

微博服务器为什么会宕机?这几年为什么极少再宕机了?
描述
大家有没有发现一个事情,相比六七年前微博动辄因为各路明星的新闻忽告宕机,近几年微博宕机的次数已经越来越少了。
自从各路明星大料不断让新浪服务器时常处在崩溃的边缘后,不少吃瓜群众将明星的咖位与微博服务器进行挂靠:如果某明星传出出轨/结婚/离婚等大事后,微博不会崩,那证明这个明星影响力不够。
为什么新浪的服务器老是崩掉呢?国外也有这种情况吗?
新浪服务器遇到明星的大爆料会崩溃就相当于国庆节上高速,访问量激增后大家一起挤在路上,服务器处理不过来,就会表现为部分业务请求无效,或是整个瘫痪,也就是所谓的宕机现象。
其实服务器崩溃的事件并不罕见,国外的网站也会出现这种问题,例如前几年YouTube出现全球范围内宕机事故,YouTube、YouTubeTV和YouTube music都被波及,大约半小时才恢复。除了爆发的访问量,引起网络瘫痪的原因也可能是物理性的,比如微软数据中心被雷击中,其云服务大面积出现网络连接问题;韩国KT电信突遭大火,整个首尔几乎全面网络瘫痪等。
究竟什么是宕机?引发宕机的原因又是什么?
实际上,宕机是IT行业术语,宕为英文down的音译。所谓宕机,是指网络空间的信息系统无法提供正常服务,出现卡顿甚至“停摆”现象,用户的直接体验就是系统长时间无响应,比如无法正常访问、搜索无响应、无法发帖等。
造成系统宕机的因素有很多,比如机房供电故障、服务器硬件崩溃、系统处理能力不足、遭受网络攻击等。由于突发热点事件引发的微博服务器宕机事件,通常是由于瞬间访问量暴增,导致后台服务器不堪重负,只好“一宕了之”。资料显示,微博系统服务器的访问量上限被设计为预估平时流量的峰值,相关服务资源均依此配置。一旦突发事件导致访问量超出此峰值,系统将无法承受,宕机也就在所难免。
微博宕机是不是因为存在什么技术问题?
其实单就技术层面来说,预防微博服务器宕机不存在太大问题,只要扩充容量即可。而微博服务器宕机事件频发,原因主要有两方面:
一是微博服务器部署规模及其处理能力受限。很多公共服务平台的平时流量基本稳定,基于成本考虑,在保持适度冗余处理能力的前提下,微博运营商不会主动去租用或配置大量超出日常数据处理需求的计算和存储资源。服务器扩容多了,如果没有流量支撑,就会造成资源闲置及成本增加。这为微博省去了大量的成本,毕竟平时如果征用这么多服务器,也都基本处于闲置状态,实在过于浪费。根据阿里云官微之前的价格公布,一台机器租用1小时只要1.86元(事实上这只是华北3区一台低配版机器的价格)。即便仅按这个最低配的价格来算,每天使用1台机器将产生45元钱左右的费用,1000台需要45000元,一个月需要135万元,一年需要1620万元成本。
另一方面,微博流量具有瞬间峰值高、持续时间短的特征,在热点事件出现时表现得更明显。微博热点流量较难预测,使得微博运营商在扩容问题上陷入两难境地:扩容多了易亏,扩容不足易挂。
目前预防服务器宕机的解决办法,新浪给出的做法是扩容。但是扩容有个最大难题是:新闻事件是随机的,明星们可不会专门挑时间让你准备好服务器再出事。所以对新闻影响力的预估就很考验平台的判断力,比如错误地预估了某个明星的事情能够带来的震荡程度就会带来另外一个问题——临时花了很高成本购买的的服务器成本搭进去了,又没带来那么大的流量,不仅拿不到到预计的收益还赔了服务器的高昂成本。
新浪这么大一个企业备几台闲置的服务器难道备不起吗?
新浪作为一个大公司,买得起是肯定买得起的,不过现在服务器基本上是按需收费、按时收费的,一天花的钱还好,一年的钱可就是个大数目了。新浪作为一个企业,首要目的肯定还是盈利。如果是直接购置硬件的话,高并发时可能需要上千台服务器才能处理,而平时的访问量已有的服务器就可以解决,导致新置的服务器绝大多数时间只能闲置,这是巨大的资源浪费。所以一般来说新浪也是有需要才会临时加购服务器。对于新浪来说最为可靠的解决办法就是:运维和程序员随时准备加班;或者和明星团队通好气,让他们在爆料之前先跟新浪联系。
如果加购选项不成立,那么能做到预测峰值流量吗?
