

基于通用的模型PADing解决三大分割任务
描述
1. 研究动机
图像分割旨在将具有不同语义的像素进行分类进而分组,例如类别或实例,近年来取得飞速的发展。然而,由于深度学习方法是数据驱动的,对大规模标记训练样本的强烈需求导致了巨大的挑战,这些训练数据需要消耗巨大的时间以及人力成本。为处理上述难题,零样本学习(Zero-Shot Learning,ZSL)被提出用于分类没有训练样本的新对象,并扩展到分割任务中,例如零样本语义分割(Zero-Shot Semantic Segmentation, ZSS)和零样本实例分割(Zero-Shot Instance Segmentation, ZSI)。在此基础上,本文进一步引入零样本全景分割(Zero-Shot Panoptic Segmentation, ZSP)并旨在利用语义知识构建一个通用的零样本全景/语义/实例分割框架,如图1所示。
本文从为未知类别生成更好的伪特征出发来设计一个通用的模型PADing解决三大分割任务。针对通用分割存在的共性问题:视觉与语言差异以及类别偏见问题,旨在实现对于新类别的全景、实例和语义分割。本文基于零样本通用分割方法PADing开展定量实验和定性可视化,研究结果表明,相对于主流方法,该方法在定量实验结果和定性可视化结果方面表现出色。
本文贡献主要包括以下四点:
研究了通用的零样本分割问题,并提出了一种名为基于协作关系对齐和特征解耦学习的基元生成(Primitive generation with collaborative relationship Alignment and feature Disentanglement learning,PADing)的统一框架来处理零样本语义分割、实例分割和全景分割问题。
提出了一种基元生成器,它使用许多带有细粒度属性的学习基元来合成未见过类别的视觉特征,有助于解决偏差问题和域间差距问题。
提出了一种协作关系对齐和特征解耦学习方法,以促进生成器产生更好的合成特征。
提出的方法PADing在零样本全景分割(ZSP)、零样本实例分割(ZSI)和零样本语义分割(ZSS)上取得了新的最先进性能。
2. 方法
2.1 方法概述
本文提出的方法基于协作关系对齐和特征解耦学习的基元生成PADing,其总体架构如图2所示。首先,Backbone预测了一组与类无关的掩码及其相应的类向量。接着,基元生成器经过训练,可以从语义向量中合成类向量。然后,将真实的与合成类向量被分解为与语义相关和与语义无关的特征,并在语义相关的特征上进行关系对齐学习。最后,通过合成未知类别的向量,用实际已知类别的真实向量和未知类别的合成向量进行重新微调训练分类器。
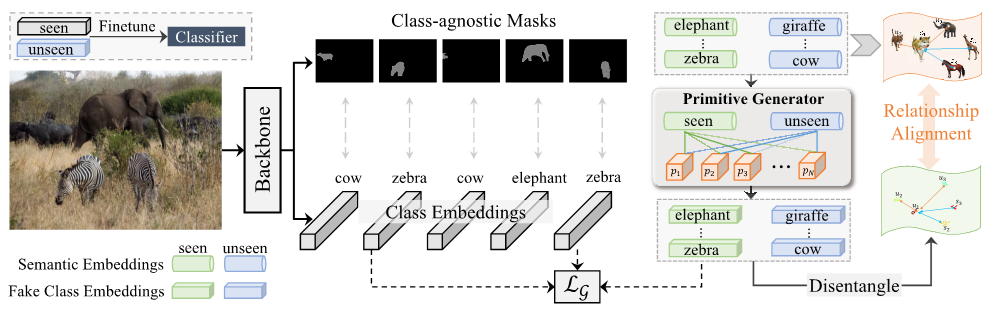
图2: PADing框架结构图
2.2 基元跨模态生成
