

RISC-V处理器生态建设的实践
描述
虽然RISC-V 架构还不完善,在诸如安全、虚拟化架构、IOMMU/SMMU、中断控制架构、RAS(Reliability,Availability and Serviceability)等方面还刚起步,在代码密度(code size)、虚拟内存管理、原子操作效率等方面也还存在一些缺陷,但这不会妨碍 RISC-V 架构的长远向好发展,因为其开源的本质不曾改变。 回顾Linux 内核的发展历史,在 Linux 内核之前,IBM 的 Unix 收费操作系统无论在稳定性和用户体验上都是非常成功的,而相比之下刚出道的 Linux 内核无论在稳定性以及用户体验上都比较糟糕,但是由于 Linux 内核的开源属性迅速在 5 年时间内(1991 年到 1996 年)吸引了超过 350 万开发者的使用。 经过30年的发展,Linux 操作系统(基于 Linux 内核开发的各种操作系统)已经成为世界上最主流的操作系统之一(Windows 主要在桌面机,IOS/安卓主要在智能手机和平板电脑),无论在服务器、云计算以及嵌入式领域基本已是 Linux 内核的天下。 RISC-V 和 X86、ARM 的竞争完全是不同维度的竞争,他们三个分别是全球处理器技术演进在不同阶段的产物,而基本可以确定的是未来三种架构会长期共存,只是应用的侧重领域有所不同罢了。
入门级微控制器:E902
