

分区存储助力QLC应用到嵌入式存储设备
描述
目前应用在移动终端的嵌入式存储设备(这里主要指UFS/eMMC等,以下统称“嵌入式存储设备”)中主流介质还是TLC。但更高存储密度的QLC也已经产品化,比如一些数据中心(读密集型应用)已经在部署QLC存储设备。QLC可以给存储设备带来更低的成本,作为消费级产品的嵌入式存储设备,未来引入QLC也是势在必行。
但和当前主流TLC相比,QLC在性能和寿命上都相差很大,从下面某原厂TLC和QLC在性能和寿命方面的一个对比可见一斑。
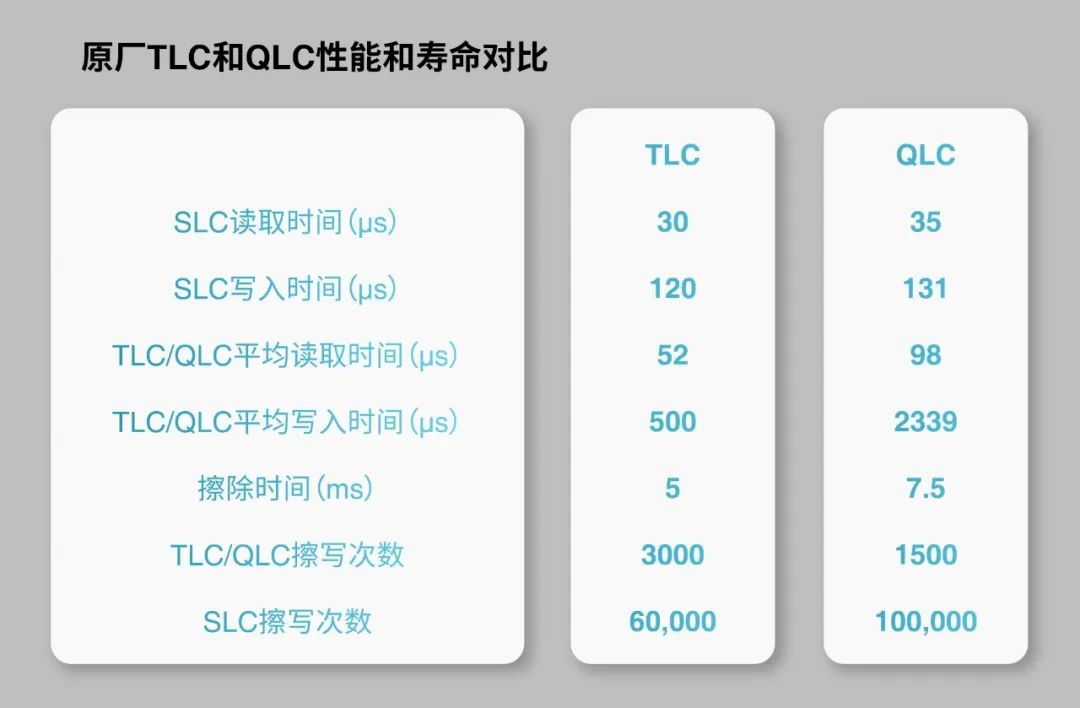
(Table 1:某原厂TLC和QLC性能和寿命对比)
因此,QLC要应用在嵌入式存储设备上,首先需要解决性能差和寿命短两大问题。
虽然QLC还不到TLC的1/4写入性能,但目前消费级固态存储产品都有成熟的SLC cache机制,能保证用户有比较好的突发写入性能(写SLC的性能)。由于嵌入式存储设备有比较充裕的空闲时间,存储设备可以利用空闲时间把数据从SLC搬到QLC,只要不是重度写入场景,这部分QLC写入性能,用户一般感知不到。
但数据一旦写到QLC,对比TLC,用户读取性能变差。针对这个读取性能差的问题,有一种方案是把热数据(经常读取)写回SLC,但这样无疑增加了设备复杂性,而且数据搬移带来了额外的写放大,这让寿命本来就不长的QLC“雪上加霜”。
如果说性能问题可以通过SLC解决或者缓解,那对于QLC寿命问题,在分区存储引入之前,可能的解决方案有:用户端使用类F2FS文件系统和使用数据分流。
F2FS文件系统化随机写为顺序写,这会减少存储设备内部垃圾回收导致的写放大,但F2FS文件系统本身的垃圾回收,会给存储设备带来额外的写。综合下来,F2FS文件系统给设备带来的写放大不一定减少。
数据分流需要主机和设备配合:主机端对数据进行冷热甄别,设备端根据数据的冷热程度把它们存储在不同的闪存块上。数据分流能一定程度上减少存储设备写放大,但具体能带来多大收益,这取决于用户冷热数据的比例,因此有一定的局限性。
今天要介绍减小写放大的终极大招——分区存储(Zoned Storage),它能消除QLC和TLC寿命之间的差异,而且能提升存储设备性能,让QLC应用到嵌入式存储设备上变得可能。
什么是分区存储?
