

Linux内核同步机制原子操作详解
嵌入式技术
描述
Linux内核同步机制原子操作
变量的修改
我们平时的编程中可能经常需要修改变量和寄存器,大概是这样操作的:
- 读一个位于memory中的变量的值然后写到寄存器中
- 修改该变量的值
- 将寄存器中的值写回memory中的变量值 如果这三个步骤是串行化的,并且是在一个线程中串行执行,那么这样做是没有问题的,然而,世界中的事情总是不能如你所愿。在多CPU体系架构中,运行在两个CPU上的两个内核控制路径同时并行执行上面操作序列,有可能发生下面的场景:
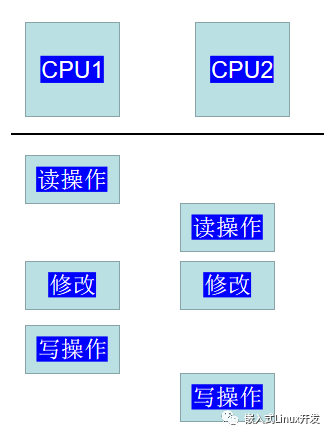

CPU和内存是通过总线进行互联的,在任意时刻,只能有一个CPU访问内存。因此,来自两个CPU上的读内存操作被串行化执行,分别获得了同样的旧值。完成修改后,两个CPU都想进行写操作,把修改之后的值写回到内存。但是,CPU的写回操作也必须是串行化的,因此CPU1首先获得了访问权,进行写回动作,随后,CPU2完成写回动作。在这种情况下,CPU1的对内存的修改被CPU2的写操作覆盖了,因此执行结果是错误的。
不仅是多CPU会存在这种问题,在单CPU上也会由于内核控制路径的交错导致上面的错误。一个简单的例子就是中断:
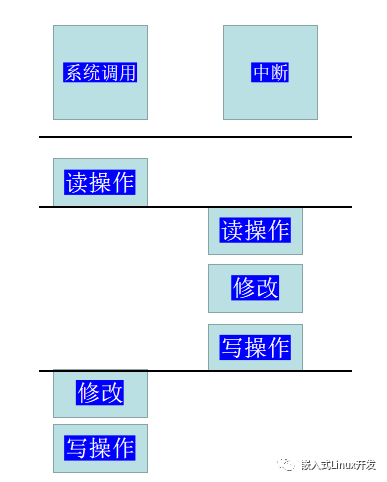
系统调用的控制路径上,完成读操作之后,硬件触发中断,开始执行中断处理函数。中断处理函数的写回操作被系统调用控制路径上的写回操作覆盖了,导致结果不一致。
正确的操作
对于那些有多个内核控制路径进行读-修改-写回的变量,内核提供了一个特殊的类型atomic_t,具体定义如下:
typedef struct {
int counter;
} atomic_t;
从定义上来看,atomic_t实际上就是一个int类型的变量counter,内核中定义了很多关于atomic_xxx的接口函数,这些函数只会接收atomic_t类型的参数。这样就确保了atomic_xxx的函数只会操作atomic_t类型的数据。
内核中具体的接口API函数如下:
| 接口函数 | 功能描述 |
|---|---|
| static inline void atomic_add(int i, atomic_t *v) | 原子变量v增加i |
| static inline void atomic_sub(int i, atomic_t *v) | 原子变量v减去i |
| static inline void atomic_inc(atomic_t *v) | 原子变量增加1 |
| static inline void atomic_dec(atomic_t *v) | 原子变量减去1 |
| static inline int atomic_read(const atomic_t *v) | 读取原子变量的值 |
| static inline void atomic_set(atomic_t *v, int i) | 设置原子变量的值 |
| static inline int atomic_dec_and_test(atomic_t *v) | 原子变量的值减去1,判断原子变量的值是否等于0 |
| static inline int atomic_cmpxchg(atomic_t *v, int oldval, int newval) | 比较oldval的值和原子变量v的值是否相等,如果相等,把newval的值赋值给原子变量v |
底层实现原理
ARMv6之前的CPU并不支持SMP架构,之后的ARM架构都是支持SMP架构的。内核中关于原子操作的实现通过#if __LINUX_ARM_ARCH__ >= 6条件变量进行区分。ARMv6之前的实现原理是通过关闭CPU中断实现的,ARMv6之后的实现是通过新增加的两个CPU指令ldrex、strex实现的。 通过下面的代码可以具体的看到实现的细节:
prefetchhw是预取操作和cache有关,主要是为了提高性能。__volatile__主要是用来防止编译器优化的。在编译c代码的时候,如果使用优化选项(-O)进行编译,对于那些没有声明__volatile__的嵌入式汇编代码,编译器有可能会对其进行编译优化,编译的结果可能不是原来的汇编代码,有了__volatile__之后,编译器就会停止对该段代码的任何优化。
独占访问指令ldrex和strex
ldrex/strex是ARMv6架构及之后架构的同步原语,属于硬件层面的同步机制。只要某个时刻只允许一个执行单元访问共享资源那么就必须进行同步,共享资源可以是内存、外设设备,执行单元可以是处理器、进程或者线程。
ldrex/strex这两个指令配合独占监控器(独占监控器会跟踪独占内存访问)可以实现原子地更新内存数据。
ldrex R1, [R0]
ldrex指令从R0寄存器表示的地址中读取一个字,存放在R1寄存器中,并且更新独占监控器状态为独占状态