玄铁 E902 采用 2 级极简流水线并对执行效率进行了增强,典型工作频率>150MHz,是首款支持硬件安全扩展技术的 RISC-V 处理器。可以应用在对功耗和成本极其敏感的IoT、MCU 等场景。
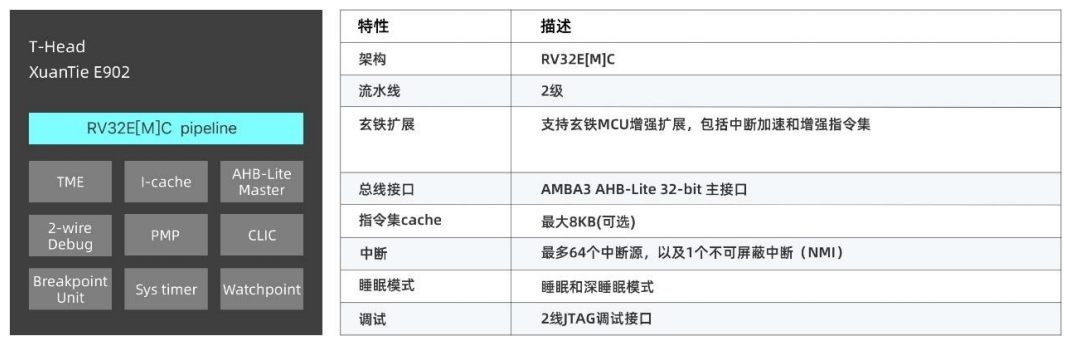
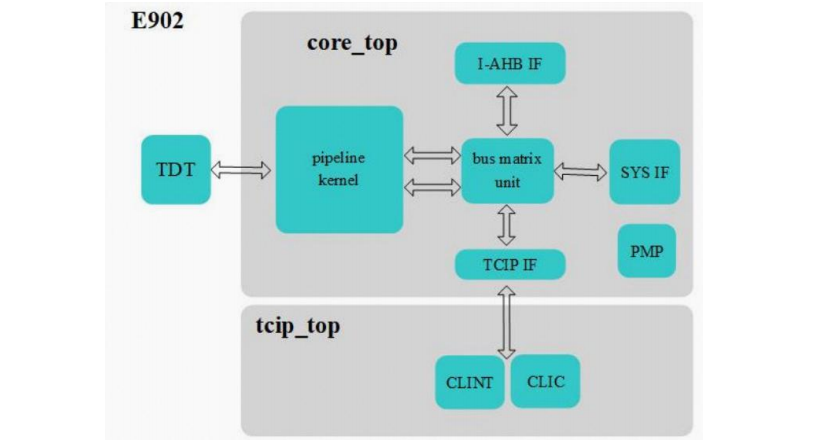
E902 处理器采用 2 级流水线结构:取指和执行。指令取指阶段主要负责从内存中获取指令;指令执行阶段主要负责指令译码、执行和回写。
高能效微控制器:E906
玄铁 E906 采用 5 级按序流水线,典型工作频率>1GHz,可选性能优异的单精度浮点单元以及标量 DSP 计算单元。可以应用在无线接入、音频、中高端 MCU、导航等场景。

E906 处理器采用 5 级流水线结构:取指、译码、执行、内存访问、写回。 ● 取指阶段,访问指令 Cache 或者总线,获取指令,同时访问 BTB,发起 0 延时跳转。 ● 译码阶段,访问动态分支预测器和返回栈,发起分支的预测跳转,同时进行指令译码,读取寄存器堆,处理数据相关性和数据前馈。 ● 执行阶段,完成单周期整型计算指令和多周期乘除法指令的执行、存储/加载指令地址计算和跳转指令处理。其中,整型计算包括普通的算术指令和逻辑指令。 ● 内存访问阶段,利用执行阶段产生的存储/载入指令的目标地址访问数据 Cache 或者总线。 ● 写回阶段,将指令执行结果写回寄存器堆。 E906 设计有片上紧耦合的 IP 接口和多条 AHB-Lite 的总线接口。片上紧耦合的 IP 接口集成矢量中断控制器(CLIC),支持中断嵌套。外部中断源数量最高可配置 240 个,中断优先级支持 4/8/16/32 级可配置。
