

虚拟存储器简述
存储技术
描述
一 虚拟存储器概念
虚拟存储器(Virtual Memory)的基本思想是对于程序来说,它的程序(code)、数据(data)、堆栈(stack)的总大小可以超过实际物理内存(Physical Memory)的大小,操作系统把当前使用的部分内容放到物理内存中,而把其它未使用的内容放到更下一级存储器,如硬盘(Disk)或闪存(Flash)上。这样可以应付随着应用程序规模的扩大,导致物理内存已经无法容纳下这样的程序。
举例来说,一个大小为32MB的程序运行在物理内存只有16MB的机器上,操作系统通过选择,决定各个时刻将程序中一部分放在物理内存中,而将其它的内容放到硬盘中,并在需要的时候在物理内存和硬盘之间交换程序片段,这样就可以把大小为32MB的程序放到物理内存为16MB的机器上运行。
运用程序是运行在虚拟存储器空间的,它的大小由处理器的位数决定,例如对于一个32位处理器来说,其地址范围就是0~0xFFFF_FFFF,也就是4GB,这个范围就是程序能够产生的地址范围,其中的某一个地址就称为虚拟地址。和虚拟存储器对应的就是物理存储器,它是在现实世界中能够直接使用的存储器,其中的某一个地址就是物理地址。物理存储器的大小不能够超过处理器最大可以寻址的空间,例如32为x86 PC中,不可能使用比4GB更大的物理内存了。
在没有使用虚拟地址的系统中,处理器输出的地址会直接送到物理存储器中,这个过程如图1所示。
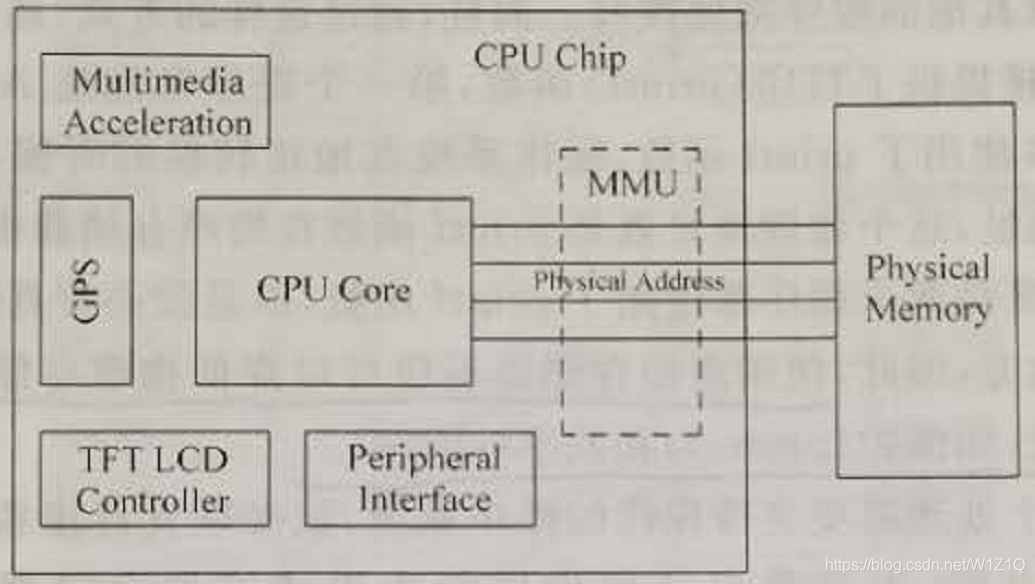
图1 没有使用虚拟存储器的系统
而如果使用了虚拟地址,则处理器输出的地址就是虚拟地址了,这个地址不会被直接送到物理存储器中,而是需要先进行地址转换,因为虚拟地址是没有办法直接寻址物理存储器的,负责地址转换的部件一般称为内存管理单元(Memory Manage Unit,MMU),如图2所示。
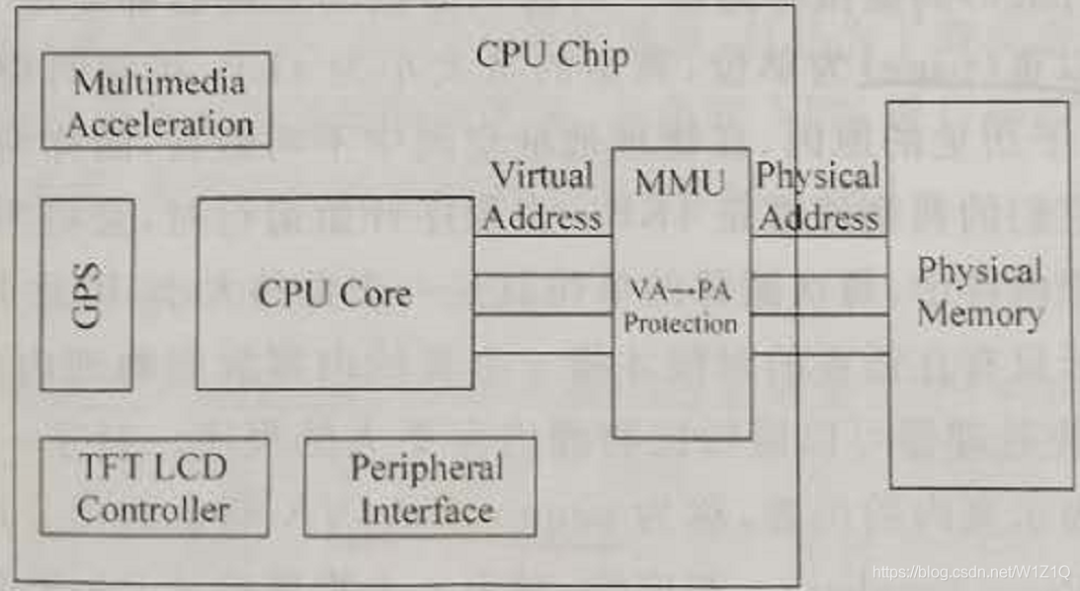
图2 使用虚拟存储器的系统
使用虚拟存储器,每个应用程序总认为它占有处理器的所有地址空间,因此程序可以任意使用处理器的地址资源,不需要考虑地址的限制,由操作系统负责调度,将物理存储器动态地分配给各个应用程序,将每个程序的虚拟地址转换为相应的物理地址,使程序能够正常运行。通过这样的方式可以保护两个程序即使使用了同一个虚拟地址,它们也会对应到不同的物理地址,因此可以保护每个程序的内容不会被其它程序随意改写。
