

CoTTA的新方法:用于在非平稳环境下进行持续的测试时间适应
电子说
描述
Continual Test-Time 的领域适应
目录
前言
相关工作
Source Data Adaptation
Target Data Adaptation
CoTTA 概述
CoTTA 详细介绍
Weight-Averaged Pseudo-Labels
Augmentation-Averaged Pseudo-Labels
Stochastic Restoration
实验
结论
参考
前言
Continual Test-Time 的领域适应(CoTTA)在 CVPR 2022 上被提出,目的是在不使用任何源数据(source domain)的情况下,将源预训练模型适应于目标域(target domain)。现有的研究主要关注于处理静态 target domain 的情况。然而,在现实世界中,机器感知系统必须在不稳定且不断变化的环境中运行,target domain 的分布会随时间不断变化。
现有的方法主要基于自训练和熵正则化,但它们还是可能受到这些非稳定环境的影响。由于 target domain 内的分布随时间发生偏移,伪标签变得不可靠。因此,带有噪声的伪标注进一步导致错误积累和灾难性遗忘。为了应对这些问题,这篇文章提出了一种测试时领域适应方法(CoTTA)。
在正式介绍 CoTTA 之前,我们先来熟悉一些相关工作。
相关工作
Source Data Adaptation
Domain Adaptation (DA) :此时,我们有源数据 + 源标签 + 目标数据,希望模型做到在没看过的⽬标数据上性能好,目标数据的标签限制到很少或者为零。
Domain Generalization (DG) :此时,我们有源数据 + 源标签,希望模型做到在⽬标数据上性能好。
Target Data Adaptation
Source-Free Domain Adaptation (SFDA): 在上面的 settings 中,训练过程是可以访问到源域数据的。但是在实际情况中,由于隐私原因(医疗数据不能公开)或者数据量问题,我们并不能获取到源域数据,而只能获取到源域所训练好的模型。这个 setting 的目的就是只利用源模型来完成 Domain Adaptation。
Test-Time Training (TTT): 从信息的角度,从前我们训练神经网络都只利用了训练集的信息(监督学习),但其实测试集也从数据分布的角度提供了信息。这个 setting 主要就是提出了一种同时利用了训练集信息,和测试集所提供的数据分布的信息去训练神经网络的方法。允许⼀次性获得整个测试数据集,并且多次迭代。测试时根据测试样本泛化,可以获取源数据。