分区存储概念最早来源于SMR HDD。SMR是“Shingled Magnetic Recording”(叠瓦式磁记录)的首字母缩写,是一种用于增加容量并降低硬盘每TB成本的重要技术。SMR硬盘把硬盘分成一个个的分区(Zone),每个分区内部必须顺序写,否则会发生数据覆盖从而导致之前写入的数据丢失问题。
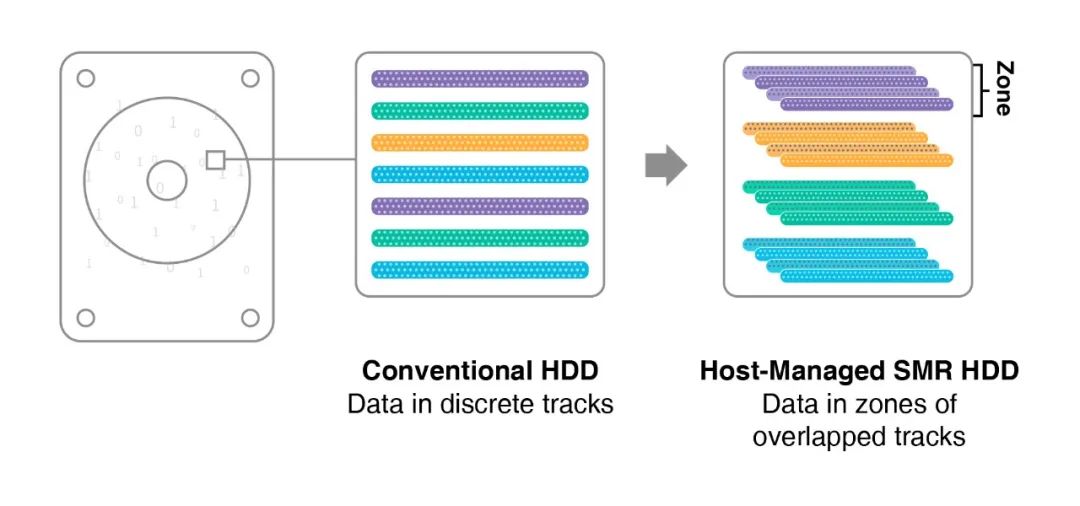
(Figure 1:SMR HDD)
分区存储设备的逻辑空间被划分成一个个连续的分区,分区内部只能被顺序写入。每个分区都有一个写指针,用于跟踪下一次写入的位置。分区中的数据不能被覆盖,必须首先使用特殊命令(区域重置)擦除数据。
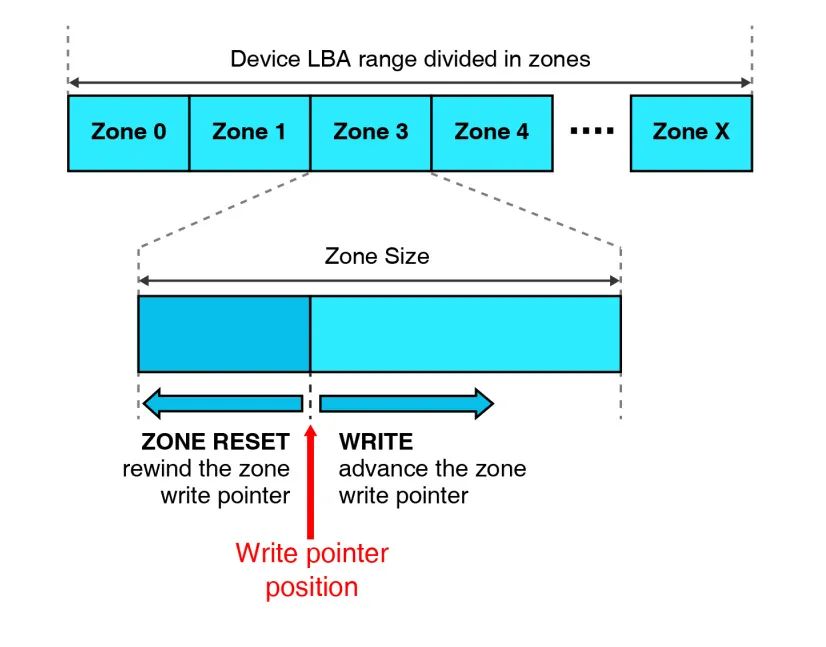
(Figure 2:分区存储概念)
