

如何设计一个高效的分布式日志服务平台
描述
GEEK TALK
01
分布式服务下日志服务挑战
分布式服务系统中,每个服务有大量的服务器,而每台服务器每天都会产生大量的日志。我们面临的主要挑战有:
1、日志量巨大:在分布式服务环境中,日志分散在多个节点上,每个服务都会产生大量的日志,因此需要一种可靠的机制来收集和聚合日志数据。
2、多样化的日志格式:不同的服务可能使用不同的日志格式,例如日志输出的字段、顺序和级别等,这会增加日志服务的开发和维护难度。
3、日志服务的可扩展性和可靠性:随着分布式服务数量的增加和规模的扩大,日志服务需要能够进行横向扩展和纵向扩展,以保证其性能和可靠性。
所以我们该如何提供分布式系统下高效、低延迟、高性能的日志服务呢?
GEEK TALK
02
业内ELK通用解决方案
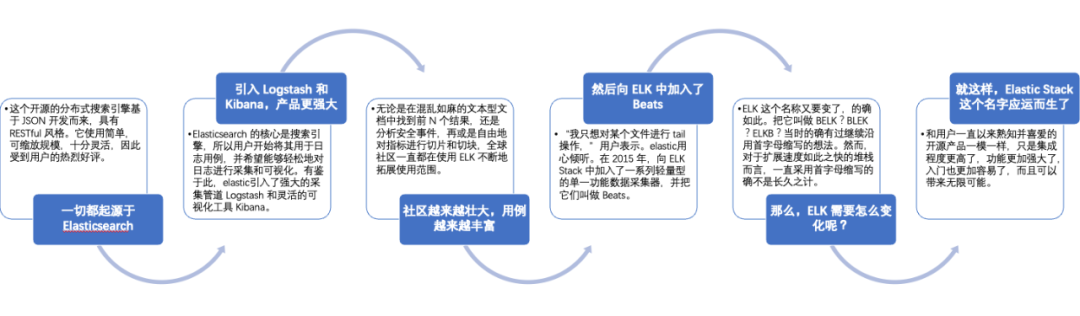
2.1 Elastic Stack发展历程
2.2 Elastic Stack组件架构图
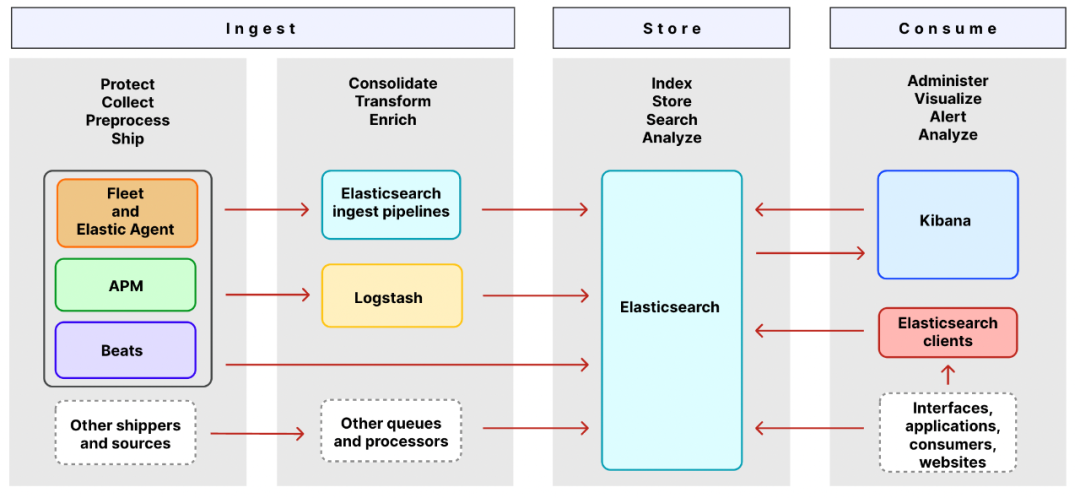
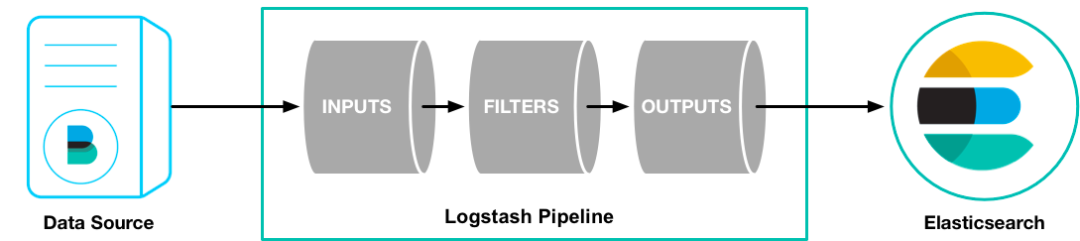
2.2.1 Ingest组件
Ingest 是获取日志数据的相关组件。
shippers 和 sources 是收集的原始日志组件,承接着原始日志(log文件日志、系统日志、网络日志等)采集和发送,其中 Elastic Agent、APM、Beats 收集和发送日志、指标和性能数据。
queues 和 processors 是原始日志数据的处理管道,使用这些组件可以定制化的对原始日志数据进行处理和转换,在存储之前可以模板化数据格式,方便elasticsearch更好的承接存储和检索功能。
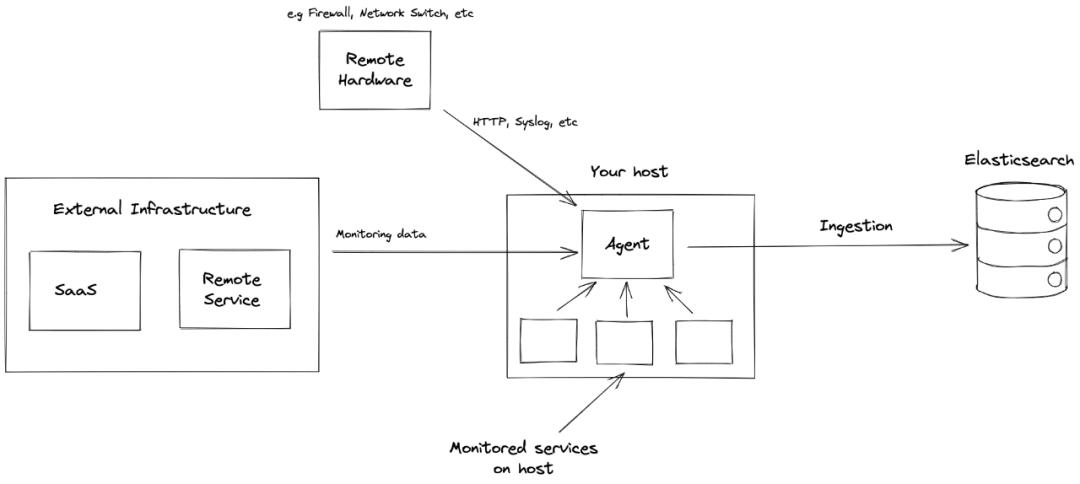
Elastic Agent 是一种使用单一、统一的方式,为主机添加对日志、指标和其他类型数据的监控。它还可以保护主机免受安全威胁、从操作系统查询数据、从远程服务或硬件转发数据等等。每个代理都有一个策略,可以向其中添加新数据源、安全保护等的集成。
Fleet 能够集中管理Elastic Agent及其策略。使用 Fleet 可以监控所有 Elastic Agent 的状态、管理agent策略以及升级 Elastic Agent 二进制文件或集成。
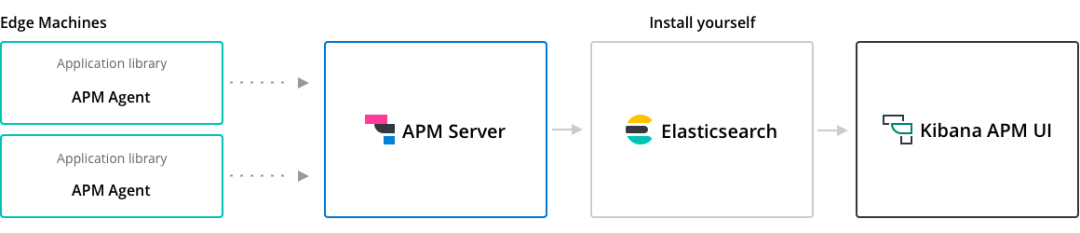
Elastic APM 是一个基于 Elastic Stack 构建的应用程序性能监控系统。通过收集有关传入请求、数据库查询、缓存调用、外部 HTTP 请求等响应时间的详细性能信息,实时监控软件服务和应用程序。
Beats 是在服务器上作为代理安装的数据发送器,用于将操作数据发送到 Elasticsearch。Beats 可用于许多标准的可观察性数据场景,包括审计数据、日志文件和日志、云数据、可用性、指标、网络流量和 Windows 事件日志。
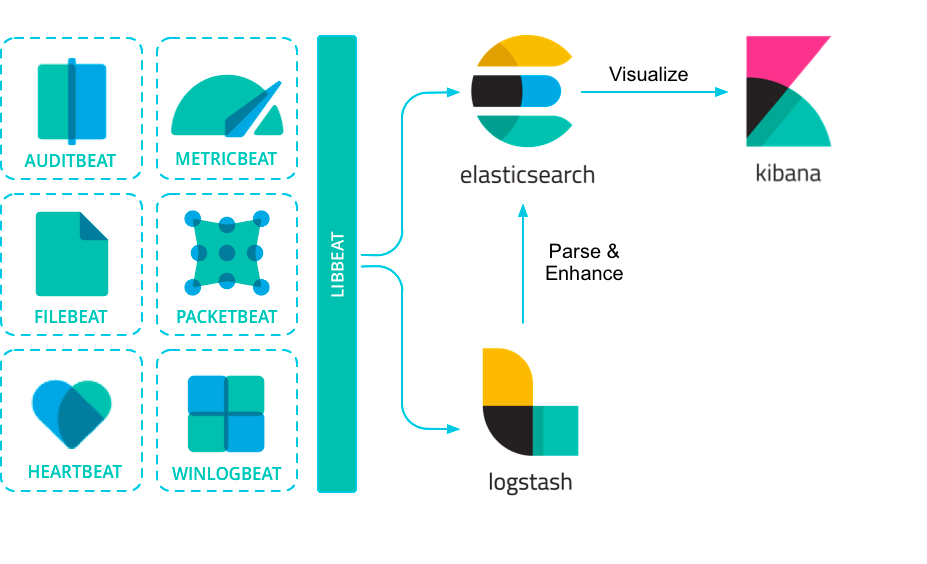
Elasticsearch Ingest Pipelines 可以在将数据存储到 Elasticsearch 之前对数据执行常见的转换。将一个或多个“处理器”任务配置为按顺序运行,在将文档存储到 Elasticsearch 之前对文档进行特定更改。
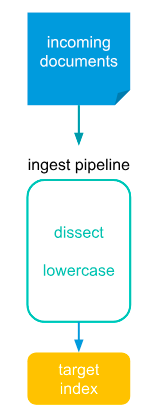 Logstash 是一个具有实时数据收集引擎。它可以动态地统一来自不同来源的数据,并将数据规范化到目的地。Logstash 支持丰富的输入、过滤器和输出插件。
Logstash 是一个具有实时数据收集引擎。它可以动态地统一来自不同来源的数据,并将数据规范化到目的地。Logstash 支持丰富的输入、过滤器和输出插件。
2.2.2 Store组件