计算增强型微控制器:E907
玄铁 E907 采用 5 级按序流水线,典型工作频率>1GHz,是玄铁 MCU 处理器中的性能最高的处理器核,可选配高性能浮点以及 DSP 计算单元,同时支持 TCM 扩展以及中断加速技术以进一步提升实时性。可以应用在语音入口 MCU、TWS、MPU、多模无线接入等场景。
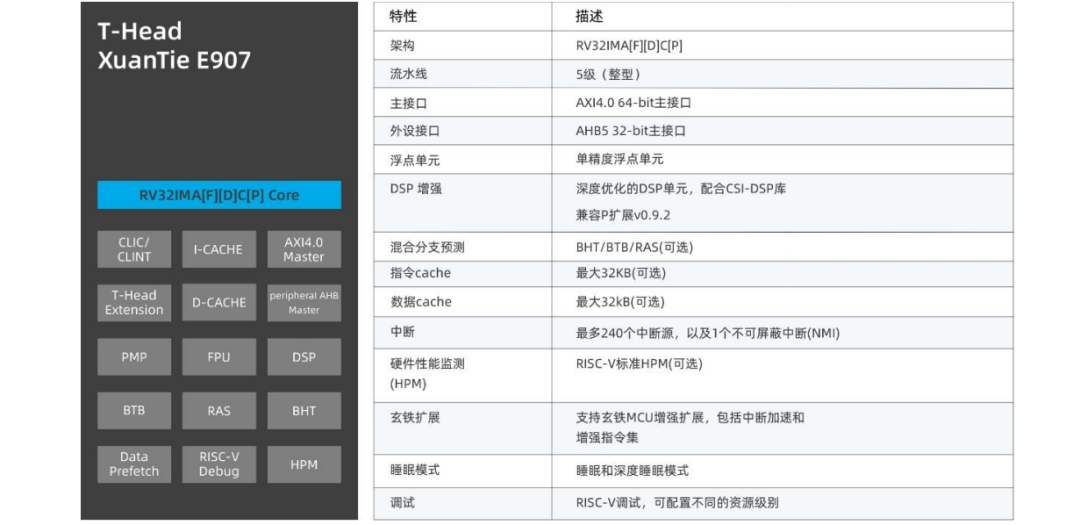
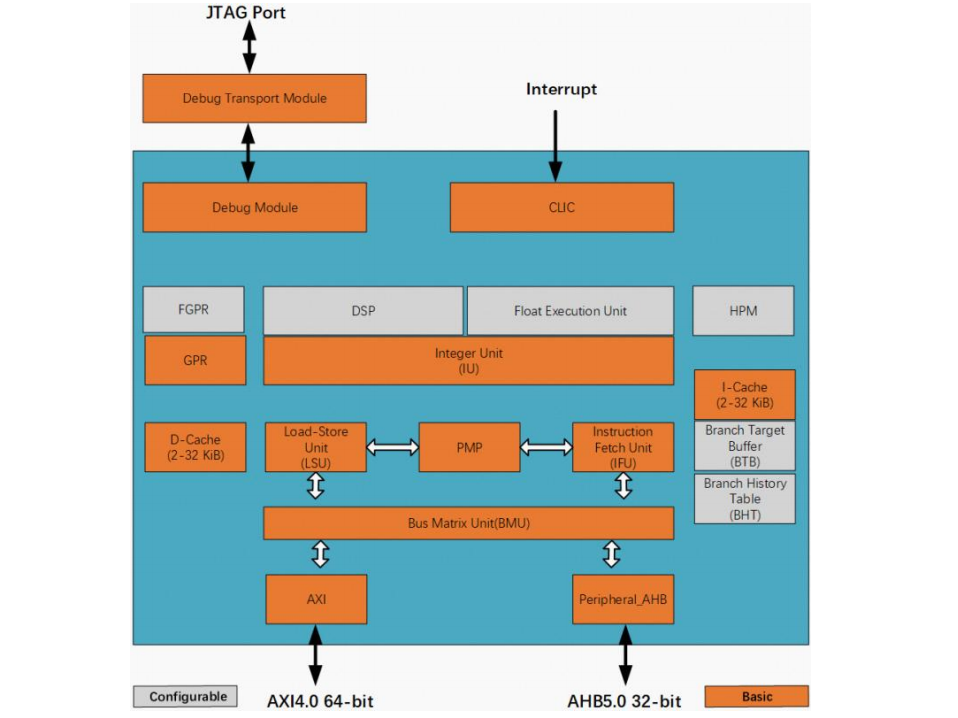
E907 处理器采用 5 级流水线结构:取指、译码、执行、内存访问、写回。 ● 取指阶段,访问指令 Cache 或者外部总线,获取指令,同时访问 BTB,发起 0 延时跳转。 ● 译码阶段,访问动态分支预测器和返回栈,发起分支的预测跳转,同时进行指令译码,读取寄存器堆,处理数据相关性和数据前馈。 ● 执行阶段,完成单周期整型计算指令和多周期乘除法指令的执行、存储/加载指令地址计算和跳转指令处理。其中,整型计算包括普通的算术指令和逻辑指令。 ● 内存访问阶段,利用执行阶段产生的存储/载入指令的目标地址访问数据 Cache 或者外部总线。 ● 写回阶段,将指令执行结果写回寄存器堆。 E907 设计有片上紧耦合的 IP 接口和两条主设备总线接口。片上紧耦合的 IP 接口集成矢量中断控制器(CLIC),支持中断嵌套。外部中断源数量最高可配置 240 个,中断优先级支持 4/8/16/32 级可配置。