除了HDD,基于闪存的固态存储设备,也是非常喜欢顺序写入的,因为顺序写性能好,而且导致的写放大也小。“让主机端顺序写入”一直是固态存储设备的梦想,在SMR HDD助力下,分区存储生态日趋完善,NVMe也制定了ZNS(Zoned Namespace)标准,SSD也算是“圆梦”了。
分区存储带来的好处
分区存储带来的一大好处就是能消除存储设备内部的垃圾回收。存储设备垃圾回收会导致两个主要问题:一是引入写放大,导致存储设备寿命减少;二是垃圾回收的同时如果伴有主机读写,垃圾回收操作则会影响主机读写性能。
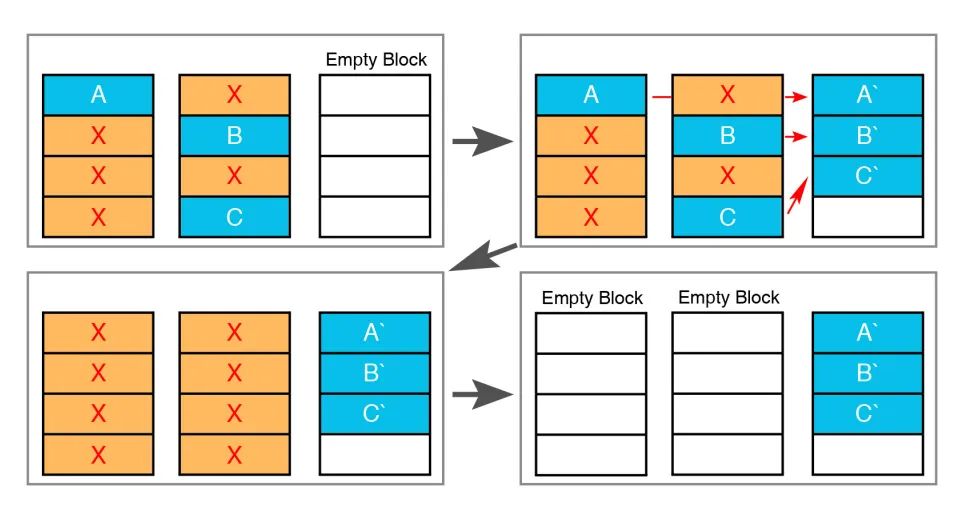
(Figure 3:垃圾回收示例)
垃圾回收原理:为腾出空闲闪存块,需要把有效数据A、B、C从源闪存数据块搬到新的闪存块,内部数据的搬移引入写放大。写放大 = 写入闪存的数据量/主机写入的数据量,写放大越大,对闪存磨损越厉害。
分区存储怎么就能消除存储设备垃圾回收的呢?
