

基于在广泛的计算平台上进行高效渲染的神经场体系结构
描述
Neural Radiance Fields (NeRF) 通过合成 3D 场景新视角图像展现出惊人的能力。然而,它们依赖于基于光线行进的专门体积渲染算法,这些算法不符合广泛部署的图形硬件的能力。本文提出了一种基于纹理多边形的新型 NeRF 表示法,它将 3D 场景转化为一组多边形。这种方法使用传统的多边形光栅化管道进行渲染,提供了大规模的像素级并行性,可以在广泛的计算平台上实现交互式帧率。
1 前言
NeRF 是表示 3D 场景的方法,通过估计从任何位置和方向发射的密度和辐射的隐式函数,用于体积渲染框架生成新视角图像。然而,传统的 NeRF 实现的渲染过程太慢以至于无法进行交互式可视化。本文提出了一个名为 MobileNeRF 的方法,将 NeRF 表示为一组纹理多边形,利用现代图形硬件的光栅化管道和 Z-buffer 实现像素级并行性,以实现交互式帧率渲染,并在 标准测试场景上优于 SNeRG 10 倍,适用于各种常见移动设备。
MobileNeRF 的贡献如下:
在与最先进的方法(SNeRG)具有相同输出质量的情况下,渲染速度提高了 10 倍;
通过存储表面纹理而不是体积纹理,使用的内存较少,使本文的方法能够在具有有限内存和功率的集成 GPU 上运行;
可以在 Web 浏览器上运行,并且与本文测试过的所有设备兼容,因为本文的查看器是一个 HTML 网页;
允许对重建的对象/场景进行实时操作,因为它们是简单的三角形网格。
2 相关背景
本文介绍了在视图综合方面的多种方法和技术,包括光场、几何图形、神经网络等。不同的方法有不同的优势和局限性,但是它们的共同目标是实现高质量的实时渲染。作者的方法通过缓存发射辐射来实现高质量的视图综合,并且适用于低功率硬件上的实时渲染。同时,它不需要输入重构的3D几何体。与现有的方法相比,作者的方法在低功率设备上具有更好的可用性。
3 方法
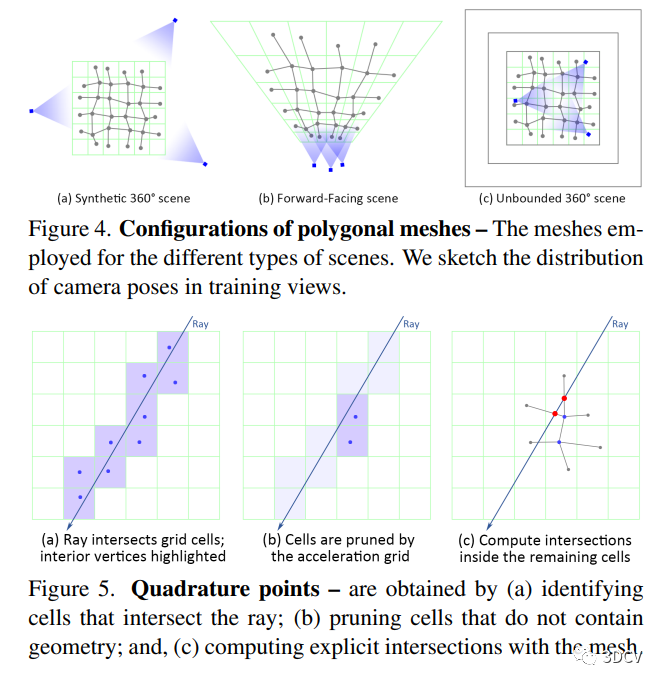
本文介绍了一种优化表示以实现高效新视图综合的方法。该表示包含一个多边形网格和纹理映射,采用两阶段延迟渲染过程来绘制图像。该方法需要初始三维几何体,并通过迭代过程中修改网格来进行优化。本文提出了一种离散表示来实现高效的新视图综合的方法。该方法通过渲染阶段1和渲染阶段2实现。作者采用三个训练阶段来构建本方法的离散表示。在最后的训练阶段,作者提取了一个稀疏的多边形网格,将不透明度和特征烘焙到纹理映射中,并存储了神经延迟着色器的权重。同时,作者提出了一种基于超采样的简单且计算高效的抗锯齿解决方案。由于采用标准的GPU光栅化管道,因此我们的实时渲染器只是一个HTML网页。
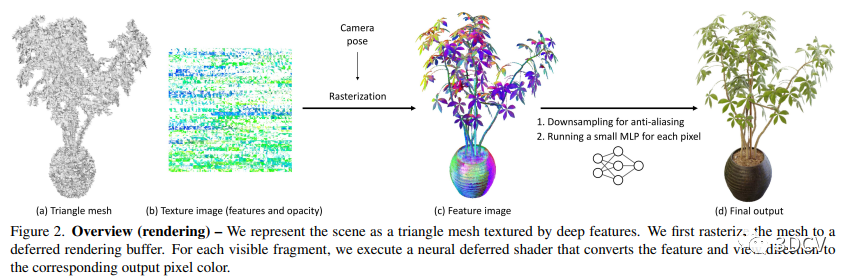