高能效应用处理:C906
玄铁 C906 采用 5-8 级变长流水线,典型工作频率>1GHz,标配内存管理单元,可运行 Linux 等操作系统,并可选性能优异的单精度浮点和矢量运算单元。可以应用在消费类 IPC、多媒体、消费类电子等场景。

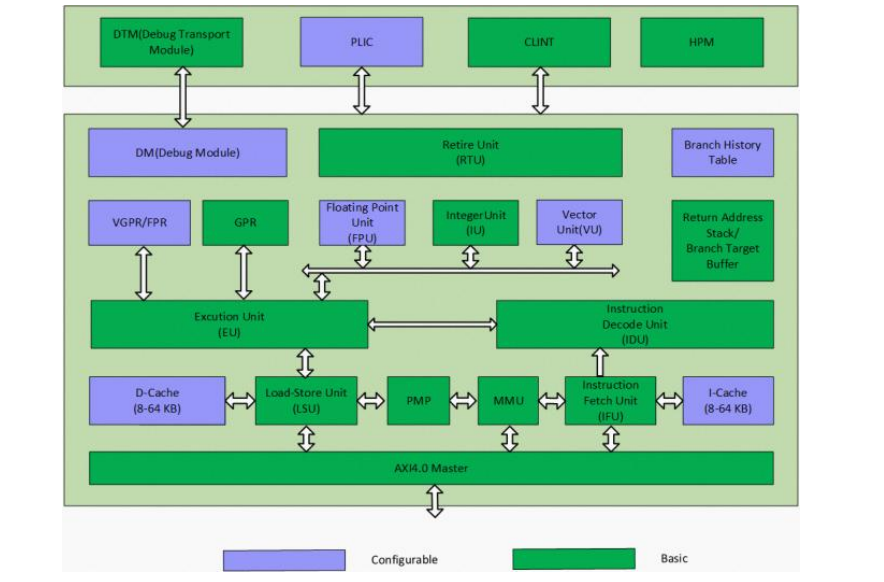
C906 核内子系统主要包含:指令提取单元(IFU)、指令译码单元(IDU)、整型执行单元(IU)、浮点单元(FPU)、可配的矢量执行单元(VPU)、存储载入单元(LSU)、指令退休单元(RTU)、虚拟内存管理单元(MMU)、物理内存保护单元(PMP)、主设备接口单元(AXI Master IF)等。
兼容 64 位高能效处理:C908
玄铁 C908 采用 9 级双发按序流水线,典型工作频率>2GHz,通过指令融合技术进一步提升流水线效率,实现了卓越的能效比。兼容 RVA22 标准,同时兼容 RISC-V 最新Vector1.0 标准以进一步提升 AI 算力。

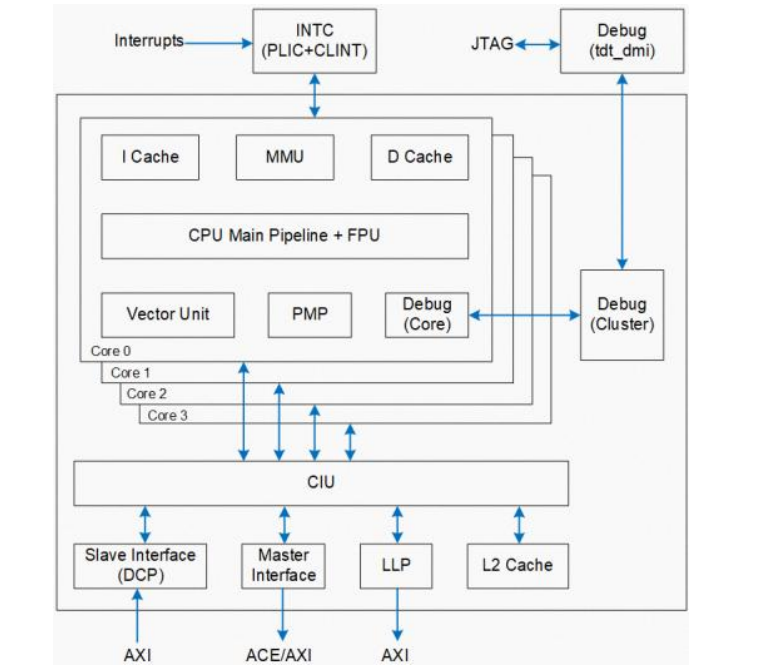
C908 核内子系统主要包含:指令提取单元(IFU)、指令执行单元(IEU)、矢量浮点执行单元(VFPU)、存储载入单元(LSU)、虚拟内存管理单元(MMU)和物理内存保护单元(PMP)。
高性能应用处理:C910
