

一种完全由LLM + 启发式搜索算法结合的TOT算法
描述
今天分享一篇普林斯顿大学的一篇文章,Tree of Thoughts: Deliberate Problem Solving with Large Language Models[1]:思维之树:用大型语言模型解决复杂问题。
这篇工作还是非常有借鉴意义的,OpenAI的Andrej Karpathy(前Tesla AI高级总监、自动驾驶Autopilot负责人)在state of gpt[2]中也分享了这篇文章,其可以通过搜索多条解决路径,利用dfs以及bfs等算法,像人类一样利用回溯、剪枝等策略来思考和解决问题,可以让GPT-4解决一些更复杂的推理问题。
一、概述
Title:Tree of Thoughts: Deliberate Problem Solving with Large Language Models 论文地址:https://arxiv.org/abs/2305.10601 论文代码:https://github.com/princeton-nlp/tree-of-thought-llm 非官方代码:https://github.com/kyegomez/tree-of-thoughts
1 Motivation
大模型的推理过程是一个token级别的,从左到右的一个决策过程,对比人类的思考方式来说,有着非常大的局限(例如人类写文章,写着写着发现写错了,我们可以回过头来,重新修改前面的内容,然后再继续往后写,而大模型LM不能这样),这使得大模型在需要探索,全局分析(前瞻探索或者回溯),初步决策发挥关键作用的任务中效果不太好。

现有大模型的缺点:1)局部性:现有LM模型不会在思维过程中探索不同的延续,即不会去探索当前节点的其他分支解决方案。2)缺乏全局性:大模型LM没有纳入任何类型的规划、展望或回溯来帮助评估不同的选项。
人类推理特点:可以重复使用可用的信息来进行启发式的探索,促使挖掘出更多真正有用的信息,找到最终的解决方案。
2 Methods
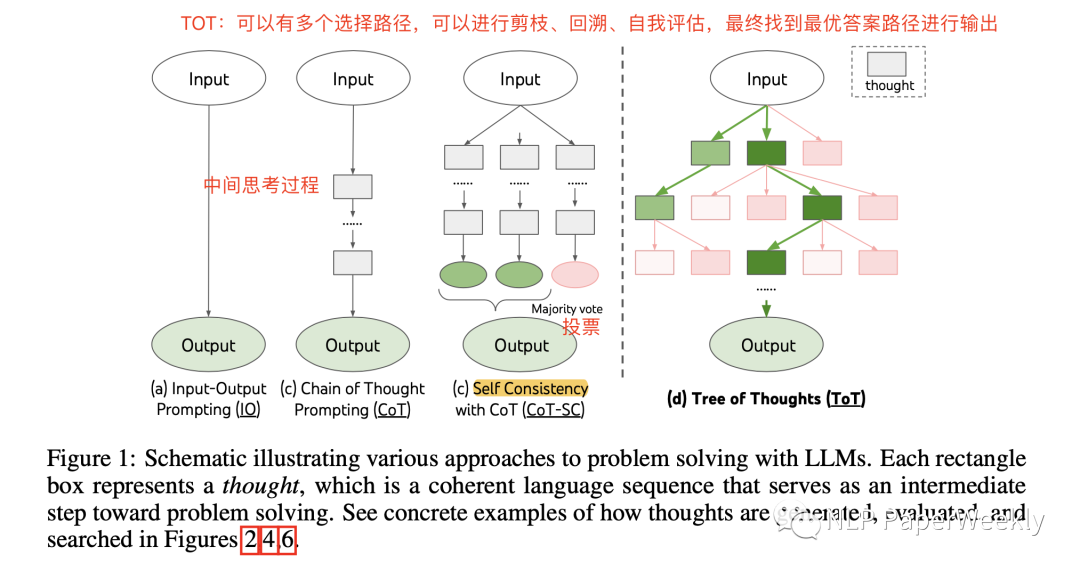
提出了Tree of Thoughts(ToT)方法:其允许LM通过考虑多种不同的推理路径并且能进行自我评估选择来决定下一步行动,并在必要时looking ahead或回溯以做出全局选择(可以用dfs或者bfs等方法做全局探索),从而进行深思熟虑的决策。
主要通过Thought decomposition【thought分解】,Thought generator【thought生成】,State evaluator【状态评估】,Search algorithm【搜索算法】四个步骤完成,详情如下。
2.1 Thought decomposition【thought分解】
目的:如何将中间过程分解成一个思维步骤【不同任务的thought steps怎么设计比较好】