如果分区大小是存储设备闪存块大小的整数倍,这样一个分区的数据会被写到闪存设备的整数个闪存块内。由于分区不允许覆盖写,一个分区数据只能被整体无效掉,也就是意味着该分区对应的闪存块也是整体被无效掉(上面没有任何有效数据),因此存储设备内部回收闪存块无需垃圾回收——只需要一个擦除动作。
传统垃圾回收由于需要搬移闪存块上的有效数据,会导致写放大。还有,为减小写放大和加速垃圾回收,存储设备都会预留一些闪存空间(也就是我们常说的OP),以减少闪存块上有效数据数量。现在分区存储设备中由于不存在垃圾回收,因此没有写放大,同时这部分OP也可以省掉了(节省成本)。
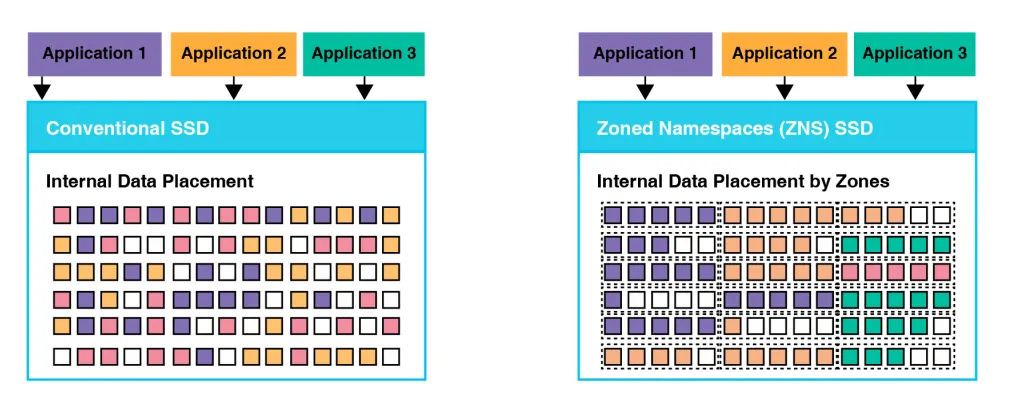
(Figure 4:传统SSD数据存放和分区SSD数据存放比较)
分区存储带来的另一大好处就是大大减少了映射表大小,从而提升系统性能,减少存储设备成本。
基于闪存的传统存储设备一般按4KB逻辑块大小为映射粒度,其L2P映射表(逻辑地址到物理地址的映射)大小一般为存储设备容量的1/1024,比如一个512GB的UFS设备,其L2P映射表大小为512MB。企业级SSD一般都配有相应大小的DRAM来存储运行时的L2P映射表,比如512GB的企业级SSD需要搭载至少512MB的DRAM;而业界消费级存储设备则是出于成本考虑,一般都没有DRAM,它利用控制器小的SRAM缓存部分L2P映射表,而绝大多数L2P映射表都是存在闪存,固件按需从闪存加载映射关系数据到控制器SRAM。这种DRAM-less的存储设备,与带DRAM的存储设备相比,少了DRAM的成本,但性能无疑会大打折扣,因为控制器SRAM大小有限,对随机读取场景来说,映射表缓存命中率很低,固件很多时候需要先从闪存加载映射关系,然后再根据获得的物理地址去读用户数据,也就是说读取一笔数据需要访问几次闪存,意味着读取性能肯定比只访问一次闪存要慢得多。
问题的根因是传统存储设备映射粒度太细了,导致映射表巨大。而分区存储设备,我们可以按照分区大小为映射粒度。假设分区大小为128MB,一个512GB的设备有4096个分区,每个分区对应的物理地址用4字节表示,那么整个L2P映射表只有16KB!这么小的映射表完全可以存储在控制器SRAM中,因此在企业级SSD中可节省DRAM的使用;对消费级存储产品来说,L2P映射表可以常驻内存,无需从闪存中获取映射关系,读取一笔数据只需访问一次闪存,这大大加速了随机读取性能。

(Table 2:传统存储设备和分区存储设备映射对比)
分区存储助力QLC嵌入式存储设备
回到QLC应用到嵌入式存储设备的话题。
在传统嵌入式存储设备中,垃圾回收一般会引入3-4的写放大,即一个3000次擦写次数的TLC闪存,真正给到用户的擦写次数可能不到1000次。而分区存储的使用,由于不存在垃圾回收,因此写放大可以做到接近1,也就是一个1500次擦写次数的QLC,给到用户就是实打实的1500次。这意味着:传统用3000次擦写次数TLC的存储设备,假设TBW为100TB,现在如果用QLC,虽然QLC的擦写次数只有TLC的一半,但由于分区存储的使用,TBW反而能提升到150TB。