Store 是承接日志存储和检索组件,这里是使用的Elasticsearch承接该功能。Elasticsearch 是 Elastic Stack 核心的分布式搜索和分析引擎。它为所有类型的数据提供近乎实时的搜索和分析。无论结构化或非结构化文本、数字数据还是地理空间数据,Elasticsearch 都可以以支持快速搜索的方式高效地存储和索引这些数据。Elasticsearch 提供了一个 REST API,使您能够在 Elasticsearch 中存储和检索数据。REST API 还提供对 Elasticsearch 的搜索和分析功能的访问。2.2.3 Consumer组件
Consumer 是消费store存储数据的组件,这里组要有可视化的 kibana 和 Elasticsearch Client。Kibana 是利用 Elasticsearch 数据和管理 Elastic Stack 的工具。使用它可以分析和可视化存储在 Elasticsearch 中的数据。
Elasticsearch Client 提供了一种方便的机制来管理来自语言(如 Java、Ruby、Go、Python 等)的 Elasticsearch 的 API 请求和响应。

2.3 天眼对比ELK差异
1、接入便捷性
ELK:方案依赖完整流程部署准备,操作配置复杂,接入跑通耗时长。
天眼:只需简单三步配置,页面申请产品线接入、页面获取产品线appkey、依赖管理中增加天眼SDK依赖并配置appkey到系统配置中。
2、资源定制化
ELK:资源修改、配置每次都需要重启才能生效,不支持多资源配置化选择。
天眼:产品线接入时可以选择使用业务自身传输、存储资源或自动使用系统默认资源,资源切换只需页面简单配置并即时自动生效。
3、扩容成本与效率
ELK:方案仅支持单个业务产品线,其他业务产线接入需重新部署一套,资源无法共享,扩容需手动增加相应实例等。
天眼:资源集中管理,产品线动态接入,资源动态配置即时生效,大部分资源自动共享同时又支持资源独享配置;扩容直接通过平台页面化操作,简单便捷。
4、日志动态清理
ELK:依赖人工发现、手动清理和处理资源占用。
天眼:自动化监测ES集群概况,自动计算资源占用情况,当达到监控阈值时自动执行时间最早的索引资源清理。
5、自适应存储
ELK:传统方案受限于存储资源空间和成本,存储成本高、可保存的数据量有限。
天眼:实现了日志转存文件及从文件自动化恢复,日志存储成本低,存储周期长。
天眼通过自建分布式日志平台,有效的解决ELK日志方案下存在的缺陷问题;当前天眼日志量级:日均10TB日志量,并发QPS:10w+,接入产品线数:1000+。
GEEK TALK
03
天眼
3.1 天眼系统架构
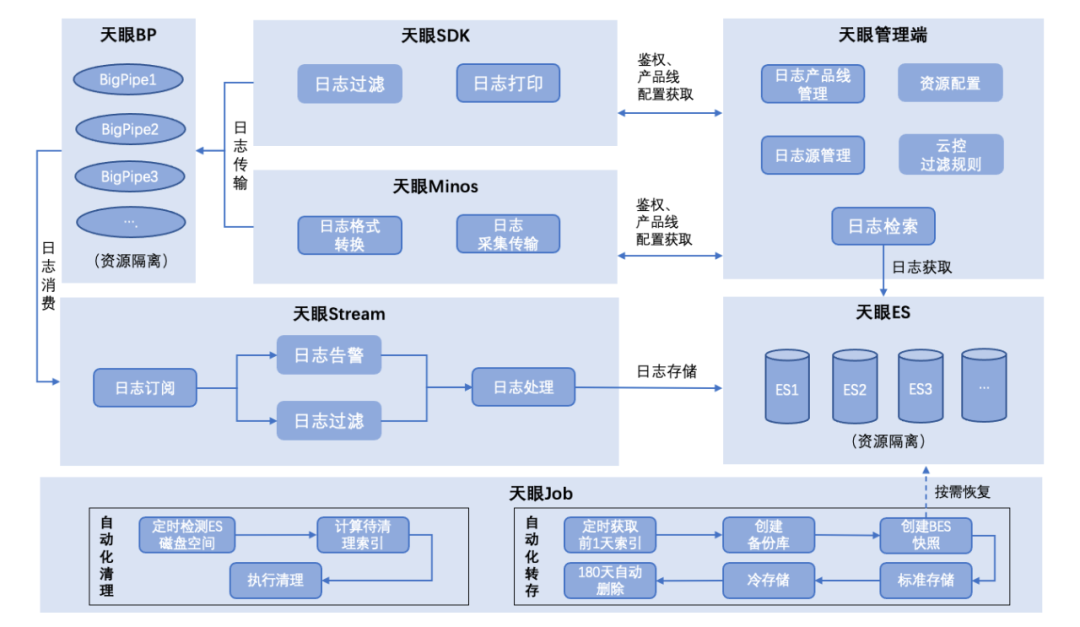
上图为完整的天眼核心系统架构,概述如下:
1、天眼日志采集支持SDK及监听日志文件两种方式,其中SDK主要通过实现日志插件接口获得完整日志结构信息,并传输至天眼日志传输管道;获得的日志信息LogEvent结构完整,同时基于LogEvent增加了产品线标识等字段,为日志隔离和检索提供核心依据;监听日志文件方式实现业务方0开发成本接入,仅需简单配置即可实现日志接入,支持产品线字段标识的同时,日志消息体解析也实现了正则匹配规则自动化匹配。
2、天眼日志传输采用高并发性能队列Disruptor,并且二次采用高性能队列Bigpipe实现日志传输异步解耦,解决了传统队列因加锁和伪共享等问题带来的性能缺陷;同时在传输过程中提供日志过滤和日志告警规则配置化自动化执行。
3、天眼日志存储通过轮询消费Bigpipe日志消息,最终写入ES的BulkProcessor,由ES自动调度并发写入ES进行存储;在日志传输和存储过程中实现了日志传输资源与存储资源隔离,根据产品线配置自动化选择传输与存储资源。
4、天眼自动化清理实现在存储资源有限的情况下自适应存储,自动化转存与恢复实现了在ES资源有限情况下低成本长时间存储解决方案。
3.2 天眼日志采集
日志平台核心目的是采集分布式场景下的业务日志进行集中处理和存储,采集方式主要包含如下:
1、借助常见日志框架提供的插件接口,在生成日志事件的同时执行其他自定义处理逻辑,例如log4j2提供的Appender等。
2、通过各种拦截器插件在固定位置拦截并主动生成和打印业务日志,将这类日志信息主动发送至日志消息传输队列中供消费使用,常见的如http、rpc调用链请求与返回信息打印,以及mybatis执行过程SQL明细打印等。
