

IPLFS的设计与实现
存储技术
描述
动机和背景
IPLFS是一个避免文件系统层垃圾回收的日志结构文件系统。作者发现,日志结构文件系统的仅追加写入方式会带来不可避免的文件系统层次垃圾回收。十数年来,学界已经提出多种缓解垃圾回收开销的方式,包括空闲时段垃圾回收、预先垃圾回收、选择最合适的回收段算法等。
与此同时,SSD的设备端垃圾回收同样给存储系统带来可观的带宽下降和延迟。当日志结构文件系统和SSD一起使用时,两端的垃圾回收开销可能会叠加影响。为了解决这种问题,大多数工作提出让主机端直接管理闪存页,以解决设备端垃圾回收开销,比如最近的ZNS技术等。
而作者发现,随着计算机系统的发展,大多数组件,比如CPU、内存等都已经支持虚拟化技术,而存储设备则不支持虚拟化。因此作者提出,可以将SSD的LBA和PBA分离,实现SSD的地址虚拟化,从而避免文件系统垃圾回收。
IPLFS的设计与实现
IPLFS的设计目标是在保持日志结构文件系统仅追加更新特性的同时,完全取消文件系统层垃圾回收。IPLFS的设计共有三个重点:多区域分区布局、无GC的元数据设计、全新的丢弃映射和丢弃日志。
多区域分区布局
为了减小LBA映射表的大小,IPLFS把整个LBA地址空间分为7个大小相同的区域,分别是一个用于存储超级块、节点映射表等数据的IPLFS元数据区,和6个对应存储F2FS不同热度、不同类型数据的段的数据区。在地址空间使用上,IPLFS使用最高的3比特作为区域标识符,剩余58位用来作为地址使用,因此每个区域可以保存258个块,共计1ZB。
元数据设计
元数据的设计要求最小化原始F2FS元数据的盘上数据修改。由于IPLFLS不再需要文件系统垃圾回收,同时由于地址空间过大,因此IPLFS仅移除了F2FS中用于垃圾回收和块丢弃的两个元数据:反向映射表和块分配映射位图。
而IPLFS仍旧保留了节点分配表NAT,而NAT的大小决定了文件系统中文件数量的上限,因此NAT的大小不再是传统的由LBA大小决定,而修改为由PBA大小决定。被移除的分配映射表和反向映射信息由全新的丢弃映射位图和丢弃日志取代。
丢弃无效块
F2FS使用块分配位图有两个原因:一是代表每个段空间利用率,二是追踪最新无效的文件系统块。而在IPLFS中,空间利用率不再重要,而被无效的块仍然需要追踪。IPLFS使用使用丢弃映射位图取代了F2FS的块分配位图,用于表征自最后一个检查点后无效的块,每个位图表示一个分区,每个分区包括一个或多个段。一个丢弃映射位图包括分区的起始地址和映射位图两部分。
当文件系统标识一个块无效,则设置对应的丢弃映射表的无效位,多个丢弃映射表使用哈希表组织为一组,使用段编号作为键。当块被无效时,IPLFS搜索哈希表并查找对应丢弃映射位图,若找到则更新位图;若更新位图不存在则分配一个新的丢弃映射位图并更新,之后将新的位图插入哈希表。