由于缺乏未知类别的样本,分类器不能使用未知类别的特征进行优化。因此,仅使用已知类别的特征进行训练的分类器往往会将所有对象标记为已知类别,这称为偏置问题。先前的方法提出利用生成模型来为未知类别合成假的视觉特征。虽然达到了良好的性能,但并未考虑特征粒度的视觉-语义差异。众所周知,图像通常包含比语言更丰富的信息。视觉信息提供了对象的非常精细的属性,而文本信息通常提供抽象和高级别的属性。这种差异导致了视觉特征和语义特征之间的不一致。为了解决这一挑战,本文提出了一个基于基元的跨模态生成器,利用大量学习到的属性基元来构建视觉表示。
先初始化一堆可学习的基元,希望它能学习到细粒度的信息,具体的方法是利用Transformer将语义向量和基元组都输入到网络中,首先语义向量先与基元组计算相似度,选择其与语义向量最为相关型的基元后并加入高斯噪声。这样就得到由基元组成的特征,当输入一个语义向量,能输出生成相应的视觉向量。最后用MMD损失来拉近这两个生成与真实的视觉向量特征。基元就像是语言与视觉之间的桥梁,消除两者之间的域内差异。
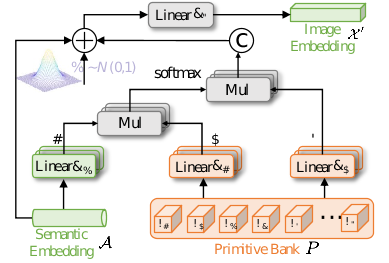
图3: 基元跨模态生成的结构示意图
2.3 语义-视觉关系对齐
众所周知,类别之间的关系自然上是不同的。例如,有三个对象:苹果、橙子和奶牛。显然,苹果和橙子之间的关系比苹果和奶牛之间的关系更紧密。语义空间中的类别关系是强大的先验知识,而类别特定的特征生成并没有明确利用这种关系。也就是语义空间中关系相近的物体,在视觉空间也应该相近,具有相似的分布。但通常的方法一般直接将语义空间的关系暴力地迁移到视觉空间中。这样并不能有效的利用语义关系,因为语义和视觉本来就不是相互对齐的空间,视觉特征包含更多信息,而语义特征可以看作是信息的浓缩。也就是视觉特征中多了多余的信息。所以本文考虑到了将视觉特征进行解耦之后再进行关系对齐。解耦的方法也就是分成了语义相关特征与语义无关特征,然后将视觉的语义相关特征再与语义特征对齐。语义无关特征希望其符合正态分布刻画着没有具体语义信息的特征。而语义相关特征需要其能通过特征将其分到指定语义信息中。
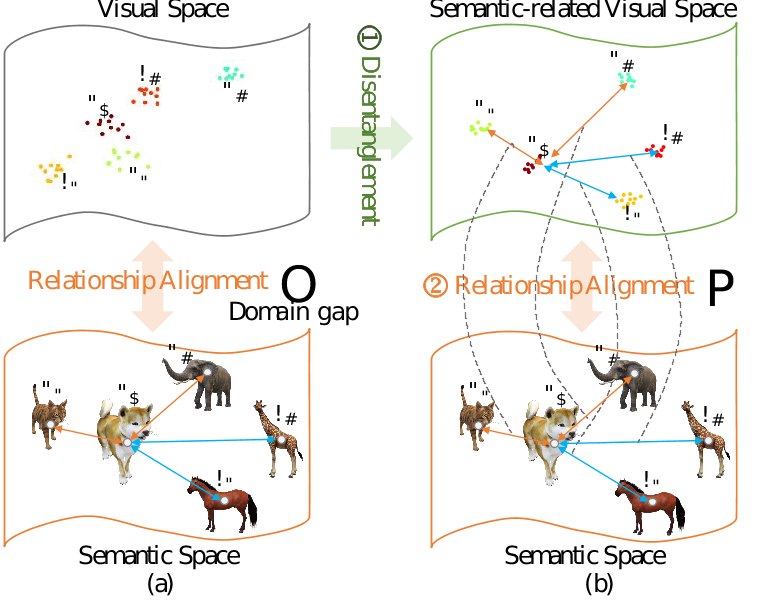
图4: 语义-视觉关系对齐示意图
3. 实验
3.1 定量结果实验
为了验证本文方法的有效性,在COCO数据上针对全景分割、实例分割、语义分割上进行了对比实验,见表1、2、3。实验结果表明,本文方法PADing取得先进的性能。
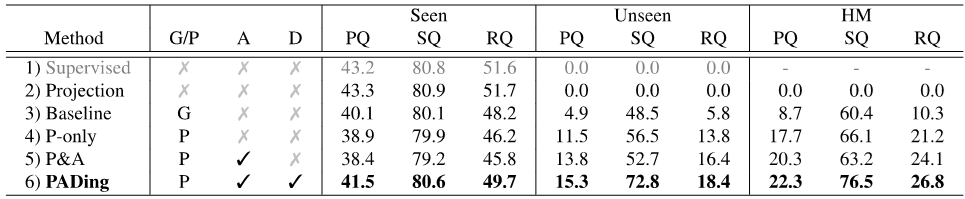
表1: 零样本全景分割结果
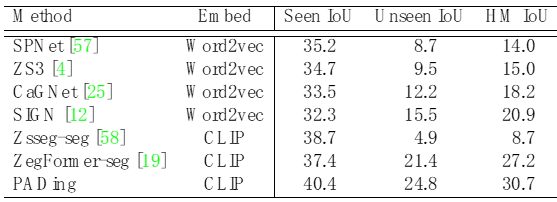
表2: 零样本语义分割结果
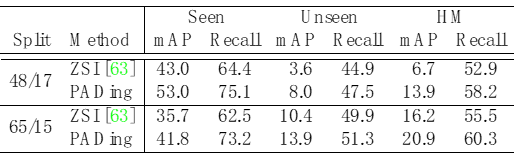
表1: 零样本实例分割结果
3.2 定性结果实验
为了探究基元是否可以代表细微的细节元素,图5可视化不同基元在图片上的注意力响应。结果表明基元可以代表不同细粒度的属性,例如在图中的猫作为例子:关注到了耳朵、尾巴以及轮廓。
