

浅谈相机成像问题中的数学工具
描述
前言
自从上世纪50年代以来,计算机视觉技术一直是学术界和工业界的热点问题,尤其是近十年来,随着新一轮人工智能技术的蓬勃发展,得到AI加持的计算机视觉技术快速走进了人们的日常生活,不断重塑着人们的生活方式。
顾名思义,计算机视觉是指让计算机能够理解、分析和处理图像和视频的技术,通过研究高效的计算机算法和系统,使计算机获得像人类一样理解和使用视觉信息的能力。在这个过程中,人们需要综合运用计算机科学、数学、物理学、生理学、心理学等跨学科的知识才能更好地解决一些实际问题。
随着视觉应用场景的不断扩大,越来越多的人已经认识到,相机成像技术处在一个十分关键的地位。在讨论视觉算法的效能时,人们经常会引用一个经典的英语表述“garbage in,garbage out”,这是在说,如果相机采集的基础图像本身就没有有用的信息,那么再复杂精妙的算法也不可能给出有用的结果。所以,作为爱芯元智的企业目标之一,就是不断研发最前沿的AI-ISP技术,期望为视觉算法提供优质的输入图像,使上层应用能够在各种高挑战场景下保持稳定的性能输出。
说到图像质量,这其实是可以讨论一千零一夜的话题,不过总的来说,人们会从分辨率、解像力、帧率、延迟、色彩还原、细节还原、噪声、动态范围、伪像、拖影、畸变等多个不同的维度分别对图像质量进行量化分析,最终形成一个总的评价。在一类典型的应用场景中,视觉算法的核心任务是精确测量物体的形状和距离,测得的参数将作为一系列重要决策的依据,有些决策可能关乎企业盈亏,而另一些决策则可能关乎人身安全。此时,输入图像的几何畸变常常是影响系统性能的关键因素之一,为此人们发展出了一系列方法对图像畸变进行分析和处理。
在这篇文章里,我们想分享的是人们在处理图像几何畸变问题时常用的思想方法和数学工具,希望相关的讨论能够对部分读者有所启发。本文所讨论的部分技术已经集成在爱芯元智AX620系列芯片的标准软件发布包中,可以帮助智慧城市、机器视觉等行业的用户对广角镜头进行畸变校正。另外,在智慧城市和辅助驾驶领域常见的双摄、多摄拼接产品形态,其核心任务是对多个图像进行像素级校正和融合,所以对镜头参数标定和畸变校正算法提出了更高的要求。在研究更高精度和收敛性的算法过程中,本文讨论的方法和工具也会有所裨益。关于图像拼接融合的技术架构已经在AX620和AX650系列芯片中得到了支持,关键算法和工具还在不断优化完善中,欢迎感兴趣的朋友关注。
1. 数学建模
与很多其它学科一样,计算机视觉从业者在分析相机成像问题时,会首先建立一个关于相机系统成像原理的数学模型,简称相机模型(camera model)。一个最为基本且众所周知的相机模型是小孔成像模型(pinhole model),其原理如图1所示。
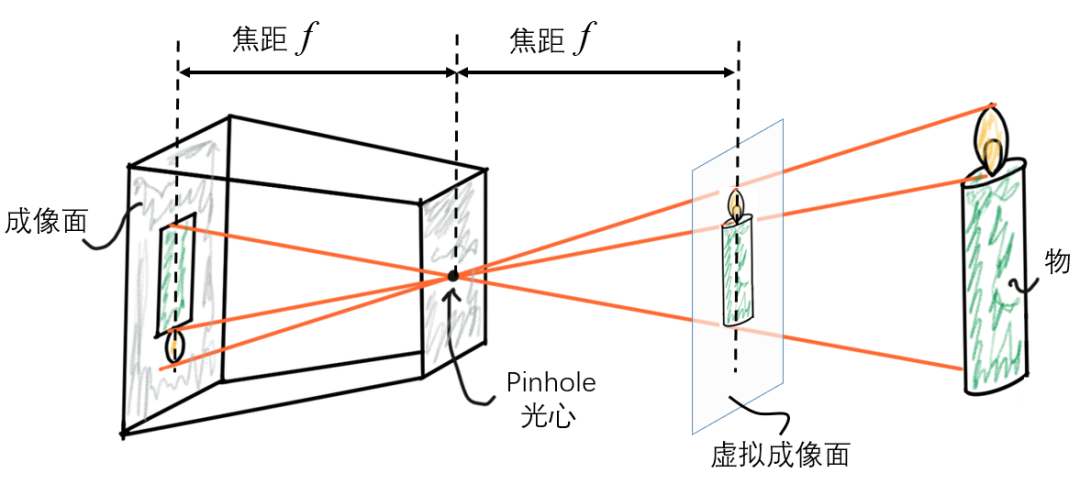
图1 小孔成像模型(pinhole camera model)
