

端到端自动驾驶到底是什么?
汽车电子
描述
CVPR 2023 落下帷幕,Best Paper 之一花落上海人工智能实验室 OpenDriveLab 团队和武汉大学联合团队的工作 UniAD。
UniAD 获得了多个首次:
CVPR 首次将最佳论文授予纯自动驾驶领域。
自动驾驶界首个开源具备全栈关键任务的端到端自动驾驶模型,统一了多个自动驾驶子任务。
十年来首次中国本土团队获得 CVPR Best Paper。
UniAD 统一自动驾驶关键任务,但是端到端的训练难度极大,对数据的要求和工程能力的要求比常规的技术栈要高,但是由此带来的全局一致性让整个系统变得更加简洁,也能够防止某个模块进入局部最优,而不是全局最优。
虽然整体称为端到端,但是各个模块直接确实有着明显的界限和区隔,并非一个整体黑盒网络。
各个模块间有了相当的可解释性,也有利于训练和 Debug,为自动驾驶端到端的设计提供了一个很好的范本,也期待在工业界的应用。
在正式讨论这篇论文前,其实有一个问题,端到端自动驾驶到底是什么?
01
端到端自动驾驶到底是什么?
经典的自动驾驶系统有着相对统一的系统架构:
探测(detection)
跟踪(tracking)
静态环境建图(mapping)
高精地图定位
目标物轨迹预测
本车轨迹规划
运动控制
几乎所有的自动驾驶系统都离不开这些子系统,在常规的技术开发中,这些模块分别由不同的团队分担,各自负责自己模块的结果输出。
这样的好处是,每一个子系统都能够有足够好的可解释性,在开发时能够独立优化。
与此同时,为了保证整体自动驾驶的性能,每一个模块都需要保证给出稳定的表现。
所以事实上在一个 Bug 出现时,需要巨大的 Triage 团队对 Bug 进行分析,然后将具体的 Bug 来源分配给责任团队。
据说在 Waymo,甚至有超过 200 人的团队,对 Bug 进行分析和责任分配。
那找 Bug 来源和 Bug 优化的任务就不能自动化吗?
当然可以, 如果我们能将各个模块用可微分的方式连接起来。类似于传统深度学习,出现误差时,深度自动回传进行权重更新。
某种程度上,这就是端到端自动驾驶的概念。
02
理想化的端到端自动驾驶
事实上,从自动驾驶开始发展,就一直伴随一个看似幼稚但是非常复杂的疑问:
为什么我们不能开发一个系统,输入时是传感器信号(摄像头,激光雷达),输出是控制指令(转向,刹车,加速)?
这个问题,实际上,业界也一直有人在探讨,甚至于国内 2018 年还有一家公司给出了这样计划:
其方案
输入为视觉信号,输出为 Steering,Brake,Accelerate,而真值为真实人类司机的上述动作。
输入输出都有了,真值数据也有了,接下来就是塞进看不太懂的胶囊神经网络里进行全局优化训练,最后就能给出结果。
这个方案好在没有吸引到什么大手笔投资,很快就销声匿迹了。
不过这两天,大模型出来之后,我甚至也看到了一模一样的计划,只不过网络换成了大模型。
03
为什么完全端到端目前不可行?
神经网络的黑盒效应让完全端到端自动驾驶无法找到正确优化方向。
本质上又回到了最初的问题,模块解耦让多模块单独优化成为可能,让每一个模块拥有独立的可解释性。
而如果变成一个巨大的神经网络模块,这种基于统计学的神经网络是无法保证在正确的道路上持续优化的,因为无法保证对未见过的物体的鲁棒性,也无法对某一个具体的 Bug 进行定向改进。
可能会有人会问,那语言大模型表现可以迁移吗?
泛化性的迁移是可行的, 根据 Google 的研究结果,他们基于语言大模型的抓取机器人,已经可以做到对没有见过的物体有直接的泛化能力,例如他们要求从未见过乌龟的机器人抓取一只乌龟,任务能够被很好地完成。
因为很好地使用了大语言模型的泛化能力,但是这件事情在自动驾驶上,尚未得到验证。
但是如何对一个具体的 Bug 进行改进?
假设出现了一次误刹,经典的自动驾驶技术栈会分析:
刹车指令的来源,是前方动态障碍物,还是静态物体?
或者是规划模块的速度规划出现问题?