3、监听日志文件写入,从文件系统上的一个文件进行读取,工作原理有些类似UNIX的tail -0F命令,当日志写入本地文件时捕获写入行内容并进行其他自定义处理,例如将日志行信息发送至消息队列供下游使用。
4、syslog:监听来自514端口的syslog消息,并将其转换为RFC3164格式。
更多可用的日志采集实现方式,可以参考:Input Plugins
下面以天眼日志采集为例详细介绍日志采集实现过程:
天眼平台供支持两类日志采集实现方式,一类是SDK、一类是minos(百度自研的新一代的流式日志传输系统)。
3.2.1 天眼SDK日志采集
天眼SDK日志采集方式为通过Java SDK方式向业务方提供日志采集组件实现,达到自动收集业务日志并自动传输的目的;核心分为message日志流和trace日志流两大块:
1、message日志流主要通过日志框架提供的Appender接口实现,共支持log4j、logback、log4j2等主流日志框架。
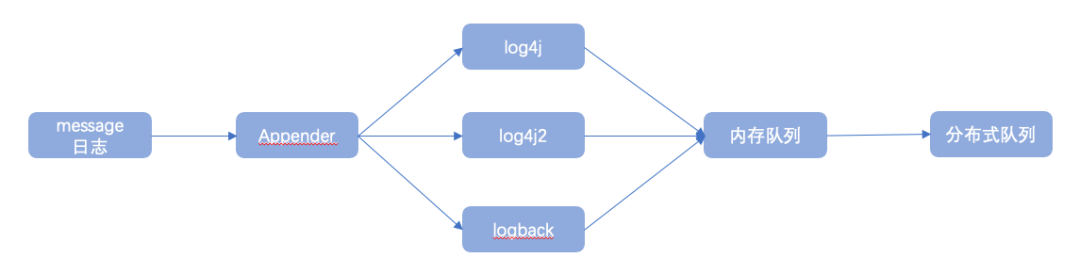
以logback为例,通过继承并实现AppenderBase抽象类提供的append方法,在logback日志框架生成LogEvent后获取日志事件对象并提交给LogbackTask执行任务处理,在LogbackTask中可以对日志事件内容进行进一步包装完善,并执行一些日志过滤策略等,最终得到的日志事件信息将直接发送至日志传输队列进行传输处理;
public class LogClientAppender<E> extends AppenderBase<E> {
private static final Logger LOGGER = LoggerFactory.getLogger(LogClientAppender.class);
protected void append(E eventObject) {
ILoggingEvent event = filter(eventObject);
if (event != null) {
MessageLogSender.getExecutor().submit(new LogbackTask(event, LogNodeFactory.getLogNodeSyncDto()));
}
}
}
2、trace日志流主要通过各类拦截器拦截业务请求调用链及业务执行链路,通过获取调用链详细信息主动生成调用链日志事件,并发送至日志传输队列进行消费使用,常见的调用链日志包含http与rpc请求及响应日志、mybatis组件SQL执行日志等;
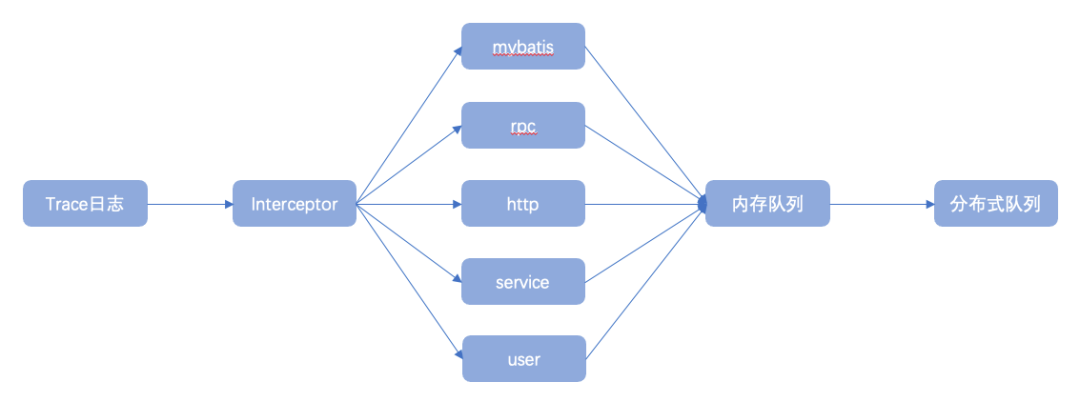
下图为trace日志流实现类图,描述了trace日志流抽象实现过程:
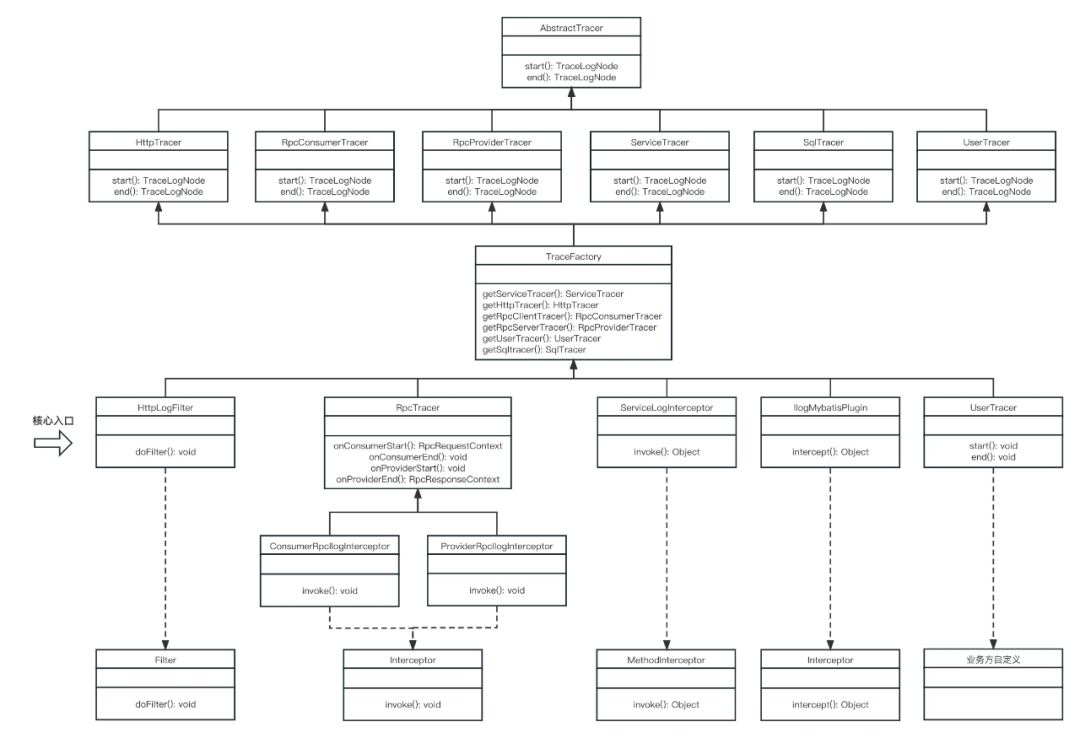
以mybatis为例,trace日志流核心拦截器实现类为IlogMybatisPlugin,实现ibatis Interceptor接口
核心代码:
TraceFactory.getSqltracer().end(returnObj, className, methodName, realParams, dbType, sqlType, sql, sqlUrl)
在end方法中将SQL执行过程中产生的各类信息通过参数传入,并组装成SqlLogNode(继承至通用日志节点LogNode)发布到队列。
使用时需要业务方手动将插件注册到SqlSessionFactory,以生效插件:
sqlSessionFactory.getConfiguration().addInterceptor(new IlogMybatisPlugin());
3.2.2 天眼minos日志采集
minos日志采集主要是借助百度自研的minos数据传输平台,实现机器实例上的日志文件信息实时传输至目的地,常见传输目的地有Bigpipe、HDFS、AFS等;目前天眼主要是通过将minos采集到的日志发送到Bigpipe实现,并由后续的Bigpipe消费者统一消费和处理;同时针对日志来源为minos的日志在消费过程中增加了日志解析与转换策略,确保采集到的日志格式和SDK方式生成的日志格式基本一致;