这个模型假定光是沿直线传播的,模型定义了一个特殊的点即光心,一个焦距参数,也就是成像面与光心之间的距离。通常会以光心为原点建立相机坐标系,并规定物方空间的Z坐标为正,像方空间的Z坐标为负。为了计算方便,模型还定义了虚拟成像面,虚拟成像面上的像是正立的,可以避免负号。
小孔成像模型的优点是足够简单,只需要初中数学的相似三角形知识就可以计算像的大小。当相机的视场角比较小时,小孔成像模型是相机成像过程的一个良好近似。但是当相机使用广角镜头,或者应用场景对模型精度要求很高时,小孔成像模型就不够准确了,此时必须在模型中引入成像畸变模型,使模型与实际情况更加符合。
在工程实践中,人们经常需要用具体的数字来定义什么是大,什么是小,什么是成功,什么是失败。在评价一个成像模型的精度时,人们会使用重投影误差(reprojection error)指标作为参考。这个指标的含义是,假设物方空间中存在一个3D坐标点P,它被相机成像后,实际从图像上提取到的2D坐标是p,此值包含了一切设计因素和随机因素导致的误差,如果再把P值代入相机成像模型进行计算,模型预测的2D坐标是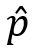 ,我们把p与之间的像素距离定义为P点的重投影误差。图2显示了重投影误差的基本思想。
,我们把p与之间的像素距离定义为P点的重投影误差。图2显示了重投影误差的基本思想。
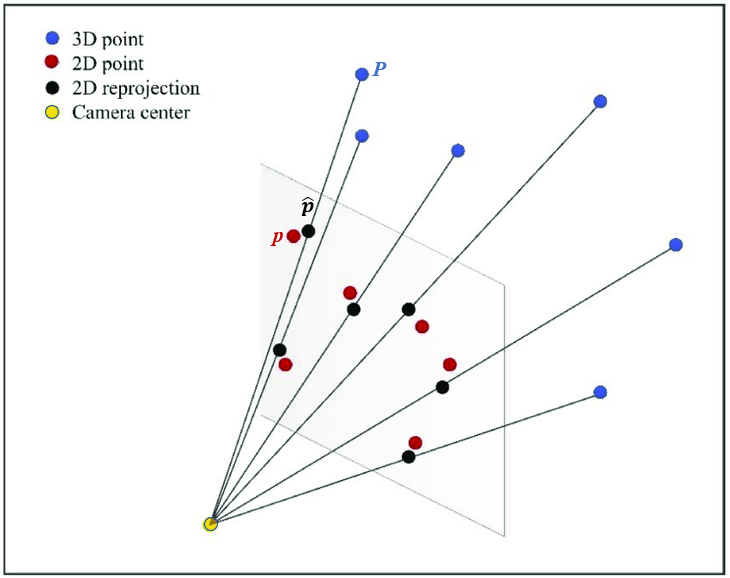
图2 重投影误差(reprojection error)
显然,一张图像中会包含成千上万个与P点类似的点,如果只用一个点的误差值来代表整张图像那明显是不太合适的。但是我们可以从一张图像中筛选出一批有代表性的点,把这些点的重投影误差的某种平均值作为成像模型的重投影误差,这样就比较公允了。进一步地,如果算法的输入数据是一个视频序列,那么只用一张图像的误差来代表整个序列也同样是不太合适的,此时需要把每一张图像的误差都计算出来,然后考察整个序列的平均值和方差情况,这样得到的数据就会更可信一些。图3是使用Matlab工具绘制的一个图像序列的重投影误差,从图中可以看到,重投影误差的序列平均值是0.18个像素,对于很多应用而言这是一个相当优秀的值。另外,重投影误差在图像之间会存在一定幅度的波动,而波动的大小也反应了成像模型的稳定性。
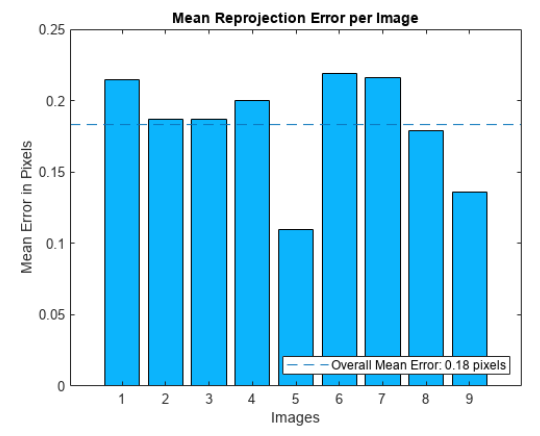
图3 图像序列的重投影误差举例
当我们掌握了重投影误差这种评价方法之后,假设有一个新的成像模型摆在面前,我们就可以客观地判断这个模型是好是坏,是有竞争力还是缺乏竞争力。在很多时候,这个能力可以帮助我们规避错误决策的风险,让我们总是站在一个相对安全的位置上。
回到刚才的话题,对于一个特定的相机系统,我们把偏离小孔成像模型的行为定义为一种畸变(distortion),当我们发现使用小孔成像模型得到的重投影误差超出可接受标准时,此时就需要设计一个合适的数学模型来定量地描述畸变,然后根据畸变模型对原图像进行校正,使校正图像的重投影误差收敛到可接受水平。