玄铁 C910 采用 12 级多发乱序流水线,典型工作频率>2.5GHz,是首款实现规模化量产的高性能乱序 RISC-V 处理器。采用 3 发射、8 执行的深度乱序执行架构,针对算术运算、内存访问以及多核同步等方面进行了增强。
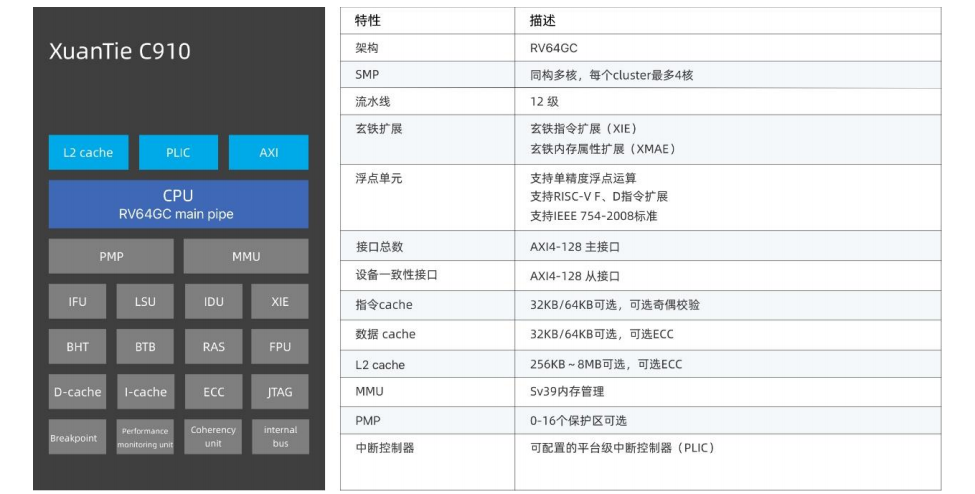
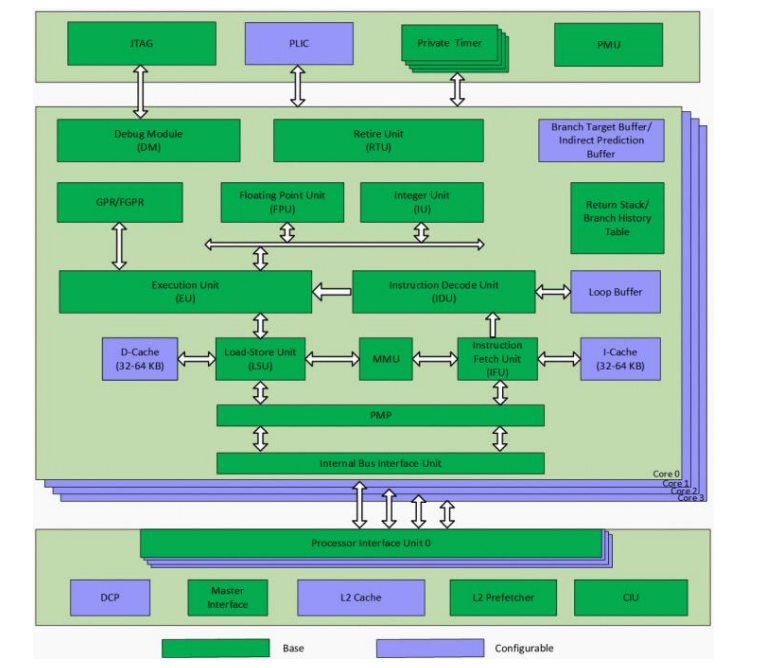
C910 核内子系统主要包含:指令提取单元(IFU)、指令译码单元(IDU)、整型执行单元(IU)、浮点单元(FPU)、存储载入单元(LSU)、指令退休单元(RTU)、虚拟内存管理单元(MMU)和物理内存保护单元(PMP)。 C910 多核子系统包含:数据一致性接口单元(CIU)、二级高速缓存、主设备接口单元、可配置的 AXI4.0 设备一致性接口(DCP,Device Coherence Port)、平台级中断控制器(PLIC)、计时器和自定义多核单端口调试框架。
AI 加速引擎:C920
玄铁 C920 采用 12 级多发乱序流水线,典型工作频率>2.5GHz,标配单精度浮点单元,并可进一步选配高性能乱序矢量运算单元。同时具备出色的访存能力,支持高性能数据预取技术。可以应用在有高并发算力要求的人工智能、自动驾驶等场景。
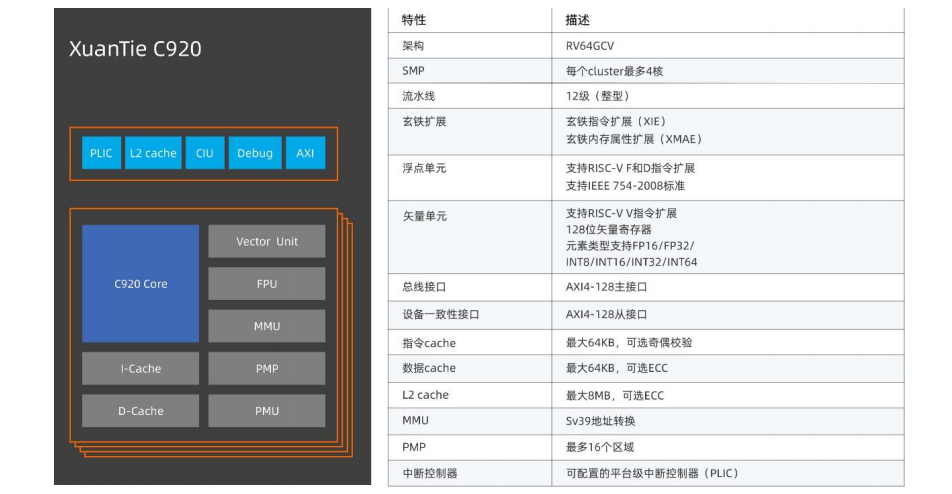
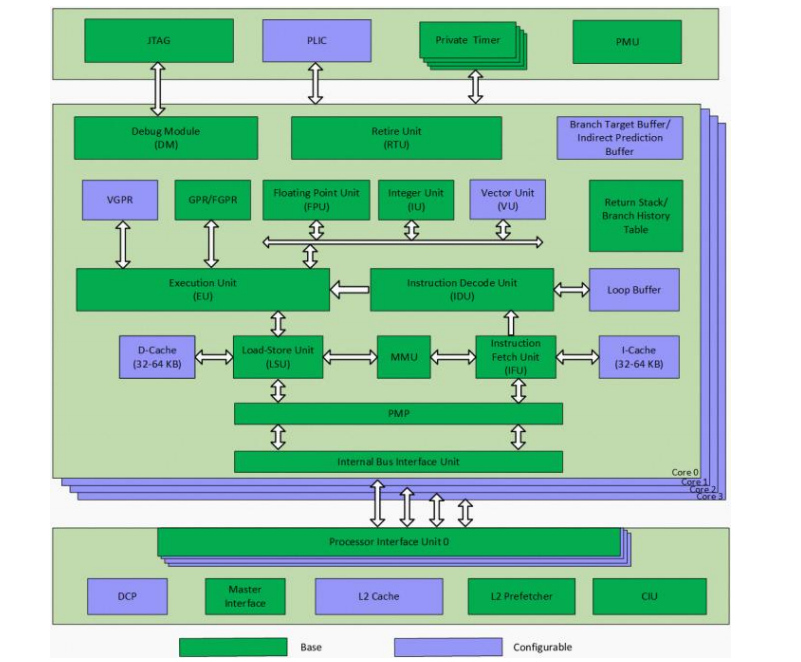