方法:不同的任务,中间的思考过程thought可能不同,例如可能是几个words(Crosswords填字谜游戏),可能是一个equation(24点游戏),也可能是一个paragraph(创意文本生成),设计thoughts可以有几个原则:
不能太大:这样LM可以生成有前景的、多样性的候选样本(例如一整本书就太大了)
不能太小:太小了LM不好评估其对最终解决问题是否有帮助(例如只生成一个token,LM无法评估其是否有用)
2.2 Thought generator【thought生成】
背景:不同的任务Thought生成的原则也不太一样,可以根据任务的特点制定thought生成的原则。
原则一:当thought空间比较大【例如创意写作,thought位一个段落】 => 可以用CoT prompt的方法来生成
例子一:【创意文本生成】thought生成方法:直接用COT方法提出多个Plans

原则二:当thought空间比较小【例如只有几个字(字谜游戏),或者只有一行(24点游戏)】 => 使用“propose prompt”依次提出想法,例如下面两个例子:
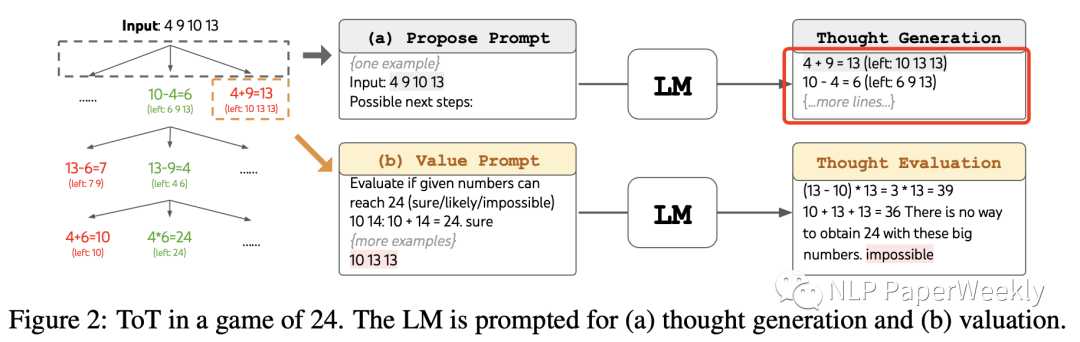
【24点游戏】是什么?:"Game of 24"是一种数学益智游戏,旨在通过组合和计算四个给定的数字(通常是1到9之间的整数)来得到结果为24的表达式。
【24点游戏】thought生成方法:根据上一个节点的left(例如:4 9 10 13),把它当作限制,生成模块依次提出多种可能的想法
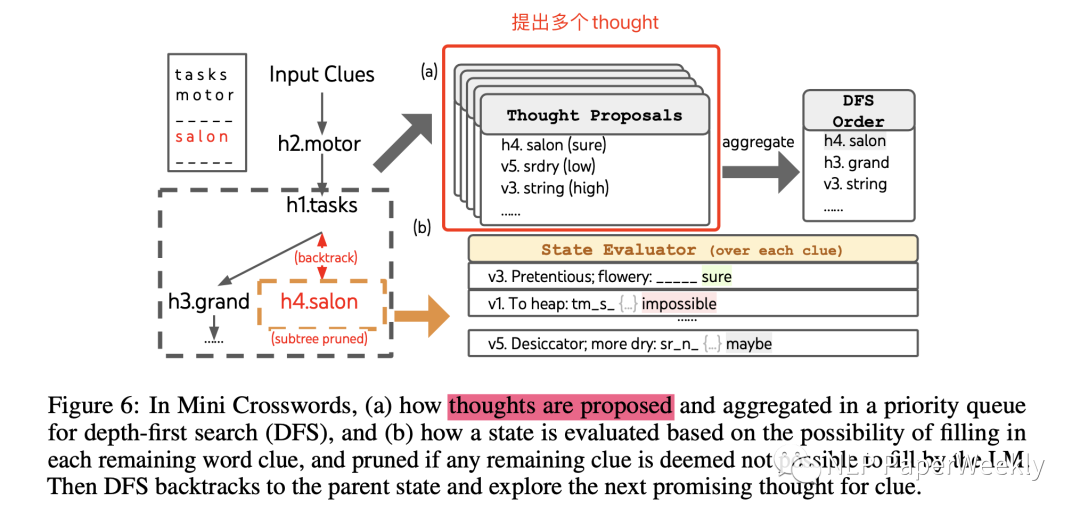
【Mini Crosswords 填字游戏】是什么?:Mini Crosswords是一种简化版的填字游戏,适合在有限的空间和时间内进行。与传统的填字游戏不同,Mini Crosswords使用较小的网格,通常为5x5或6x6,且只包含较少的单词。每个单词都有一个提示,玩家需要根据提示填写正确的单词。
【Mini Crosswords 填字游戏】thought生成方法:直接根据当前节点已经填好的单词(限制条件),利用prompt方法生成5次,产生下一个词可能的5种填写方法。
2.3 State evaluator【状态评估】
定义:给定不同的当前state状态,state evalutor用于评估那个方法最有接近解决当前问题。通常是利用heuristis方法来解决,像deepBlue是用编程的方法来解决,AlphaGo是用学习的方法来解决,本文直接是用LM去评估和思考当前state解决问题的前景。同样的,针对不同的任务也有不同的评估方法。这里主要提出两种策略:
原则一:【独立评估】,当每个state独立时并且好用数值型的方式来评估时,直接利用prompt生成数值型或者类别性的评估结果,这里可以利用一些前瞻性的模拟(例如:5+5+14可以凑成24点) + 常识commonsense(例如:1,2,3太小了,够不到24点)来直接给出 good 或者 bad的评价,并且不要求特别准确。
