

神经网络初学者的激活函数指南
描述
作者:Mouâad B.
来源:DeepHub IMBA
如果你刚刚开始学习神经网络,激活函数的原理一开始可能很难理解。但是如果你想开发强大的神经网络,理解它们是很重要的。
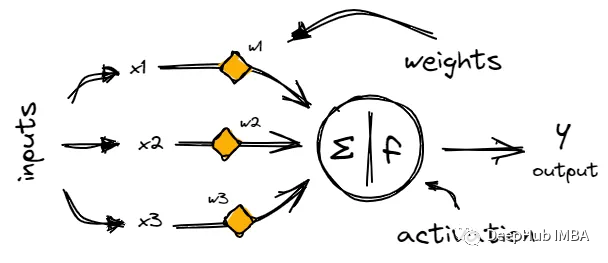
但在我们深入研究激活函数之前,先快速回顾一下神经网络架构的基本元素。如果你已经熟悉神经网络的工作原理,可以直接跳到下一节。
神经网络架构
神经网络由称为神经元的链接节点层组成,神经元通过称为突触的加权连接来处理和传输信息。
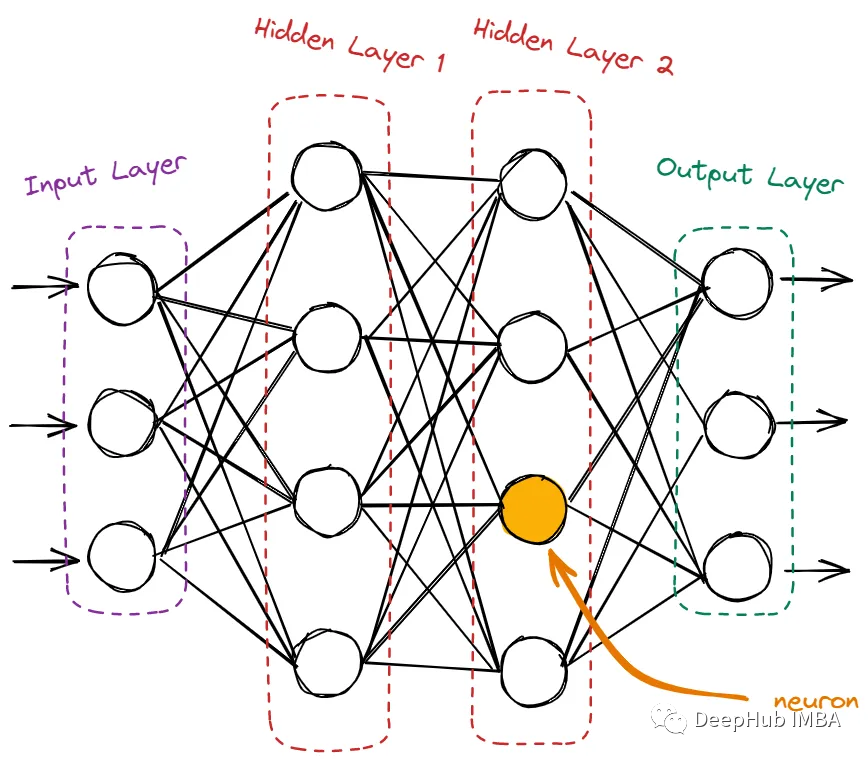
每个神经元从上一层的神经元获取输入,对其输入的和应用激活函数,然后将输出传递给下一层。
神经网络的神经元包含输入层、隐藏层和输出层。
输入层只接收来自域的原始数据。这里没有计算,节点只是简单地将信息(也称为特征)传递给下一层,即隐藏层。隐藏层是所有计算发生的地方。它从输入层获取特征,并在将结果传递给输出层之前对它们进行各种计算。输出层是网络的最后一层。它使用从隐藏层获得的所有信息并产生最终值。
为什么需要激活函数。为什么神经元不能直接计算并将结果转移到下一个神经元?激活函数的意义是什么?