在日志采集过程中,天眼如何解决平台化标识:
1、在产品线接入天眼时,天眼给对应产品线生成产品线唯一标识;
2、SDK接入方式下,产品线服务端通过系统变量配置产品线标识,SDK在运行过程中会自动读取该变量值并设置到LogNode属性中;
3、LogNode作为日志完整信息对象,在传输过程中最终存储到ES,同时ES在建索引时为产品线唯一标识分配字段属性;
4、产品线唯一标识贯穿整个分布式日志链路并和日志内容强绑定。
3.3 高并发数据传输和存储
在ELK方案中,生成的日志信息直接发送给logstash进行传输,并写入到es,整个过程基本为同步操作,并发性能完全依赖logstash服务端及ES服务端性能;
天眼则是通过异步方式解耦日志传输过程,以及在日志入口处引入Disruptor高性能队列,并发性能直奔千万级别;同时在Disruptor本地队列之后再设计Bigpipe离线队列,用来长效存储和传输日志消息;以及引入兜底文件队列BigQueue解决方案,处理在极少数异常情况下写本地队列或离线队列失败时的兜底保障,如下图所示:
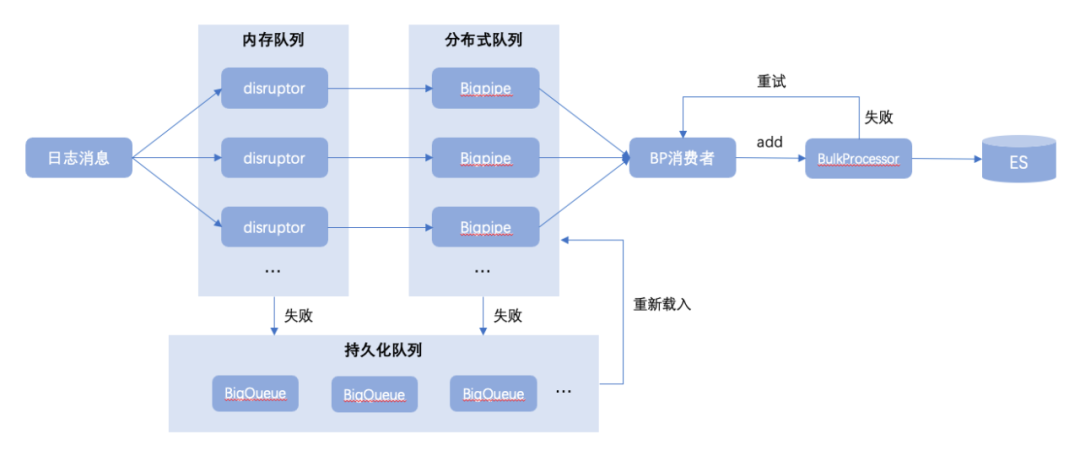 Disruptor 是一个高性能的用于线程间消息处理的开源框架。Disruptor内部使用了RingBuffer,它是Disruptor的核心的数据结构。Disruptor队列设计特性:固定大小数组:由于数组占用一块连续的内存空间,可以利用CPU的缓存策略,预先读取数组元素附近的元素;数组预填充:避免了垃圾回收代来的系统开销;缓存行填充:解决伪共享问题;位操作:加快系统的计算速度;使用数组+系列号的这种方法最大限度的提高了速度。因为如果使用传统的队列的话,在多线程环境下对队列头和队列尾的锁竞争是一种很大的系统开销。
Bigpipe是一个分布式中间件系统,支持Topic和Queue模型,不仅可以完成传统消息队列可以实现的诸如消息、命令的实时传输,也可以用于日志数据的实时传输。Bigpipe能够帮助模块间的通信实现解耦,并能保证消息的不丢不重;BigQueue是基于内存映射文件的大型、快速和持久队列;
Disruptor 是一个高性能的用于线程间消息处理的开源框架。Disruptor内部使用了RingBuffer,它是Disruptor的核心的数据结构。Disruptor队列设计特性:固定大小数组:由于数组占用一块连续的内存空间,可以利用CPU的缓存策略,预先读取数组元素附近的元素;数组预填充:避免了垃圾回收代来的系统开销;缓存行填充:解决伪共享问题;位操作:加快系统的计算速度;使用数组+系列号的这种方法最大限度的提高了速度。因为如果使用传统的队列的话,在多线程环境下对队列头和队列尾的锁竞争是一种很大的系统开销。
Bigpipe是一个分布式中间件系统,支持Topic和Queue模型,不仅可以完成传统消息队列可以实现的诸如消息、命令的实时传输,也可以用于日志数据的实时传输。Bigpipe能够帮助模块间的通信实现解耦,并能保证消息的不丢不重;BigQueue是基于内存映射文件的大型、快速和持久队列;1、快 : 接近直接内存访问的速度,enqueue和dequeue都接近于O(1)内存访问。
2、大:队列的总大小仅受可用磁盘空间的限制。
3、持久:队列中的所有数据都持久保存在磁盘上,并且是抗崩溃的。
4、可靠:即使您的进程崩溃,操作系统也将负责保留生成的消息。
5、实时:生产者线程产生的消息将立即对消费者线程可见。
6、内存高效:自动分页和交换算法,只有最近访问的数据保留在内存中。
7、线程安全:多个线程可以同时入队和出队而不会损坏数据。
8、简单轻量:目前源文件个数12个,库jar不到30K。
在采集到日志事件后,进入传输过程中,天眼SDK中支持日志过滤规则策略匹配,针对命中策略的日志进行过滤,实现过程如下图所示: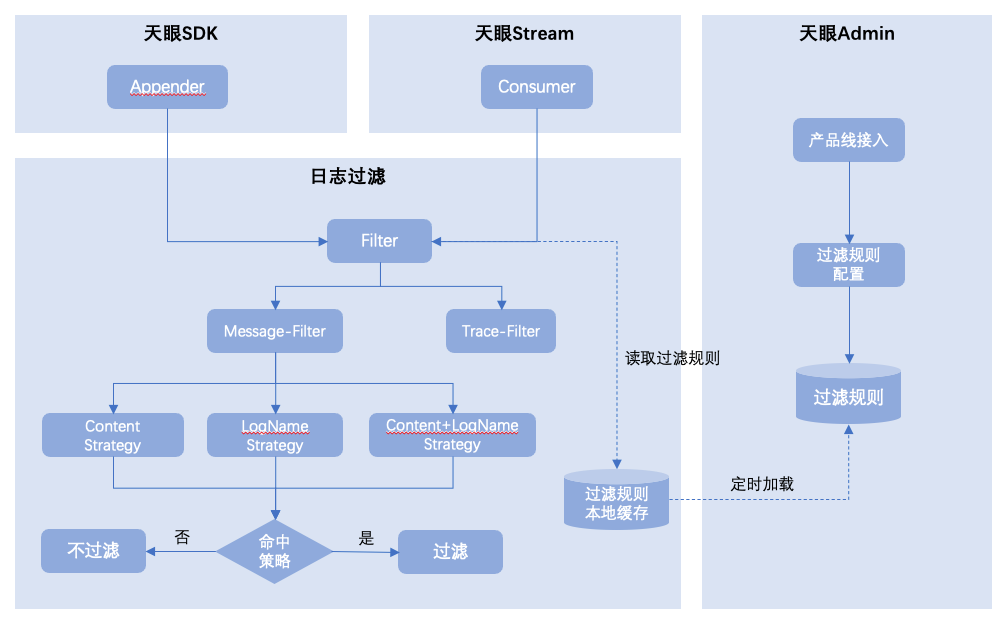
