

基于Prometheus的全方位监控平台设计
描述
一、背景:
Kubernetes集群规模大、动态变化快,而且容器化应用部署和服务治理机制的普及,传统的基础设施监控方式已经无法满足Kubernetes集群的监控需求。
需要使用专门针对Kubernetes集群设计的监控工具来监控集群的状态和服务质量。
Prometheus则是目前Kubernetes集群中最常用的监控工具之一,它可以通过Kubernetes API中的 metrics-server 获取 Kubernetes 集群的指标数据,从而实现对Kubernetes集群的应用层面监控,以及基于它们的水平自动伸缩对象 HorizontalPodAutoscaler。
二、Metrics-server
资源指标管道 Metrics API | Kubernetes
Metrics Server 是一个专门用来收集 Kubernetes 核心资源指标(metrics)的工具,它定时从所有节点的 kubelet 里采集信息,但是对集群的整体性能影响极小,每个节点只大约会占用 1m 的 CPU 和 2MB 的内存,所以性价比非常高。
Metrics Server 工作原理:
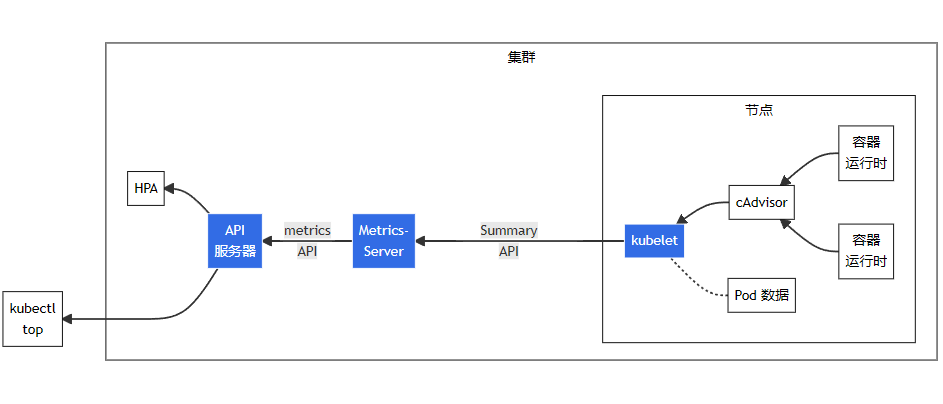
图中从右到左的架构组件包括以下内容:
cAdvisor: 用于收集、聚合和公开 Kubelet 中包含的容器指标的守护程序。
kubelet: 用于管理容器资源的节点代理。可以使用 /metrics/resource 和 /stats kubelet API 端点访问资源指标。
Summary API: kubelet 提供的 API,用于发现和检索可通过 /stats 端点获得的每个节点的汇总统计信息。
metrics-server: 集群插件组件,用于收集和聚合从每个 kubelet 中提取的资源指标。API 服务器提供 Metrics API 以供 HPA、VPA 和 kubectl top 命令使用。Metrics Server 是 Metrics API 的参考实现。
Metrics API: Kubernetes API 支持访问用于工作负载自动缩放的 CPU 和内存。要在你的集群中进行这项工作,你需要一个提供 Metrics API 的 API 扩展服务器。
2.1、Metrics-server部署配置
Metrics Server 的项目网址(https://github.com/kubernetes-sigs/metrics-server)
$ wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml && mv components.yaml metrics-server.yaml
修改 YAML 文件
apiVersion: apps/v1 kind: Deployment metadata: name: metrics-server namespace: kube-system spec: ... ... template: spec: containers: - args: - --kubelet-insecure-tls ... ...
Metrics Server 默认使用 TLS 协议,要验证证书才能与 kubelet 实现安全通信,而我们的内网环境里没有这个必要。
默认镜像源非国内,如有下载失败的小伙伴,更改镜像为如下阿里云提供的即可:
registry.aliyuncs.com/google_containers/metrics-server:v0.6.1
部署:
$ kubectl apply -f metrics-server.yaml
测试验证:
$ kubectl top node $ kubectl top pod -n kube-system
三、HorizontalPodAutoscaler
HorizontalPodAutoscaler (HPA)是Kubernetes中的一个控制器,用于动态地调整Pod副本的数量。HPA可以根据Metrics-server提供的指标(如CPU使用率、内存使用率等)或内部指标(如每秒的请求数)来自动调整Pod的副本数量,以确保应用程序具有足够的资源,并且不会浪费资源。
HPA是Kubernetes扩展程序中非常常用的部分,特别是在负载高峰期自动扩展应用程序时。
3.1、使用HorizontalPodAutoscaler
创建一个 Nginx 应用,定义 Deployment 和 Service,作为自动伸缩的目标对象:
apiVersion: apps/v1 kind: Deployment metadata: name: ngx-hpa-dep spec: replicas: 1 selector: matchLabels: app: ngx-hpa-dep template: metadata: labels: app: ngx-hpa-dep spec: containers: - image: nginx:alpine name: nginx ports: - containerPort: 80 resources: requests: cpu: 50m memory: 10Mi limits: cpu: 100m memory: 20Mi --- apiVersion: v1 kind: Service metadata: name: ngx-hpa-svc spec: ports: - port: 80 protocol: TCP targetPort: 80 selector: app: ngx-hpa-dep
注意在它的 spec 里一定要用 resources 字段写清楚资源配额,否则 HorizontalPodAutoscaler 会无法获取 Pod 的指标,也就无法实现自动化扩缩容。
接下来我们要用命令 kubectl autoscale 创建一个 HorizontalPodAutoscaler 的样板 YAML 文件,它有三个参数:
min,Pod 数量的最小值,也就是缩容的下限。
max,Pod 数量的最大值,也就是扩容的上限。
cpu-percent,CPU 使用率指标,当大于这个值时扩容,小于这个值时缩容。
现在我们就来为刚才的 Nginx 应用创建 HorizontalPodAutoscaler,指定 Pod 数量最少 2 个,最多 8 个,CPU 使用率指标设置的小一点,5%,方便我们观察扩容现象:
$ kubectl autoscale deploy ngx-hpa-dep --min=2 --max=8 --cpu-percent=5 --dry-run=client -o yaml > nginx-demo-hpa.yaml
YAML 描述文件:
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: ngx-hpa spec: maxReplicas: 8 minReplicas: 2 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: ngx-hpa-dep targetCPUUtilizationPercentage: 5
通过kubectl apply创建这个 HorizontalPodAutoscaler 后,它会发现 Deployment 里的实例只有 1 个,不符合 min 定义的下限的要求,就先扩容到 2 个:
# kubectl get deploy NAME READY UP-TO-DATE AVAILABLE AGE ngx-hpa-dep 1/2 2 1 95s
3.2、测试验证
下面我们来给 Nginx 加上压力流量,运行一个测试 Pod,使用的镜像是httpd:alpine,它里面有 HTTP 性能测试工具 ab(Apache Bench):
$ kubectl run test -it --image=httpd:alpine -- sh
然后我们向 Nginx 发送一百万个请求,持续 1 分钟,再用 kubectl get hpa 来观察 HorizontalPodAutoscaler 的运行状况:
$ ab -c 10 -t 60 -n 1000000 'http://ngx-hpa-svc/'
Metrics Server 大约每 15 秒采集一次数据,所以 HorizontalPodAutoscaler 的自动化扩容和缩容也是按照这个时间点来逐步处理的。
当它发现目标的 CPU 使用率超过了预定的 5% 后,就会以 2 的倍数开始扩容,一直到数量上限,然后持续监控一段时间;
如果 CPU 使用率回落,就会再缩容到最小值 (默认会等待五分钟如果负载没有上去,就会缩小到最低水平,防止抖动)。
$ kubectl get po NAME READY STATUS RESTARTS AGE ngx-hpa-dep-7984687bb9-86cg5 0/1 ContainerCreating 0 14s ngx-hpa-dep-7984687bb9-9wpr8 1/1 Running 0 29s ngx-hpa-dep-7984687bb9-gjzwl 0/1 ContainerCreating 0 14s ngx-hpa-dep-7984687bb9-k4dpj 0/1 ContainerCreating 0 14s ngx-hpa-dep-7984687bb9-qkhpq 1/1 Running 0 4m45s ngx-hpa-dep-7984687bb9-sgxtc 0/1 ContainerCreating 0 14s ngx-hpa-dep-7984687bb9-xq6xk 1/1 Running 0 6m11s ngx-hpa-dep-7984687bb9-xs9q8 0/1 ContainerCreating 0 29s
四、总结
1、Metrics Server是Kubernetes中的一个组件,它可以将集群中的散布的资源使用情况数据收集并聚合起来。收集的数据包括节点的CPU和内存使用情况等。
2、通过API提供给Kubernetes中的其它组件(如HPA)使用。Metrics Server可以帮助集群管理员和应用程序开发者更好地了解集群中资源的使用情况,并根据这些数据做出合理的决策,例如调整Pod副本数、扩展集群等。
3、Metrics Server对于Kubernetes中的资源管理和应用程序扩展非常重要。
- 相关推荐
- 热点推荐
- API
- 容器
- 监控平台
- Prometheus
-
Prometheus的架构原理从“监控”谈起2020-10-10 5502
-
Prometheus服务监控系统2022-04-26 650
-
[分享]全方位剖析BGA布线规则与技巧2008-07-17 7601
-
行车记录仪全方位录像2012-04-17 3059
-
全方位距离雷达动态检测系统的设计怎么设计2014-03-06 2561
-
Glance360全方位智能展示2017-11-15 3293
-
什么是全方位汽车安全解决方案?2019-11-01 2427
-
关于全方位立体电容传感器的设计2020-04-29 1696
-
prometheus做监控服务的整个流程介绍2020-12-23 2659
-
介绍一种全方位测量和检验的软件2021-07-12 1275
-
安全监控电路提供全方位监测,确保系统的安全性2009-03-31 917
-
prometheus下载安装教程2023-01-13 10118
-
基于kube-prometheus的大数据平台监控系统设计2023-05-30 1402
-
基于Prometheus开源的完整监控解决方案2023-10-18 1436
-
储能EMS控制器(3) — 储能系统如何做到快速接入全方位监控?2025-11-19 708
全部0条评论

快来发表一下你的评论吧 !
