

MPU进化,多核异构处理器有多强?A核与M核通信过程解析
描述
随着市场对嵌入式设备功能需求的提高,市面上出现了集成嵌入式处理器和单片机的主控方案,以兼顾性能和效率。
在实际应用中,嵌入式处理器和单片机之间需要进行大量且频繁的数据交换,如果采用低速串行接口,则数据传输效率低,这将严重影响产品的性能;而如果采用高速并口,则占用管脚多,硬件成本将会增加。
为解决这一痛点,各大芯片公司陆续推出了兼具A核和M核的多核异构处理器,如NXP的i.MX8系列、瑞萨的RZ/G2L系列以及TI的AM62x系列等等。虽然这些处理器的品牌及性能有所不同,但多核通信原理基本一致,都是基于寄存器和中断传递消息,基于共享内存传输数据。
以配电终端产品为例,A核负责通讯和显示等人机交互任务,M核负责采样和保护等对实时性要求较高的任务,双核间交互模拟量、开关量和录波文件等多种信息,A核+M核的方案既满足了传统采样保护功能,又支持多种接口通信及新增容器等功能,符合国家电网现行配电标准。
 通信过程整体架构说明
通信过程整体架构说明
接下来小编将以NXP的i.MX8MP为例,借助飞凌OKMX8MP-C开发板分别从硬件层、驱动层、应用层介绍大致的通信实现流程以及实测效果。
1. 硬件层通信实现机制
通过物理内存DDR分配,将硬件层分为了两部分:TXVring Buffer(发送虚拟环状缓冲区)和RXVring Buffer(接收虚拟环状缓冲区);其中M核从TXVring区发送数据,从RXVring区读取接收数据,A核反之。
处理器支持消息传递单元(MessagingUnit,简称MU)功能模块,通过MU传递消息进行通信和协调,芯片内的M7控制核和A53处理核通过通过寄存器中断的方式传递命令,最多支持4组MU双向传递消息,既可通过中断告知对方数据传递的状态,也可发送最多4字节数据,还可在低功耗模式下唤醒对方,是保证双核通信实时性的重要手段。
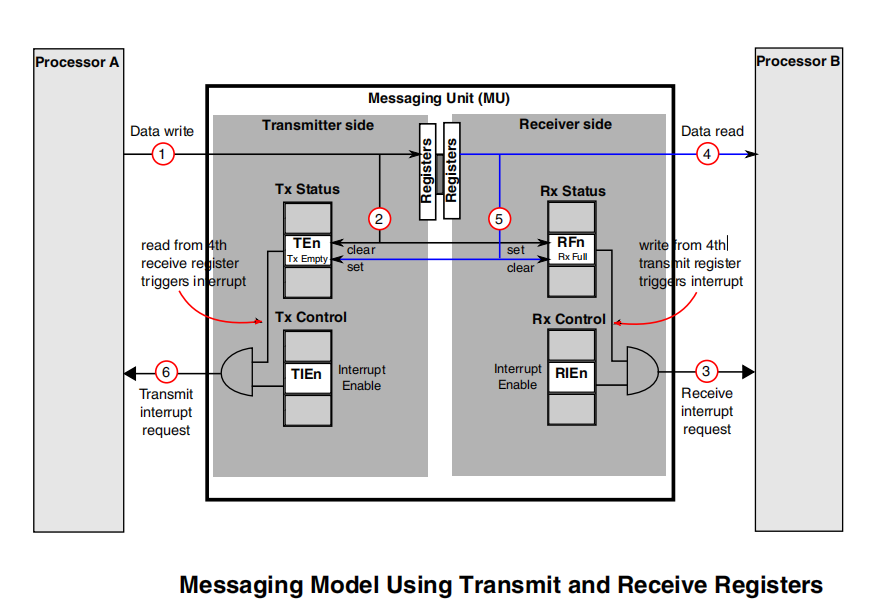 寄存器输入输出通信模型
寄存器输入输出通信模型
(1)CoreA写入数据;
(2)MU将Tx 空位清0,Rx满位置1;
(3)产生接收中断请求,通知CoreB接收状态寄存器中的接收器满,可以读取数据;
(4)CoreB响应中断,读取数据;
(5)CoreB读完数据后,MU将Rx满位清0,Tx空位置1;
(6)状态寄存器向CoreA生成发送中断请求,告知CoreB读完数据,发送寄存器空。
通过以上步骤,就完成了1次从CoreA向CoreB 传递消息的过程,反之亦然。
2. 驱动层Virtio下RPMsg通信实现
Virtio是通用的IO虚拟化模型,位于设备之上的抽象层,负责前后端之间的通知机制和控制流程,为异构多核间数据通信提供了层的实现。
RPMsg消息框架是Linux系统基于Virtio缓存队列实现的主处理核和协处理核间进行消息通信的框架,当客户端驱动需要发送消息时,RPMsg会把消息封装成Virtio缓存并添加到缓存队列中以完成消息的发送,当消息总线接收到协处理器送到的消息时也会合理地派送给客户驱动程序进行处理。