激活函数在神经网络中的作用
网络中的每个神经元接收来自其他神经元的输入,然后它对输入进行一些数学运算以生成输出。一个神经元的输出可以被用作网络中其他神经元的输入。
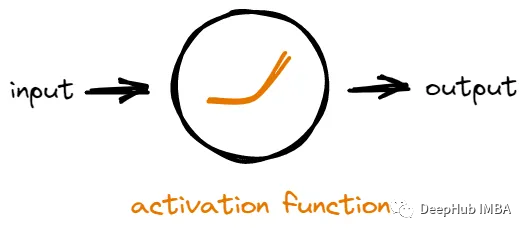
如果没有激活函数,神经元将只是对输入进行线性数学运算。这意味着无论我们在网络中添加多少层神经元,它所能学习的东西仍然是有限的,因为输出总是输入的简单线性组合。
激活函数通过在网络中引入非线性来解决问题。通过添加非线性,网络可以模拟输入和输出之间更复杂的关系,从而发现更多有价值的模式。
简而言之,激活函数通过引入非线性并允许神经网络学习复杂的模式,使神经网络更加强大。
理解不同类型的激活函数
我们可以将这些函数分为三部分:二元、线性和非线性。
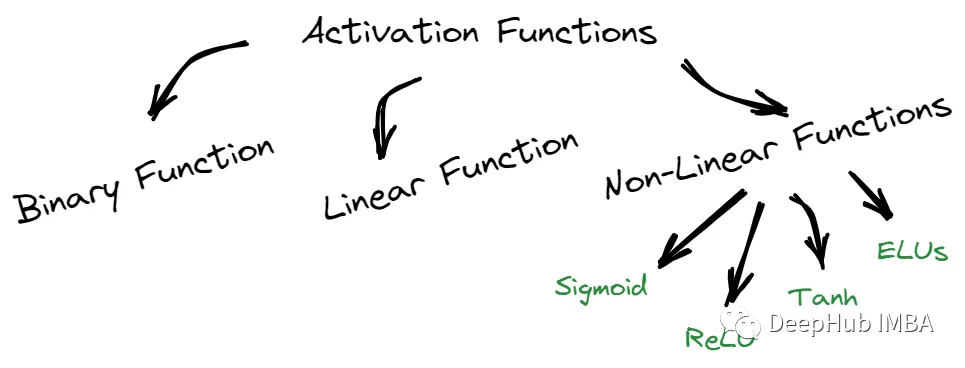
二元函数只能输出两个可能值中的一个,而线性函数则返回基于线性方程的值。
非线性函数,如sigmoid函数,Tanh, ReLU和elu,提供的结果与输入不成比例。每种类型的激活函数都有其独特的特征,可以在不同的场景中使用。
1、Sigmoid / Logistic激活函数
Sigmoid激活函数接受任何数字作为输入,并给出0到1之间的输出。输入越正,输出越接近1。另一方面,输入越负,输出就越接近0,如下图所示。
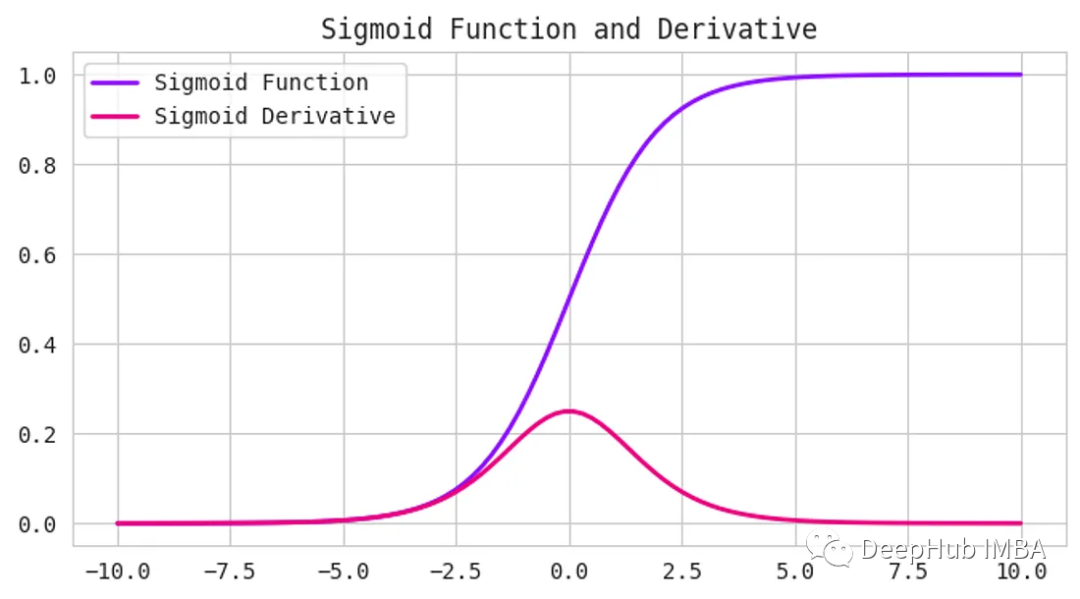