strex < Rd >, < Rt >, [< Rn >]
strex指令存储一个字到内存中,但是这个存储指令是有条件的,如果独占监控器允许这个存储操作,那么对应的内存地址就会更新,并且将返回值0保存在目标寄存器中,代表此次操作成功。如果独占监控器不允许存储操作,那么就不会更新独占监控器,并且将返回值1保存在目标寄存器中,代表此次操作失败。
独占监控器
在上面的描述中我们提到独占监控器,独占监控器是一种简单的状态机,有两种状态:打开或者独占。为了实现多个处理器间的同步,一般会存在两类独占监控器:本地监控器和全局监控器。
"1: ldrex %0, [%3]\\n"其中%3就是input operand list中的"r" (&v->counter),r是限制符(constraint),用来告诉编译器gcc,选择一个通用寄存器保存该操作数。%0对应output openrand list中的"=&r" (result),=表示该操作数是write only的,&表示该操作数是一个earlyclobber operand,编译器在处理嵌入式汇编的时候,倾向于使用尽可能少的寄存器,如果output operand没有&修饰的话,汇编指令中的input和output操作数会使用同一个寄存器。&确保了%3和%0使用不同的寄存器。现在%0这个output操作数已经被赋值为atomic_t变量的old value,毫无疑问,这里的操作是要给old value加上i。这里%4对应"Ir" (i),这里“I”表示这是一个有特定限制的立即数,该数必须是0~255之间的一个整数通过rotation的操作得到的一个32bit的立即数。每个指令32个bit,其中12个bit被用来表示立即数,其中8个bit是真正的数据,4个bit用来表示如何rotation。这一步将修改后的new value保存在atomic_t变量中。是否能够正确操作的状态标记保存在%1操作数中,也就是"=&r" (tmp)。最后检查memory update的操作是否正确完成,如果发生了问题,需要跳转到lable 1那里,重新进行一次read-modify-write的操作。
#define ATOMIC_OP(op, c_op, asm_op) \\
static inline void atomic_##op(int i, atomic_t *v) \\
{ \\
unsigned long tmp; \\
int result; \\
\\
prefetchw(&v- >counter); \\
__asm__ __volatile__("@ atomic_" #op "\\n" \\
"1: ldrex %0, [%3]\\n" \\
" " #asm_op " %0, %0, %4\\n" \\
" strex %1, %0, [%3]\\n" \\
" teq %1, #0\\n" \\
" bne 1b" \\
: "=&r" (result), "=&r" (tmp), "+Qo" (v- >counter) \\
: "r" (&v- >counter), "Ir" (i) \\
: "cc"); \\
}
#define ATOMIC_OP(op, c_op, asm_op) \\
static inline void atomic_##op(int i, atomic_t *v) \\
{ \\
unsigned long flags; \\
\\
raw_local_irq_save(flags); \\
v- >counter c_op i; \\
raw_local_irq_restore(flags); \\
}
总结
本篇主要介绍了Linux内核的同步机制之一原子操作,从原子的操作的API接口到原子操作的底层实现原理,进行了简单分析。
-
Linux内核同步机制mutex详解2023-06-26 2090
-
浅谈Linux kernel中的同步机制2023-05-04 1884
-
关于Linux kernel同步机制的这些知识点你不得不知道2023-04-21 1616
-
详解linux内核中的mutex同步机制2022-05-13 8126
-
Linux内核GPIO操作函数的详解分析2021-01-22 1129
-
Linux内核的同步机制2020-09-22 3325
-
Linux内核中有哪些锁2020-02-24 4081
-
Linux内核同步机制2019-08-06 1399
-
可以了解并学习Linux 内核的同步机制2019-05-14 1117
-
你了解Linux内核的同步机制?2019-05-12 1019
-
你知道linux 同步机制的complete?2019-04-24 1860
-
Linux内核同步机制之原子操作2018-12-13 3496
-
linux内核机制有哪些2017-11-14 5984
-
linux内核rcu机制详解2017-11-13 9485
全部0条评论

快来发表一下你的评论吧 !
