

浅谈存算一体技术的发展路线
描述
后摩智能发布了首款存算一体芯片——鸿途 H30,最高物理算力 256TOPS,功耗仅为 35W,碾压国内一众智驾芯片。
存储一体?还首款?
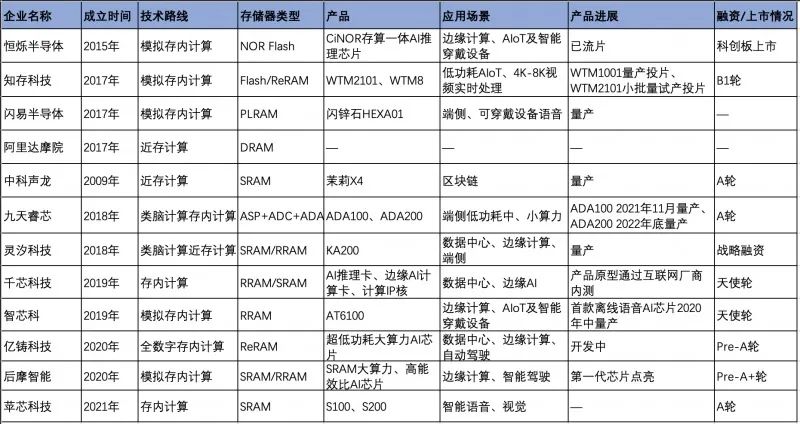
不仅是后摩智能,包括英特尔、SK 海力士、IBM、美光、三星、台积电、阿里、九天睿芯、恒烁股份、亿铸科技、千芯科技、苹芯科技、知存科技、智芯科技等在内,无论是国际大厂还是初创企业都纷纷扎堆涌入这个领域。
不禁要问,让各大芯片厂商打鸡血的存储一体是个什么东西,下面我们存算一体技术是什么,为什么这么火爆。
01存算一体是什么
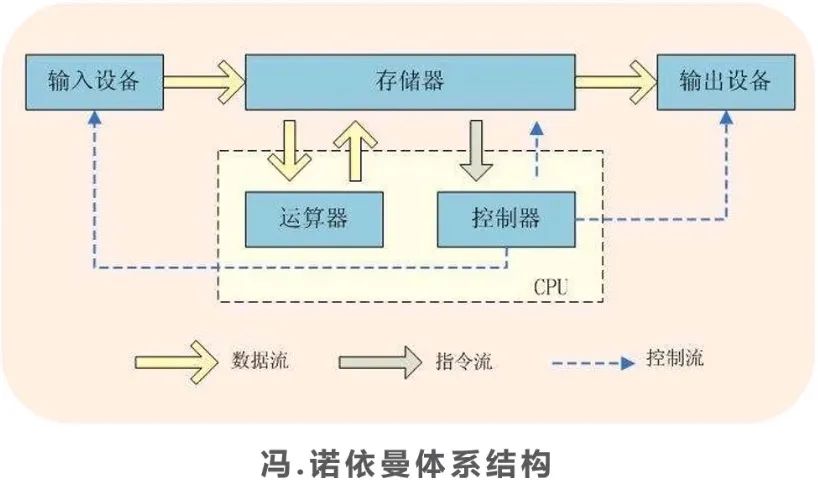
目前市面上的芯片都是基于冯诺依曼架构,其特点是处理单元和存储单元分离,各不相干,需要运算的时候,计算单元再从存储单元读取数据进行处理,处理完再还回去。
而存算一体则是把存储单元和处理单元合二为一,把数据和计算融合在同一片区中,这样处理的好处在于可以直接利用存储器进行数据处理,从根本上消除冯诺依曼架构计算存储分离的问题,尤其特别适用于现代大数据大规模并行的应用场景。
实际上存储一体并不是近年来被提出的新概念,最早可追溯至上个世纪 70 年代,只是受限于当时的芯片制造技术和算力需求,存算一体仅仅停留在理论研究上,一直到了大数据、人工智能时代,巨大的算力需求才为存算一体提供了新的发展动力。
比如中国国防科大、中科曙光和国家并行计算机工程技术研究中心计划推出首台 E 级超算,但想要研制这种级别的超算,科学家首先面临的巨大挑战就是功耗过高问题,以现有的技术研制 E 级超算功率高达千兆瓦,需要一个专门的核电站才能满足耗电量,而其中 50% 以上的电量都要被用来消耗进行数据搬运。
本质上就是冯诺依曼架构的处理和存储分离的缺陷所致,因此存算一体被当作全村的希望。
02存算一体的优势
由于把存储计算合二为一,去掉了中间传输路径,所以可以大幅减少数据搬运,消过程中不必要的延迟和功耗,能耗可降至 1/10-1/100,能效可提升 10-100TOPS/W
因为存储一体是以存储器为介质,在里面加入计算单元,所以可以直接利用存储单元进行逻辑计算提升算力。(等效于在面积不变的情况下规模化增加计算核心数),在特定区域可提供 1000TOPS 以上的算力
不依赖制程工艺,因为存储一体基于全新架构开发,可以打破摩尔定律的限制,所以不受先进制程工艺限制。比如鸿途 H30 就是基于 12nm 制程工艺打造,在 Int8 数据精度下实现高达 256TOPS 的物理算力,功耗不超过 35W。
如果在传统的冯·诺依曼架构下采用相同工艺,能效比多在 2TOPS/W,某国际巨头芯片基于 8nm 工艺,如果二者用同一工艺,存算一体架构的芯片处理效率优势将会更加明显。