【24点游戏】评估方法:直接利用prompt LM去评估每个thoughts为sure、maybe、impossible几个选项
【Mini Crosswords 填字游戏】评估方法:直接利用prompt评估每个candidates的confidence(sure、impossible、maybe)
原则二:【对所有state投票】:当评估passage coherency(段落连贯性),不是特别好用数值型的方法来评估时,通过vote prompt来详细比较不同的state,选出一个最优前景的方案,例如可以将多个state拼接成一个多选题,然后利用LM来对其进行投票。
【创意文本生成】评估方法:直接利用LM投票从多个state中选择最好的一个,例如使用以下prompt:“analyze choices below,then conclude which is most promising for the instruction”
其他:对于每一种策略,都可以利用LM prompt多次集成多次的value分数或者vote投票提升其鲁棒性。
2.4 Search algorithm【搜索算法】
说明:对于树的结构,有很多中搜索算法,本文探索了两种简单的搜索算法BFS和DFS。
BFS(宽度优先算法):每一个步骤保留b个最有前景的方案,本文提到的Game of 24以及Creative Writing就是用的这个算法,其中tree depth限制为(T小于等于3),thoughts step可以先打分(evaluated)然后剪枝到一个小的集合b小于等于5。
DFS(深度优先算法):先探索最有前景的解决方案,直到超过树的最大深度T(t>T),或者当前state已经不可能解决问题了,此时可以直接剪枝,然后回到父节点,继续进行探索。
3 Conclusion
在需要non-trivial planing(非平凡的规划)或者search(搜索)的任务中,取得了非常好的表现,例如24点游戏(Game of 24,4个数凑成24)中,GPT-4+COT只有4%的解决率,本文TOT方法解决率可以达到74%。
TOT再利用LM解决通用问题时有几大优点:(1)通用性:IO,COT,COT-SC,self-refinement都可以看作TOT的一种特例。(2)模块化:基础LM,thought分解,thought生成、评估、搜索都可以独立的当做一个模块来实现。(3)适应能力强:不同的问题,LM,资源限制都能使用。(4)方便:不需要额外的训练,直接用预训练的LM就足够了。
4 Limitation
必要性:有些场景GPT4已经解决的比较好了,可能用不上。
需要更多资源:多次调用GPT-4 API等等带来的cost。
只是离线使用,没有利用TOT-stype的思想去对LM做fine-tuning,该方法可能更能增强LM解决问题地能力。
二、详细内容
1 三个实验的定义

