

以太网时钟的PPM频率偏差的解决方案(下)
描述
4. 异步FIFO(先进先出)
图<6>是深度(depth)为8的异步FIFO的示意图。其中,0~7代表8个寄存器,他们组成了一个环。
绿色的外圈代表写操作,按照顺时针方向(地址递增),依次写入不同的寄存器;写完所有的寄存器,再从寄存器#0开始,循环不断;写指针(wrtie pointer)代表当前写入寄存器的地址;写操作是写时钟的同步电路。
橙色的内圈代表读操作,按照顺时钟方向(地址递增),依次读取不同的寄存器,读完所有8个寄存器,再从寄存器#0开始,循环不断;读指针(read pointer)代表当前读取寄存器的地址;写操作是读时钟的同步电路。
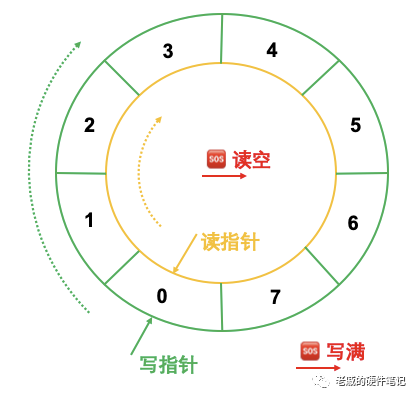
图<6>
对于特定寄存器,FIFO必然是先写后读;FIFO内部,读指针在不断追赶写指针。当写指针跑的太快,比如已经超越读指针一圈,这种状态就是写满(FIFO full),这时候继续写入就会把覆盖(overwrite)未被读取的寄存器(上溢,overflow),造成数据的丢失;另一种情况,读指针等于写指针,这种状态就是读空(FIFO empty),指向的寄存器还没有被写入,这时候继续读,读出来的是空的或者是上一个循环已经读取过的数据(下溢,underflow)。
写满(Full):读指针 = 写指针 + FIFO深度;
读空(Empty):读指针 = 写指针;
写满和读空是两种边界状态,更多情况下,FIFO处于写满和读空之间的中间状态。读指针和写指针之间的差值形成了水位图(watermark),代表着FIFO的实际使用率。
异步FIFO的实现有很多技术考量,最重要的是跨时钟域(CDC)问题:写指针和写满信号属于写时钟的时钟域;读指针和读空信号属于读时钟的时钟域。有很多文献讨论异步FIFO的实现细节,有兴趣的可以参考文献<1>。
异步FIFO的设计已然成熟,经过封装后成为异步FIFO模块(或者IP),比如图<7>。我们可以直接调用而不必顾虑内部的细节。

图<7>
图<7>中,左侧是写操作,右侧是读操作,读写操作工作在各自的时钟域,互不影响。只要没有写满信号,写操作就可以一直持续;只要没有读空信号,读操作也可以一直持续。数据源源不断从左侧流向右侧。
5. RX弹性缓存(Elastic Buffer)
在以太网的接收端,PCS层使用弹性缓存来补偿时钟的PPM频率差异。
10b编码经过异步FIFO,从RX时钟的时钟域转换到本地时钟域。
802.3标准没有提供异步FIFO的实现细节,老戚从Xilinx的用户手册找了一个1000Base-X设计例子做为参考。
这是一个深度为32的异步FIFO。计算读指针和写指针的差距,形成了图<8>的水位图。
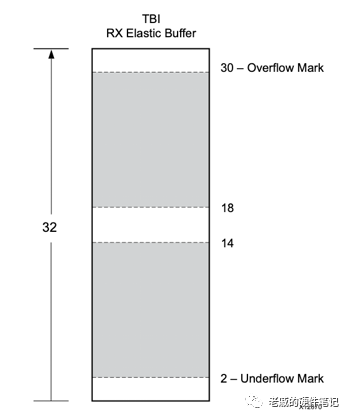
图<8>
当水位上升时,意味着FIFO读取的速度大于写入的速度;反之,则意味着FIFO读取的速度小于写入的速度。
上篇说到,PCS和PMA之间(TBI)的10b编码是连续的。读写时钟(本地时钟 VS RX时钟)的频率差异会导致水位或者上升到上溢,或者下降到下溢。
