

芯片性能小谈—时间并行
EDA/IC设计
描述
众所周知,评估一颗芯片的好坏,PPA(performance,power,area)是最重要的指标之一。我们往往要从性能,功耗,面积三个维度来评估设计方案,进行trade-off。在设计的每个环节也会通过各种小技巧尽可能的全方位提升这三个指标。
1
性能的评估——带宽、吞吐量、时延
在讨论如何提高性能之前,得先看看如何评估性能。
从直观上来说,性能好代表着快。那么如何评估”快”呢?首先芯片根据应用场景分为很多不同的种类,通信类的5G,蓝牙,wifi;接口类的USB,以太网,HDMI;计算类的通用CPU,GPU,AI等。在不同的场景下其实都能通过一些统一的指标来衡量:带宽(bandwidth),吞吐量(throughput)和时延(latency)。我们所熟悉的CPU性能跑分,从微观层面来说,实际上评估的无非也是同一段时间内系统能正确处理多少段标准的代码,蕴藏有吞吐量的概念在里面。在计算机网络中,这三者的大致概念如下:
● 带宽: 信道上单位时间内能传输的最大数据量。
****● 吞吐量: 某段时间里,信道上单位时间内的有效传输的数据量。
****● 时延: 每一次有效传输所需要的时间。
这三个概念既可以作为宏观的计算机网络传输性能指标,从微观上来说,也可以作为芯片内部数据计算,传输的性能指标。比如AXI总线的数据传输,比如内存访问的数据传输,甚至是模块与模块间的数据传输。
以AXI总线为例,我们都知道这是一种高带宽,高性能,低时延的总线,其与同为AMBA总线的AHB和APB的对比如下:
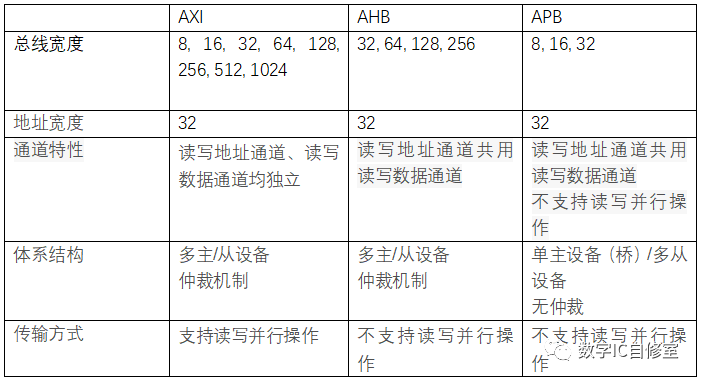
AXI的快,从带宽,吞吐量以及时延的角度来说,主要得益于以下特性:
● 带宽:
AXI支持更宽的总线宽度。更宽的总线宽度带来的好处毋庸置疑,一个周期传输的最大数据量更大。形象点说就是公路更宽了。
● 吞吐量:
- 读写通道独立带来的读写并行操作。读写通道独立意味着读操作和写操作可以并行。并行的好处自然是同一段时间内可以同时进行的读和写更多,完成的也更多,从而增加了一段时间内的有效数据传输量,也就是吞吐量。
- 流水/分裂传输。这里的流水/分裂传输用AXI文档里的说法叫outstanding。这是一种时间上的并行。在每笔读/写操作还未结束的时候就发送下一笔,这样一来同样一段时间内并行的读写操作更多,传输数据更多,增加了吞吐量。
- 猝发传输。用于连续地址的读写访问,一次地址发送在slave端可以同时访问多个连续地址,同一段时间内能访问更多的地址,传输更多的数据,增加了吞吐量。
- 乱序访问。相比于顺序访问,总线上自由度更大。顺序是一种约束,放宽了约束自然可以更肆无忌惮的传输数据。假设一种场景,传输1访问地址空间A,三个周期读回数据。传输2访问地址空间B,一个周期读回数据。因为顺序的约束,先得到数据的传输2无法返回数据,必须等到传输1完成,这样效率就很低。有了乱序的支持,后发出的操作如果先完成,可以先返回数据,这样一来吞吐量自然就更高。
● 时延:
- 地址数据通道独立。在AHB协议中,因为地址数据通道共用,一次写操作需要经历发送地址->发送写数据这样的步骤。而在AXI中,写数据和写地址可以同时发送,减小了一次写操作所需要的时延。