Test-Time Adaptation (TTA): 传统的模型训练后固定,在测试时无法改变。TTA 可以让模型在测试时可以快速地微调和调整,从而能够面对现实世界中,数据的分布不断演化的过程。TTA 是 Domain Adaptation 的一个分支。它们同样有一个源域和一个目标域,首先在源域上进行预训练,然后半监督或无监督地适应到目标域上。两者的主要区别在于,Test-Time Adaptation 的训练在测试的同时完成。可以简单理解为,Test-Time Adaptation 是只经过一个 epoch 的 DA。另一个区别在于,DA 往往报告模型训练完成后的模型性能,而 TTA 的测试和训练是同时进行的,故报告的性能介于训练前和训练结束之间。我们可以获得源模型 + 整个测试数据。
CoTTA 概述
先考虑一个问题,为什么要从 TTA 到 CoTTA?现有的方法通常遭受错误累积和遗忘(Error Accumulation and Forgetting)的问题,问题只出现在 Backward-based model 中。Error Accumulation:切换 domain 时性能会直接崩掉,因为 overfit 上⼀个 domain 的噪声。Forgetting:long-term update 导致遗忘 pre-trained model 的信息.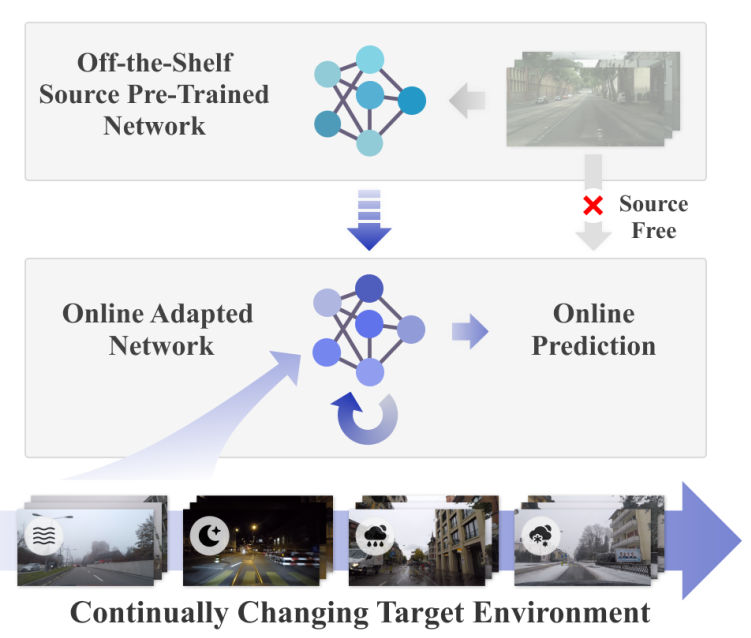
CoTTA 能使预先训练好的源模型适应不断变化的测试数据。它克服了现有方法的两个主要局限性。该方法的第一个组成部分旨在减少误差积累。CoTTA 采用了两种不同的方式来提高自训练框架下的伪标签质量。首先,使用了平均权重教师模型来提供更准确的预测,因为平均教师预测通常比标准模型具有更高的质量。其次,对于存在较大域差异的测试数据,使用增强平均预测来进一步提高伪标签的质量。该方法的第二部分旨在帮助保存源知识并避免遗忘。建议将网络中的一小部分神经元随机恢复到预先训练好的源模型中。通过减少误差积累并保留知识,CoTTA能够在不断变化的环境中进行长期适应,并实现对训练网络的所有参数的调整。
需要指出的是,权重平均和增强平均策略以及随机恢复可以轻松地整合到任何现有的预训练模型中,而无需重新训练源数据。这篇证明了我们提出的方法在四个分类任务和分割任务中的有效性,并显著提高了现有方法的性能。CoTTA 的贡献包括:
提出了一种持续测试时间自适应方法,能够使现有的预训练源模型有效适应不断变化的目标数据。
通过采用更准确的权重平均和增强平均伪标签,减少了误差积累。
通过明确保留源模型中的知识,缓解了长期遗忘效应。
CoTTA 详细介绍
给定一个现有的预训练模型 ,参数θ训练在源数据 上,我们的目标是在推理期间以不访问任何源数据的在线方式,使用持续更改的目标域,提高这个现有模型的性能。未标记的目标域数据 依次提供,模型只能访问当前时间步长的数据。在时间步 t,提供目标数据 作为输入,模型 需要进行预测 ,并相应地适应未来的输入 。 的数据分布也在不断变化。该模型是基于在线预测进行评估的。这种 setting 很大程度上是由于在不断变化的环境中对机器感知应用程序的需要。例如,由于位置、天气和时间的原因,自动驾驶汽车的周围环境正在不断变化。感知决策需要在网上(online)做出,模型需要进行调整。如下图所示,CoTTA 是一种在线连续测试时间自适应方法。该方法采用一个现成的源预训练模型,并以在线的方式适应不断变化的目标数据。由于误差积累是自训练框架中的关键瓶颈之一,CoTTA 建议使用权重平均和增强平均伪标签减少错误积累。此外,为了帮助减少持续适应中的遗忘,CoTTA 建议明确地保留从源模型中获得的信息。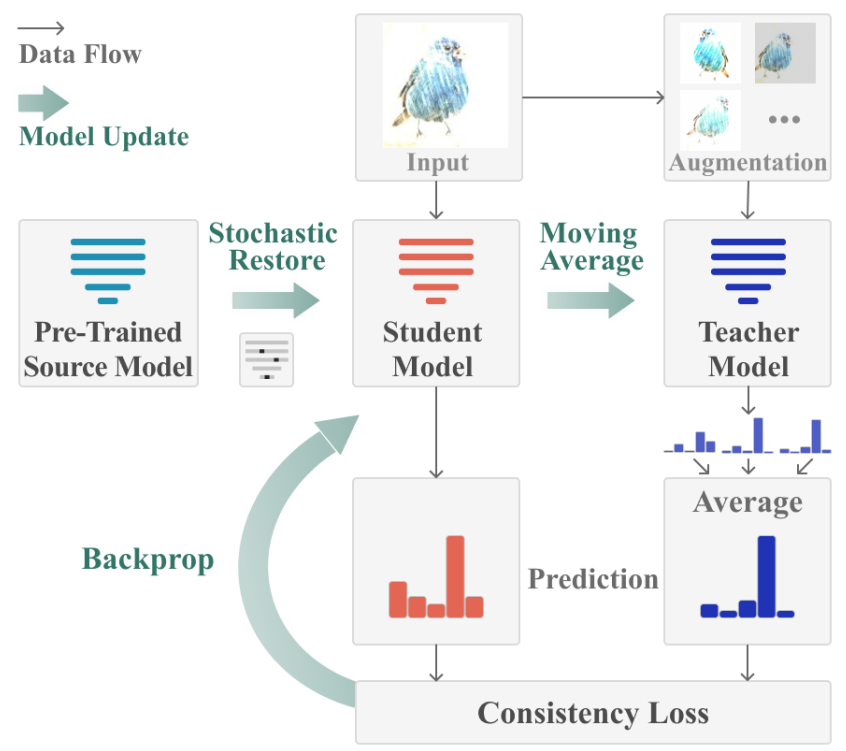 下面的部分将分别介绍 CoTTA 贡献中涉及到的三个内容。