未命中过滤规则的日志消息事件将继续发送至Bigpipe,至此日志生产阶段即完成,后续通过天眼消费者模块订阅Bigpipe消费并批量推送至ES。
3.4 天眼日志检索
基于天眼链路最终存储到ES的日志数据,天眼平台提供了可视化日志检索页面,能够根据产品线唯一标识(日志源ID)指定业务范围进行检索,同时支持各种检索条件,效果如下图所示:
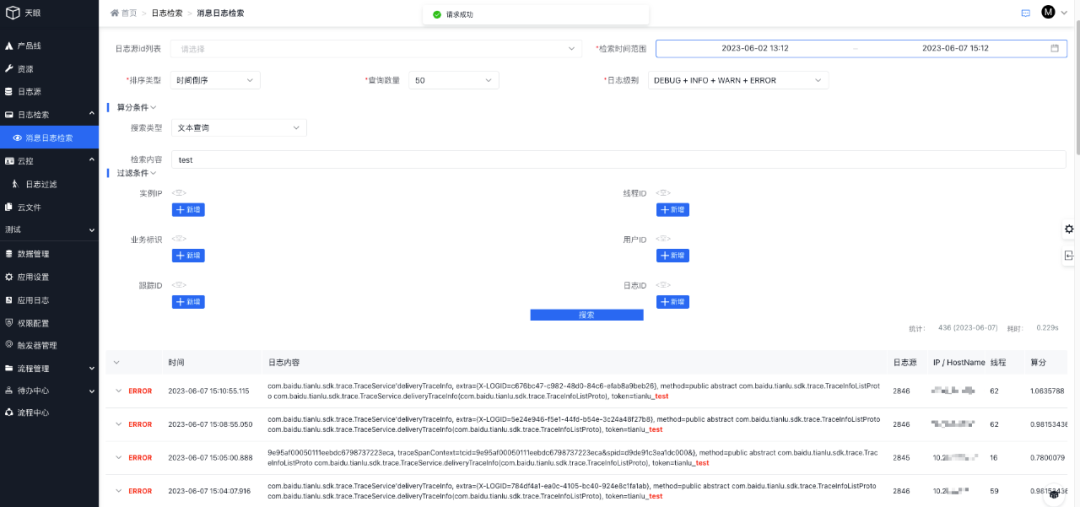
3.4.1 检索条件详解
日志源id列表:获取日志源对应的日志
检索时间范围:日志的时间范围
排序类型:日志的存入时间/日志存入的算分
查询数量:查询出多少数量的日志
日志级别:查询什么级别的日志,如:DEBUG / INFO / WARN / ERROR
算分条件:支持五种算分查询,文本查询、等值查询、短语查询、前缀查询、逻辑查询;五选一

过滤条件:只显示符合过滤条件信息的日志

3.4.2 算分条件检索详细说明
支持五种算分查询:文本查询、等值查询、短语查询、前缀查询、逻辑查询。五选一
搜索内容字段:message、exception
"message": {
"type": "text",
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 15000
}
},
"analyzer": "my_ik_max_word",
"search_analyzer": "my_ik_smart"
},
"exception": {
"type": "text",
"analyzer": "my_ik_max_word",
"search_analyzer": "my_ik_smart"
}
说明:
-
"analyzer": "my_ik_max_word":底层使用ik_max_word,message和exception信息在存储是会以最细粒度拆词进行存储;
-
"search_analyzer": "my_ik_smart":底层使用ik_smart,在查询内容是,会将查询内容以最粗粒度拆分进行查询。
3.4.2.1 文本查询
底层实现原理
{
"query": {
"bool": {
"must": [{
"multi_match": {
"query": "searchValue",
"fields": ["message", "exception"],
"type": "best_fields"
}
}]
}
}
}
天眼管理端对应图
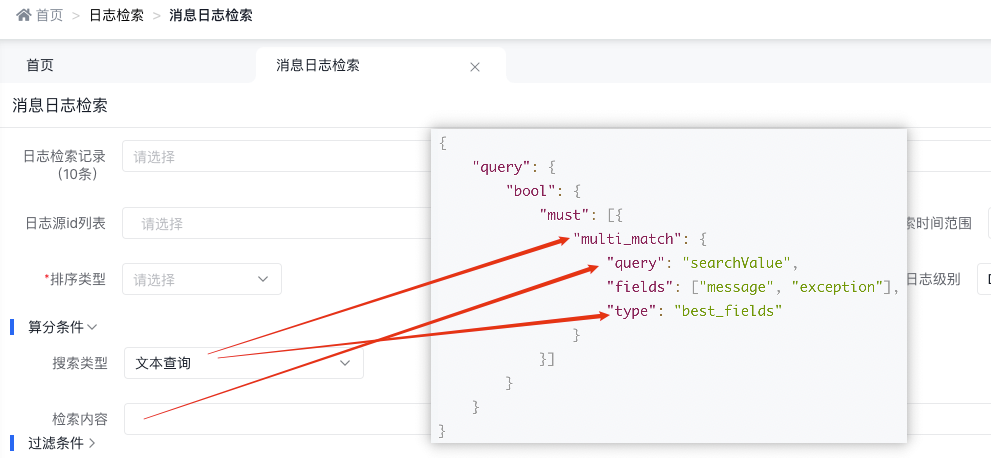
使用说明:
-
multi_match中的best_fields会将任何与查询匹配的文档作为结果返回,但是只使用最佳字段的 _score 评分作为评分结果返回
3.4.2.2 等值查询
底层实现原理
{
"query": {
"bool": {
"must": [{
"multi_match": {
"query": "searchValue",
"fields": ["message", "exception"],
"type": "best_fields",
"analyzer": "keyword"
}
}]
}
}
}
天眼管理端对应图
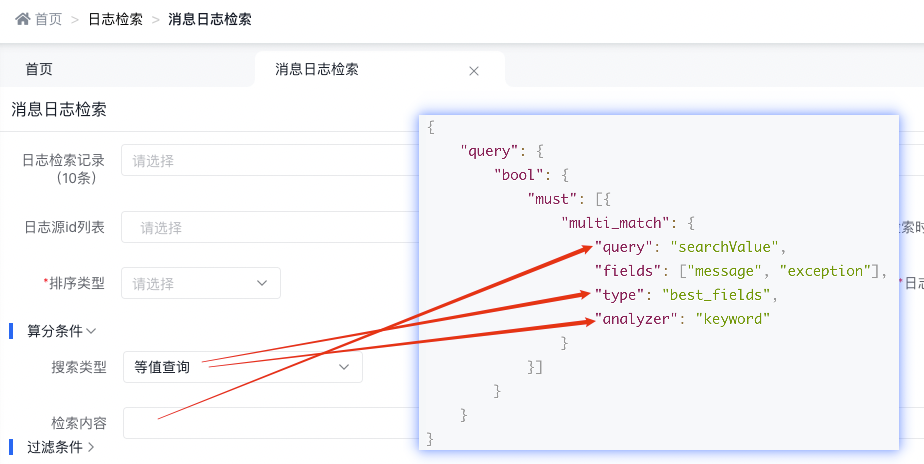
使用说明:
-
multi_match中的best_fields会将任何与查询匹配的文档作为结果返回,但是只使用最佳字段的 _score 评分作为评分结果返回
-
设置 analyzer 参数来定义查询语句时对其中词条执行的分析过程
-
Keyword Analyzer - 不分词,直接将输入当做输出
3.4.2.3 短语查询
底层实现原理
{
"query": {
"bool": {
// 短语查询
"must": [{
"multi_match": {
"query": "searchValue",
"fields": ["message", "exception"],
"type": "phrase",
"slop": 2
}
}]
}
}
}
天眼管理端对应图
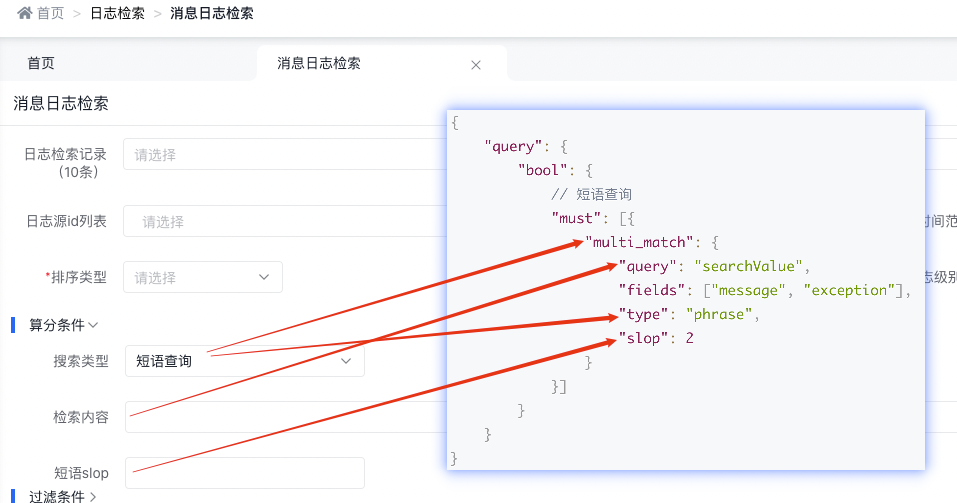