段的大小和文件系统性能存在trade-off。段大小越大,丢弃映射位图越大。段越小则哈希表中的丢弃映射位图条目越多,查询延迟升高。实验表明,最佳段大小为1GB,同时平衡性能和内存压力。
在每个检查点触发时,IPLFS扫描哈希表,对每个丢弃映射位图构造丢弃指令,之后移除对应丢弃映射位图。IPLFS会定期提交丢弃指令。IPLFS单独开启一个线程用于分发丢弃指令,每次唤醒最多下发16条丢弃指令,IPLFS的丢弃指令分发相较F2FS更加激进,无论是否存在等待中的IO,均下发丢弃指令;而F2FS需要等待直到文件系统中无等待中的IO存在再下发丢弃指令。在实验中发现发现激进的下发策略获得了更好的基准测试表现,因为这样做使得SSD的GC更加高效,避免了写放大。
丢弃日志
由于缺乏块分配位图,IPLFS难以感知存储空间泄露,即flash页存储了无效的FS块,但是FS从不回收这些页。如系统崩溃时为下发的丢弃指令。F2FS中恢复程序会根据恢复的块分配位图重建丢弃指令。为了解决这个问题,IPLFS使用了丢弃日志。丢弃日志在下发丢弃指令前建立丢弃指令检查点,保证丢弃指令再下发到设备前被持久化。在检查点包中建立丢弃日志区保存丢弃日志。在每个检查点,IPLFS检查丢弃映射表并创建丢弃指令,IPLFS在丢弃日志区记录丢弃指令的信息(起始LBA、长度),之后将日志同步落盘,检查点后,IPLFS唤醒丢弃线程提交丢弃指令。
重建丢弃指令分为两个阶段,首先是回滚恢复,恢复模块读取最近的检查点包,重建丢弃指令;之后是前滚恢复,前滚恢复时识别在最近检查点后被写入文件,对比节点块,对比前滚恢复阶段的节点块和检查点时的节点快,识别修改记录,针对新分配的节点块更新文件映射表。
中间映射表设计
为了解决过大的LBA占用过多SSD映射资源的问题,IPLFS在OpenSSD平台重新设计了中间映射表。首先,中间映射表采用LBA充足映射方式,作者称之为间隔映射,设计和Interval tree类似,树高限制为3,通过增加根节点扇出的方式增加映射节点,以此降低地址转换相关内存开销。间隔映射以分区数组的形式组织存储区域。每个分区都是一个映射段数组,每个分区对应16GB,而每个段对应16MB;间隔映射树的根节点保存一组分区节点队列,每个节点维护单个分区的数据。一个分区节点维护1024个映射表节点作为子节点,每个映射表节点维护一个段的LBA-PBA映射。
映射中间层是一块需要IM树进行映射的逻辑分区,映射中间层使用其对应逻辑分区的第一个分区的起始LBA和最后一个分区的起始LBA表示。当分区创建时,映射中间层会为IPLFS分区创建6个独立的IM树,分别对应IPLFS的6个数据段。