【24点游戏】是什么?:"Game of 24"是一种数学益智游戏,旨在通过组合和计算四个给定的数字(通常是1到9之间的整数)来得到结果为24的表达式。
【Mini Crosswords 填字游戏】是什么?:Mini Crosswords是一种简化版的填字游戏,适合在有限的空间和时间内进行。与传统的填字游戏不同,Mini Crosswords使用较小的网格,通常为5x5或6x6,且只包含较少的单词。每个单词都有一个提示,玩家需要根据提示填写正确的单词。
【创意文本生成】是什么:这个比较好理解,就是生成创意文本。
其他:红色圈出来的部分为定义的Thoughts中间结果。
2 搜索算法策略

特点:利用BFS,可以像人类一样,一直探索比较好的b个(宽度)实现方法。利用DFS方法,可以方便的进行剪枝,回溯,像人一样,当前路走不通,我退回上一个不走重新选择。相对于之前的COT等从左到右的思想策略,理论上感觉确实会有着比较大的提升空间。
3 Game of 24实验结果分析
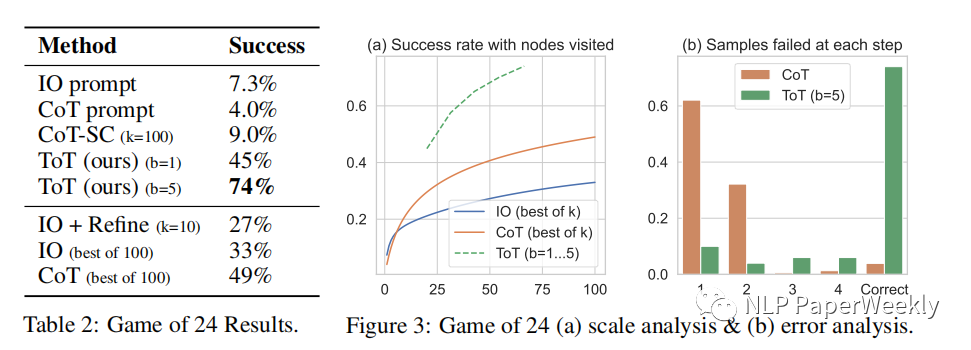
Table2:IO、CoT和CoT-SC提示方法在任务上表现较差,仅达到7.3%、4.0%和9.0%的成功率。相比之下,具有b = 1宽度的ToT的成功率为45%,而b = 5的成功率为74%。
Figure3(a):比较访问k个样本(感觉是生成k次结果)的情况下,IO,COT,TOT方法的成功率,COT(100)才49%,TOT在30左右就超过60了,在60左右应该就有74%的成功率。
Figure3(b):直接利用COT,有60%左右在第一部就失败了,这突出了直接从左到右解码的问题。
4 Creative Writing results和Mini Crosswords results结果分析
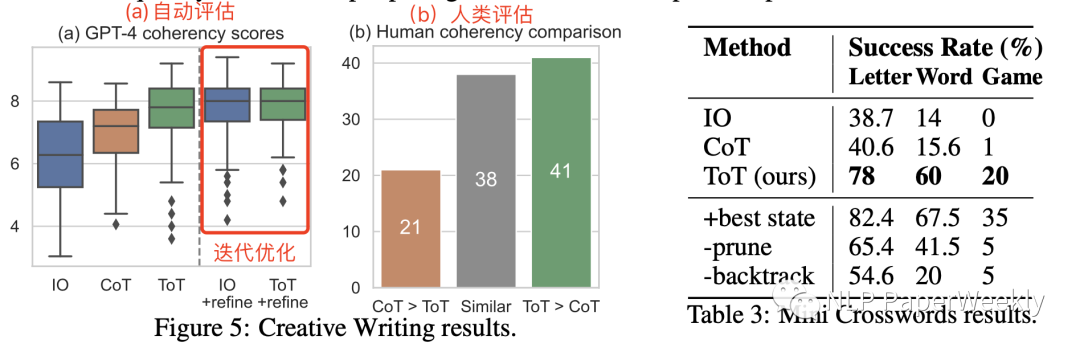
Creative Writing results结果
自动评估(连贯性):ToT (7.56) > CoT (6.93) > IO (6.19)
人工评估(GSB):ToT vs COT G:S:B = (41:38 :21)
iterative-refine(旧的thought -> refine -> 新的thought):迭代优化还能继续提升,ToT (7.56 -> 7.91) ,IO (6.19 -> 7.17) ,这个提升也挺大的,可以作为一个新的方法
Mini Crosswords results结果
Letter(字母级别准确率):ToT (78) > CoT (40.6) > IO (38.8)
Word(字级别准确率):ToT (60) > CoT (15.6) > IO (14)
Game(游戏级别解决率):ToT (20) > CoT (1) > IO (0)