下面的部分将分别介绍 CoTTA 贡献中涉及到的三个内容。
Weight-Averaged Pseudo-Labels
权重平均一致性的好处是双重的。一方面,通过使用通常更准确的权重平均预测作为伪标签目标,模型在连续适应过程中遭受较少的误差积累。另一方面,平均教师预测 编码了过去迭代中模型的信息,因此在长期持续适应中不太可能发生灾难性遗忘,提高了对新的看不见领域的泛化能力。这一步没什么可以进一步介绍的,受到了在半监督学习中提出的平均教师方法的启发。
Augmentation-Averaged Pseudo-Labels
数据增强是在训练期间对原始数据进行一系列变换和扩充的技术,旨在增加训练数据的多样性,从而提高模型的性能。研究人员通常手动设计或搜索适合不同数据集的增强策略。另外,经过证明,在测试期间进行数据增强也可以提高模型的鲁棒性,即对不同类型的输入能够更好地进行预测。然而,测试时间的增强策略通常是为特定数据集确定并固定的,没有考虑到推理期间数据分布的变化。在实际应用中,测试数据的分布可能会因为环境的不断变化而发生显著改变,这可能导致原先确定的增强策略失效。为了解决这个问题,这篇文章提出了一种考虑测试时间领域迁移的方法,并通过预测的置信度来近似领域之间的差异。只有当领域之间的差异较大时,才会应用增强技术,以减少由于错误累积而引起的问题。这种方法能够更好地适应不断变化的环境,提高模型在测试期间的性能和鲁棒性。
其中 是教师模型的增强平均预测, 是教师模型的直接预测, 是源预训练模型对当前输入 的预测置信度, 是一个置信阈值。通过使用上面中预先训练的模型 计算当前输入 的预测一致性,试图近似源和当前域之间的域差。假设,较低的置信度表示越大的域间隙,相对较高的置信度表示域间隙越小。因此,当置信度高且大于阈值时,我们直接使用 作为伪标签,而不使用任何增强。当置信度较低时,额外应用 N 个随机增强来进一步提高伪标签的质量。当观察到随机的增加时,过滤是关键的对于具有较小域间隙的自信样本,有时会降低模型的性能。总之,使用置信度来近似域的差异,并确定何时应用增强。
Stochastic Restoration
随机恢复可以被看作是一种特殊的 Dropout 形式。在这种方法中,网络通过随机地将可训练权重中的一小部分张量元素恢复到初始权重,以避免与初始源模型之间的差异过大,从而防止灾难性遗忘的发生。此外,通过保留源模型的信息,可以训练所有可训练参数而不会导致模型崩溃。这种方法可以有效地平衡源模型知识的保留和新数据的学习。上面这三个内容,都可以在 CoTTA 的框架图里找到。
实验
首先我们看下 CoTTA 在分类任务上的表现,从 CIFAR10 跨域到 CIFAR10C 的结果如下表,CIFAR10C 包括了各种可能下手动增加的噪声。