使用说明:
-
phrase 在 fields 中的每个字段上均执行 match_phrase 查询,并将最佳字段的 _score 作为结果返回
-
默认使用 match_phrase 时会精确匹配查询的短语,需要全部单词和顺序要完全一样,标点符号除外
-
slop指查询词条相隔多远时仍然能将文档视为匹配 什么是相隔多远? 意思是说为了让查询和文档匹配你需要移动词条多少次?以 "I like swimming and riding!" 的文档为例,想匹配 "I like riding",只需要将 "riding" 词条向前移动两次,因此设置 slop 参数值为 2, 就可以匹配到。
3.4.2.4 前缀查询
底层实现原理
{
"size": 50,
"query": {
"bool": {
// 前缀查询
"must": [{
"multi_match": {
"query": "searchValue",
"fields": ["message", "exception"],
"type": "phrase_prefix",
"max_expansions": 2
}
}]
}
}
}
天眼管理端对应图
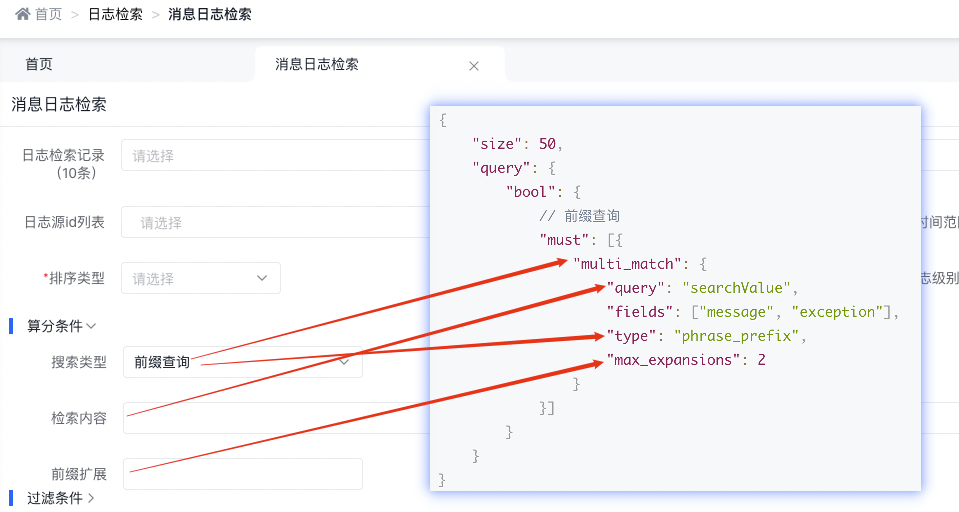
使用说明:
-
phrase_prefix 在 fields 中的字段上均执行 match_phrase_prefix 查询,并将每个字段的分数进行合并
-
match_phrase_prefix 和 match_phrase 用法是一样的,区别就在于它允许对最后一个词条前缀匹配,例如:查询 I like sw 就能匹配到I like swimming and riding。
-
max_expansions 说的是参数 max_expansions 控制着可以与前缀匹配的词的数量,默认值是 50。以 I like swi 查询为例,它会先查找第一个与前缀 swi 匹配的词,然后依次查找搜集与之匹配的词(按字母顺序),直到没有更多可匹配的词或当数量超过 max_expansions 时结束。
-
match_phrase_prefix 用起来非常方便,能够实现输入即搜索的效果,但是也会出现问题。 假如说查询 I like s 并且想要匹配 I like swimming ,结果是默认情况下它会搜索出前 50 个组合,如果前 50 个没有 swimming ,那就不会显示出结果。只能是用户继续输入后面的字母才可能匹配出结果。
3.4.2.5 逻辑查询
底层实现原理
{
"query": {
"bool": {
// 逻辑查询
"must": [{
"simple_query_string": {
"query": "searchValue",
"fields": ["message", "exception"]
}
}]
}
}
}
天眼管理端对应图:
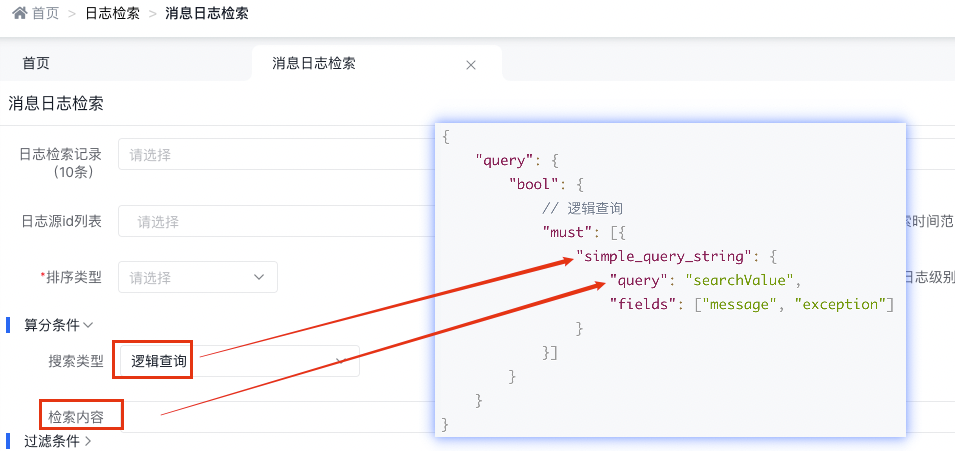
simple_query_string查询支持以下操作符(默认是OR),用于解释查询字符串中的文本:
-
+ AND
-
| OR
-
- 非
-
" 包装许多标记以表示要搜索的短语
-
* 在术语的末尾表示前缀查询
-
( and ) 表示优先级
-
~N 在一个单词之后表示编辑距离(模糊)
-
~N 在短语后面表示溢出量
官方使用文档:https://www.elastic.co/guide/en/elasticsearch/reference/6.8/query-dsl-simple-query-string-query.html
使用示例解释:
GET /_search
{
"query": {
"simple_query_string": {
"fields": [ "content" ],
"query": "foo bar -baz"
}
}
这个搜索的目的是只返回包含foo或bar但不包含baz的文档。然而,由于使用了OR的default_operator,这个搜索实际上返回了包含foo或bar的文档以及不包含baz的文档。要按预期返回文档,将查询字符串更改为foo bar +-baz。
