

处理器基础抱佛脚-存储器部分
处理器/DSP
描述
2 存储器
存储器是用来进行数据存储的(指令也是一种数据),按使用类型可分为只读存储器ROM(Read Only Memory)和随机访问存储器RAM(Random Access Memory),RAM是其中最为常见的一种形式。
2.1 半导体存储器
2.1.1 RAM:可读写并支持随机访问的存储器
静态随机访问存储器(SRAM)
由MOS组成触发器实现,快速,可保持电平,昂贵,读写速度快,所用管子数目多,单个器件容量小,面积大,相同比特下是DRAM面积的几倍
动态随机访问存储器(DRAM)
比较慢,不可保持电平,需要刷新,相对廉价,所用管子少,芯片位密度高,存取速度慢。
DRAM采用电容来存储带来的问题:
- 充电的效果将在读取时被消耗,所以必须在读取后重新充电
- 更糟糕的是,即便不读,也会有漏电
- 每个单元都必须定期被刷新
解决方案和产生的问题:
- 存储器的控制电路周期性的顺序读取每个单元的内容并回写
- 在刷新周期内CPU不能使用这部分存储器,因此降低系统性能
DRAM电容容量的trade-off:
- 我们需要大的C以便于它不要太容易泄漏完
- 但是大的C会带来大的时间常数和延迟
DRAM相较于SRAM的主要优缺点
- DRAMs 可以做得很大,lots of bits in the same area
- 但是它们比SRAM慢
2.1.2 存储器的基本参数
容量——以字节或比特数表示速度——以访问时间TA、存储周期TM或带宽BM表示
- TA——从接收读申请到将信息读出存储器输出端的时间
- TM——连续两次启动存储器访问所需的最小时间间隔
- BM——单位时间内读取到或写入的数据量
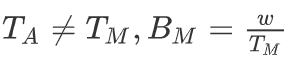 , w为数据总线宽度
, w为数据总线宽度
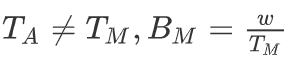 , w为数据总线宽度
, w为数据总线宽度成本——以每位价格表示
2.2 存储器层次结构
存储器的层次结构是依靠存储器访问的局部性实现的。现代计算机大多采用寄存器-高速缓存-主存(内存)-辅助存储器(磁盘)结构
- 目前正在使用的指令或数据或者将要用到指令或数据应该在高速缓存中过一段时间才会用到的
- 指令或数据应该在主存储器中
- 暂时用不到的程序或数据应该在磁盘中
- 如果大部分访问都是对高速缓存进行的,那么我们就不大感觉到主存储器和磁盘的速度慢,好像我们有一个又大又快的存储器
层次结构存储系统的性能一般由命中率来衡量
- 命中(hit)——对层次结构存储系统中的某一级高层存储器来说,要访问的数据正好在这一层
- 缺失(miss)——对层次结构存储系统中的某一级高层存储器来说,要访问的数据不在这一层,而在下面的层次
- 追求访问效率e尽可能接近1
2.3 Cache
容量小,比寄存器慢、比内存快,保存最近操作过的内存数据副本,对于程序员透明的通常与处理器在同一芯片上。
2.3.1 局部性原理
处理器访问存储器时,无论取指令还是取数据,所访问的存储单元都趋向于聚集在一个较小的连续单元区域中。
时间局部性 (如循环语句)——如果一个位置被访问,很有可能马上再次被访问
空间局部性 (如程序顺序执行、数组顺序访问)——地址相近的一些单元在最近也将被访问
2.3.2 Cache结构
Cache 由 Cache 存储体、地址映象与变换机构、 Cache 替换机构几大模块组成。以行( Cache Line )为单位进行存储的,一个缓存行对应主存的一个数据块。N个行,每行K字节数据。通过标签来知道这一行存的是内存中哪一段地址对应的数据。有效位用于确定 Cache 行是否含有有效地址。平均访问时间= tc+(1 - H)tm。