它具有s形曲线,使其成为二元分类问题的理想选择。如果要创建一个模型来预测一封电子邮件是否为垃圾邮件,我们可以使用Sigmoid函数来提供一个0到1之间的概率分数。如果得分超过0.5分,则认为该邮件是垃圾邮件。如果它小于0.5,那么我们可以说它不是垃圾邮件。
函数定义如下:

但是Sigmoid函数有一个缺点——它受到梯度消失问题的困扰。当输入变得越来越大或越来越小时,函数的梯度变得非常小,减慢了深度神经网络的学习过程,可以看上面图中的导数(Derivative)曲线。
但是Sigmoid函数仍然在某些类型的神经网络中使用,例如用于二进制分类问题的神经网络,或者用于多类分类问题的输出层,因为预测每个类的概率Sigmoid还是最好的解决办法。
2、Tanh函数(双曲正切)
Tanh函数,也被称为双曲正切函数,是神经网络中使用的另一种激活函数。它接受任何实数作为输入,并输出一个介于-1到1之间的值。
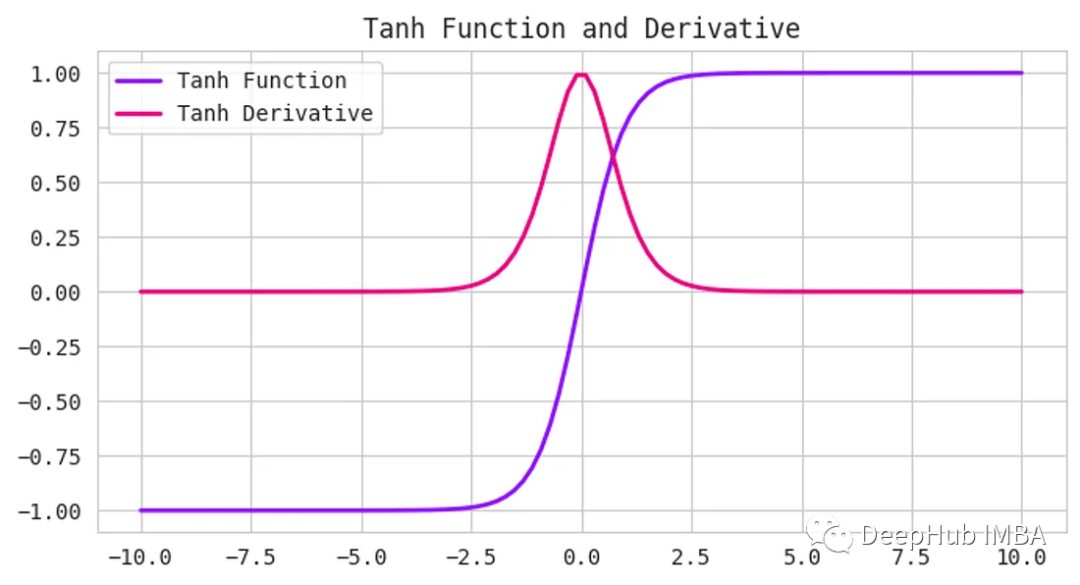
Tanh函数和Sigmoid函数很相似,但它更以0为中心。当输入接近于零时,输出也将接近于零。这在处理同时具有负值和正值的数据时非常有用,因为它可以帮助网络更好地学习。
函数定义如下:
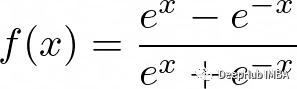
与Sigmoid函数一样,Tanh函数也会在输入变得非常大或非常小时遭遇梯度消失的问题。
3、线性整流单元/ ReLU函数
ReLU是一种常见的激活函数,它既简单又强大。它接受任何输入值,如果为正则返回,如果为负则返回0。换句话说,ReLU将所有负值设置为0,并保留所有正值。