通过考察畸变行为我们能够发现一些基本事实,首先,大部分的成像畸变都可以归因于镜头的设计、制造、装配等环节,因此通常可以用镜头畸变来指代成像畸变;其次,镜头畸变的特性和观察尺度有关,在宏观尺度上观察时,广角镜头和鱼眼镜头通常表现为桶形畸变,长焦镜头经常表现为枕形畸变,这些行为是由镜头的光学设计决定的,每个镜头都应该具有相同的行为,而在微观尺度上观察时,镜头的某些局部区域会表现出相对宏观规律的偏离,这往往是加工制造环节中一些不可控因素导致的,每个镜头的具体行为不一定相同;最后,不同生产批次的镜头,由于材料、加工、装配等因素的变化,也会导致批次与批次之间呈现出可观测的行为差异。
基于以上观察我们认识到,镜头畸变模型可能需要分成两类:如果应用场景对模型的精度要求不高,比如图像主要是服务于人眼观察,那么畸变模型只要能够描述镜头的宏观设计行为就可以了;如果应用场景对模型的精度要求很高,比如基于图像进行测量的场景,那么畸变模型必须能够描述镜头的局部特性,此类模型所使用的参数数量一定远远多于前者,获取这些参数的过程也会更复杂。
对于描述镜头宏观设计行为的畸变模型,我们不妨对问题做一些合理的简化,首先假设镜头的行为是圆对称的,只需要考察任一直径方向上的成像规律,其次假设存在一条理想的光滑曲线可以精确地描述镜头的成像行为。基于这两条假设,我们可以建立理想像点(基于小孔成像模型)与实际像点的函数关系r'=f(r),在某些情况下,我们可以把r作为理想像点,r'作为实际像点,在另一些情况下,也可以把r作为实际像点,r'作为理想像点。在r=0附近对光滑曲线f(r)做泰勒展开,并忽略阶数高于N的余项,即可得到关于镜头实际成像公式的多项式模型:
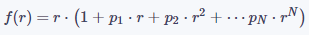
公式(1)
其中,r为理想像点(或实际像点)到镜头光心的距离,p1,⋯,pN是待定参数,需要通过实验标定的方法获得具体的值。
在实践中,可以对(1)做进一步简化,只使用其中的奇数次多项式或偶数次多项式,即:
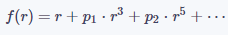
公式(2)
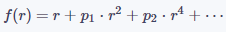
公式(3)
2. 优化问题
在前一节的讨论中,我们已经能够建立一个关于相机成像的数学模型,其中包含了镜头畸变的模型,但是该模型中存在一组待定系数p1,⋯,pN目前还不知道具体值,需要找到最优解。在数学上,这是一类典型的优化问题,已经有了很成熟的解决方案。实际上,早在1809年就出现了Gauss-Newton法来处理非线性最小二乘优化问题,但是该方法在迭代过程中要求目标函数的雅可比矩阵必须列满秩,这一条件限制了它的应用。Levenberg于1944年提出了一个改进的方法,然后Marquardt在1963年进一步发展出了Levenberg-Marquardt方法,目前L-M方法已经成为非线性优化的首选方法。关于L-M方法的实现原理已有很多文献给出了很好的描述,在OpenCV、Python、Matlab等工具中也提供了相应的库可以直接调用,对此感兴趣的读者可以深入研究。