3.1 Continuous training (Training Stage 1) - 连续训练(训练阶段1
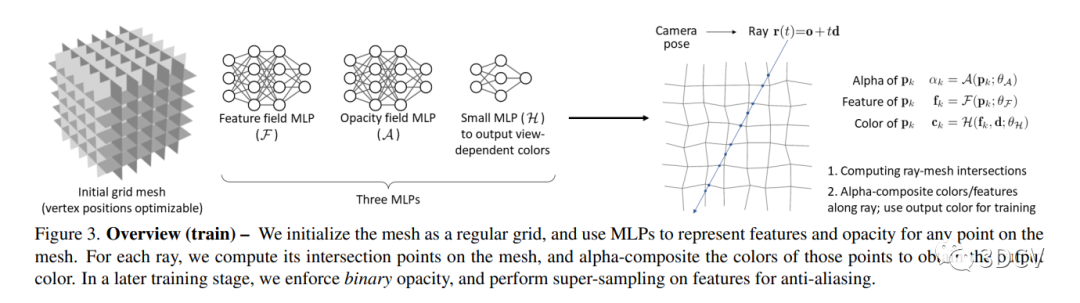
本文提出了一个新颖的渲染框架,构建了一个以多边形网格为基础的渲染器,其中使用透明合成和神经渲染器来产生高保真度的图像。作者使用MLPs来表示网格中的颜色和不透明度,使用MLP的输入来表示网格中的几何完成,从而实现了从场景数据到图像的连续训练。作者使用了加速格子来限制每条光线上的积分点数量,从而减少了渲染时间。与现有的渲染框架相比,作者的方法可以更好地处理反射,折射,阴影和非连续性的材料,并且对于多个数据集进行了广泛的实验和评估,结果表明它可以生成具有可比性的视图。
3.2 Binarized training (Training Stage 2) - 二值化训练(训练阶段2)
 本文介绍了如何使用离散/分类不透明度来避免处理半透明物体时需要排序的问题。作者使用一个直通估计器优化离散操作,并提出了一个联合训练策略来同时训练连续模型和离散模型。离散模型的输出辐射度由离散不透明度和颜色加权组成。最后,文章提到将进行微调来优化训练结果。
本文介绍了如何使用离散/分类不透明度来避免处理半透明物体时需要排序的问题。作者使用一个直通估计器优化离散操作,并提出了一个联合训练策略来同时训练连续模型和离散模型。离散模型的输出辐射度由离散不透明度和颜色加权组成。最后,文章提到将进行微调来优化训练结果。
3.3 Discretization (Training Stage 3) - 交叉注意力实现可微分渲染
本文介绍了如何将离散/分类不透明度的表示转换为显式的多边形网格,并将其存储为纹理图像。作者实验中使用的技术包括可见的四边形的剪裁、尺寸调整和离散不透明度值和特征值的烘焙。值得注意的是,8位的量化精度在反向传播中没有被考虑到,但对渲染质量的影响不大。
3.4 Anti-aliasing - 训练和损失函数
本文采用超采样来实现抗锯齿,并通过对特征进行平均来避免每帧多边形排序。抗锯齿的变化应用于训练阶段2中,最终作者平均子像素特征来获得抗锯齿表示并将其传递给神经推迟着色器。
3.5 Rendering - 渲染
本文使用优化的延迟渲染管线进行渲染,包含两个步骤:光栅化多边形以及渲染纹理矩形并将其与特征图像叠加。采用二进制透明度的z-buffer使得多边形不需要按照深度排序,且由于特征转换的小型MLP可以在GLSL片元着色器中并行运行,所以能够在GPU上高度优化,以实现在各种设备上以交互式帧速率运行。
4 实验
MobileNeRF通过在三个数据集上进行测试,包括NeRF合成的场景,LLFF前向场景和Mip-NeRF 360的无界户外场景,证明了在各种场景和设备上表现良好。与SNeRG进行比较显示MobileNeRF可以在常见设备上实时运行。详细的消融研究进一步研究了不同设计选择的影响。