3.5 日志资源隔离
在庞大的企业级软件生产环境下,业务系统会产生海量日志数据。一方面,随着业务方的不断增加,日志系统有限的资源会被耗尽,导致服务不稳定甚至宕机。另一方面,不同业务的日志量级、QPS 存在差异,极端情况下不同业务方会对共享资源进行竞争,导致部分业务的日志查询延时变高。这对日志系统的资源管理带来了挑战。
天眼平台采用资源隔离的方式解决此问题,来为业务提供实时、高效、安全的存储与查询服务。
资源隔离主要围绕着日志的传输资源与日志的存储资源进行。业务方在接入天眼系统时,可以根据业务需要在平台交互界面,进行传输资源与存储资源的隔离配置,这种隔离资源的配置方式避免了共享资源竞争导致的日志延迟增加与潜在的日志丢失问题。
具体的隔离实现方案如图 3.5.1 所示,主要包括以下步骤:
1、业务方生产日志:如 3.2 介绍到的,业务方运行时产生的日志可以通过 SDK 或 minos 的方式将日志传输至分布式队列 BP 中;
2、天眼平台订阅日志:在业务方通过天眼平台进行 ES、BP 资源的配置之后,配置监听器会监测到变更内容,再根据配置的变更类型管理日志订阅器、分发器的生命周期,包括ES 客户端、BP 客户端的创建与销毁;
3、平台内部日志处理:日志订阅器通过 BP 客户端收到业务方的日志后,首先会采用 3.3 中提到的业务方过滤规则进行过滤拦截,再将日志转换为事件放入绑定的内存通道中;
4、天眼平台分发日志:日志分发器会不断从绑定的内存通道中拉取日志事件,并通过 ES 客户端对日志进行存储,如果存储失败则会触发相应 backoff 策略,例如异常行为记录;
5、业务方日志查询:日志存储至 ES 集群之后,业务方可以通过平台界面便捷地进行日志查询。
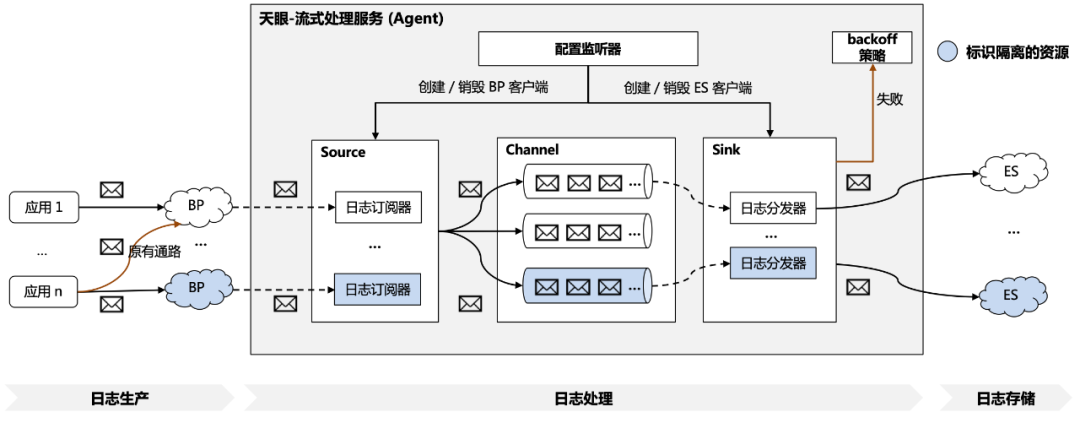
△3.5.1 天眼-资源隔离方案
可见在复杂的多应用场景下,隔离资源机制是一种高效管理日志系统资源的方式。天眼日志系统提供了灵活的资源配置来避免资源浪费,提供了共享资源的隔离来降低业务方日志查询的延迟、提升日志查询的安全性,进而推动业务的增长和运营效率。
3.6 日志动态清理与存储降级
随着业务的长期运行与发展,日志量级也在不断增加。一方面,针对近期产生的日志,业务方有迫切的查询需求。针对产生较久的日志,迫于监管与审计要求也有低频率访问的诉求。如何在成本可控并且保证平台稳定的前提下,维护这些海量日志并提供查询服务对日志系统而言也是一个挑战。
天眼平台通过资源清理机制和日志存储降级机制来解决这个问题。
资源清理机制主要用作 ES 集群的索引清理。随着日志量的增加,集群的资源占用率也在增加,在极端情况下,过高的磁盘与内存占用率会导致 ES 服务的性能下降,甚至服务的宕机。资源清理机制会定期查询 ES 集群的资源占用情况,一旦集群的磁盘资源超过业务方设定的阈值,会优先清理最旧的日志,直到资源占用率恢复正常水平。
存储降级机制主要用作 ES 集群的索引备份与恢复。将日志长期存储在昂贵的 ES 集群中是一种资源浪费,也为日志系统增加了额外的开销。存储降级机制会定期对 ES 集群进行快照,然后将快照转存到更低开销的大对象存储服务(BOS)中,转存之后的快照有 180 天的有效期以应对审查与监管。当业务方需要查询降级存储后的日志时,只需要从大对象存储服务中拉取快照,再恢复到 ES 集群以提供查询能力。
具体的资源清理机制与存储降级机制如图 3.6.1 所示,主要包括以下步骤:
1、集群状态查询:资源清理任务通过定期查询集群信息的方式监测资源占用率,当资源占用率超过业务方设定的阈值时会触发资源清理;
2、集群索引清理:通过查询索引信息并进行资源占用情况计算,再根据时间倒序删除依次最旧的索引,直到满足设定的阈值;
3、集群索引备份:存储降级任务会定期对集群进行快照请求,然后将快照文件转存到低开销的大文件存储服务中完成存储的降级;
4、集群索引恢复:在业务方需要查询降级存储后的日志时,服务会将快照文件从大文件存储服务中拉取目标快照,再通过快照恢复请求对快照进行恢复,以提供业务方查询。
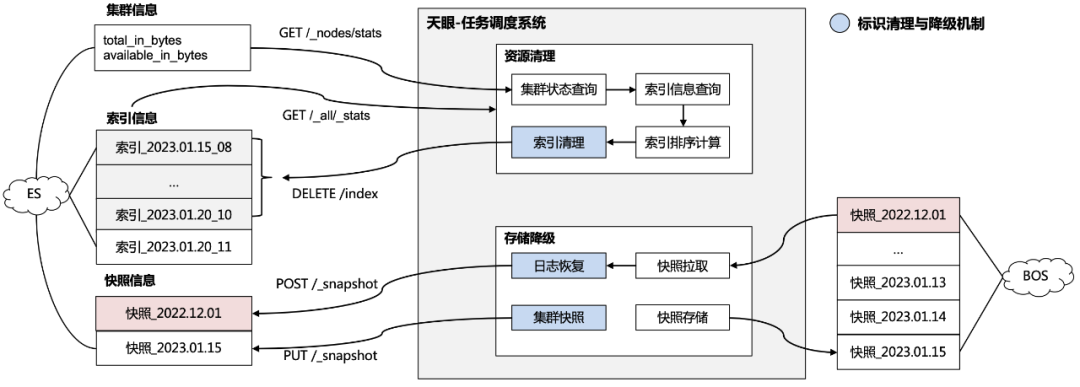