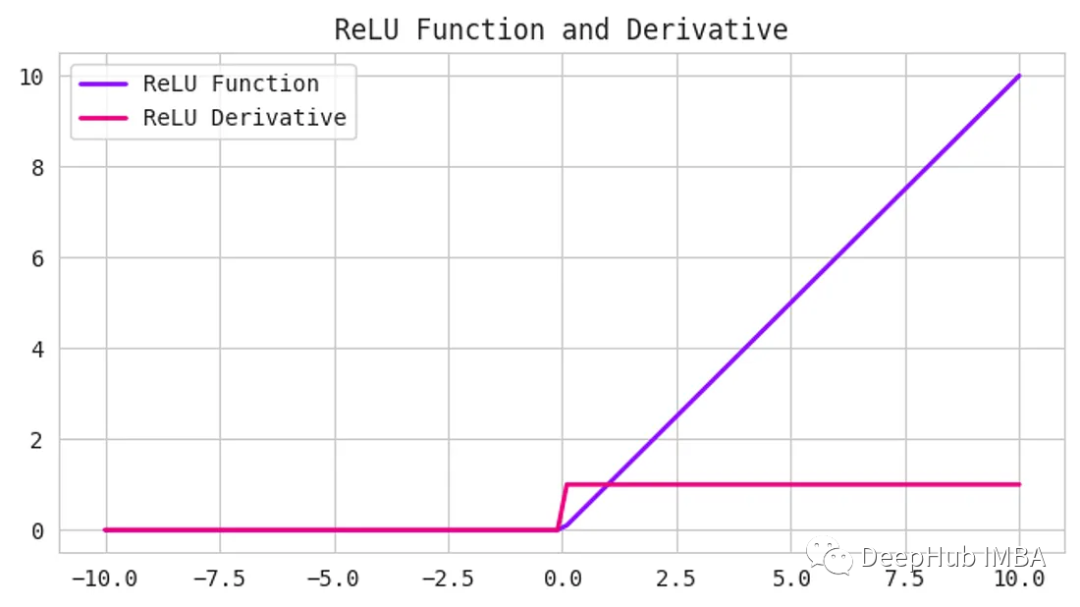
函数定义如下:
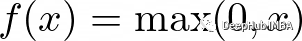
使用ReLU的好处之一是计算效率高,并且实现简单。它可以帮助缓解深度神经网络中可能出现的梯度消失问题。
但是,ReLU可能会遇到一个被称为“dying ReLU”问题。当神经元的输入为负,导致神经元的输出为0时,就会发生这种情况。如果这种情况发生得太频繁,神经元就会“死亡”并停止学习。
4、Leaky ReLU
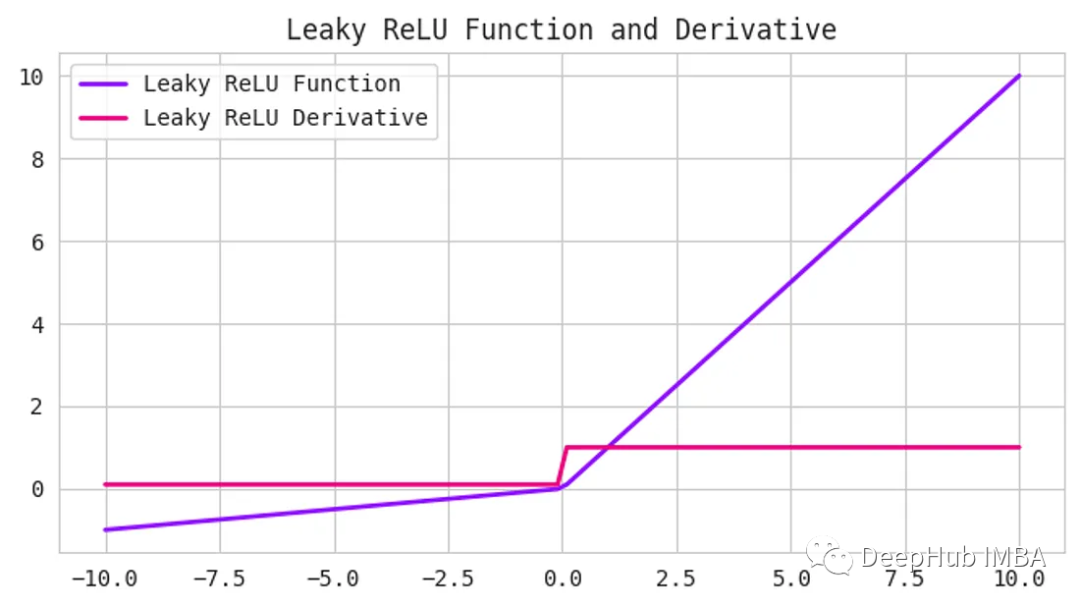
Leaky ReLU函数是ReLU函数的一个扩展,它试图解决“dying ReLU”问题。Leaky ReLU不是将所有的负值都设置为0,而是将它们设置为一个小的正值,比如输入值的0.1倍。他保证即使神经元接收到负信息,它仍然可以从中学习。
函数定义如下:
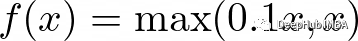
Leaky ReLU已被证明在许多不同类型的问题中工作良好。
5、指数线性单位(elu)函数
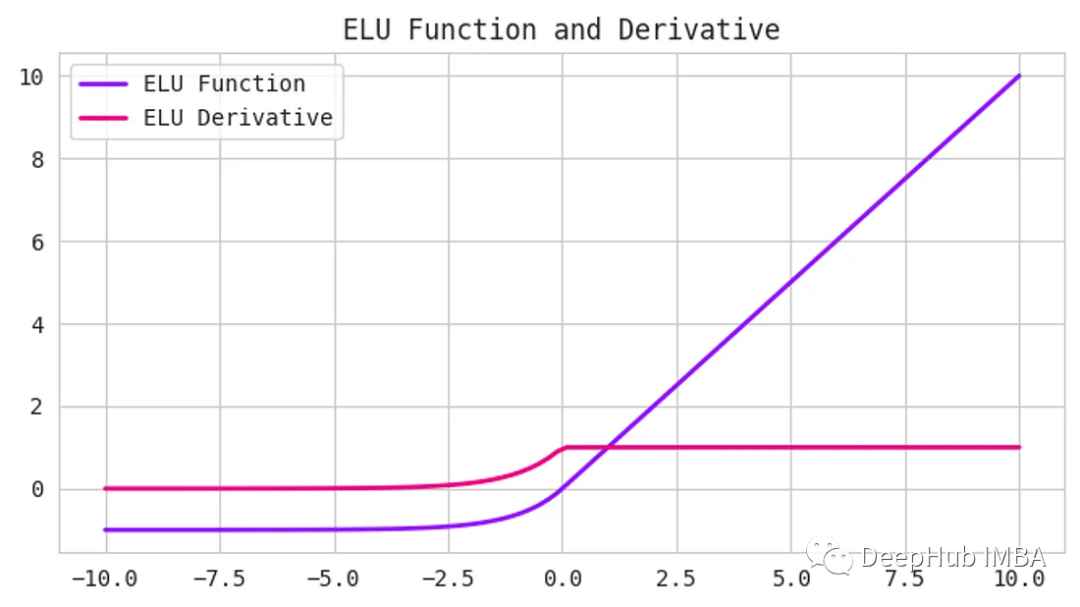
ReLU一样,他们的目标是解决梯度消失的问题。elu引入了负输入的非零斜率,这有助于防止“dying ReLU”问题
公式为:
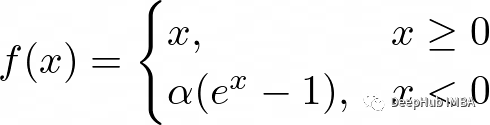
这里的alpha是控制负饱和度的超参数。
