

自压缩神经网络
描述
过去十年,人工智能研究主要集中在探索深度神经网络的潜力。我们近年来看到的进步至少可以部分归因于网络规模的不断扩大。从使用GPT-3 [1] 的文本生成到使用 Imagen [2] 的图像生成,研究人员付出了相当大的努力来创建更大、更复杂的架构,以实现越来越令人印象深刻的壮举。此外,现代神经网络的成功使其在各种应用中部署。就在我写这篇文章的时候,一个神经网络正在施图预测我即将写的下一个单词,尽管它不够准确,不能很快取代我!
另一方面,性能优化在该领域受到的关注相对较少,这是神经网络更广泛部署的一个重大障碍。造成这种情况的一个可能原因是能够同时在数千个GPU 或其他硬件上的数据中心中训练大型神经网络。这与计算机图形领域形成鲜明对比,例如,必须在单台计算机上实时运行的限制产生了在不牺牲质量的情况下优化算法的强大动力。
神经网络容量的研究表明,发现高精度解决方案所需的网络容量大于表示这些解决方案所需的容量。Frankle和Carbin [3]在他们的论文《彩票假设:寻找稀疏、可训练的神经网络》 [3] 中发现,只需要网络中权重的一小部分即可代表一个好的解决方案,但直接训练容量减少的网络并不能达到相样的精度。同样,Hinton等人。[4] 发现,将“知识”从高精度网络转移到低容量网络可以产生比使用、相同损失函数的高容量网络更高精度的网络。
在本篇博文中,我们查找是否可以在训练时动态减少网络参数。虽然这样做具有挑战性,但由于实现的复杂性( PyTorch不是为处理动态网络架构而设计的,例如,在训练期间移除整个通道),
我们希望实现以下优点。
减少最终网络中的权重数量。
减少剩余权重的位宽。
减少最终网络的运行时间。
减少训练时间。
降低设计网络架构时选择层宽度的复杂性。
- 不需要特殊的硬件来优化(例如,不需要稀疏矩阵乘法)。
在这项工作中,我们通过引入一种新颖的量化感知训练(QAT)方案来实现这些目标,该方案平衡了最大化网络精度和最小化网络规模的要求。我们同时最大限度地提高精度并最大限度地减少权重位深度,从而消除不太重要或不必要的通道,从而以现有硬件可以轻松利用的方式降低计算和带宽需求。
可微量化这是通过可微量化实现的,正如我在之前的文章[5]中介绍的那样。简而言之,可微量化允许您同时学习数字格式的参数和权重。这允许以与网络中的权重完全相同的方式学习量化,并启用诸如自压缩网络之类的新技术——本文的主题。量化函数量化为可变比特率有符号定点格式:
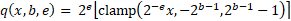
这可以描述为以下步骤顺序:
- 使用指数缩放输入值:
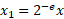
- 使用位深度钳位值:
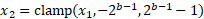
- 四舍五入到最接近的整数:
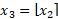
反转步骤 1 中引入的缩放: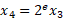
其中 b 是位深度,e 是指数,x 是被量化的值(或一组值) 。为了确保连续可微性,我们在训练期间使用实值位深度参数。
上述函数使用舍入运算。通过它传播可用梯度的常用方法是将四舍五入操作的梯度定义为1 而不是 0。这类似于“直通估计器” [6] 。要了解其工作原理,请考虑下图:
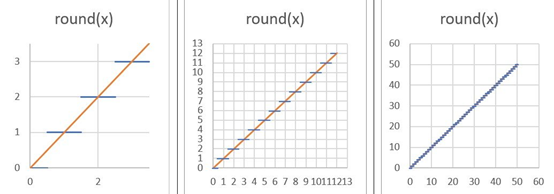
当我们从函数中“缩小”时,您可以看到它是如何实现的;舍入函数似乎接近y=x 线。我们将取整函数的后向传递(梯度)替换为函数 y=x 的梯度,即常数1。
可微量化进行自压缩
在这项工作中,我们使用可微量化(1)来减少训练期间网络参数的位宽(即压缩),以及(2)发现哪些参数可以用 0 位表示。当神经网络中的参数可以用 0 位表示而不影响网络的精度时,就没必要使用该参数。当发现权重张量中的通道可以用0 位表示时,在训练期间将其从网络中删除。这样做的一个附加好处是训练会随着时间的推移而加速(见图2)。