- 多主从设备/仲裁机制。与APB只有一个apb master从而导致需要2个cycle才能完成传输不同,AXI与AHB都是多主从设备,可以直接点对点完成传输,1个cycle就可以完成传输,减小了时延。虽然仲裁机制的引入一定程度上又增加了时延,但基于流水分裂传输,性能还是可以得到保证。
从上述AXI的特性以及其对性能带来的增益我们可以明显看到,性能的提升手段有很多,但这里面蕴藏的主要思想是类似的:提速与并行。道理很简单,想要更快,那么在一段时间里就需要做更多的事。
2
性能的提升——提速与并行
提速指的是减小时延(latency),即减小每次有效输出的时间。提速的方式可以来自于计算传输自身的算法优化,硬件升级。比如我们在设计的时候经常会做的去除冗余逻辑,本来1拍能做的事没必要2拍,这就是一种自身算法优化。而更先进的工艺,更小的门电路延迟,也可以减小硬件时延,算作是一种硬件升级。
提速也可以来自于并行。并行又分为空间并行和时间并行。其主要区别在于空间并行需要更多的物理资源,通过更多的资源同时运作来实现并行。而时间并行则是充分调度有限的资源,使其在一段时间内尽可能少的处于闲置等待状态。
举一个最简单的例子就是,你开了一个工厂,原计划在1个礼拜内完成一个项目交付,老板突然把要求提高了,让你三天完成,怎么办呢?可以有以下几种处理方式。
- 请更多的工人,同样一堆活丢给更多的人去做,这就是空间并行。
- 减少工人偷懒或者无所事事的时间,充分利用闲暇时间用来干活,同一时刻让更多的工人处于干活状态,这就是时间并行。
- 每个工人提升工作效率,做一项工作的时间缩短,这样相同时间就可以做更多工作,这可以类比于硬件上的算法优化和先进工艺。
在AXI的例子中,更宽的总线宽度,读写通道独立,地址数据独立属于空间并行,用更多的总线资源换来速度。流水/分割,猝发,乱序都是属于时间并行。而多主从的连接方式则帮助到了传输本身的提速。
3
时间并行——隐藏latency
这里主要讨论一下时间并行。还是基于AXI,从流水/分裂传输开始,也就是耳熟能详的Outstanding。
Outstanding的英文含义是未完成的。在AXI协议中,Outstanding的意思是在一个读写操作还没完成的时候就开始另外一个。
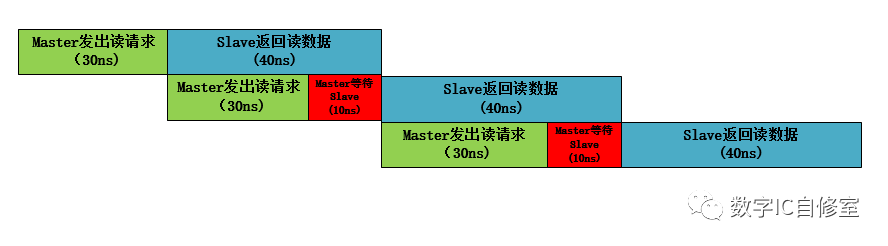
如下图所示,水平方向表示时间,如果没有Outstanding,那么总线在同一时刻只会有一个传输正在执行。两个传输必须要串行完成。这样完成两个读操作总共需要100ns。

但我们通过观察可以发现,一个完整的读操作由Master和Slave共同完成。Master处理地址发出读请求,Slave处理请求返回数据。如果把Master和Slave看成两个工人,工人M处理完读请求操作之后,在等待工人S返回数据的20ns里其实是啥事都不做的偷懒状态。为了提高效率,让工人M不偷懒,可以让他处理完第一笔读请求操作之后马上开始准备发出第二个请求。如下图所示:
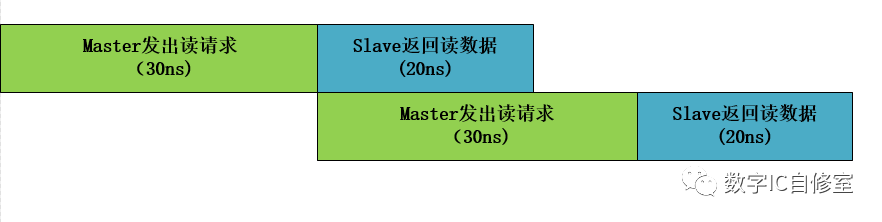