热点流量虽较难以预测,但不等于不可预测。只要能预估出流量峰值范围,就可通过定时扩容和提供弹性计算存储资源来从容应对。很多平台在这方面都有过应对流量突增的成功案例,比如电商平台应对“双十一”时的峰值流量。明星离婚等网络突发事件,虽不受微博运营商控制,但微博运营商应该可通过舆情监控等手段感知即将到来的流量大潮,通过启动应急预案来应对。构建弹性伸缩业务系统,辅以人工智能预测和业务持续性监控,来保障峰值服务正常运行。比如,通过人工智能技术来预测网络突发流量,利用云计算弹性计算资源平台来实现快速扩容甚至实时扩容,以应对高峰流量。云提供商目前可在宕机后数秒内探测到服务不可连接,然后在90秒内实现扩容,恢复运行中断业务。这种按需部署的服务器配置方式,既可显著降低网络平台服务器宕机的风险,又能很好地利用存储计算资源,实现双赢。
同时微博还可采用“降级”运行策略,即将服务器的业务拆分为若干相对独立的业务,各业务之间共享数据库。一旦服务器出现过载,可启动降级策略来“丢卒保车”,至少保证核心业务能正常运行。比如,若微博热搜榜崩溃,可维持评论、转发等核心功能的正常运行。
另一种有效的应对方式是利用边缘计算技术,通过在网络边缘实现数据分布式本地处理,可显著降低访问数据的汇聚和传输总量,这不仅能缩短用户响应时间、提升用户体验,还能大幅降低中心节点的数据传输和处理压力,也是一条应对宕机的新路径。
“边缘计算”比较完美的解决了宕机难题
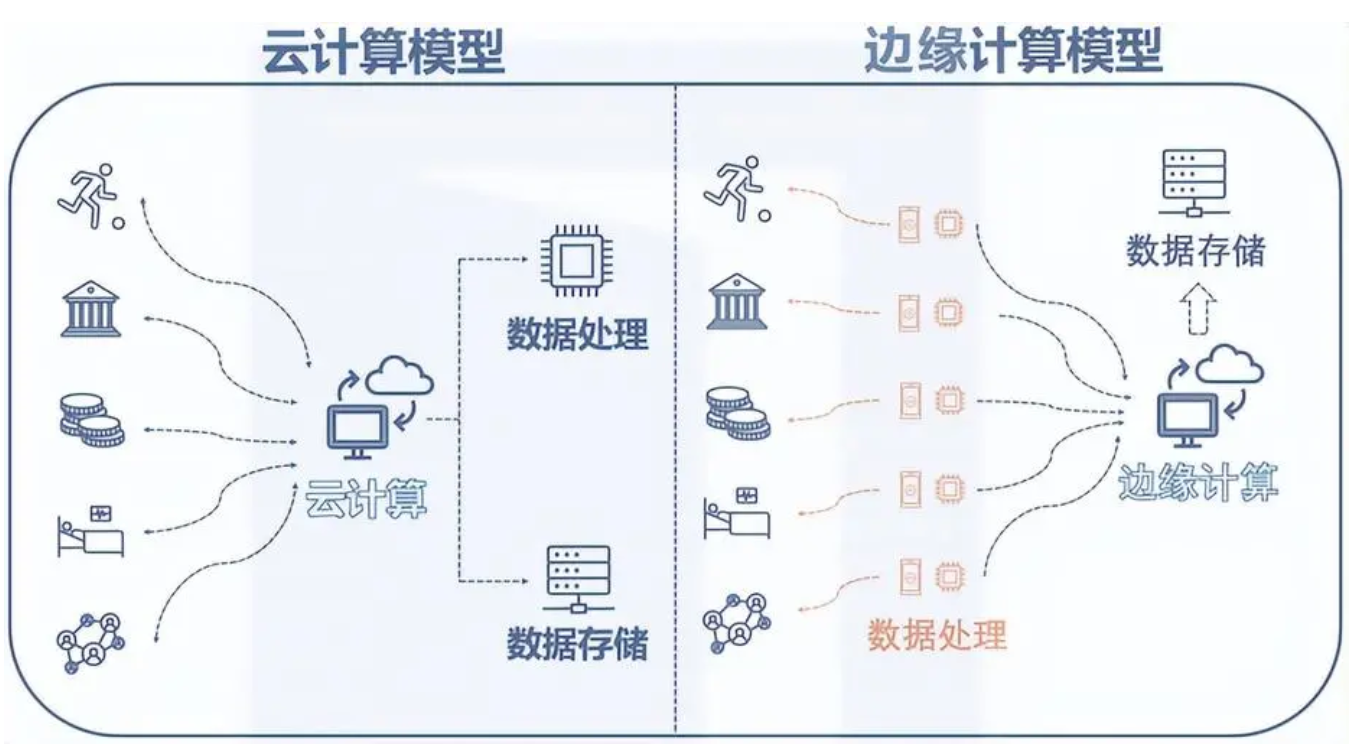
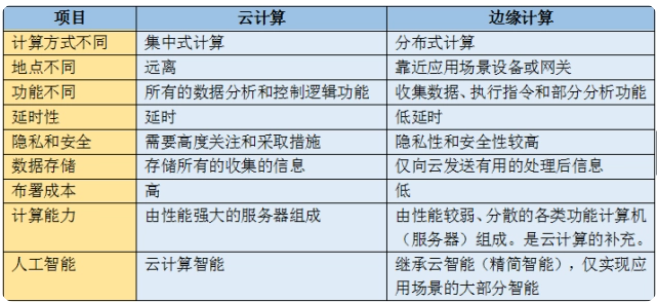
边缘计算是为应用开发者和服务提供商在网络的边缘侧提供云服务和IT环境服务;目标是在靠近数据输入或用户的地方提供计算、存储和网络带宽。边缘计算是一种分布式计算,将数据资料的处理、应用程序的运行和功能服务的实现,由网络中心下放到网络边缘的节点上。这样就可以把云打散,就近接入不同节点,提供最近端服务。把边缘计算和云计算紧密结合,充分发挥边缘的低延迟,安全等特性同时,结合云的大数据分析能力。
全国网民在同时访问微博时,可以就近访问不同的节点。各个节点之间有一定的处理能力,处理完再上报给集中节点,这就大大减少了数据的汇聚和传输量,同时就近节点的访问延迟也会缩短。此外,边缘计算支持数据本地处理,大流量业务本地卸载可以减轻回传压力,有效降低成本。
CDN巨头对于边缘计算的应用如何?
CDN(即内容分发网络)的核心价值是将数字内容智能分发到离用户更近的节点,进而提升整体分发效率,降低网络延时、节省带宽资源,其与生俱来的边缘节点属性,低延时和低带宽,令其在边缘计算市场具备先发优势,CDN本身就是边缘计算的雏形。