统一结构 ——指令和数据用同一个Cache,根据当前程序的需要自动调整指令在Cache中的比例,能够获得比固定划分更好的性能
哈佛结构 ——指令和数据采用分开的两组Cache,使load/store指令能够单周期执行
2.3.3 Cache地址映象与变换
全相联
主存中的每一块能够装入到 Cache 中的任意一行中 ,数据在主存中的地址由“主存块号”和“主存的块内地址”两部分组成。“主存的块内地址”位宽与一个 Cache Line 的位宽相同,地址中剩余位宽为“主存块号”在 Cache 中被当作“标签”存储下来。当 CPU 访问某一地址的数据项时,该地址的主存块号将与 Cache 内所有行的标记相比较,若无有相同项,则不命中,若有相同项,则检查该行的有效位是否为 1 ,若有效则命中,同时根据块内地址读出行内对应地址的数据,若无效则不命中。对于 Cache 不命中的情况,则需访问主存以读取相应数据。
需要并行的搜索匹配标签方法(相联搜索比较所有标记)、电路复杂;命中率较高 、Cache 的空间利用率较高 。
直接映像
主存中的每一块只能装入到 Cache 中唯一的特定行中,Cache行号 ==(主存块号 mod Cache 的行数),主存地址中中间几位即为 Cache 行号。访问某一地址的数据时,只需检查对应 Cache 行号所存储的标记是否与当前地址的主存标签一致,若一致且该 Cache Line 有效,则命中,否则不命中。
搜索匹配标签方法相对简单、电路易于设计;命中率低、 Cache 的空间利用率也低。
组相联
每个块可以存放在 Cache 中的 n(≥ 2) 个固定的位置上,称为 n 路组相联映像 。这有相互关联的 n 行被称为 1 组 Set。组间直接映像,组内全相联映像 。访问某一地址的数据时,只需并行检查该组内对应Cache 行号所存储的标记是否有与当前地址的主存标签一致的标记,若有且该 Cache Line 有效,则命中,否则不命中。
直接映像 1 路组相联 ,全相联N 路组相联,优缺点介于全相联和直接映像之间 。
2.3.4 Cache数据替换与更新
数据替换是指缓存中没有合适的空余位置,必须将已有的缓存行从缓存中清除,代之以新的缓存行的过程。
数据更新是指写操作将已有缓存行中数据更新为新值的过程。
数据替换
随机法 ——从所有缓存行中随机挑选一个替换掉。实现简单,不需要存储关于缓存行的任何信息。
先进先出 (FIFO)——选择最先放入缓存中的行进行替换。
最近最少使用 ( LRU )——选择所有缓存行中距离上次被访问时间最久的行进行替换。
后两种方法较为高效,需要记录各缓存行被放入或访问的时间等信息。
数据更新
写通过 (Write-Through)——在写入时同时访问缓存和主存,写入时间是访问主存时间(慢)。设计简单,不需要记录额外的信息,缓存与主存始终一致,不需要维护一致性,替换时无需将调出的块写回主存;每次访问需要的时间长。
一种缓解机制是使用 带缓冲区的写通过 ,在写入主存时通过一个很快的缓冲区,当缓冲区未满的时候就不需要等待主存完成写入。所有写操作仍然直接对主存操作,但数据不是直接写入主存,而是将要写的地址及数据保存到可以高速接收写信息的写缓冲器中。使用缓冲区可以一次写入大量的数据,在此后一段时间内慢慢地将数据写回内存。但同时,由于缓冲区内容与主存不一致,在读操作前,需要确认被读取的内容是否在缓冲区内。
写回 (Write-Back)——在写入时只访问缓存,当被修改过的缓存行被替换掉时才写回主存。需要为缓存行维护一个脏( dirty )位,并在写回时访问主存,以此保证缓存中数据与主存的一致性。缓存行由于读取而被存入缓存中时,脏位是 0 ,表示缓存内容与主存一致;当缓存行被写入或由于写入操作存入缓存中时,脏位是 1 ,表示缓存内容与主存不一致,如果该行被替换,必须将数据写回主存。在被替换之前,脏的缓存行可以直接读取、写入,而不需要访问主存。