活跃中间层表示的是对应映射中间层中活跃的已使用分区的窗口。活跃分区类似,活跃中间层起始于对应映射中间层中第一个有效分区,结束于对应映射中间层中最后一个有效分区。当活跃中间层表中第一个分区被无效时,其起始分区被更新;当新的分区加到活跃中间层末端时,其结束分区被更新。随着FS老化,活跃中间层的地址表示窗口向高处移动,当活跃中间层终点移动到接近映射中间层终点时,中间映射表会构造新的根节点和新的映射中间层以更好容纳不断变化的活跃中间层。
评估
IPLFS实现在F2FS(Linux 5.11.0)上,中间映射表使用OpenSSD(230GB ,8通道)实现。测试环境采用PC服务器(I7-4770K)+8GB DRAM配合OpenSSD实现。
文件系统垃圾回收消除效果实验
首先测试消除文件系统层垃圾回收的前后性能表现,测试方式为:在SSD上构建30GB逻辑空间的F2FS,用4线程随机写28GB文件,每2s检测吞吐量。测试发现,当F2FS开始进行文件系统层垃圾回收时,IO性能下降到之前的以下,如下图所示。
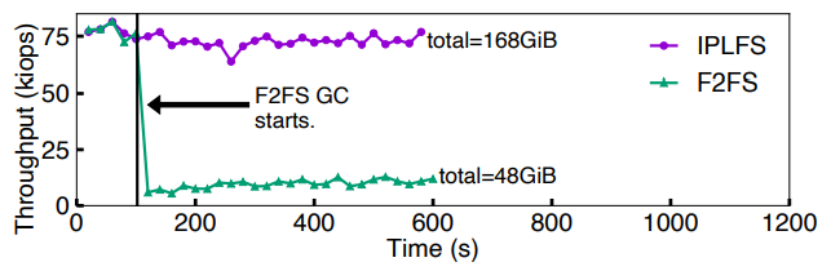
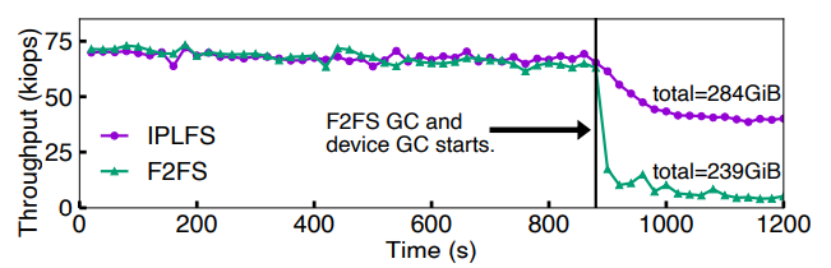
接着作者测试了文件系统层垃圾回收和设备端垃圾回收对性能的影响权重。测试方式为:使用与OpenSSD物理容量相同的逻辑分区大小共230GB,随机写210GB的文件。结果表明,当F2FS开始垃圾回收时,吞吐量下降到接近;而IPLFS消除了文件系统层垃圾回收,但是无法消除设备侧垃圾回收,当OpenSSD开始设备层垃圾回收时,性能下降60%左右。因此作者认为,文件系统层垃圾回收对性能的影响比设备层垃圾回收更大。
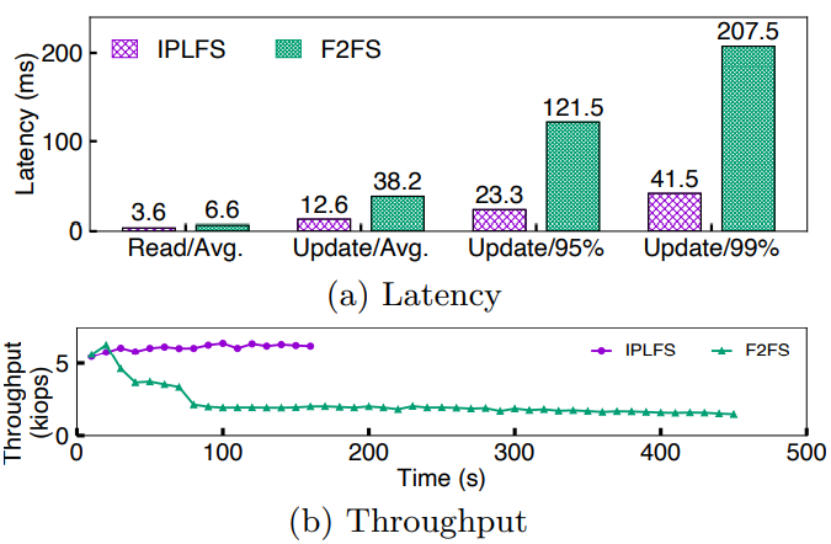
最后,作者使用MySQL数据库和YCSB-A负载测试数据库操作受文件系统垃圾回收的影响情况。YCSB-A负载包括等量的读更新操作。从下图的吞吐量、延迟变化曲线可以看出,开始测试时文件系统达到90%占用率,因此快速触发文件系统层垃圾回收。IPLFS的平均读延迟和平均更新延迟仅为F2FS的和。同时作者从实验结果发现:取消文件系统垃圾回收可以显著提升尾端延迟表现,IPLFS的95%和99%尾延迟相对F2FS分别降低5.2X和5X,并且IPLFS吞吐量保持稳定。
IPLFS的丢弃策略
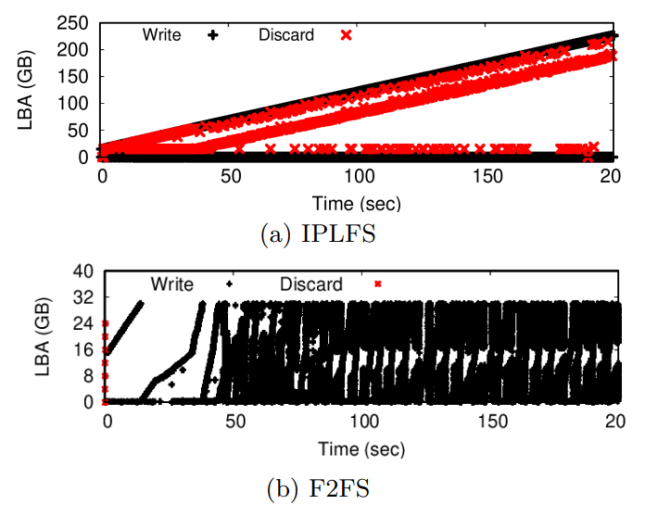
