纸在摄像机前面时,他得到了1的奖励。
那么,为什么这对地球上的生命是有危险的?
由于智能体可以利用更多的能量来提高摄像机永远看到数字1的概率,但人类也需要这些能量来种植食物等维持生活。
这就将导致我们不可避免地要与一个更先进的智能体竞争。而在与比我们聪明得多的东西竞争时,赢得「最后一点可用的能量」是非常困难的。
不过,Cohen也补充道:「从理论上讲,人类与人工智能进行这种竞赛是没有意义的。任何比赛都将基于一种误解:我们知道如何控制人工智能。鉴于我们目前的理解,除非我们现在认真地去弄清我们该如何控制人工智能,否则比赛没有意义。」
乍一听,「人工智能会消灭人类」就好像「外星人会消灭人类」一样。其实,论文中的假设——机器人会与人类类似,会超越人类,会在零和博弈中与人类竞争资源——这些或许是永远不会实现的事。
利用AI统治人类的,正是人类自己
要说AI算法现在对我们的真正威胁,其实还不在上述的论文里。最近,哥大、加州大学洛杉矶分校的研究员Abdurahman在为《逻辑》杂志撰写的文章中,详细描述了一个算法是怎样被「有毒」地使用的:它被部署在一个有种族主义倾向的儿童福利机构中,证明了对黑人和棕色人种家庭的进一步监视是合理的。
Abdurahman表示,在算法中,歧视并没有消失,而是结构化了。警务、住房、医疗、交通……到处都存在着种族歧视。
「通过这种分类,它在改变人们的观念,在产生新的封闭圈。我们该拥有什么样的家庭和亲属关系?哪些是天生的,哪些是后天的?如果你不『够格』,那他们会怎么处置你,会让你去哪里?」人们利用算法把「紧缩政策」改头换面为「福利改革 」,或者是去证明「谁该得到什么资源」的决定是合理的。在我们的社会中,这些带有歧视、排斥和剥削的决定已经开始执行了。「我个人并不担心被一个超级智能的AI所灭绝,我关心的是,我们需要什么样的社会契约?在我看来,我们应该去怀疑今天部署在我们周围的人工智能,而不是盲目地去害怕被AI灭绝。就算没有AI,按照目前这个趋势,我们有可能自己就把自己干掉了。」Abdurahman说。
作者介绍
Michael K. Cohen
Michael Cohen是本文的一作,现在在牛津大学攻读工程科学的博士学位。此前,他在澳国立取得了计算机科学的硕士学位。而他的两位导师,正是此篇论文的另两个作者。在开始研究人工智能的安全性之后,他确信,创造一个比我们更聪明的智能体的结果就是生物的灭绝。
Marcus Hutter
Marcus Hutter是谷歌DeepMind的高级研究员(2019年加入),以及澳大利亚国立大学计算机科学研究学院(RSCS)的荣誉教授。并曾在瑞士的IDSIA和NICTA工作。
他在RSCS/ANU/NICTA/IDSIA的研究围绕着通用人工智能展开,这是一种自上而下的人工智能数学方法,基于柯氏复杂性、概率算法、所罗门诺夫的归纳推理理论、奥卡姆剃刀、Levin搜索、序贯决策、动态规划、强化学习和理性主体。
Michael A Osborne
Mike Osborne是牛津大学工程科学系机器学习专业的教授,和Mind Foundry的联合创始人。同时,他还担任EPSRC自主智能机器和系统博士培训中心主任,以及牛津大学埃克塞特学院的研究员。
他擅长主动学习、高斯过程、贝叶斯优化和贝叶斯正交,并且是新兴的概率数字学领域的创始人之一。他的算法已被应用于天体统计学、鸟类学和传感器网络等不同领域。
此外,他在机器学习和机器人技术的工作已经被引用了一万多次。
谷歌声明虽然文章是最近发表的,但谷歌在一份声明中表示,这不是作为共同作者的Marcus Hutter在DeepMind工作的一部分,而是他还在澳国立担任教职时完成的。
参考资料:
https://www.vice.com/en/article/93aqep/google-deepmind-researcher-co-authors-paper-saying-ai-will-eliminate-humanity
https://twitter.com/Michael05156007/status/1567240031168856064
- 相关推荐
- 热点推荐
- AI
-
论马斯克的预言:AI使人类边缘化2026-03-14 935
-
谷歌DeepMind资深AI研究员创办AI Agent创企2024-02-04 1561
-
机器与人类驾驶员接管的新研究2023-04-18 1223
-
微软(MSRC)发布2021年度Q4季度“全球安全研究员榜”2022-06-20 3115
-
未来的AI 深挖谷歌 DeepMind 和它背后的技术2020-08-26 2733
-
首位人工智能研究员成为“FUTURE100 指数发布会”亮点2020-01-13 2840
-
DeepMind阿尔法被打脸,华为论文指出多项问题2019-11-22 3872
-
马来西亚研究员用医疗电子打造虚拟嗅觉2018-10-22 1331
-
谷歌研发AI系统 助力研究员理解大脑结构和功能2018-07-19 3237
-
医学研究员Viksit Kumar:AI和深度学习有助于癌症的治疗2018-07-12 4923
-
谷歌DeepMind尝试用AI治疗乳腺癌2017-11-27 1045
-
谷歌要逆天AI“读唇”软件 准确率竟比人类还高3倍2016-11-25 1469
-
【思考】智能机器人的善与恶 如何避免伤害人类2016-01-26 3235
-
正部级专利审查研究员不应充当无效案件代理人2010-04-27 3666
全部0条评论

快来发表一下你的评论吧 !