与ReLU和tanh等其他激活函数相比,elu已被证明可以提高训练和测试的准确性。它在需要高准确度的深度神经网络中特别有用。
6、Softmax函数
在需要对输入进行多类别分类的神经网络中,softmax函数通常用作输出层的激活函数。它以一个实数向量作为输入,并返回一个表示每个类别可能性的概率分布。
softmax的公式是:
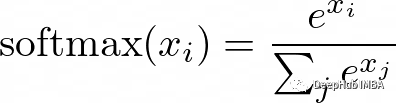
这里的x是输入向量,i和j是从1到类别数的索引。
Softmax对于多类分类问题非常有用,因为它确保输出概率之和为1,从而便于解释结果。它也是可微的,这使得它可以在训练过程中用于反向传播。
7、Swish
Swish函数是一个相对较新的激活函数,由于其优于ReLU等其他激活函数的性能,在深度学习社区中受到了关注。
Swish的公式是:
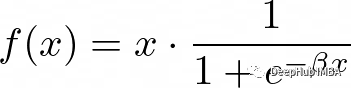
这里的beta是控制饱和度的超参数。
Swish类似于ReLU,因为它是一个可以有效计算的简单函数。并且有一个平滑的曲线,有助于预防“dying ReLU”问题。Swish已被证明在各种深度学习任务上优于ReLU。
选择哪一种?
首先,需要将激活函数与你要解决的预测问题类型相匹配。可以从ReLU激活函数开始,如果没有达到预期的结果,则可以转向其他激活函数。
以下是一些需要原则:
- ReLU激活函数只能在隐藏层中使用。
- Sigmoid/Logistic和Tanh函数不应该用于隐藏层,因为它们会在训练过程中引起问题。