该过程可以描述如下:
- 将网络的参数拆分为通道。
- 用位宽和指数的单个量化参数对每个通道进行量化。
- 为原始任务训练网络,同时最小化所有位宽参数。
当位宽参数达到 0 时,从网络中移除该参数编码的网络权重通道。由于消除了整个输出通道,这减少了相应卷积的大小以及消耗输出张量的任何后续操作,而不会更改网络输出。
通过在训练期间从网络中移除空(即0 位)通道,我们可以显著加速训练而不改变训练结果:训练结果与我们在最后只移除空通道时得到的网络相同。
尽管本文中描述的方法学习压缩和消除通道,但它可以推广到其他硬件可利用的学习稀疏模式。
网络架构
选择的网络架构是David Page 的CIFAR-10[7]的DAWNbench条目,这是一个可以快速训练的浅ResNet 。
使用快速训练网络有几个优点,包括:
- 使算法设计迭代更快,
- 缩短调试周期,
- 使在合理的时间内在单个 GPU 上执行实验变得容易,
帮助重现这项工作的结果。
该网络由两种主要类型的块组成:卷积块(卷积→批量归一化→激活→池化)和残差块(残差分支由两个卷积块组成)。
以下部分描述了如何对这些模块应用可微量化以使其可压缩。
优化目标
这项工作的目标是减少神经网络的推理和训练时间。为了实现这一点,应该在损失函数中体现推理时间,以便将其最小化,从而产生更快的网络。在这种情况下使用的指标是网络规模,定义为用于表示网络中权重的总位数。作为网络性能的体现,计算层输出所需的激活张量大小或操作数也可以最小化。单个权重张量的大小可以用四个张量维度的乘积表示:输出通道、输入通道、滤波器高度和滤波器宽度(0、I、H、W)。由于我们使用一个单独的数字格式量化每个输出通道,并为层提供一个可学习的位数,因此用于表示张量的总位数由下式给出:
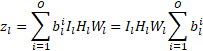
当 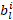 为 0 时,ith 通道变得不必要,减少了权重张量中的输出通道总数,以及下一个卷积的权重张量中相应的输入通道数。因此最小化通过
为 0 时,ith 通道变得不必要,减少了权重张量中的输出通道总数,以及下一个卷积的权重张量中相应的输入通道数。因此最小化通过 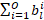 最小化输出通道的数量,可以最小化权重张量中的元素数量。这有效地最小化了权重张量的输出维度。认识到一层的输入通道数等于前一层的输出通道数,可以使压缩损失更好地反映网络的大小。这样一个权重张量的输入维度也可以最小化:
最小化输出通道的数量,可以最小化权重张量中的元素数量。这有效地最小化了权重张量的输出维度。认识到一层的输入通道数等于前一层的输出通道数,可以使压缩损失更好地反映网络的大小。这样一个权重张量的输入维度也可以最小化:
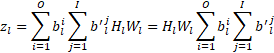
一旦通道可以被压缩到0 位,它就可能在训练期间被删除。然而,需要克服的实际问题是,从卷积层中移除一个输出通道并不一定意味着可以从下一层的输入中安全地移除相应的输入通道,因为可以将偏差添加到层的输出0中,在这种情况下删除它可能会显著改变网络的输出。为了处理这个问题,识别达到 0 位的加权通道(过滤器),并对其输出应用L1 损耗,以将其推至 0 位。只有当偏差减少到0 时,这些过滤器才会被移除,因为此时移除这样的通道不会改变网络的输出。
整个网络的大小是所有层大小的总和:
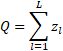
为了平衡网络的准确性和规模,我们简单地使用两项的线性组合:
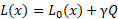
