

在X3派上玩转一亿参数量超大Transformer,DIY专属你的离线语音识别
描述
Transformer模型在自然语言领域被提出后,目前已经扩展到了计算机视觉、语音等诸多领域。然而,虽然Transformer模型在语音识别领域有着更好的准确率,但还面临着一个问题,计算复杂度和内存储存开销会随着语音时长的增加而变大。
技术普及在于产品价格亲民,而价格亲民在于技术易落地易实现,离线语音识别应运而生,运用深度学习等技术且只需在本地进行运算就可实现人机语音交互,而且具备实时的响应速度、无需联网的特点,能更好的应用在大小家电、照明、车载、健康仪器、教育设备等行业。
本次内容由社区优秀开发者、首百第四批新品体验官——宋星辰将带领大家DIY个人专属离线语音识别,在X3派上玩转一亿参数量的超大Transformer。欢迎感兴趣的旭友们点击注册地平线开发者社区交流讨论,相关文档详见地平线开发者社区。
技术详解
Step-1:模型转换的环境准备
环境准备本身没有什么奇技淫巧,这里想重点描述的是:pytorch版本的升级对精度瓶颈和速度瓶颈分析所带来的跨越式的体验提升。
在地平线开发者社区官方提供的安装包中,为了兼容训练算法包海图(HAT),安装的 pytorch版本为1.10.0。pytorch版本本身对模型转换的精度不会有什么影响,但是不同版本的pytorch所导出的onnx,在节点(node, 或称op)命名上有很大的区别。
就一般情况而言,当torch版本为1.10.0时,Node的命名采用了“optype+数字”的形式,这种形式的缺点是:当模型 Layer/SubLayer数量非常多(比如本文一亿参数量的Transformer,包含的 OP 有上千个),我们很难一眼定位 Conv_xx 到底是第几层的第几个卷积。
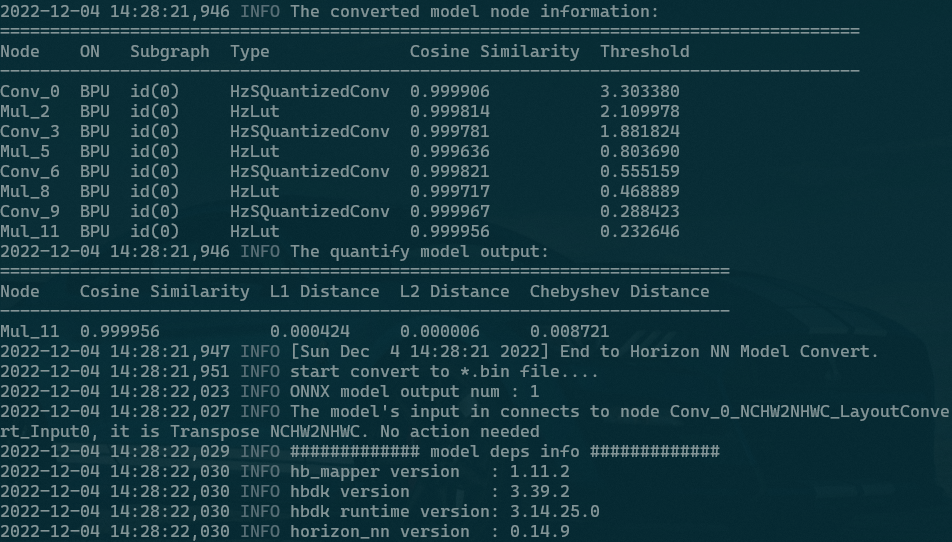
torch 1.10.0版本结果
通常一个量化明显掉点的模型,会从中间某一个OP开始有鲜明的Cosine Similarity损失,在当前的命名格式下,为了找到这个OP在原始模型中的位置(第x Layer的第y SubLayer),我们需要从头开始一个一个数,这无疑是效率低下的。当然,随着对模型细节的熟悉,定位的速度会越来越快,但这不能从根本上解决效率问题。
相反,当torch版本升级到1.13.0时Node的命名采用了“Layer+SubLayer+Attribute+OP”的形式,一眼定位,一眼丁真,大大节省了开发人员定位精度问题(哪层的OP相似度下降严重)or 速度问题(哪层的OP跑在CPU)的时间。
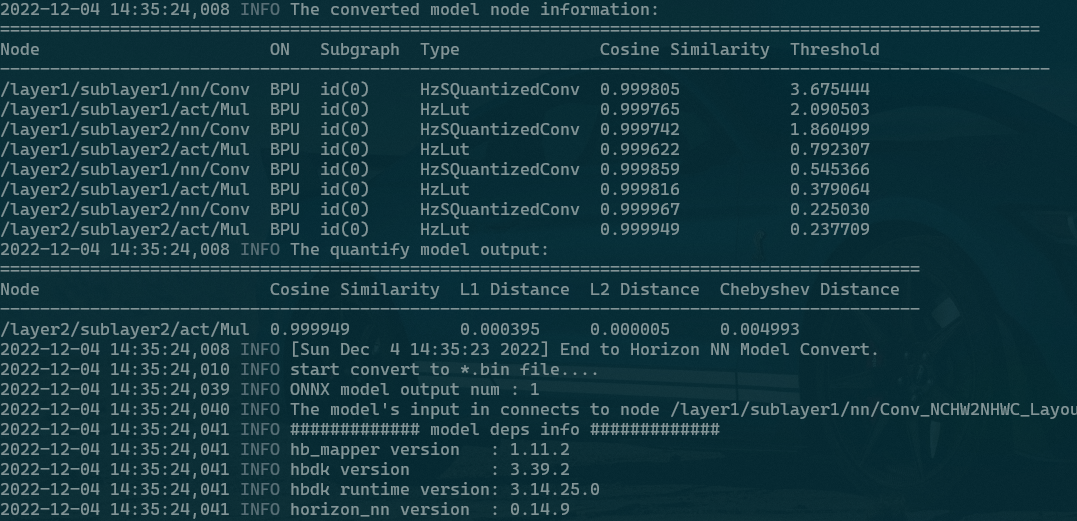
torch 1.13.0版本结果
Step-2:C++ Demo 的编译
由于X3派板端内存有限,编译C++ Demo时笔者采用了交叉编译的形式,在开发机上sudo安装aarch gcc即可。至于使用C++实现BPU模型的板上推理,实现推理的逻辑本身是一件很容易的事情,无论是使用python实现亦或是C++实现,其流程都是固定的,也即:

关于这四个步骤的API调用范例,官方 C++ 文档中都给出了比较详细的 know-how 示例,但是大多数都是单模型 + 单输入的简单case,在语音识别模型中,会涉及到 多模型(多个bin串联)+ 多输入(一个bin有多个输入)的情况,这里给出本文的针对性示例:
// BPUAsrModel 类定义 using hobot::easy_dnn::Model; using hobot::easy_dnn::DNNTensor; using hobot::easy_dnn::TaskManager; using hobot::easy_dnn::ModelManager; class BPUAsrModel : public AsrModel { public: BPUAsrModel() = default; ~BPUAsrModel(); BPUAsrModel(const BPUAsrModel& other); void Read(const std::string& model_dir); void PrepareEncoderInput(const std::vector>& chunk_feats); // 其他成员函数... protected: void ForwardEncoderFunc(const std::vector>& chunk_feats, std::vector>* ctc_prob) override; private: // models std::shared_ptr encoder_model_ = nullptr; std::shared_ptr ctc_model_ = nullptr; // input/output tensors, 使用vector方便应对单模型多输入的情况 std::vector> encoder_input_, encoder_output_; std::vector> ctc_input_, ctc_output_; // 其他成员变量... };
Step-3:正式开始模型转换
(一)一行代码 改写Transformer模型
使用工具链去转换NLP领域的原生Transformer模型,体验可能会是非常糟糕的(甚至会在转换过程中直接报错)。这是因为NLP中的Transformer,输入tensor的维度通常是二维或三维,类型既包含float也包含long 。而XJ3芯片在设计时只着重考虑了视觉任务,通常都是浮点的四维图像输入,工具链也只对这类视觉模型有比较极致的体验优化。
那么,为了转换NLP类的Transformer,我们是否需要重头训练一个四维数据流的模型呢?答案显然是否定的,本文通过等价替换和抽象封装,实现了一行代码将原生Transformer等价改写为BPU友好的Transformer:
# 一键完成 3D数据流 Transformer 等价转换 4D数据流 Transformer Encoder4D = wenet.bin.export_onnx_bpu.BPUTransformerEncoder(Encoder3D)
这里的BPU TransformerEncoder就像是科幻电影中的“外骨骼机甲”一样,其内核没变(权重参数值没变),但是功能上实现了针对性升级。具体而言,在 BPUTransformerEncoder 的构造过程中,会逐OP遍历原生的 Encoder3D,并对其中的 BPU 不友好的 OP 实施等价改写。
(二) 一句命令 走完转换全流程
一个完整pytorch模型到bpu模型的转换流程,一般要经过如下四步:
①pytorch 模型 转 onnx 模型;
②构造 Calibration 数据;
③构造 config.yaml;
④调用 hb_mapper 执行 onnx 转 bpu bin。
在WeNet开源的代码中,我们用人民群众喜闻乐见的python把这四个步骤 “粘” 到了一起,使用如下命令,就可走完全流程。