C920 核内子系统主要包含:指令提取单元(IFU)、指令译码单元(IDU)、整型执行单元(IU)、浮点单元(FPU)、矢量执行单元(VU)、存储载入单元(LSU)、指令退休单元(RTU)、虚拟内存管理单元(MMU)和物理内存保护单元(PMP)。 C920 多核子系统包含:数据一致性接口单元(CIU)、二级高速缓存、主设备接口单元、可配置的 AXI4.0 设备一致性接口(DCP,Device Coherence Port)、平台级中断控制器(PLIC)、计时器和自定义多核单端口调试框架。
可靠实时增强:R910
玄铁 R910 用 12 级多发乱序流水线,典型工作频率>2.5GHz,同时支持 Cache 以及TCM 存储架构,各级片上存储支持校验纠错以提升可靠性,可进一步选配快速外设接口以及一致性外设接口,从而大幅提升系统实时性。可以应用在对实时性及算力有高要求的企业级 SSD,网络通信等场景。

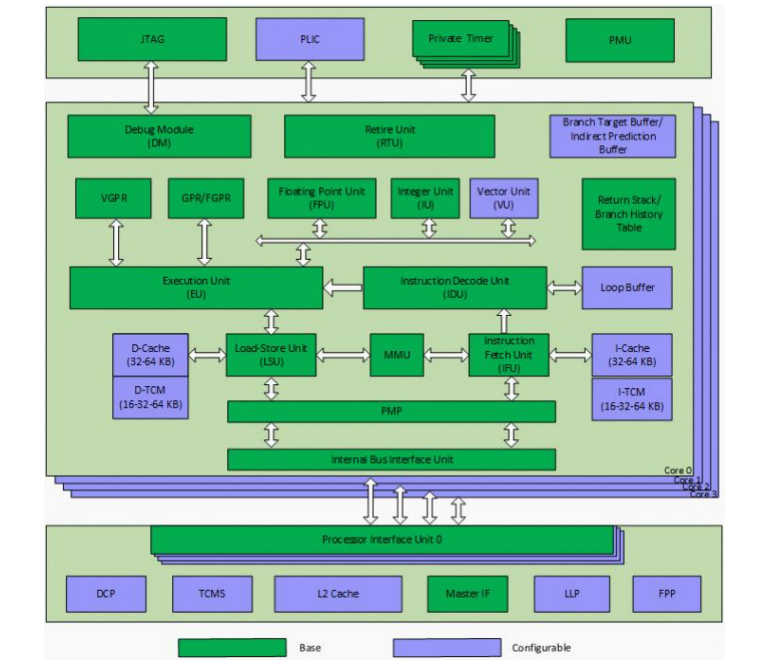
R910 核内子系统主要包含:指令提取单元(IFU)、指令译码单元(IDU)、整型执行单元(IU)、浮点单元(FPU)、存储载入单元(LSU)、指令退休单元(RTU)、虚拟内存管理单元(MMU)和物理内存保护单元(PMP)。 R910 多核子系统包含:数据一致性接口单元(CIU)、二级高速缓存、主设备接口单元、可配置的快速外设访问接口(LLP)、可配置的 APB 主设备接口(FPP)、可配置的紧耦合内存访问接口(TCMSP)、可配置的 AXI4.0 设备一致性接口(DCP,Device Coherence Port)、平台级中断控制器(PLIC)、计时器和自定义多核单端口调试框架。