在鞭策了M之后,他发出第一个读请求之后,马上马不停蹄地开始处理第二个读请求。于此同时,S并行地处理着之前的第一个读请求。当M完成了第二个读请求发出时,因为S已经完成了第一个读请求的数据返回,M可以立马交付出自己的第二个读请求,开始第3个读请求的准备。这样一来完成两次读操作的总时间为80ns,相比第一种情况缩短了20ns。这20ns是S处理第一笔数据的时间,也就是latency,它被“隐藏”在M的第二次操作里。
上述的情况中,有一个前提条件是,S端返回读数据的latency要小于M发出读请求处理的latency。这样才能保证M发出读请求的时候S能马上收走。因为在AXI中是握手传输,即需要M端valid与S端ready信号同时有效才能进行传输。如果S某一次返回读数据的latency大于M端,M在完成了一次读请求之后需要等待S端的ready信号,从而还是会有闲置状态,如下图所示:
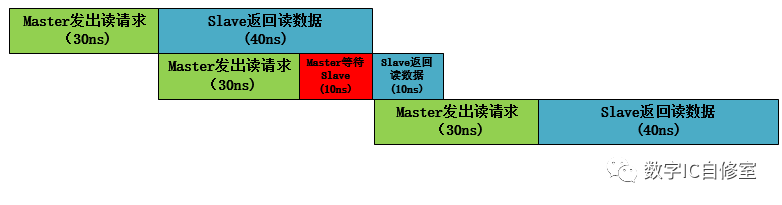
在上图中,由于在第二次传输的时候Master等待了10ns,三次读操作总共用了140ns。
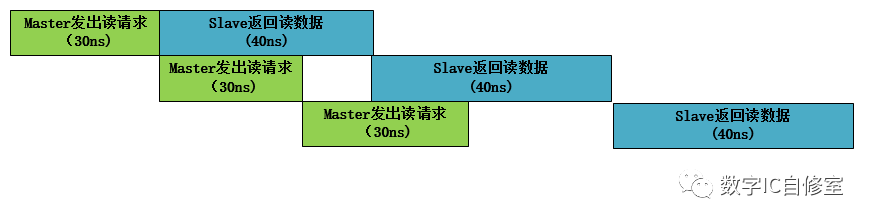
一个解决此问题的办法是改变M和S的交互方式。假想M发出请求之后,如果有个地方可以缓存这个请求,M就可以腾出手去做别的事了。这个缓存可以用BUF来做到。如果S特别慢,M发出好几个请求S都来不及收,就缓存更多,并满足先发的请求先被处理,则可以使用FIFO进行衔接。如下图所示:
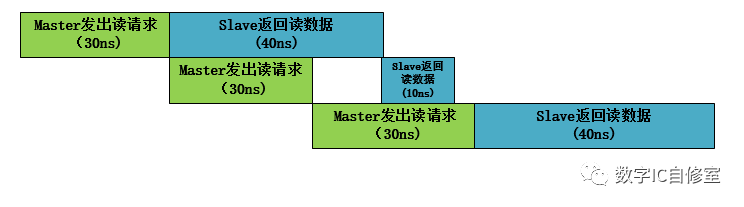
在有了BUF缓存之后,M的第二次操作完成时可以直接进行第三次操作,以此节省了10ns的等待时间,三次读操作总共只需要130ns。在AXI里,如果有outstanding设置,M与S之间都会有buffer来进行此类缓存,保证同时可以有多个数据传输并行。此时的slave ready信号其实是这些缓存FIFO的非满信号。
从上面的例子中,我们看到了outstanding的魔力,成功地将latency隐藏起来,从而提升了系统的性能。这里的性能提升点为吞吐量,因为单位时间的有效输出数据增加了。并行之所以重要,是因为在这些例子里的时延latency,即master发出读请求和slave返回读数据本身需要的时间,一般来说是比较难降低的。Master发出读请求前需要处理计算地址,以及slave返回数据时可能有的Memory读取时间,在设计没太大毛病的基础上,要缩短只能靠工艺的升级,内存结构的改变。而要提高系统的吞吐量,只能想办法将一部分latency隐藏起来。
4
时间并行的瓶颈
以上的一切看起来很好,但如果这样的并行技术那么牛逼,照理说我们可以使系统无限快才对。当然这样的技术还是有一定的局限性的。它使用的前提是Master端是效率的瓶颈。如果Slave端总是比Master端更慢,那么实际上系统的吞吐量并不能得到增加,看以下两个例子:
从上面两图的对比我们可以看到,虽然Outstanding技术可以帮助Master以最快速度发出三个请求,但这三笔读数据最后完成的时间和与不使用该技术是完全一样的。这是因为在此例子中Slave端的处理速度才是瓶颈所在。