回到我们的具体问题,使用L-M方法求解镜头畸变模型的待定系数的过程是,首先要选定一组样本G作为训练集,假设G中包含m个样本点。然后,定义变量x=(p1,⋯,pN)T,表示模型的待定参数;定义函数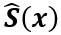 ,表示待定参数为x时,样本G对应的模型预测值,该函数返回一个包含m个2D点坐标的向量;定义函数S(x),表示从图像中提取的关于样本G的实测值,同理,该函数返回一个包含m个2D点坐标的向量;
,表示待定参数为x时,样本G对应的模型预测值,该函数返回一个包含m个2D点坐标的向量;定义函数S(x),表示从图像中提取的关于样本G的实测值,同理,该函数返回一个包含m个2D点坐标的向量;
定义重投影误差函数:
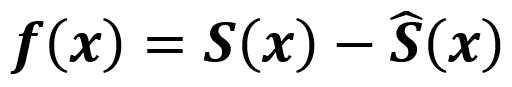
定义优化的目标函数:
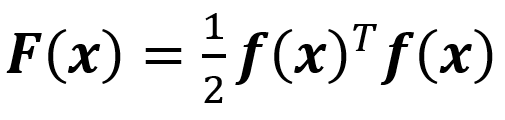
当x取最优解x*时,F(x*)取最小值。
此外,我们还需要手动提供一个x的初值x0,作为迭代优化的起始点。
在每一次迭代过程中,L-M算法会计算函数f(x)的雅可比矩阵J,然后根据公式(4)计算下一个x点距离当前点的步长∆xlm,
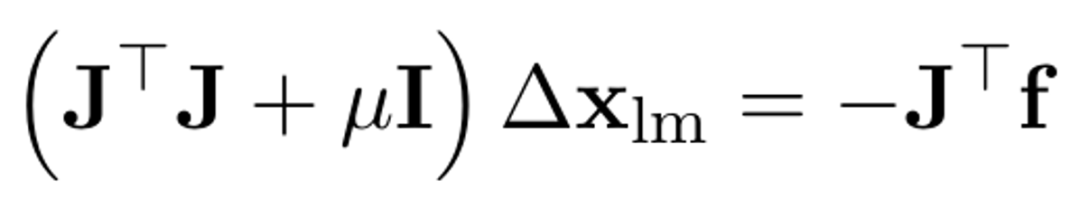
公式(4)
其中,μ≥0是一个阻尼因子,用于动态地调整∆xlm的步长。
为了方便讨论,我们先给出LM算法的伪代码,然后简要地讨论一下其中涉及到的数学工具,期望起到抛砖引玉的作用。

观察上述伪代码可知,LM算法的关键在于如何求解线性方程组(A+μI)h=g,其中h是由待定参数构成的向量,系数矩阵A=J(x)TJ(x)是一个n阶方阵,它的元素是对传感器图像运行某种特征提取算法得到的,比如图4所示的例子,是使用Matlab软件从相机拍摄的棋盘格图像中提取角点的位置坐标。

图4 使用Matlab工具提取棋盘格特征点
由于图卡不平整、曝光不均匀、软件四舍五入等随机因素的存在,矩阵A的元素值包含了多种误差的贡献,因此本质上并不存在一个“绝对正确的h”,我们只能希望得到一个“较好的h”。一般而言,参与计算的样本越多,离群样本的贡献就越小,得到的结果就越优。接下来的问题是,如何求解h向量才能获得最佳的数值精度和稳定性,因为不同的方法在特性上是有一定区别的。在实践中,我们经常会使用三种方法来求解线性方程组。
我们假定矩阵A的维度为nxn,h为n维列向量,包含n个待定的参数,I为n维单位矩阵,J或J(x)为mxn的雅克比矩阵。为了求解n个未知数,数学上必须有m≥n,否则这是一个欠定问题,h有无穷多解。当然,我们已经知道样本点是越多越好,所以m≥n本来也是在计划之内的。
进一步地,我们记y=f(x)为m维列向量,记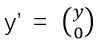 为(m+n)维列向量。另外,我们定义