-
深圳:“开源鸿蒙+RISC-V” 生态建设全面提速2025-11-04 1288
-
RISC-V 工具链的版本更新、开发动态及生态建设愿景2025-07-18 5329
-
RISC-V有哪些优缺点?是坚持ARM方向还是投入risc-V的怀抱?2024-04-28 2376
-
RISC-V走向高性能计算,开源生态建设突飞猛进2023-08-31 3339
-
Codasip的系列RISC-V处理器助力RISC-V生态建设2023-07-03 1787
-
RISC-V软件生态计划“RISE”启动,平头哥成中国大陆唯一董事会成员2023-06-02 1476
-
OHDC2023回顾03 | “芯” 星之火!面向RISC-V的OpenHarmony生态建设2023-04-21 1043
-
时擎科技研:RISC-V指令架构对智能芯片的赋能2023-03-31 834
-
RISC-V系列处理器的相关资料推荐2022-02-28 1471
-
如何建设RISC-V软件生态?2021-06-23 4530
-
RISC-V是什么?如何去设计RISC-V处理器?2021-06-18 2810
-
沙龙活动:蓬勃发展的RISC-V生态2021-03-08 6271
-
科普RISC-V生态架构(认识RISC-V)2020-08-02 7065
全部0条评论

快来发表一下你的评论吧 !