对分区存储设备,由于L2P映射表很小,完全能够存放在控制器SRAM,因此可快速更新和获取映射关系,从而大幅提升系统读写性能。传统基于TLC的嵌入式存储设备,在随机读取一笔数据(4KB)的时候,由于L2P映射缓存很小(几百KB),固件大概率要先从闪存上加载L2P映射关系,这个时间大概40us左右,然后再花60us左右的时间从闪存加载用户数据——随机读取一笔数据的时间大概需要花100us左右;而现在基于分区存储的嵌入式存储设备,由于省掉了加载映射关系的时间,虽然读取闪存的时间QLC要比TLC长,但总的时间下来,两者是相当的。
由于分区存储设备的使用,再加上成熟的SLC缓存机制,这两大特性弥补了QLC寿命短和性能差两大短板,让QLC应用到嵌入式存储设备上变得可行。现在典型的嵌入式存储设备为UFS设备,如果引入了分区存储,像UFS中的HPB、FBO等特性完全可以抛弃,这也无疑简化了UFS设备的设计。
嵌入式存储设备技术展望
前端接口协议方面,应用于安卓平台上的嵌入式存储设备当前主流是UFS设备,相信未来很长一段时间也会沿着UFS路线继续向前。UFS4.0协议今年8月份发布,三星早前也发布了UFS4.0存储设备。

(Figure 5:嵌入式存储协议发展路线)
存储介质方面,作为消费级产品,嵌入式存储设备对成本敏感,随着QLC闪存的成熟,QLC必然会应用到未来的嵌入式存储设备上,无论是厂商还是消费者,都要做好这个心理准备。事实上,今年(2022年)年初铠侠已经发布了基于QLC的UFS3.1产品。
QLC应用到嵌入式存储设备上,要让消费者用得放心,这需要相关的技术来解决QLC介质可靠性差、寿命短、性能差等问题。因此在技术趋势方面,一方面是嵌入式存储控制器纠错能力需要变得越来越强;另一方面,像数据分流、分区存储这些能减小写放大的技术也会被引入,来弥补QLC寿命短这块短板。
目前,江波龙具有基于主流3D TLC闪存的丰富的嵌入式存储产品,从eMMC到高性能UFS3.1,从消费级存储到车规级存储,产品矩阵全面。同时,公司也在思考怎么把存储密度更高的QLC应用到嵌入式存储产品上,并开展相关技术预研工作。未来,江波龙会持续给客户带来更多超越期望的嵌入式存储产品。
-
姑苏秋叙 共话QLC:江波龙携手Solidigm共探嵌入式存储新蓝海2025-10-31 1556
-
嵌入式系统存储的软件优化策略2025-02-28 1756
-
EVASH Ultra EEPROM:助力ChatGPT等AI应用的嵌入式存储解决方案2024-06-26 1842
-
分区存储助力QLC应用到嵌入式存储设备2023-02-14 1267
-
谈一谈嵌入式设备的压缩存储算法2021-12-21 1008
-
嵌入式硬件系统与存储体系2021-12-17 1023
-
嵌入式系统是怎样应用到企业中去的?2021-04-27 1552
-
嵌入式存储产品有什么特点2019-09-12 1654
-
基于嵌入式主机上的USB海量存储设备类2017-10-31 803
-
嵌入式主机上的USB海量存储设备类2012-03-06 1020
-
国产嵌入式存储新技术助力终端发展2011-08-16 952
-
浅析嵌入式存储系统设计方法2010-01-26 1422
-
基于虚拟存储的嵌入式存储系统的设计方法2009-11-05 1056
全部0条评论

快来发表一下你的评论吧 !
