

旭日X3派BPU部署教程系列之手把手带你成功部署YOLOv5
描述
环境配置
安装依赖包
如果在当前python环境下能利用pip install onnx轻松安装onnx,直接配置YOLOv5的环境即可;如果环境安装有一些限制,建议跑模型的python环境为3.10。
# 在指定路径下创建虚拟环境,我的anaconda安装在c盘,但我想把环境放在d盘,所以利用--prefix D:\Anaconda3\envs\yolov5指定路径 conda create --prefix D:\Anaconda3\envs\yolov5 python=3.10 # 切换虚拟环境 conda activate D:\Anaconda3\envs\yolov5 # 安装关键包ONNX pip install -i https://pypi.tuna.tsinghua.edu.cn/simple onnx # 安装yolov5依赖的pytorch pip install "torch-1.11.0+cu113-cp310-cp310-win_amd64.whl" "torchaudio-0.11.0+cu113-cp310-cp310-win_amd64.whl" "torchvision-0.12.0+cu113-cp310-cp310-win_amd64.whl" -i https://pypi.tuna.tsinghua.edu.cn/simple # 安装yolov5需要的包 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple matplotlib>=3.2.2 numpy>=1.18.5 opencv-python>=4.1.1 Pillow>=7.1.2 PyYAML>=5.3.1 requests>=2.23.0 scipy>=1.4.1 tqdm>=4.64.0 tensorboard>=2.4.1 pandas>=1.1.4 seaborn>=0.11.0 ipython psutil thop>=0.1.1
运行YOLOv5
下载文件,参照如下流程操作:
①解压yolov5-master.zip;
②将zidane.jpg放到yolov5-master文件夹中;
③将yolov5s.pt放到yolov5-master/models文件夹中;
④进入yolov5-master文件夹,输入python .\detect.py --weights .\models\yolov5s.pt --source zidane.jpg,代码会输出检测结果保存路径(以我为例:Results saved to runs\detect\exp9)检测结果如下所示。

PyTorch的pt模型文件转onnx
注意:BPU的工具链没有支持onnx的所有版本的算子,即当前BPU支持onnx的opset版本为10和11。
# 错误的转换指令 python .\export.py --weights .\models\yolov5s.pt --include onnx # 正确的转换指令 python .\export.py --weights .\models\yolov5s.pt --include onnx --opset 11
转换后,控制台会输出一些log信息,转换后的模型文件在.\models\yolov5s.pt。
export: data=D:\05 - \01 - x3\BPUCodes\yolov5\yolov5-master\data\coco128.yaml, weights=['.\\models\\yolov5s.pt'], imgsz=[640, 640], batch_size=1, device=cpu, half=False, inplace=False, train=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['onnx'] YOLOv5 2022-9-1 Python-3.10.4 torch-1.11.0+cu113 CPU Fusing layers... YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients PyTorch: starting from models\yolov5s.pt with output shape (1, 25200, 85) (14.1 MB) ONNX: starting export with onnx 1.12.0... ONNX: export success 3.6s, saved as models\yolov5s.onnx (28.0 MB) Export complete (4.2s) Results saved to D:\05 - \01 - x3\BPUCodes\yolov5\yolov5-master\models Detect: python detect.py --weights models\yolov5s.onnx Validate: python val.py --weights models\yolov5s.onnx PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'models\yolov5s.onnx') Visualize: https://netron.app