Swish函数用于深度大于40层的神经网络会好很多。
输出层的激活函数是由你要解决的预测问题的类型决定的。以下是一些需要记住的基本原则:
回归-线性激活函数
二元分类- Sigmoid
多类分类- Softmax
- 多标签分类- Sigmoid
选择正确的激活函数可以使预测准确性有所不同。所以还需要根据不同的使用情况进行测试。
-
前馈神经网络的基本结构和常见激活函数2024-07-09 2938
-
卷积神经网络激活函数的作用2024-07-03 3081
-
神经网络中激活函数的定义及类型2024-07-02 2235
-
神经网络中的激活函数有哪些2024-07-01 2057
-
神经网络初学者的激活函数指南2023-04-18 1174
-
微伺服初学者指南2022-11-04 803
-
SBC 基础课程——CAN/LIN SBC初学者指南2022-11-01 1289
-
图文详解:神经网络的激活函数2020-07-05 4670
-
循环神经网络(RNN)和(LSTM)初学者指南2019-02-05 1425
-
MATLAB、Torch和TensorFlow对比分析_初学者如何选择2018-06-29 11997
-
R语言初学者指南 pdf下载2018-02-26 1961
-
ReLU到Sinc的26种神经网络激活函数可视化大盘点2018-01-11 33225
-
初学者必读:卷积神经网络指南(一)2017-11-16 1990
-
电子初学者电路图如何看2015-11-23 1489
全部0条评论

快来发表一下你的评论吧 !