Akamai作为全球CDN领头羊早在2003年就与IBM合作边缘计算,如今Akamai与IBM在其WebSphere上提供基于边缘Edge的服务。网宿科技也已将边缘计算当成核心战略,2016年开始建设边缘计算网络,2017年逐步推出边缘计算微服务,并将逐步开放边缘IaaS和PaaS服务。CloudFlare公司在2017年就推出了CloudFlare Workers,以微服务的形式开放边缘计算服务,支持用户在边缘端编程,这标志着它已经初步搭建好了边缘计算的平台。阿里云/腾讯云也均在云计算和边缘计算上下了很大功夫,并且有非常成功的经验,比如上文所提的微博就是主要使用的阿里云服务器,正是因为阿里云的云计算和边缘计算技术不断进步和迭代,才保障了微博近年来宕机事件越来越少的成果。
目前火伞云已经建立了遍布全球的智能融合CDN网络,为客户提供集边缘计算、边缘存储、融合CDN及安全防护于一体的综合解决方案。公司旗下的火伞云融合CDN目前已融合多家头部CDN厂商:阿里云、腾讯云、网宿云、亚马逊云、谷歌云、白山云等,未来我们将不断融合更多更全的海内外知名厂商,为用户提供更多,更安全稳定的CDN节点服务。
-
OpenAI就ChatGPT宕机事件致歉2024-12-16 1503
-
服务器数据恢复—硬盘出现坏扇区导致网站服务器宕机的数据恢复案例2024-09-12 1046
-
TELNET拔网线输出信息较长时宕机求助?2023-04-27 1991
-
服务器“异常”的几个可能性预警请重视!2023-04-06 1399
-
服务器宕机出现的原因与解决办法2023-03-24 4282
-
修复 Windows VPS 服务器宕机的简单步骤2023-02-23 1598
-
Redis在服务器宕机时如何避免数据丢失呢?2023-02-12 1388
-
TELNET拔网线输出信息较长时宕机怎么解决2022-08-24 1513
-
服务器宕机重启原因分析与解决方案2022-07-10 4332
-
亚马逊云服务为何频繁发生宕机事故2021-12-14 4329
-
微博疑似服务器宕机 评论无法加载2021-01-19 2960
-
谷歌服务器再次全球宕机2020-12-15 3016
-
服务器出现宕机时的处理方式都有哪些2020-11-12 3821
-
服务器异常会出现那些可能性预警2020-06-02 1092
全部0条评论

快来发表一下你的评论吧 !