其中 L0 是网络的原始损失,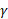 是压缩因子。较大的 会生成较小但不太准确的网络。
是压缩因子。较大的 会生成较小但不太准确的网络。
处理分支
压缩网络时出现的另一个问题是网络分支的处理,例如,在残差块中。解决这个问题最简单的方法是分别考虑这两个分支。
更新优化器
实现细节涉及使优化器随着网络的变化而更新的问题。优化器跟踪网络中每个参数的信息(元参数),当网络参数被动态删除时,相应的元参数也必须从优化器中删除。
结果
自压缩网络允许在规模和精度之间进行权衡,可以在规模准确度图中可视化(参见图1)。该图中的每个点都表示一个神经网络的大小和精度,该神经网络经过随机压缩率,从覆盖范围的对数均匀分布中采样 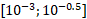 。图1 显示了在使用随机压缩率训练网络时,用于表示网络权重的位数与32 位每权重基线(对应于 32 位浮点)之间的关系。这是通过保留权重的百分比乘以剩余权重的平均位宽来计算的。网络的基线精度(未压缩精度)为95.69 ± 0.22。
。图1 显示了在使用随机压缩率训练网络时,用于表示网络权重的位数与32 位每权重基线(对应于 32 位浮点)之间的关系。这是通过保留权重的百分比乘以剩余权重的平均位宽来计算的。网络的基线精度(未压缩精度)为95.69 ± 0.22。
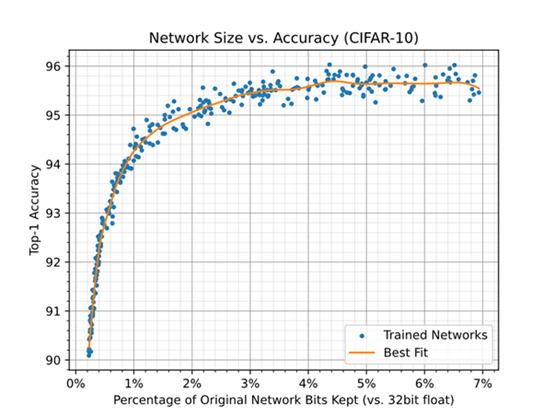
图 1:当使用随机压缩率训练网络时,用于表示网络权重的位数与32位/权重基线之间的关系。
图 2 仅显示了网络中使用的权重数量的减少。在不影响精度的情况下,可以移除大约 75% 的权重。
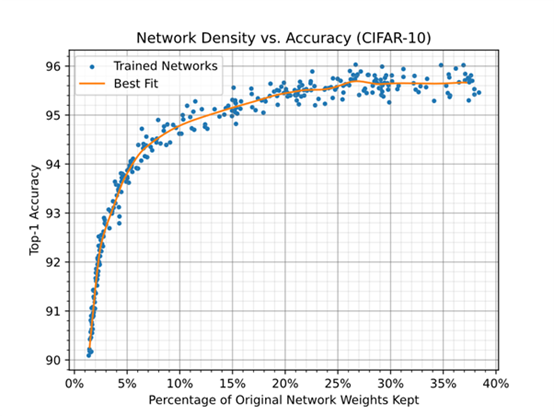
图 2 显示了使用随机压缩率训练网络时,网络中保留的权重百分比与精度之间的关系。
图 3 显示了通过在训练期间移除权重对训练时间的影响。一个世代的训练时间不仅取决于网络的大小,还取决于系统的其他部分,例如输入数据通道。为了确定基线训练开销,对于同一网络进行训练,每个层仅使用一个通道。每个训练世代大约需要7.5 秒。
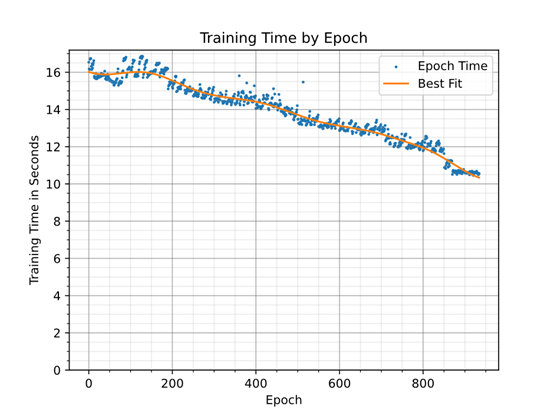 图 3:随着参数从网络中移除,神经网络训练时间加快。训练结束时移除了 86% 的权重。图 4 显示了
图 3:随着参数从网络中移除,神经网络训练时间加快。训练结束时移除了 86% 的权重。图 4 显示了  时使用压缩率训练的网络架构。训练将移除除残差层中的快捷分支。其余九个通道在训练结束时已经达到 0 位,并且正在消除它们的偏差。预计它们会随着更长的训练而消失。第二个残差层中的快捷分支与它相关的损失非常低(由于它对网络规模的贡献最小),因此它的减少速度太慢,无法在训练结束时消失。
时使用压缩率训练的网络架构。训练将移除除残差层中的快捷分支。其余九个通道在训练结束时已经达到 0 位,并且正在消除它们的偏差。预计它们会随着更长的训练而消失。第二个残差层中的快捷分支与它相关的损失非常低(由于它对网络规模的贡献最小),因此它的减少速度太慢,无法在训练结束时消失。
 图 4:训练前后的层大小和每层平均位宽的示例。这里删除了 86% 的权重和 97.6% 的位。每个方块代表一个卷积。方块中的值表示卷积的输出或输入(“in”)通道的总数,其中需要此类信息(在分支处)。
图 4:训练前后的层大小和每层平均位宽的示例。这里删除了 86% 的权重和 97.6% 的位。每个方块代表一个卷积。方块中的值表示卷积的输出或输入(“in”)通道的总数,其中需要此类信息(在分支处)。
图 5 显示了整个训练过程中的网络规格。它在早期迅速收缩,然后逐渐减少。
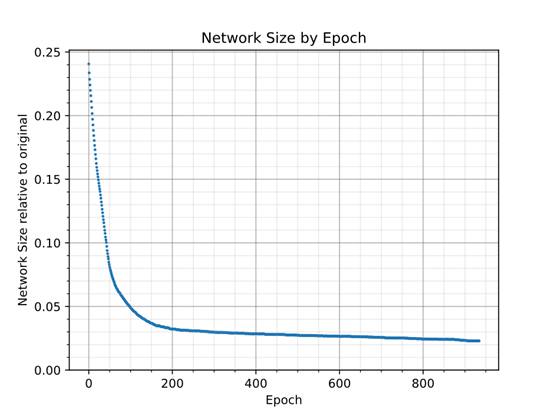
图 5:网络规模在训练早期快速缩小,之后逐渐减小。
优化您的网络