之后进行的测试目的是测试激进的丢弃策略对设备层垃圾回收和应用性能的影响。作者采用Filebench的fileserver负载,创建50个线程,更新/删除2MB文件。测试发现,在全占用率下,IPLFS的写放大比F2FS更低,同时吞吐量提升24%。对结果进行分析后,作者认为更激进的丢弃策略节省了FTL在垃圾回收时的迁移数量,因此IPLFS在写放大和基准测试方面有了显著改善。通过IO trace分析,作者发现IPLFS比F2FS更频繁的提交丢弃指令,这是由于F2FS仅在无等待IO时提交丢弃指令。然而在测试中,极少有不存咋等待中IO的情况。
地址转换开销测试
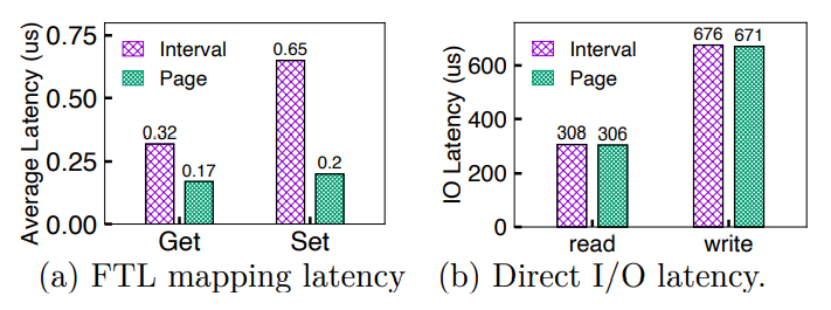
首先作者进行了地址转换延迟的测试,测试方法为使用fio对10GB文件进行4线程随机写操作。测试发现,IPLFS的中间映射方式比传统的页映射延迟长88%。作者分析这是因为中间映射层在地址转换时使用的是多索引查找,而当构建新的映射条目时,中间映射层的延迟为页映射的3.3倍。
之后作者进行了端到端延迟测试,测试发现中间映射层和页映射在读写延迟上几乎相同,如下图所示,而这是因为实际访问中,Nand的访问延时和设备数据传输延时是延迟的主要部分,而FTL中的延迟影响微不足道。
总结
作者提出了一种用于无限分区的日志结构文件系统IPLFS。将文件系统分区大小从物理存储大小中分离出来,并使得逻辑文件系统的分区大小实际上无限大,这样就可以使日志结构的文件系统免于回收无效的文件系统块。为了维护超大逻辑文件系统分区的映射信息,作者开发了中间映射层,只为活跃的LBA区域维护LBA-PBA映射。通过将IPLFS和中间映射层结合在一起,作者成功减轻了日志结构文件系统回收无效块的开销。
编辑:黄飞
-
FPGA实现网络抓包怎么实现?2013-01-22 4885
-
如何采用VHDL硬件实现DDS的优化设计与实现?2021-04-12 1225
-
怎么实现基于STM32的DAC实现音频波形的输出?2021-11-19 1624
-
多功能数字钟的设计与实现2009-05-03 3057
-
用PLD实现FFT2009-05-11 1098
-
触摸屏的实现原理及在android上的实现2016-05-23 772
-
无线充电技术设备的实现无线充电技术设备的实现2017-09-15 1168
-
目标捕捉系统的的设计和实现2017-10-16 819
-
如何使用LabVIEW实现小波变换2020-04-20 2461
-
HAL实现多个超声波测距(输入捕获实现)2021-11-23 1308
-
如何使用VPSS实现旋转功能2022-01-26 1009
-
ChatGPT实现原理2023-02-13 149354
-
触发器实现边沿出发是如何实现的?2023-06-28 3542
-
Netfilter 的设计与实现2023-11-13 1325
-
通过电平转换实现窄带IoT实现2024-09-21 479
全部0条评论

快来发表一下你的评论吧 !