为(m+n)维列向量。另外,我们定义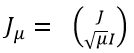 是一个分块矩阵,其维度为 m’xn,m’ = (m+n)。借助以上定义,我们可以把两个矩阵相加等价地表示成两个矩阵相乘,即:
是一个分块矩阵,其维度为 m’xn,m’ = (m+n)。借助以上定义,我们可以把两个矩阵相加等价地表示成两个矩阵相乘,即:
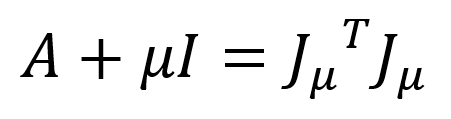
公式(5)
其中,上标T代表矩阵的转置操作。
我们马上会发现,使用两个矩阵相乘的表示方法会给我们带来很多便利。
方法一,Cholesky分解
对矩阵(A+μI)进行Cholesky分解,即:A+μI=RTR,其中I为单位阵,R为上三角矩阵。注意到矩阵A= J(x)TJ(x)+μI为正定矩阵,则R的对角元素为正。我们得到 RTRh=g,则利用两次“回代”即可求出h。
Cholesky分解计算速度很快,所以使用较为广泛,但该方法存在较大的计算误差。深入研究发现,Cholesky分解的误差正比于矩阵(A+μI)的条件数+,而它又等于矩阵Jμ条件数的平方。因此为减少数值计算的误差,我们的计算对象应该是Jμ而不是(A+μI)。
+矩阵的条件数
矩阵的条件数(condition number)是数值分析和线性代数中的一个重要概念,任意矩阵B的条件数为σmax / σmin,其中,σmax表示B的最大奇异值,σmin表示B的最小奇异值。条件数刻画了矩阵令向量发生形变的能力。条件数越大,向量在变换后可能的变化量就越大,而大的条件数会放大数据中存在的误差。关于条件数的介绍可参考书籍:Matrix Analysis-Roger A. Horn -2nd Edition
方法二 QR分解
我们注意到,方程(A+μI)h=g=-JTy,这是一个线性最小二乘问题,即min||Jμh+y'||2的正规方程(关于h的梯度等于0的方程),则求解该方程等价于求对应线性二乘问题的解。
我们对矩阵Jμ进行QR分解得到:Jμ∙P=QR=Q1R1,其中,Q是维度为m’xm的单位正交矩阵,R为m’xn维的上三角矩阵;Q1为Q的前n列,维度为m’xn;R1为R的前n行,维度为nxn;P为列变换基本矩阵,使得R的对角线元素的绝对值递减(即|Rii|≥|Rjj|,i<j),其维度为nxn。
将该QR分解等式带入线性最小二乘的式中化简可知,R1PTh=-Q1Ty',然后利用回代法,即可得到h。
QR分解法的计算误差正比于矩阵Jμ的条件数,而不是该矩阵条件数的平方,所以它比Cholesky分解更稳定,但会增加计算量。当优化变量的维度较小时,QR分解法使用比较广泛,实际上很多流行的最优化库(比如minpack和ceres)都是基于QR分解实现的。
方法三 SVD分解