△3.6.1天眼-日志动态清理与存储降级方案
可见在面对海量日志的存储与查询,通过资源清理机制可以防止集群资源过载同时提升日志检索效率,通过存储降级机制可以提升资源利用率同时确保审计的合规性,从而在业务高速增长使用的同时保证日志系统的健壮性。
3.7 最佳实践
基于前面提到的天眼平台设计思想,结合其中部分能力展开介绍天眼在运维管理方面的实践。
3.7.1 天眼平台化实践
天眼通过抽象产品线概念,针对不同的接入方提供产品线接入流程,为业务生成产品线唯一标识并与业务日志绑定;产品线相关流程如下:
1、产品线日志源申请流程
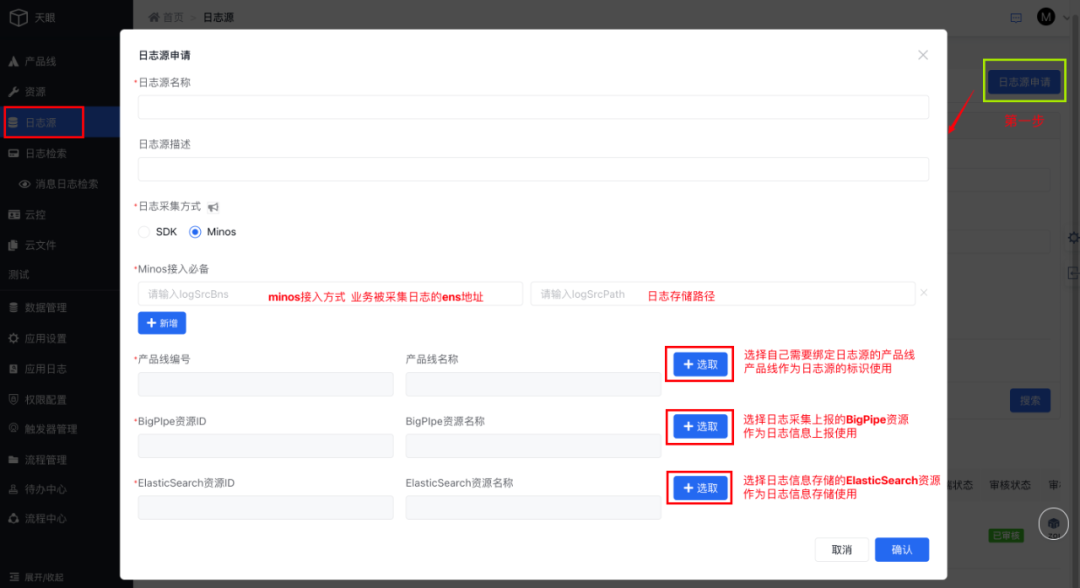
支持产品线选择日志采集方式包含SDK、Minos两种方式,选择minos接入时,bns与日志存储路径必选,方便系统根据配置自动执行日志采集。
同时在Bigpipe资源与ES资源方面,平台支持多种资源隔离独立使用,不同的产品线可以配置各自独有的传输和存储资源,保障数据安全性和稳定性。
2、日志源申请后,需要管理员审核后才能进行使用(申请后无需操作,仅需等待管理员通过审核后,进行SDK接入)

access_key的值查看权限:仅日志源绑定产品线的经理及接口人可查,access_key将作为产品线接入天眼鉴权的关键依据。
3.7.2 日志过滤实践
产品线接口人可以基于自身产品线新增日志过滤规则配置,配置的规则将自动生效于日志采集传输流程中:
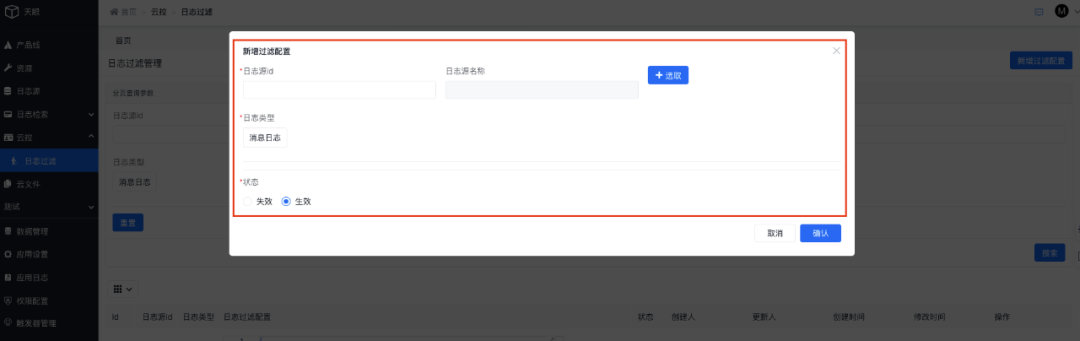
选择消息日志后将弹出详细过滤规则配置菜单,当前系统共支持三种过滤规则,分别是按日志内容、按日志名称、按日志内容和日志名称组合三种方式:
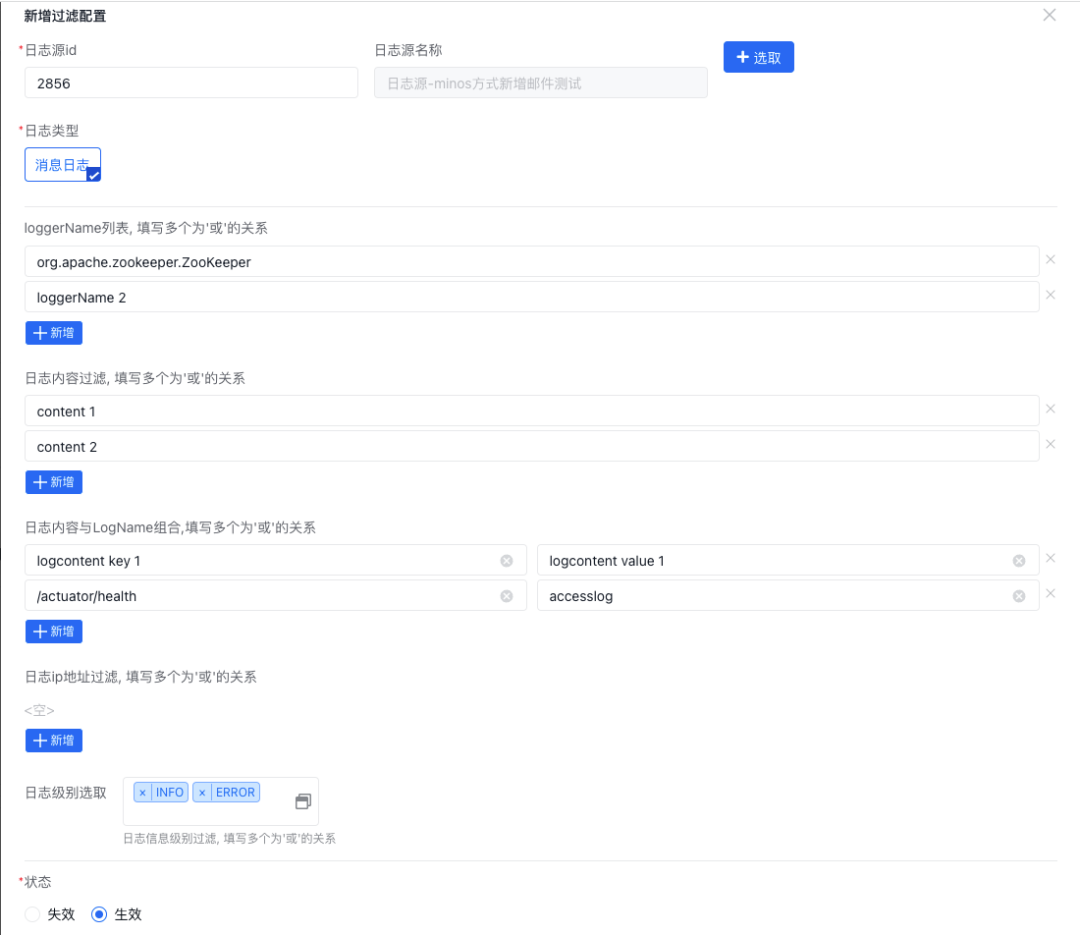
过滤规则配置完成后可以在列表管理每条规则:
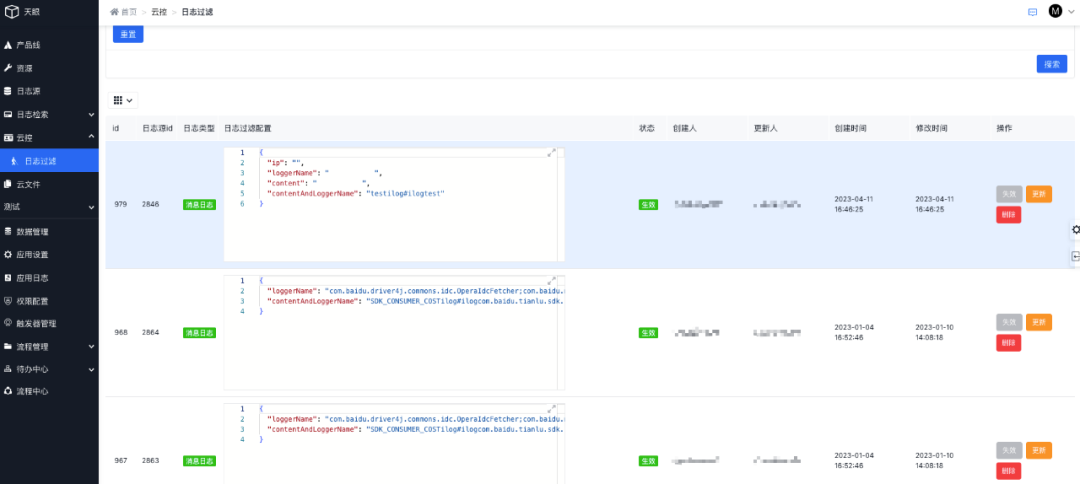
GEEK TALK
04
思考与总结
随着分布式业务系统的日益复杂,为业务方提供高效、低延迟、高性能的日志服务系统显得尤为重要。本文介绍了天眼平台是如何进行日志采集、传输并支持检索的,此外还通过支持日志的资源隔离,解耦各业务方的日志通路和存储,从而实现业务日志的高效查询和业务问题的高效定位。此外通过对日志进行监控可以主动发现系统问题,并通过告警日志的trace_id快速定位问题,从而提升问题发现导解决的效率。
随着大模型技术的不断发展,我们也通过大模型进行一些业务迭代,进而提升业务检索和排查效率。例如:我们可以直接询问,今天有几笔异常核销订单;订单7539661906核销异常原因是什么等等。通过与大模型的结合,我们缩短了业务方问题排查定位的路径,提升了业务运维效率和交互体验。后续我们也将不断与大模型进行深入打磨和持续深耕,持续沉淀和输出相关的通用方案。
-
分布式日志追踪ID实战2025-01-20 1451
-
zookeeper分布式原理2023-12-03 1501
-
如何使用Jmeter进行分布式测试;检索日志?2023-05-10 645
-
【学习打卡】OpenHarmony的分布式任务调度2022-07-18 4378
-
HDC2021技术分论坛:如何高效完成HarmonyOS分布式应用测试?2021-12-13 3171
-
分享一个有趣的鸿蒙分布式小游戏2021-11-01 3786
-
在 Java 中利用 redis 实现一个分布式锁服务2019-07-05 1418
-
区块链分布式身份证核验服务平台联核云VIS介绍2018-12-03 4185
-
基于分布式调用链监控技术的全息排查功能2018-08-07 3229
-
一行代码,保障分布式事务一致性—GTS:微服务架构下分布式事务解决方案2018-06-05 2714
-
开放分布式追踪(OpenTracing)入门与 Jaeger 实现2018-03-07 5731
-
微服务和分布式的区别2018-02-09 82289
-
分布式软件系统2009-07-22 5469
-
网络取证日志分布式安全管理2009-05-11 517
全部0条评论

快来发表一下你的评论吧 !