RX弹性缓存能够识别10b码型,然后根据水位来相应的插入或者删除特定的10b码型。
当水位上升到上半部灰色区间时,就删除IDLE码;
当水位下落到下半部灰色区间时,就插入IDLE码;
当水位处于中间区域时,既不删除也不插入。
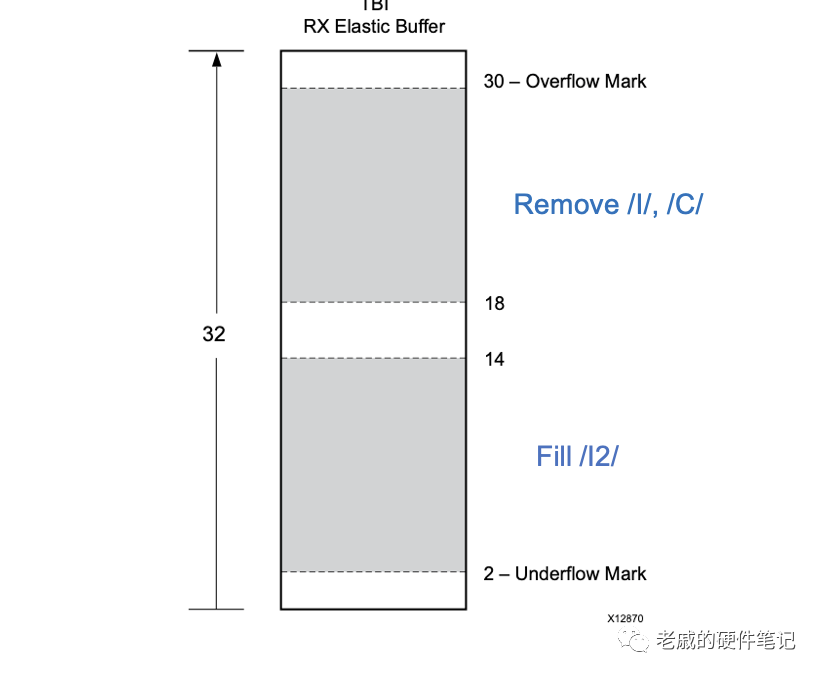
图<9>
MAC层的以太网帧之间的间隙(IPG)最小是12字节(Octets);而在PCS层,最小IPG转换成10b码型:/T/,/R/,5/I/*。(见上篇)
由于不能删除帧内数据,MAC帧越长,频差积累的影响就会越大。
假设RX时钟频率为正偏100PPM,本地时钟频率为负偏100PPM,考虑最长的Jumbo帧:
9216 Byte * (1.0001 / 0.9999 - 1) = 1.84 Byte
或者说,删除一个/I/(/I2/ = /K28.5/D16.2/)就足以补偿最大时钟PPM偏差。
如果RX的时钟慢于本地时钟,那么就需要插入IDLE码。
理想的水位是中间,比如16,这也意味着数据经过FIFO的时候会有16x 10b (128ns)的延时。
6. 为什么还会丢包?
RX时钟慢于本地时钟的情况下,在RX的10b数据中插入IDLE码,IPG变大,不会造成问题;反过来,会删除部分的/I/,结果可能导致以太网帧的IPG被削减到标准之下,虽然并不损失正常数据,但是在MAC层可能成为问题。
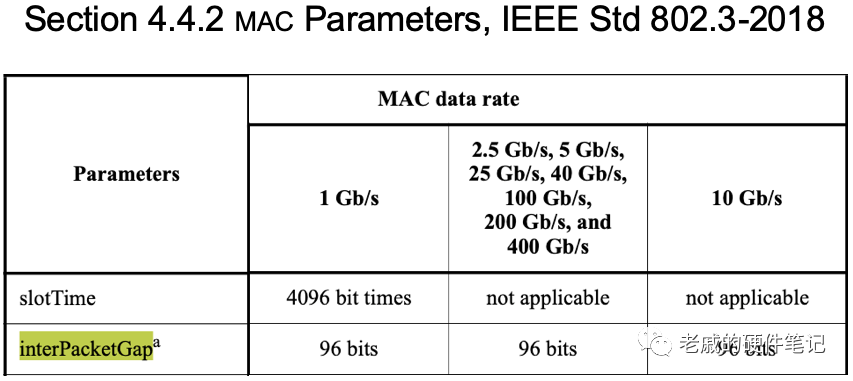
图<10>
通常而言,交换芯片(点击进入:可编程交换芯片)的内部带宽会大于接口的带宽,所以入口(Ingress)侧也不会丢包;在出口(Egress)侧,MAC却必须严格按照802.3标准恢复12字节的最小帧间隙,这会减缓发送的速度。可以想象,长时间的饱和流量会导致出口侧的缓存(packet buffer)越积越满。这种情况持续发生,最终会导致出口丢包。

图<11>
对于交换机产品,端口之间互相打包(转发包)是最基本的验证测试项目(图<11>)。我们期望线速(line rate,utilization 100%,最小IPG)不丢包,然而,经常会看到99.9999%就丢包了,丢的数量不多,短时间甚至看不出来;调到99.99%变好了;或者下调发包仪器(traffic generator)的参考时钟,比如-10PPM,丢包问题就消失了。当然,也有很多交换机按照100%速率转发包没有任何问题。究其原因,就是PPM时钟频率偏差引起的。
一个有意思的推论就是,虽然PCS能够补偿时钟的频率差异,同步以太网(Synchronized Ethernet)时钟驱动的时钟域,至少要包含MAC层,而不仅仅是PCS PHY。(SYNC-E下次聊)
部分以太网交换机的厂商会使用中心频率正偏25PPM的参考时钟,使得交换机的本地时钟处在相对高位,从而避免频差引起的丢包。但是,交换机之间的背对背连接呢?只要频率是本地产生的,总是会有高有低,这样做不能从根本上解决问题。