将矩阵Jμ进行SVD分解,即:Jμ=USVT=U1S1VT,其中:U为m’xm’维的单位正交阵;S为m’xn维的对角阵;V为nxn维的单位正交阵;U1为U的前n列,维度为m’xn;S1为S的前n行,维度为nxn;将SVD分解等式带入线性最小二乘的式中并化简,可知:
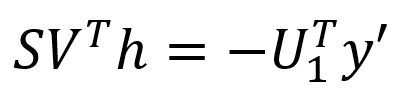
简单整理可得下方公式,即可计算出h。
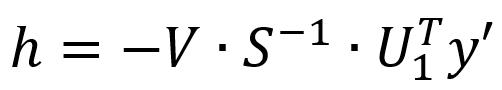
SVD法的稳定性很高,但其计算量也最大。
以上我们讨论了求解LM算法核心方程组时三种常用方法的优缺点。另外我们也注意到,以L-M算法为代表的非线性优化方法并不能保证总是给出收敛的解,其收敛与否往往与我们手动提供的初值质量有关。在工程领域,一个不保证总是有效的方案其可用性是大打折扣的,必须要有其它机制作为失效后的补充。因此,一个十分重要的研究课题是寻找一些稳定可靠的线性优化方法,一方面为主算法提供一个良好的迭代初值,另一方面可以作为主算法失效时的备选方案。限于篇幅,本文对此就不做展开讨论了,如果读者喜欢,后续可以专题讨论一下这个问题。
小结
在本文中,我们主要讨论了计算机视觉领域经常遇到的一个基础性问题,即如何定量地评价图像的几何畸变,以及如何通过数学建模的方法为镜头建立成像模型,从而能够定量地描述成像畸变并加以校正。当镜头模型建立后,为了求解模型中的待定参数,我们还介绍了L-M方法,这是一种非常实用的最小二乘非线性优化方法,在工程技术领域有着非常广泛的应用。虽然很多文献和资料都会有涉及LM算法的应用,但是讨论LM算法实现细节的资料却颇为少见,所以我们借本文简要讨论了求解LM算法可以使用的数学工具以及工具背后的数理逻辑,希望我们所讨论的这些思想方法和具体工具能对读者带来一定的启发,非常感谢广大读者对爱芯元智的关注和支持,我们下期再会!
审核编辑:汤梓红
-
用于分析镜头系统成像误差的工具2026-05-18 318
-
Matlab符号数学工具箱应用说明2009-09-22 4463
-
机器视觉检测设备相机的成像原理!2019-12-16 1935
-
数码相机的成像原理图2009-04-27 12052
-
数码相机成像原理2012-05-15 21032
-
一种用于形状精确描述的数学工具2017-12-25 939
-
可用于无创血红蛋白传感和成像的光学工具2022-08-15 2457
-
鱼眼相机的成像原理与成像模型解析2022-09-26 7327
-
如何学习相机模型与标定?2023-06-01 1707
-
浅谈工业相机镜头的参数与选型2023-11-03 676
-
如何提升科研级CCD相机成像信噪比?2025-06-09 1531
-
什么是快照式光谱成像相机?2025-09-12 1006
-
数学工程计算+失效分析,双轮驱动电路可靠性2026-02-27 487
-
浮思特 | 从原理到应用:红外热成像相机如何重塑智能检测与感知能力2026-04-24 319
-
AI时代如何在数学建模竞赛中取胜2026-06-12 234
全部0条评论

快来发表一下你的评论吧 !