存算一体超越冯诺依曼架构,该架构可彻底消除数据搬运过程中的延迟和功耗,是一种真正意义上的处理存储相融合,所以二者完全耦合,可以开发更细粒度的并行性,从而获得更高的性能和能效,明显超越现有的 ASIC 芯片。
存算一体架构无论是制程、功耗、成本还是算力,相比传统架构都有明显优势,可以说完全就是为人工智能时代而生,但前途有多光明,道路就有多曲折,存算一体技术研发的困难也是相当巨大。
03存算一体的挑战
传统架构是计算和存储相分离,现在两者要合二为一,这就对存储器本身和存算一体的设计提出更高的要求,是需要技术人员从头探索的新领域。
随着以后数据量不断增大,在全新架构下,计算、功耗、通信三方面都要重新变革,对制造工艺都提出更高要求。
为了保持梯度计算的保真性和权重更新,现在市面上的AI芯片大都在 16bit 精度以上,而作为首款存算一体芯片的鸿途 H30 只有 8bit,还难以和传统芯片媲美,即便是在 PCM 存储器上有十多年的 IBM,也只是发布了 8bit 精度的模拟芯片,而其他大厂如微软、英特尔、美光等则是投资创业公司。
由于存算一体是把计算和数据高度耦合,因此一旦其中一方出问题,另一方几乎也会遭到极大影响,这都是需要处理的难题。
总而言之,存算一体是一条全新的、没有现成方法可以参考的、还需要解决传统架构遗留问题的艰难道路。
可即便优势明显,但存算一体难度这么大,为什么各路大厂还要纷纷打鸡血参战,传统芯片架构技术成熟、产品可靠,创业公司也就算了,但为什么传统厂商也来趟这趟回水,传统芯片架构没路可走了吗,下面就要说说传统架构的问题了。
04传统芯片架构的「原罪」
文章开头提到过,传统芯片都是基于冯诺依曼架构开发,这种架构的特点是处理和存储两部分是分开的,通过数据总线进行数据连接传输,而且是以处理为主,存储主要起到辅助作用,处理器先要把存储器里的数据搬运出来才能处理,处理完再丢回去。
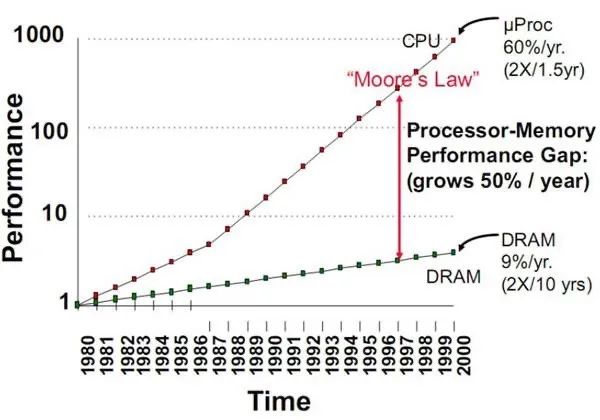
但随着芯片技术的飞速发展,处理器的性能不断飙升,而存储器的性能却在龟速前进,两者的性能差距越来越大,存储器的读写速度远远跟不上处理器的处理速度,导致芯片在运行的时候,大部分算力都被搬运数据的过程消耗掉了,只有小部分算力被有效利用。
就相当于一个极度口渴的人拿着一瓶水,瓶子的瓶体直径有 1 米,但瓶口直径只有 1 厘米,那种感觉各位感受下,所以逐渐就形成了业界普遍流传的存储墙,严重制约芯片综合性能的提升。
有算力的地方就有功耗,正如上文所说,基于冯诺依曼架构开发的芯片在处理数据的过程中,处理器先要通过数据总线把存储器中的数据搬运出来,处理完成后在搬运回去,整个搬运过程所消耗的功耗是浮点运算的 4-1000 倍左右。
虽然半导体工艺一直在进步,芯片的总体功耗在下降,但冯诺依曼架构天然的缺陷难以改变,数据搬运的功耗比只会越来越大,整个过程的无用能耗能占到 60%-90%,能效之低,令人发指,因此又形成了功耗墙,两面墙就这样死死压制着芯片性能的提升。