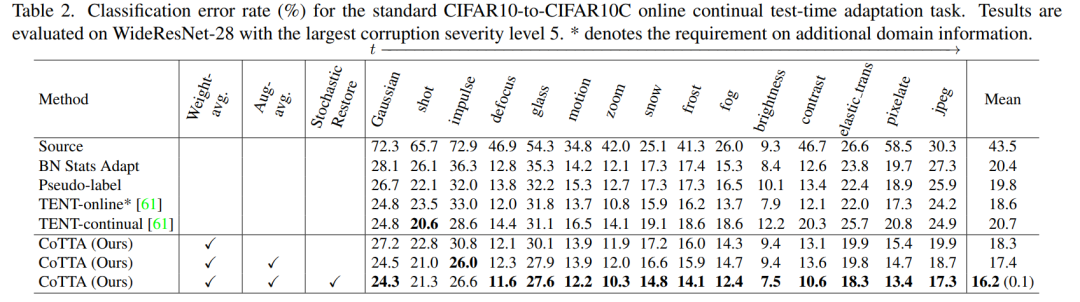 在这里插入图片描述
在这里插入图片描述
下表是 CoTTA 在分割任务上的表现,从 Cityscapes 跨域到 ACDC,包括雾天,夜晚,雨天和雪天四种不同的情况,从左到右时间步依次增长。
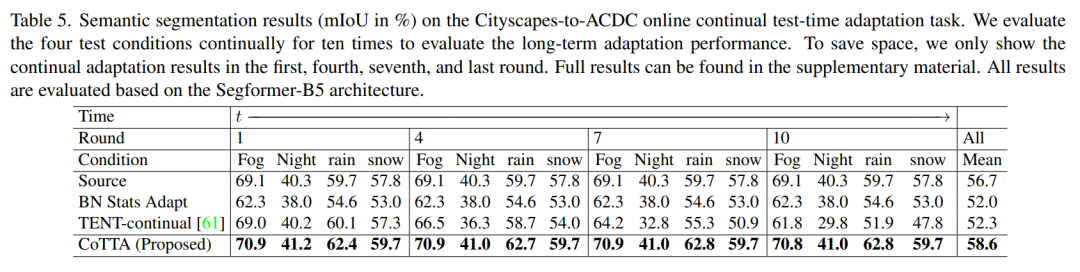 在这里插入图片描述
在这里插入图片描述
结论
该论文提出了一种名为 CoTTA 的新方法,用于在非平稳环境下进行持续的测试时间适应。在这种环境中,目标域的数据分布会随着时间的推移而不断变化。该方法由两个主要组成部分构成:一是使用权重平均和增强平均伪标签来减少误差的累积,二是通过随机地恢复一小部分权重到源预训练的权重,以保留源模型中的知识。CoTTA 方法可以方便地集成到现有的预训练模型中,而无需访问源数据。该方法的有效性在四个分类任务和一项针对持续测试时间适应的分割任务中得到了验证,并且在实验中表现出优于现有方法的性能。通过使用权重平均和增强平均伪标签来减少误差累积,CoTTA 方法能够更好地适应不断变化的目标分布。同时,通过随机恢复一小部分权重到源预训练权重,CoTTA 方法能够保留源模型中的知识,从而避免灾难性遗忘的问题。这项研究为在非平稳环境中进行持续的测试时间适应提供了一种有效的方法,并在实验中展示了其优越性,可以适应在一些 online 任务上。此外,在下一篇文章中我们将介绍 CVPR 2023 中的 EcoTTA: Memory-Efficient Continual Test-Time Adaptation via Self-Distilled Regularization,是基于 CoTTA 在内存上做的优化。
责任编辑:彭菁
-
用于窄带匹配高速射频ADC的全新方法2026-01-04 8320
-
VLSI系统设计的最新方法2023-11-20 698
-
安森美电感式位置感测新方法加快上市时间2022-12-21 1866
-
求大佬分享按键扫描的新方法2022-01-17 893
-
使用PIM分析仪测试连接器互调的新方法是什么?2021-05-10 3042
-
AD采集的新方法资料分享2018-03-23 1318
-
一种新的非平稳噪声环境下的噪声功率谱估计方法2018-03-13 1139
-
一种标定陀螺仪的新方法2016-08-17 4299
-
测电阻,新方法,不加激励2015-03-26 5711
-
运用于matlab中的矩阵求逆的新方法有哪些啊(不是函数inv)2013-01-21 10027
-
基于LabVIEW8.2提取ECG特征点的新方法2012-11-30 6903
-
矢量混频器表征和混频器测试系统矢量误差修正的新方法 白皮书2009-12-14 2764
-
高精度非接触测量转速新方法研究2009-09-03 579
-
虚拟环境中软体的包围盒更新方法分析2009-08-14 915
全部0条评论

快来发表一下你的评论吧 !