在本篇博文中,我们分享了一个通用框架,用于优化神经网络的典型固定特征——通道数和位宽——以使网络在训练过程中学会自我压缩。这样做的主要优点是更快的执行时间和更快的生成网络训练。以前的许多工作都集中在通过创建稀疏层来减少网络规模,这需要软件和/或硬件的特殊支持才能更有效地运行。简单地减少层的宽度不需要专门支持。通过减少 DRAM 带宽,支持可变位宽可以提高多种架构的性能。
参考
[1] T. B. Brown and al, “Language Models are Few-Shot Learners,” 2020.
[2] C. Saharia and al, “Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding,” 2022.
[3] J. Frankle and M. Carbin, “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks,” 2018.
[4] G. Hinton, O. Vinyals and J. Dean, “Distilling the Knowledge in a Neural Network,” 2015.
[5] Cséfalvay, S, “High-Fidelity Conversion of Floating-Point Networks for Low-Precision Inference using Distillation,” 25 May 2021. [Online]. Available: https://blog.imaginationtech.com/low-precision-inference-using-distillation/.
[6] G. Hinton, “Lecture 9.3 — Using noise as a regularizer [Neural Networks for Machine Learning],” 2012. [Online]. Available: https://www.youtube.com/watch?v=LN0xtUuJsEI&list=PLoRl3Ht4JOcdU872GhiYWf6jwrk_SNhz9.
[7] Page, D, “How to Train Your ResNet 8: Bag of Tricks,” 19 Aug 2019. [Online]. Available: https://myrtle.ai/how-to-train-your-resnet-8-bag-of-tricks/.
本文作者:Szabolcs Cséfalvay
- 相关推荐
- 热点推荐
- 人工智能
-
神经网络压缩框架 (NNCF) 中的过滤器修剪统计数据怎么查看?2025-03-06 403
-
神经网络教程(李亚非)2012-03-20 58575
-
卷积神经网络如何使用2019-07-17 2900
-
【案例分享】ART神经网络与SOM神经网络2019-07-21 3334
-
如何设计BP神经网络图像压缩算法?2019-08-08 4010
-
基于三层前馈BP神经网络的图像压缩算法解析2021-05-06 1785
-
如何构建神经网络?2021-07-12 2035
-
基于BP神经网络的PID控制2021-09-07 2757
-
采用BP神经网络的通用数据压缩方案2009-09-11 823
-
BP神经网络图像压缩算法乘累加单元的FPGA设计2010-03-29 976
-
深度神经网络的压缩和正则化剖析2017-11-16 2348
-
神经网络图像压缩算法的FPGA实现技术研究论文免费下载2021-03-22 1374
-
基于剪枝与量化的卷积神经网络压缩算法2021-05-17 1325
-
一文详解自压缩神经网络2022-10-25 696
-
卷积神经网络的压缩方法2024-07-11 1580
全部0条评论

快来发表一下你的评论吧 !