或者是控制模块在输出正确的情况下,控制指令出现了问题?
根据这些然后再进行定向优化。
但是,完全端到端,就失去了这种定向优化的能力,甚至都无法知道,具体应该提供哪种数据进行定向优化。
而理想在上周提到的红绿灯意图网络(TIN)也同样是一个视觉输入到转向意图的整体设计创新,令人印象深刻。
但是对于具体如何应用到量产中我其实并不乐观,一个这样的网络硬件部署难度和实际效用的收益比尚且不论,而优化过程是一个更加大的命题。
如果答案是加上所有的量产数据,显然不能说服工程界,期待之后有更加深入的介绍。
当然,Elon Musk 在上个月的 Twitter 中,画了一个巨大的视觉到控制指令的饼,但是我也绝不认为他们正在研究的模型内部是一个完全黑盒的网络。
04
工程派的端到端自动驾驶 UniAD
整体自动优化,可解释性我统统都要
为了解决整体优化问题,UniAD 使用了一个巨大的 Transformer 网络,但是为了保证每个模块有足够的可解释性并能够被独立优化,这个网络被分割成多个共享 BEV 特征的 Transformer 网络。
首次将跟踪、建图、轨迹预测、占据栅格预测统一到一起,并且使用不依赖高精地图的 Planner 作为一个最终的目标输出,同时使用 Plan 结果作为整体训练的 loss 来源。
也就是说,UniAD 并没有完全抛弃原有的自动驾驶技术栈,而是改变了子模块连接的方式,传统可能是靠规则和显式连接,例如先从检测网络拿到目标物体的位置和速度,再喂给下一个模块。
这种规则和显式连接的方式无法完成梯度传播(神经网络的自我迭代方式),只能靠人工优化。
但是 UniAD 共享了 BEV 特征,将子模块用神经网络的方式连接起来。这样就保证了整体网络的一致性,能够完成梯度的前向传播,也就有了自动优化的能力。
整体流程
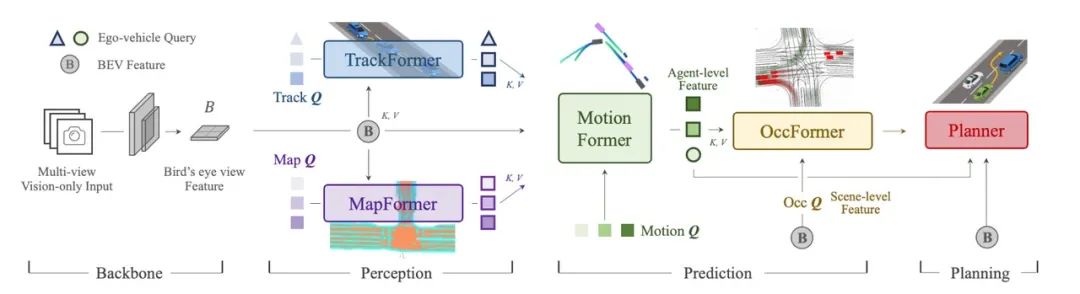
从流程上看,首先将环视的图片以 Transformer 映射到 BEV 空间供后续模块使用。
TrackFormer 根据 BEV 信息进行推理,融合了检测和跟踪任务,输出为目标检测和跟踪的信息;
MapFormer 根据 BEV 信息给出实时地图构建结果;
之后 Motion Former 将 TrackerFormer 的结果和 MapFormer 的结果和 BEV 结果进行融合,最后得出周围物体整体轨迹和预测。
这些信息会作为 OccFormer 的输入,再次与 BEV 特征融合作为占据栅格网络预测的输入。Planner 的目标是防止本车与占据栅格碰撞,作为整个大模块的最终输出。
前景
面对一个巨大的,并且分模块的任务,训练过程一定是非常不稳定的。
文章中提到,根据他们的经验,他们会先训练 6 次 Percecption(Track 和 Map )部分,再训练 20 次整体,最后得到比较好的结果。
这种训练方式也是得益于整体设计的相对解耦,感知模块可以被单独训练。能够在获得一个相对已经稳定的感知结果的基础上,进行后续模块的训练,同时也对感知模块进行优化。