4.1 比较
本研究通过在各种设备上测试证明了MobileNeRF的出色性能和兼容性。在渲染质量方面,使用PSNR、SSIM和LPIPS等指标显示本文的方法具有与SNeRG相近的图像质量,且优于NeRF。此外,MobileNeRF需要的GPU内存比SNeRG少5倍。渲染质量在相机距离适当的情况下与SNeRG类似,但当相机缩放时,SNeRG容易渲染过度平滑的图像。三角形面不与实际物体表面对齐,因此需要更好的正则化损失或训练目标来改善表面质量。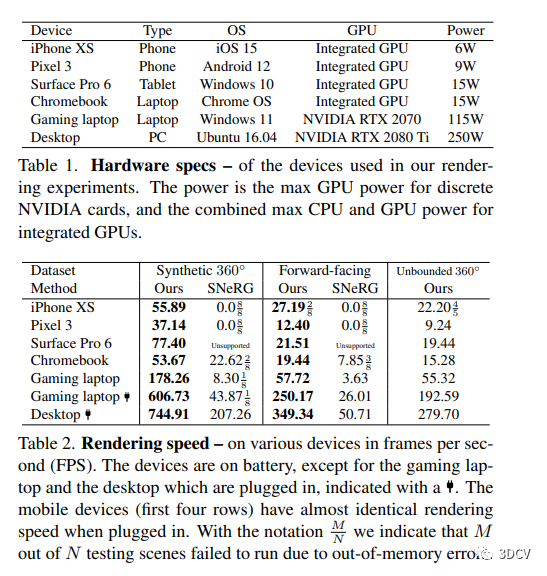
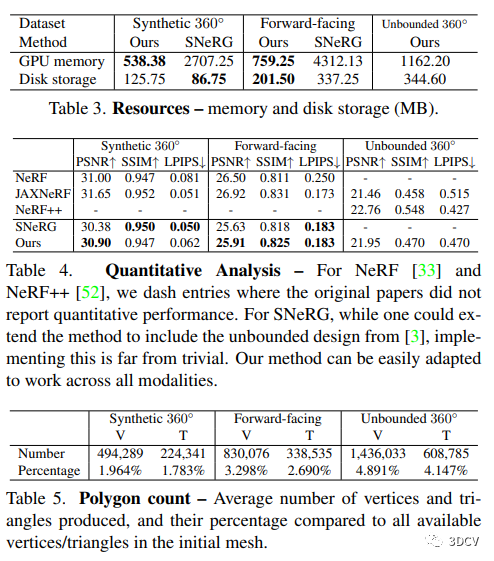

4.2 消融研究
本文讨论了在表中展示的消融研究,分析了在每个阶段中各种修改对渲染效果的影响。在第一阶段中,使用固定网格或不使用视角相关效果会显着降低性能。在第二阶段中,不进行微调或仅使用二进制不透明度会导致性能下降。在第三阶段中,使用更大的纹理大小可以提高性能,但空间成本也会增加。超采样步骤和小型MLP对性能影响最大。

5 总结
MobileNeRF介绍了一种可以在广泛的计算平台上进行高效渲染的神经场体系结构,可以比之前的最新技术更快地生成同等质量的图像。然而,它存在一些限制,如估计的表面可能不准确,它无法处理半透明和高光表面等。扩展多边形渲染管道可以解决这些问题,并将该架构扩展到快速训练的体系结构这是未来工作的一个激动人心的方向。
-
无线传感器网络的体系结构分析2011-11-03 10083
-
带你了解Linux内核体系结构2018-08-27 3352
-
如何在Android上进行高刷新率渲染2021-01-26 2776
-
工业以太网协议可以分成哪几类体系结构?2021-04-15 2067
-
面向计算体系结构的电机控制,看完你就懂了2021-05-18 2028
-
了解计算机硬件体系结构2021-09-17 1430
-
计算机体系结构的相关资料推荐2022-01-07 1221
-
怎样在阿里云物联网平台上进行单片机程序的编写呢2022-02-22 1714
-
了解体系结构 - 介绍 Arm 体系结构2023-08-01 650
-
Arm的DRTM体系结构规范2023-08-08 1133
-
Arm CoreSight体系结构规范2023-08-09 477
-
LTE体系结构2009-06-16 10306
-
网络体系结构,什么是网络体系结构2010-04-06 2142
-
计算机体系结构2016-06-21 795
-
软件体系结构的分析2017-11-24 1451
全部0条评论

快来发表一下你的评论吧 !