实际上,对于以太网的应用来说,PPM时钟偏差的影响并不大。不像SDH/SONET这种时分复用的系统,以太网包交换(packet switching)的优势在于带宽动态复用(或者统计复用,Statistical Multiplexing),企业级交换机(Enterprise Class Ethernet Switch)使用大缓存(packet buffer)来起到削峰填谷的作用。在MAC层,802.3X流控(flow control)协议定义了Pause Frame,可以用来通知对端暂停发送一段时间。更上层,TCP支持出错重传,还有QoS等等。
以上的讨论都是基于1000Base-X。当以太网的端口速率上升到10G以上,8b10b编码就被64b66b替代了,降低了额外带宽开销,前提是PMA层的CDR的技术提升(仅仅要求66b保证最少一次01转换);PCS层的IDLE码换了形式继续存在;8b10b检错变成了AM控制码携带的BIP(Bit Interleaving Parity)。总的来说,形式变了,原理没有变。而且,不仅是以太网,PCIe、SAS、SATA、USB等等也有类似的功能。
小结一下:物理层(physical layer)的物理编码子层(PCS - Physical Coding Sublayer)对解决时钟PPM问题起了关键作用,PCS借助FIFO处理跨时钟域,通过删除或插入IDLE码组,来补偿接收数据和本地时钟的有限频差,这就是弹性缓存(Elastic buffer)。弹性缓存加上包缓存,对突发(burst)数据流量有完美的效果,却不能解决长时间线速(line rate)流量下的丢包问题。当然,通过802.3X流控或者更上层协议避免长时间线速。
-
以太网应用关键技术及设计方案集锦2015-01-23 10329
-
德州仪器(TI)工业以太网解决方案2015-01-22 5314
-
设计坊第三期:灵活的工业以太网解决方案2013-12-25 5323
-
基于标准的汽车以太网解决方案的优势有哪些?2021-05-24 1847
-
工业以太网方案选择指南2011-07-09 1065
-
以太网协议及应用方案2017-01-21 823
-
高速以太网引动超大规模计算技术革新,时钟方案是实现高速以太网的关键2018-03-16 5996
-
Linux以太网解决方案的介绍2018-11-27 4125
-
半导体车用以太网解决方案2019-05-01 5485
-
以太网供电解决方案2021-05-18 1220
-
以太网时钟的PPM频率偏差的解决方案(上)2023-06-23 7702
-
数据中心市场的关键以太网解决方案2024-03-12 1222
-
MMWAVEPOEEVM以太网供电解决方案用户指南2024-11-28 595
-
TOSUN 车载以太网仿真测试解决方案2024-12-07 2227
-
IDT ICS8440258I - 45频率合成器:千兆和万兆以太网时钟解决方案2026-04-12 570
全部0条评论

快来发表一下你的评论吧 !