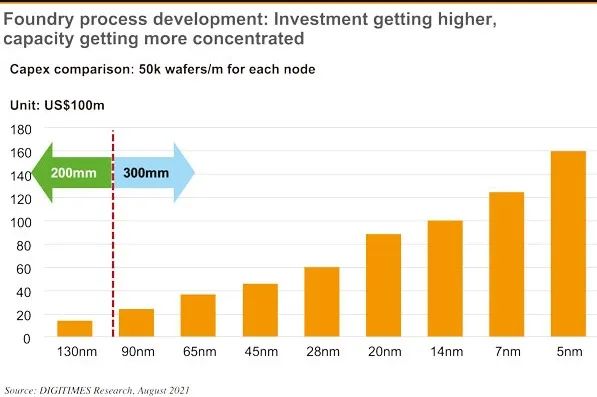
另外,根据咨询公司评估,晶圆厂每一代工艺的建设资金都在急剧增加,还不说技术专利和人才问题,只是建造一个 5nm 晶圆厂,就需要 160 亿美元,光是资金就吓退所有人。
为了打破冯诺依曼架构的瓶颈,降低处理和存储二者搬运过程带来的高损耗,学术界和产业界尝试了各种方法,大体可分为两类:
近存储计算
核心思想就是设计芯片的时候,把处理单元和存储单元两块区域尽可能的拉近距离,缩短路径,从而降低数据搬运过程中的算力损耗和功耗,目前市面上的主要技术路径是多级缓存和高密度片上存储。
光互连、2D/3D堆叠和高速带宽数据通信
2D/3D堆叠技术是将多个芯片堆叠在一起,通过增大处理单元和存储单元之间的并行宽度提高传输速度。
高速带宽数据通信主要就是通过提高通信带宽降低数据搬运过程的损耗。
因为冯诺依曼架构的天然缺陷依旧存在,所以上面两种方案并没有从根本上解决数据存储和处理的搬运损耗问题,到了大数据、人工智能时代,海量的数据处理让这些问题暴露的更加彻底,产业界和学术界都迫切希望找到一种能彻底解决该问题的方案,就是存算一体。
综上所述,就是传统的冯诺依曼架构缺陷导致自我消耗、限制太大,无法满足算力需求,再加上摩尔定律逼近极限、晶圆厂建设又是个吞金兽,成本巨大,几乎死路一条,各大厂商只能押注存算一体。
简单来说,从冯诺依曼架构到存算一体架构,指导思想就是停止内耗,一致对外。
05存算一体技术发展路线
虽然存储一体已经成为目前业界发展共识,但由于各个技术厂商的技术、发展方向、商业模式等条件不同,因此发展出了四种路径。
查存计算
目前 GPU 芯片中对复杂函数的处理就是用了这种方法,主要通过在存储单元内部查表完成处理任务,技术成熟稳定。
近存计算
国外的典型代表便是 AMD 的 ZEN 系列 CPU,国内阿里巴巴基于 DRAM 的 3D 堆叠技术芯片也是这个路线,主要通过在存储区域外部的独立处理单元完成操作,这种架构的代际升级成本较低,特别适合传统芯片厂商过渡。
存内计算
主要在存储单元内部加入独立计算单元完成数据处理操作,计算方式可以是数字也可以是模拟,一般用于固定场景的算法计算,上文提到的鸿途 H30 便属于这种。
存内逻辑
这是目前存算一体的最新架构,主要在存储区域加入计算逻辑,直接进行数据计算,这种架构数据传输路径最短,真正做到存算一体,能满足大模型的计算需求,代表厂商有 TSMC 和千芯科技。
由于存算一体芯片都是基于存储器介质开发,而存储器可分为易失性和非易失性两种,所以又有数字计算和模拟计算两种方向。
基于易失性的数字计算存储器,主要有 SRAM 和 DRAM。
SRAM 和 DRAM 技术工艺成熟,是目前存储器的主流,因此很多厂商都基于两者展开存算一体技术研究,具有高性能和高精度优点,也有很好的抗噪声能力和可靠性。