那么如何解决这个问题呢?其实这个问题一直是计算机系统效率提升的头号问题,即著名的”Memory Wall”。可以将上图中的Master看作是CPU计算单元,Slave看作是系统内存DRAM Memory。因为访问系统内存的时间本身远远大于CPU计算单元本身处理,而 CPU在变得原来越快(多核处理器,superscalar等),DRAM的读取速度相比之下比较难提高(虽然有DDR,HBM等技术,但还是要寄希望于DRAM本身的提高),这个差距在越拉越大。
目前在计算机体系中使用的是缓存技术,用高速的SRAM作为一个“假”的Memory来进行访问。只在必要的时候访问DDR。对应到上图中实际上是缩短了蓝色色块Slave返回读数据的时延latency。
5
完美的时间并行——Pipeline
从上面的Outstanding技术中,我们可以发现,Master与Slave端自身的Latency对并行的效果会有很大影响。如果Slave端Latency较大,Outstanding无法很好起到提升吞吐量的效果,并且Master需要很多的BUF来储存自己的数据。而如果Master的Latency较大,上述的Outstanding是否效率最高呢?
从上图中我们可以看到,虽然Master端效率达到了最高,工人M一刻不停歇地处理数据,但是Slave在接受处理完Master发出的第一个请求后,有10ns的空闲时间在等待M的第二个读请求。因为Master是主动方,Slave在收到Master的请求之前没法做别的事,要避免Slave白等,只能将Master提速。如果Master的latency也是20ns,那么系统中将没有任何等待,如下图所示:
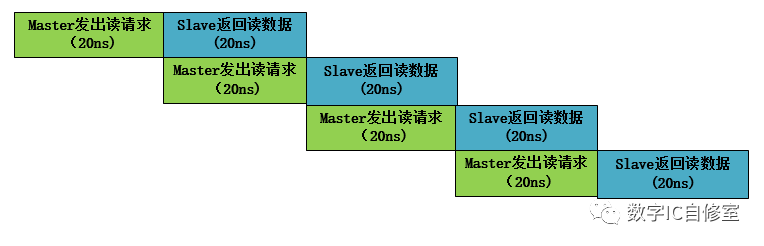
我们知道,如果你迟到了,让一个人某一次等了一个小时,可能他没什么感觉,也不会生气。但如果每天都让别人等1小时,一个月是30小时,相当于这个人这个月花了一天的时间来等你,他还能没感觉吗?
对于系统来说也是一样的道理。某次传输存在等待问题不大,但若每一次传输都存在等待,整个系统的效率将大大降低。因此最完美的并行是没有等待的并行,也就是master发出请求的时候,slave刚刚处理完上一个请求,准备开始下一个。
以上的讨论都基于两个工作者,M和S。但就像大鱼吃小鱼一个道理一样,你是一个人的Slave,也会是其他人的Master,生物链是一环扣一环的。系统也一样,有可能是层层往下传递的。上述的例子读操作起始于M,经过S,终止于M。如果加上AXI的网络(实际情况也不会是直接bypass访问),Slave1在接收到读请求之后,只是将其做了预处理,又继续往下发放到Slave2, Slave3, 直到真正的Memory Slave,如下图所示:
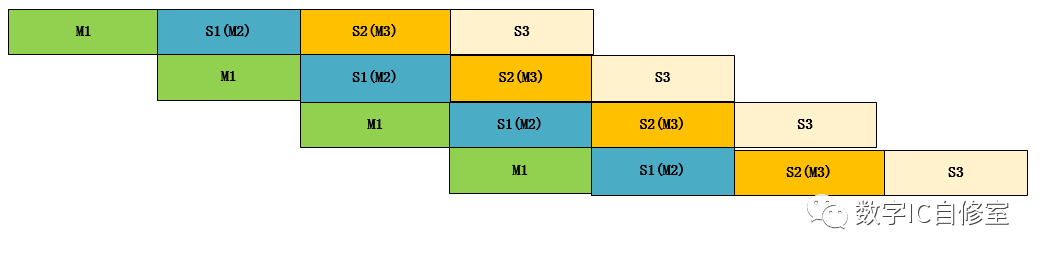
上图是一种理想状态,每一对M与S都不存在等待问题,这在现实中很难做到,因为不同的功能块时延Latency很难做到一致。但还是先来看看这种理想状态。
因为级数增多了,总的效率提升更为显著。并且随着传递深度的提升,Latency的隐藏更为显著。整段时间内最多有4个任务在并行,并且这四个任务的Latency相等,有多达3段latency被完美隐藏!