在驱动层,对A核,Linux采用RPMsg框架+Virtio驱动模型,将RPMsg封装为了tty文件供应用层调用;在M核,将Virtio移植,并使用简化版的RPMsg,因为涉及到互斥锁和信号量,最终使用FreeRTOS完成过程的封装,流程框图如下方所示。
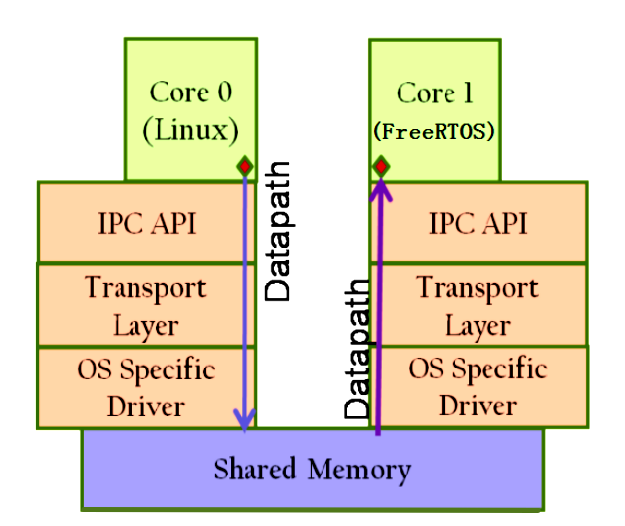 主处理核与协处理核数据传递流程图
主处理核与协处理核数据传递流程图
(1)Core0向Core1发送数据,通过rpmsg_send函数将数据打包至Virtioavail链表区;
(2)在avail链表寻找共享内存中空闲缓存,将数据置于共享内存中;
(3)通过中断通知Core1数据到来,共享内存由avail链表区变至used区;
(4)Core1收到中断,触发rpmsg的接收回调函数,从used区获取数据所在的共享内存的物理地址,完成数据接收;
(5)通过中断通知Core0数据接收完成,共享内存缓存由used区变为avail区,供下次传输使用。
3. 应用层双核通信实现方式
在应用层,对A核可使用open、write和read函数对 /dev下设备文件进行调用;对M核,可使用rpmsg_lite_remote_init、rpmsg_lite_send和rpmsg_queue_recv函数进行调用,不做重点阐述。
4. 实际使用效果
通过程序实测,M核和A核可以批量传输大数据。同样以配电产品为例——128点采样的录波文件大约为43K,若通过传统的串行总线传输方式,需要数秒才可完成传输。
而使用i.MX8MP的双核异构通信方案,只需要不到0.5秒即可传输完成,数据传输效率提升数十倍!同时还避免了串行总线易受EMC干扰的问题,提高了数据传输稳定性,简化了应用编程,可满足用户快速开发的需求。
以上就是多核异构处理器中A核与M核通信过程的解析,想要了解具体详细程序实例,可到【飞凌嵌入式官方微信公众号】回复关键词“程序实例”查看。
- 相关推荐
- 热点推荐
- 处理器
-
【老法师】多核异构处理器中M核程序的启动、编写和仿真2025-08-13 4367
-
多核异构中A核与M核通信过程2023-10-31 3192
-
多核异构处理器对共享外设和资源的调配方法2023-03-10 1480
-
基于OKMX8MP-C板的多核异构处理器对外设和内存资源的使用方法2023-02-21 1318
-
多核异构处理器中A核与M核通信过程的解析2023-02-10 3661
-
【玩转多核异构】处理器对共享外设和资源的调配方法2023-02-07 1390
-
A核+M核通信过程解析2022-11-23 1402
-
MPU进化,多核异构处理器有多强?2022-11-21 1432
-
核间通信(IPC)解决方案2022-11-03 2028
-
探究一种新的可配置处理器的异构多核线程级动态调度模型2021-04-27 3100
-
创龙带您解密TI、Xilinx异构多核SoC处理器核间通讯2020-09-08 2462
-
基于SystemC的异构多核通信模块设计2010-01-20 872
-
嵌入式异构多核的片上通信架构设计2009-12-04 1029
全部0条评论

快来发表一下你的评论吧 !