消融实验:(1)+best state:利用更好的state评估器,可能得到更大的提升,Game级别解决率从20%->35%,说明本文提到的简单的启发式的评估算法还有比较大的空间。(2)剪枝:去掉剪枝,只能解决1个问题,另外3个都是通过启发式的剪枝找到的,说明这种方法对于解决问题是至关重要的。(3)回溯:去掉回溯算法后,效果表现比较差,说明有延续性的这种寻找答案的方法也是非常重要的。
缺点:感觉用的测试数据不算太多?只用了20个游戏来做测试?
5 Related Work
三、总结
1. 提出了一种完全由LLM + 启发式搜索算法结合的TOT算法,其可以从多条解决路径,快速的找到最佳解决方法,可以解决的一些复杂的,GPT-4都表现差的一些任务。其主要由thought生成、thought评估、搜索算法组成,可以生成解决方案、对方案进行自我评估、同时可以通过回溯算法来延续之前的解决思路,利用剪枝算法过滤不可靠解决方案,提升找到最优解决路径的速度。
2. TOT其各个部分都是高度模块化的,例如可以用不同的LM,不同的搜索算法来实现,通用性比较强,同时其对于每个任务thought的定义都不太一致,如何针对不同的任务设置更好的thought也比较重要,他这里提出了“不能太小”、“不能太大”的指导原则可以参考。
3. TOT直接利用LM的评估器效果还有待提高,Mini Crosswords results任务利用更好的state评估器,可能得到更大的提升,Game级别解决率从20%->35%,说明利用更好的评估器也是非常重要的,可以取得更好的结果。
4. OpenAI的Andrej Karpathy在state of gpt中也提到了TOT算法,其也可能是比Auto-GPT更好的一种,让llm进行深思熟虑来解决复杂问题的一种实现思路。
-
混合启发式算法在汽车调度中的应用2009-09-19 3277
-
改进的双向启发式搜索算法主要流程是怎样的?2021-05-17 1943
-
基于禁忌搜索的启发式求解背包问题算法2009-05-07 864
-
一种采用启发式分割点计算的包分类算法2009-11-13 563
-
一种求上近似约简的快速启发式算法2009-12-18 802
-
布谷鸟搜索算法源程序2016-08-05 617
-
一种改进的邻近粒子搜索算法2017-01-07 726
-
一种改进的自由搜索算法_任诚2017-03-14 1247
-
提出一种基于启发式搜索算法在解空间搜索候选智能体的工程方法2017-12-21 6675
-
单规格一刀切矩形排样的启发式搜索算法2017-12-28 1482
-
基于网页排名算法面向论文索引排名的启发式方法2017-12-30 776
-
基于并行搜索和快速插入的算法2018-01-07 916
-
启发式算法和遗传混合算法在流水车间的应用2021-06-30 842
-
基于启发式搜索算法的无人机航迹规划2021-07-02 970
-
基于群体的元启发式算法——象鼻虫伤害优化算法2022-10-19 1650
全部0条评论

快来发表一下你的评论吧 !