2.3.5 Cache缺失
引起cache 缺失的原因有三种:强制(compulsory )缺失,容量 capacity )缺失和冲突(conflict )缺失 3C。关联度越高,冲突失效就越少;强迫性失效和容量失效不受相联度的影响;强迫性失效不受Cache容量的影响,但容量失效却随着容量的增加而减少。
强制缺失
由于某段数据从未被访问过而不得不产生的缺失。强制缺失只在首次访问某段数据时产生,无法避免。增大块大小可以在一定程度上缓解强制缺失,但会使得缺失损失增大。
-
增加块尺寸
-
对指令cache非常有用的办法
-
弊端
l 如果不命中, 损失变大l 更大的块尺寸意味着可能更多的没有必要的事先读入的数据
l 如果块尺寸太大,会造成更多的冲突性缺失
容量缺失
由于 cache 容量有限导致的缺失。当 cache 被完全占满而必须进行数据替换时即发生容量缺失。无穷大的(理想) cache 不会发生容量缺失。增加 cache 容量可以降低容量缺失。
-
增加Cache容量
-
弊端
l 大的Cache导致命中时间增加
冲突缺失
由于 cache 相联性不足而导致的缺失。当 cache 没被占满,但是由于相联性不够,导致必须发生数据替换时即为冲突缺失。全相联 cache 不会发生冲突缺失。对于冲突缺失,增加相联性可以降低冲突缺失,因为增加相联性就是增加了缓存行可以存放的位置数目,使得冲突可能性降低。增加 cache 中的块数也可以降低冲突缺失,因为这样一来相联性划分得更细,原来的块 访问将映像到不同的组 ,降低了冲突的可能。
-
增加相联性
-
一个全相联的Cache将没有冲突引起的缺失
-
但是
l 更多的相联意味着更复杂的硬件l 更长的访问延迟
2.4 Cache性能评估
2.4.1 性能方程

其中第一项与硬件无关,第三项只与时钟频率有关,Cache 所影响的只有第二项 CPI 。在引入 Cache 之前,我们给出了各种指令所需要的执行周期数,对于访存指令,我们认为所有的访存时间都相同,这实际上假定了所有访存指令都 Cache 命中。存储器停顿时钟周期数可以分为读、 写操作引起的停顿。
2.4.2 多级Cache
L1 Cache致力于减少命中时间,以获得较短的时钟周期;L2 Cache致力于降低缺失率,以减少访问主存的缺失损失。
-
存储器是如何组织的?是如何与处理器总线连接的?2021-07-26 1735
-
浅析STM32F103处理器内部存储器结构及映射2021-12-09 2596
-
NAS网络存储器的处理器2010-01-09 855
-
什么是处理器缓存2010-02-04 1225
-
LSI推出无需外部存储器的多核通信处理器APP31002010-04-27 843
-
ARM处理器存储器及存储器映射I/O2017-10-18 1478
-
微处理器又称为什么2018-10-31 26645
-
EE-271: 高速缓冲存储器在Blackfin®处理器中的应用2021-03-21 928
-
EE-286:将SDRAM存储器连接到SHARC®处理器2021-04-28 1136
-
EE-213:通过Blackfin®处理器的异步存储器接口进行主机通信2021-05-25 961
-
利用MAXQ处理器中的非易失性存储器服务2023-03-03 1722
-
内存储器分为随机存储器和什么2024-10-14 5304
-
EE-213:Blackfin处理器通过异步存储器接口进行主机通信2025-01-05 637
-
EE-286:SDRAM存储器与SHARC处理器的接口2025-01-06 552
-
EE-271: 高速缓冲存储器在Blackfin处理器中的应用2025-01-07 444
全部0条评论

快来发表一下你的评论吧 !