模型转换
新建一个文件夹bpucodes(可根据喜好自行命名),把前面转好的yolov5s.onnx放进这个文件夹里,在docker中,进入bpucodes文件夹,开始我们的模型转换。
(PS:模型转换需在docker中转换,怎么安装docker,怎么进入OE,怎么挂载硬盘等相关问题可在系列一中进行查看)
模型检查
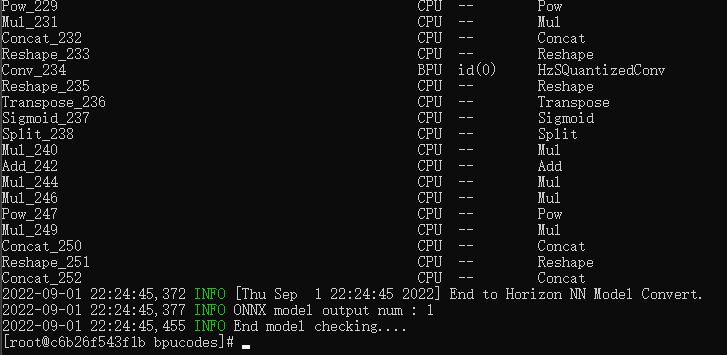
模型检测的目的是检测有没有不支持的算子,输入指令hb_mapper checker --model-type onnx --march bernoulli2 --model yolov5s.onnx,开始检查模型,显示如下内容表示模型检查通过。这时可以发现网络的后端部分存在一些层是运行在CPU上的,这会导致耗时多一些。
准备校准数据
校准数据的代码参考系列一中的YOLOv3的校准代码,整体没有太多改变,输入prepare_calibration_data.py可以得到校准数据。
# 修改输入图像大小为640x640 img = imequalresize(img, (640, 640)) # 指定输出的校准图像根目录 dst_root = '/data/horizon_x3/codes/yolov5/bpucodes/calibration_data
开始转换BPU模型
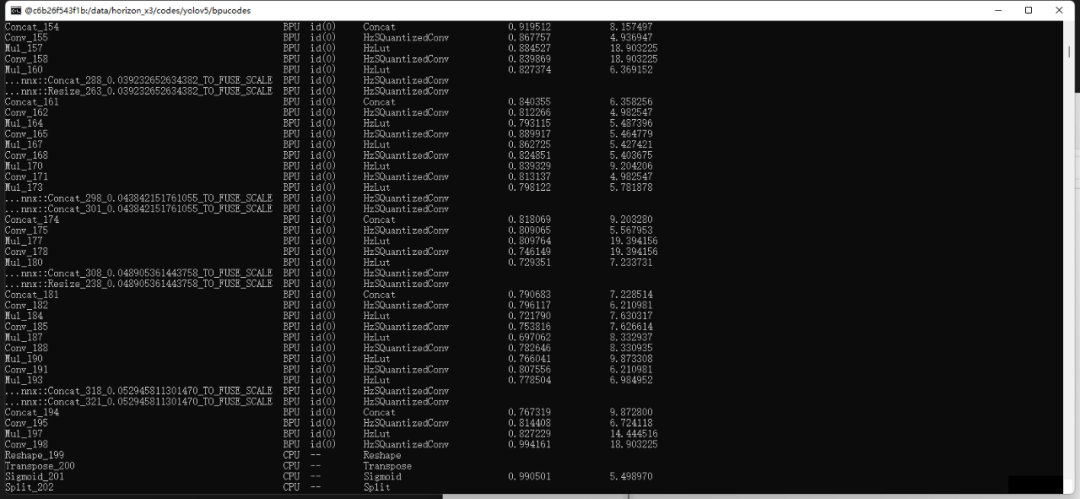
输入命令hb_mapper makertbin --config convert_yolov5s.yaml --model-type onnx开始转换我们的模型。校准过后会输出每一层的量化损失,转换成功后,得到model_output/yolov5s.bin,这个文件拿出来,拷贝到旭日X3派上使用,它也是我们上板运行所需要的模型文件。
上板运行
文件准备
下载百度云的文件,拷贝到旭日X3派开发板中,其中yolov5s.bin就是我们转换后的模型,coco_classes.names仅用在画框的时候,如果用自己的数据集的话,参考coco_classes.names创建个新的名字文件即可。
输入sudo apt-get install libopencv-dev安装opencv库,之后进入代码根目录,输入python3 setup.py build_ext --inplace,编译后处理代码,得到lib/pyyolotools.cpython-38-aarch64-linux-gnu.so文件。
运行推理代码
模型推理的代码如下所示,其中yolotools.pypostprocess_yolov5为C++实现的后处理功能,推理代码在我这里保存为inference_model_bpu.py。
import numpy as np import cv2 import os from hobot_dnn import pyeasy_dnn as dnn from bputools.format_convert import imequalresize, bgr2nv12_opencv # lib.pyyolotools为封装的库 import lib.pyyolotools as yolotools def get_hw(pro): if pro.layout == "NCHW": return pro.shape[2], pro.shape[3] else: return pro.shape[1], pro.shape[2] def format_yolov5(frame): row, col, _ = frame.shape _max = max(col, row) result = np.zeros((_max, _max, 3), np.uint8) result[0:row, 0:col] = frame return result # img_path 图像完整路径 img_path = '20220904134315.jpg' # model_path 量化模型完整路径 model_path = 'yolov5s.bin' # 类别名文件 classes_name_path = 'coco_classes.names' # 设置参数 thre_confidence = 0.4 thre_score = 0.25 thre_nms = 0.45 # 框颜色设置 colors = [(255, 255, 0), (0, 255, 0), (0, 255, 255), (255, 0, 0)] # 1. 加载模型,获取所需输出HW models = dnn.load(model_path) model_h, model_w = get_hw(models[0].inputs[0].properties) print(model_h, model_w) # 2 加载图像,根据前面模型,转换后的模型是以NV12作为输入的 # 但在OE验证的时候,需要将图像再由NV12转为YUV444 imgOri = cv2.imread(img_path) inputImage = format_yolov5(imgOri) img = imequalresize(inputImage, (model_w, model_h)) nv12 = bgr2nv12_opencv(img) # 3 模型推理 t1 = cv2.getTickCount() outputs = models[0].forward(nv12) t2 = cv2.getTickCount() outputs = outputs[0].buffer # 25200x85x1 print('time consumption {0} ms'.format((t2-t1)*1000/cv2.getTickFrequency())) # 4 后处理 image_width, image_height, _ = inputImage.shape fx, fy = image_width / model_w, image_height / model_h t1 = cv2.getTickCount() class_ids, confidences, boxes = yolotools.pypostprocess_yolov5(outputs[0][:, :, 0], fx, fy, thre_confidence, thre_score, thre_nms) t2 = cv2.getTickCount() print('post consumption {0} ms'.format((t2-t1)*1000/cv2.getTickFrequency())) # 5 绘制检测框 with open(classes_name_path, "r") as f: class_list = [cname.strip() for cname in f.readlines()] t1 = cv2.getTickCount() for (classid, confidence, box) in zip(class_ids, confidences, boxes): color = colors[int(classid) % len(colors)] cv2.rectangle(imgOri, box, color, 2) cv2.rectangle(imgOri, (box[0], box[1] - 20), (box[0] + box[2], box[1]), color, -1) cv2.putText(imgOri, class_list[classid], (box[0], box[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, .5, (0,0,0)) t2 = cv2.getTickCount() print('draw rect consumption {0} ms'.format((t2-t1)*1000/cv2.getTickFrequency())) cv2.imwrite('res.png', imgOri)
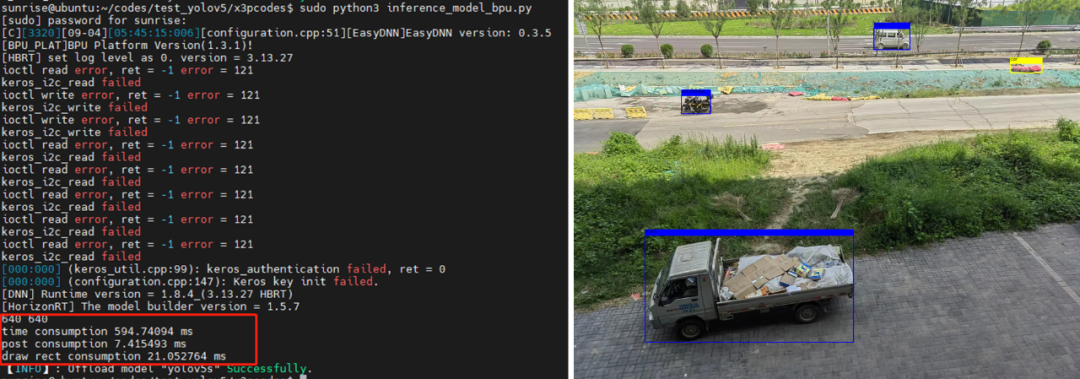
输入sudo python3 inference_model_bpu.py,推理结果保存为res.png,相关结果如下所示,可以看出,后处理部分耗时为7ms,C++和Python混编有效提升了代码的运行速度。
利用Cython封装后处理代码
①写后处理的C++代码
首先,创建头文件yolotools.h,用来记录函数声明,方便其他代码调用。因为Cython调用时,调用C++的一些类并不方便,所以写成C语言接口更方便调用。后处理的函数名为postprocess_yolov5,创建yolov5postprocess.cpp来对后处理函数进行实现。
②写Cython所需的Pyx文件
同级目录下创建pyyolotools.pyx,切记文件名不要跟某个CPP重复了,因为cython会将pyyolotools.pyx转为pyyolotools.cpp,如果有重复的话可能会导致文件被覆盖掉。
③写编译Pyx所需的python代码
创建setup.py文件,将下面代码放进去,配置好opencv的头文件目录、库目录、以及所需的库文件。在Extension中配置封装的函数所依赖的文件,然后在控制台输入python3 setup.py build_ext --inplace即可。
本文转自地平线开发者社区
原作者:小玺玺
-
基于瑞芯微RK3576的 yolov5训练部署教程2025-09-11 3450
-
yolov5转onnx在cubeAI进行部署,部署失败的原因?2025-03-07 456
-
【YOLOv5】LabVIEW+TensorRT的yolov5部署实战(含源码)2023-08-21 2408
-
使用旭日X3派的BPU部署Yolov52023-04-26 2084
-
平平无奇纵享丝滑,旭日X3派高速网络新体验2023-02-21 1774
-
在C++中使用OpenVINO工具包部署YOLOv5模型2023-02-15 12581
-
yolov5训练部署全链路教程2023-01-05 4831
-
旭日X3派BPU部署教程系列之带你轻松走出模型部署新手村2022-11-29 2563
-
旭日X3派更新最小启动固件2022-11-10 1965
-
旭日,从地平线升起——地平线旭日X3派开箱试用2022-11-08 3191
-
#旭日X3派首百尝鲜#旭日x3派移植mjpg-streamer2022-08-10 2433
-
【地平线旭日X3派试用体验】开箱篇硬件介绍2022-07-26 7352
-
旭日X3派烧录最小启动固件2022-07-18 1817
-
龙哥手把手教你学视觉-深度学习YOLOV5篇2021-09-03 8029
全部0条评论

快来发表一下你的评论吧 !