这么完美的并行技术,无法天然形成,但不利用岂不可惜!我想大家都已经知道了,这就是经典的Pipeline技术。我们会将一些时延较长的电路手动分割成几个部分,每个部分之间有寄存器链接,这样一来虽然每个部分的时延latency不同,都会在一个时钟周期的时候同时更新:Master在时钟上升沿传递数据,Slave在时钟上升沿完成上一数据处理。Pipeline技术大大提高了系统的吞吐量,深度越深,提升越显著。
理论上来说,任何的电路都可以使用Pipeline技术,但最经典的应用莫过于CPU流水线处理器。下图是经典的MIPS 5级Pipeline处理器流程:
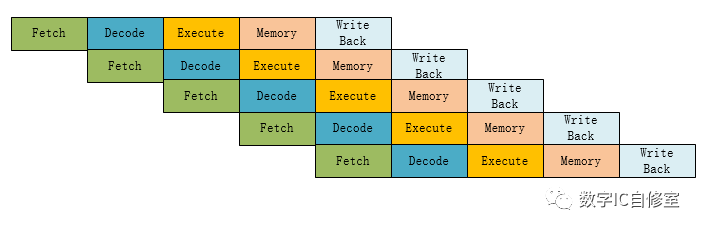
指令的生命周期分别有5个阶段: Fetch读取指令,Decode指令解码,Execute指令执行,Memory内存访问,以及Write Back指令回写寄存器。最后一步结束后一条指令即完成执行。从上图可以看出,在不考虑数据依赖关系的理想状态下,有了Pipeline并行技术的加持,在从第5个周期开始,每个周期都可以完成一条指令,大大提高了吞吐量!
6
小结
今天介绍的并行技术其实只是抛砖引玉,也只是设计中并行思想的冰山一角。这种思想可以是outstanding,可以是pipeline,其实还可以是很多很多其他的技术细节。希望大家能应用到平时的设计中,多想想那些地方是存在等待的,那些地方就是效率提升点。
-
 jf_73143430
2023-11-17
0 回复 举报很清晰,太棒的文档了 收起回复
jf_73143430
2023-11-17
0 回复 举报很清晰,太棒的文档了 收起回复
-
请问如何使用fx3芯片来对FPGA进行并行配置?2024-05-28 423
-
芯片性能小谈—时间并行2023-06-05 3549
-
如何使用FPGA驱动并行ADC和并行DAC芯片2022-04-21 8694
-
可编程并行接口芯片应用2021-07-22 1482
-
浅析云计算和并行计算2020-05-03 5580
-
并行编程对单芯片多处理性能有什么影响?2019-08-01 1535
-
怎样成为一名异构并行计算工程师2019-04-09 3589
-
AI芯片谈算法不谈智能,谈实现不谈芯片!2018-08-24 3461
-
时间数据流的并行检测算法2018-03-06 1094
-
基于并行搜索和快速插入的算法2018-01-07 924
-
基于Spark的BIRCH算法并行化的设计与实现2017-11-23 1129
-
12位并行模/数转换芯片AD1674及其应用2016-01-25 1416
-
14位并行模数转换芯片AD9240及其应用2009-04-30 1915
-
MCS-51并行口的扩展2008-12-20 872
全部0条评论

快来发表一下你的评论吧 !