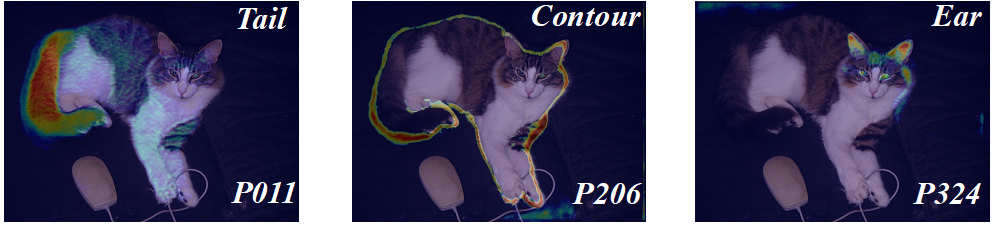
图5: 基元注意力响应图
为了研究本文合成的未见特征的属性,并展示本章提出的方法的有效性,图6使用 t-SNE来展示合成的未知特征的分布情况。(a)由 GMMN 生成器生成的合成特征由于语义-视觉差异而杂乱无序。(b)引入了本文的基元生成器,同一类别的特征变得更加紧密,不同类别的特征则高度可分。此外,在语义相关特征上应用关系对齐约束后,(c),不同类别的特征相距更远,分布结构更好,这表明结构关系已经嵌入到合成的特征中,合成的未见特征大大增强了较好的区分性。
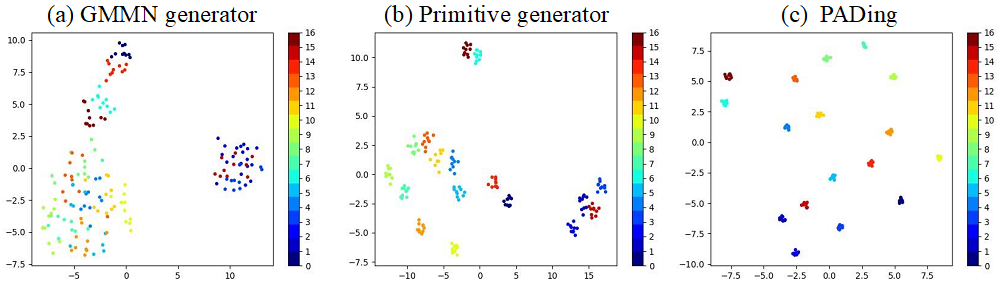
图6: 不同生成器生成未知类别特征分布图
图7定性可视化了零样本通用分割结果的例子,结果表明我们的方法可以取得很好的效果。

图7: 零样本通用分割(全景、实例、语义分割)可视化结果
4. 总结
本文针对零样本通用分割中存在的视觉与语言差异以及类别偏见问题,提出了基元生成、协作关系对齐与特征解耦学习的统一框架(PADing),以实现高效、实用的零样本通用分割。首先,提出了基元生成器,用于合成未知类别的伪训练特征。接着,提出了协作的特征解耦和关系对齐学习策略,帮助生成器产生更好的伪未知特征,前者将视觉特征解耦为语义相关部分和语义不相关部分,后者将跨类知识从语义空间传输到视觉空间。PADing在三个零样本分割任务,包括语义、实例和全景分割上进行的广泛实验,都取得了最先进的结果。
责任编辑:彭菁
-
通过任务分割提高嵌入式系统的实时性2009-05-15 503
-
基于多级混合模型的图像分割方法2009-07-08 661
-
基于改进活动轮廓模型的图像分割2017-01-07 704
-
基于三维模型球型分割的信息隐藏算法2017-11-28 970
-
聚焦语义分割任务,如何用卷积神经网络处理语义图像分割?2018-09-17 1037
-
基于预测算法实现模型的最优在线任务分配2021-03-22 1347
-
通用航空器运行排班及维修任务的优化模型2021-04-22 1022
-
基于遥感数据的海岛边界快速分割模型2021-06-11 975
-
在NGC上玩转图像分割!NeurIPS顶会模型、智能标注10倍速神器、人像分割SOTA方案、3D医疗影像分割利器应有尽有2022-11-21 1955
-
通用视觉GPT时刻来临?智源推出通用分割模型SegGPT2023-04-09 2285
-
SAM分割模型是什么?2023-05-20 3990
-
近期分割大模型发展情况2023-05-22 2365
-
中科院提出FastSAM快速分割一切模型!比Meta原版提速50倍!2023-06-28 2817
-
三项SOTA!MasQCLIP:开放词汇通用图像分割新网络2023-12-12 1953
-
图像分割与语义分割中的CNN模型综述2024-07-09 3479
全部0条评论

快来发表一下你的评论吧 !