python3 $WENET_DIR/tools/onnx2horizonbin.py \ --config ./model_subsample8_parameter110M/train.yaml \ --checkpoint ./model_subsample8_parameter110M/final.pt \ --output_dir ./model_subsample8_parameter110M/sample50_chunk8_leftchunk16 \ --chunk_size 8 \ --num_decoding_left_chunks 16 \ --max_samples 50 \ --dict ./model_subsample8_parameter110M/units.txt \ --cali_datalist ./model_subsample8_parameter110M/calibration_data/data.list
其中:
config(描述了模型配置,几层layer等);
checkpoint(pytorch 浮点模型);
output_dir(.bin 文件输出目录);
chunk_size(跟识别有关的解码参数);
num_decoding_left_chunks(跟识别有关的解码参数);
max_samples(使用多少句数据制作calibration data);
dict(字典);
cali_datalist(描述了标定数据的位置)。
综上,我们对如下这四个步骤实现了完完全全的 python化封装 和 一体化串联 ,真正实现了一句命令(python3 $WENET_DIR/tools/onnx2horizonbin.py ...)走完全部转换流程。
Demo展示
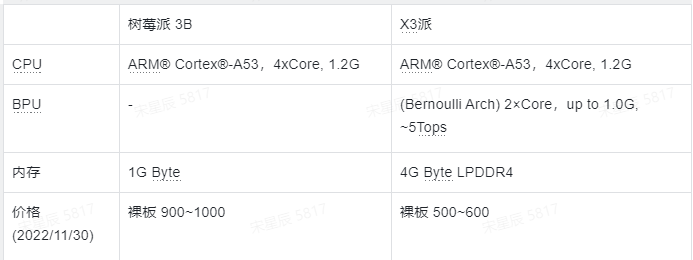
硬件配置:
模型配置:

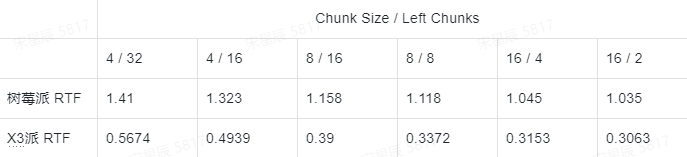
解码速度对比(单核单线程,量化后的模型):
本文转自地平线开发者社区
原作者:xcsong
- 相关推荐
- 热点推荐
- 嵌入式
- 语音识别
- 人工智能
- Transformer
-
离线语音识别及控制是怎样的技术?2023-11-24 2190
-
平平无奇纵享丝滑,旭日X3派高速网络新体验2023-02-21 1733
-
旭日X3派首百尝鲜 | 借助旭日X3派玩转智能家居2022-11-28 1513
-
旭日X3派更新最小启动固件2022-11-10 1898
-
旭日,从地平线升起——地平线旭日X3派开箱试用2022-11-08 3122
-
【地平线旭日X3派试用体验】X3派开箱及开发环境搭建2022-10-21 2217
-
【 地平线旭日X3派试用体验】地平线旭日X3派AGV智能车设计2022-09-12 5436
-
#旭日X3派首百尝鲜# 用solidworks画了一个旭日X3派的模型2022-08-31 25979
-
#旭日X3派首百尝鲜#旭日x3派移植mjpg-streamer2022-08-10 2380
-
#旭日X3派首百尝鲜# 【AI健身实体机】Arduino使用MAX30102人体心率血氧检测模块在X3派上位机上的显示2022-07-27 2348
-
地平线旭日X3派试用-玩转串口通信2022-07-22 2481
-
旭日X3派烧录最小启动固件2022-07-18 1760
-
【地平线旭日X3派试用体验】开箱+快速上手体验2022-07-17 3790
-
【语音识别】你知道什么是离线语音识别和在线语音识别吗?2021-04-01 7136
全部0条评论

快来发表一下你的评论吧 !