基于非易失性的模拟计算存储器,主要有闪存 Flash、相变存储器 PCM、阻变存储器 RRAM/忆阻器 ReRAM。
这些新型存储器在近年来取得了较快的发展,具有存储密度大、并行度高优点、对存储和计算具备天然的融合性,但对环境噪声和温度比较敏感,但由于工艺尚不成熟,距离真正落地还有一段距离。
数字存算一体适合大算力高能效的应用场景,模拟存算一体适合小算力、不需要非常强的可靠性的民用场景。
一句话概括,未来很长一段时间内,SRAM 和 DRAM 都是存算一体芯片的主流选择。
写在最后
存算一体已经被业界普遍确定为下一代人工智能芯片技术发展方向,由于是全新的技术方向,目前国内外厂商都处于刚起步阶段,没有成熟方法可以借用,而且该技术依赖于存储器的不断流片积累经验,需要技术团队有充分的量产经验和技术认知,还需要大量资金,行业壁垒很高。
目前各大厂商根据自身情况,主要有两种发展思路:
从小算力入手,比如从 1TOPS 开始,先解决音频类、健康类这些低功耗的应用场景,掌握芯片商业化后的性能和功耗问题,然后在进入大算力领域。
直接发展大算力,提供大于 100TOPS 的高性价比产品,应用于智能驾驶、云计算、机器人等领域。
随着现在各种大模型、自动驾驶、云计算等 AI 技术的加速落地,对大算力需求迫切增加,即使技术有很多困难,但巨大的市场需求一定会倒逼技术突破,成为继 CPU、GPU 架构之后的另一主流架构。
审核编辑:汤梓红
-
存算一体大算力AI芯片将逐渐走向落地应用2022-05-31 6823
-
比存算一体更进一步,“感存算一体化”前景如何?2022-06-08 7866
-
2PFLOPS,存算一体迎来新的卷王2022-08-29 4813
-
探索存内计算—基于 SRAM 的存内计算与基于 MRAM 的存算一体的探究2024-05-16 5828
-
ReRAM存算一体AI大算力芯片的独特优势2022-06-20 9738
-
存算一体技术路线如何选2022-06-21 11444
-
存算一体技术发展现状和未来趋势电子发烧友网官方 2023-04-25
-
2023年存算一体是芯片设计的技术趋势2023-01-13 3540
-
关于存算一体,我们和ChatGPT聊了聊2023-02-09 2897
-
特斯拉的下一代AI芯片:存算一体2023-03-09 3658
-
ChatGPT开启大模型“军备赛”,存算一体开启算力新篇章2023-07-06 905
-
如何选择存储器类型 存算一体芯片发展趋势2023-09-06 1931
-
存算一体芯片的技术壁垒2023-09-22 2839
-
存算一体芯片新突破!清华大学研制出首颗存算一体芯片2023-10-11 2354
-
一文看懂“存算一体”2025-08-18 1834
全部0条评论

快来发表一下你的评论吧 !