这种设计为工业界使用提供了一定的便利,多个模块之间的输出可以被单独 debug,也能被统一优化。
而在工业界相对比较多的本车 Plan 相关数据也为整个网络的训练提供了保证。
UniAD 的输出到了Planning 就截止了,确实因为后面控制的内容就不属于计算机视觉领域了,并且其实控制模块用 Learning 的方式其实并没有的得到承认 期待一些公司的部署结果。
写在最后
关于自动驾驶的未来,各个模块之间的界限越来越模糊,与此同时,配套的开发工具链也需要从模块解耦转换到模块融合。
有意思的是,恰逢其时,来自 Waabi 创始人,著名研究学者 Raquel 的一篇文章 CVPR Highlight UniSim 也非常值得一读。
使用 NeRF 相关技术,统一了场景编辑、Camera 仿真、Lidar 仿真、交通仿真多个任务。
这篇文章为高效端到端的仿真训练提供了可能性。
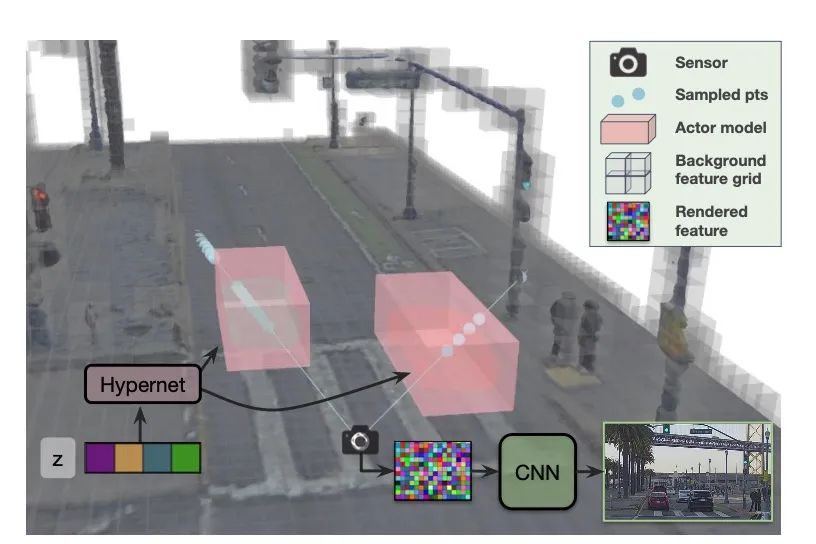
虽然从算法创新的角度看,太阳底下没有什么新鲜事,UniAD 是 Tranformer 的工程化创新,UniSim 是 NeRF 的工程化创新。
但是自动驾驶本身就是一个工程问题,工程化和快速迭代的能力会越来越重要。
学术界已经有了非常明显的转变,国内工业界某些公司却似乎还在每天宣传自家算法的巨大创新。
甚至在这次 Best Paper 发布之后, 知乎上很多人诟病 UniAD 算法不够创新。
可是自动驾驶作为一个巨大的工程问题,为了创新而创新是无法带来真正量产可用的系统的。
这种反差倒也是一件非常有意思的事情。
编辑:黄飞
- 相关推荐
- 热点推荐
- 机器人
- 控制模块
- 自动驾驶
- Transformer
-
如何基于深度神经网络设计一个端到端的自动驾驶模型?2019-04-29 6195
-
端到端自动驾驶的基石到底是什么?2024-02-22 1006
-
实现自动驾驶,唯有端到端?2024-08-12 2750
-
Mobileye端到端自动驾驶解决方案的深度解析2024-10-17 1756
-
连接视觉语言大模型与端到端自动驾驶2024-11-07 1496
-
端到端自动驾驶技术研究与分析2024-12-19 2070
-
一文带你厘清自动驾驶端到端架构差异2025-05-08 1306
-
为什么自动驾驶端到端大模型有黑盒特性?2025-07-04 1188
-
Nullmax端到端自动驾驶最新研究成果入选ICCV 20252025-07-05 2083
-
端到端自动驾驶相较传统自动驾驶到底有何提升?2025-09-02 1172
-
西井科技端到端自动驾驶模型获得国际认可2025-10-15 1544
-
自动驾驶中端到端仿真与基于规则的仿真有什么区别?2025-11-02 1983
-
如何训练好自动驾驶端到端模型?2025-12-08 1763
-
自动驾驶端到端为什么会出现黑盒现象?2026-02-20 9720
-
端到端时代的自动驾驶,哪些岗位更加吃香?2026-06-12 290
全部0条评论

快来发表一下你的评论吧 !