还可以实现了程序间的共享,例如操作系统提供了打印(printf)函数,第一个程序在地址A使用了printf函数,第二个程序在地址B使用了printf函数,操作系统在地址转换的时候,会将地址A和地址B转换为同样的物理地址,这个物理地址就是printf函数在物理存储器中的实际地址,这样就实现了程序共享。
因此使用虚拟存储器不仅可以降低物理存储器的容量需求,也可以带来另外的好处,如保护(Protect)和共享(Share)。
可以说,如果一个处理器要支持现代的操作系统,就必须支持虚拟存储器,它是操作系统一个非常重要的内容,本文重点从硬件层面来讲述虚拟存储器,涉及到页表(Page Table)、程序保序和TLB等内容。
二 地址转换
目前最通用的虚拟存储器实现方式是基于分页(page)的虚拟存储器。虚拟地址空间以页(page)为单位划分,典型的页大小为4KB,相应的物理地址空间也进行同样大小的划分,由于历史原因,在物理地址空间中不叫做页,而称为frame,它和页的大小必须相等。
当程序开始运行时,会将当前需要的部分内容从硬盘中搬移到物理内存中,每次搬移的单位就是一个页的大小。由于只有在需要的时候才将一个页的内容放到物理内存中,这种方式就称为demand page,它是处理器可以运行比物理内存更大的程序。
对于一个虚拟地址(Virtual Address)来说,VA[11:0]用来表示页内的位置,称为page offset,VA剩余的部分用来表示哪个页,也称为VPN(Virtual Page Number)。
相应的,对于一个物理地址PA(Physical Address)来说,PA[11:0]用来表示frame内的位置,称为frame offset,而PA剩余的部分用来表示哪个frame,也称为PFN(Physical Frame Number)。由于页和frame的大小是一样的,所以从VA到PA的转化实际上也就是从VPN到PFN的转化,offset的部分是不需要变化的。
表3所示的例子,假设处理器是16位的,则它的虚拟地址范围是0~0XFFFF,共64KB,页的大小是4KB,因此64KB的虚拟地址包括了16个页,即16个VPN;而这个系统中物理内存只有32KB,它包括了8个PFN。现有一个程序,它的大小大于32KB,因此该程序在运行时不能一次性调入内存中运行,这台机器必须有一个可以存放这个程序的下一级存储器(例如硬盘或内存),以保证程序片段在需要的时候可以被调用。
在图3中,一部分虚拟地址已经被映射到了物理空间,例如VPN0(地址范围0-4K)被映射为PFN2(地址范围8-12K,图上画错了);VPN1(地址范围4-8K)被映射为PFN0(地址范围0-4K)等。
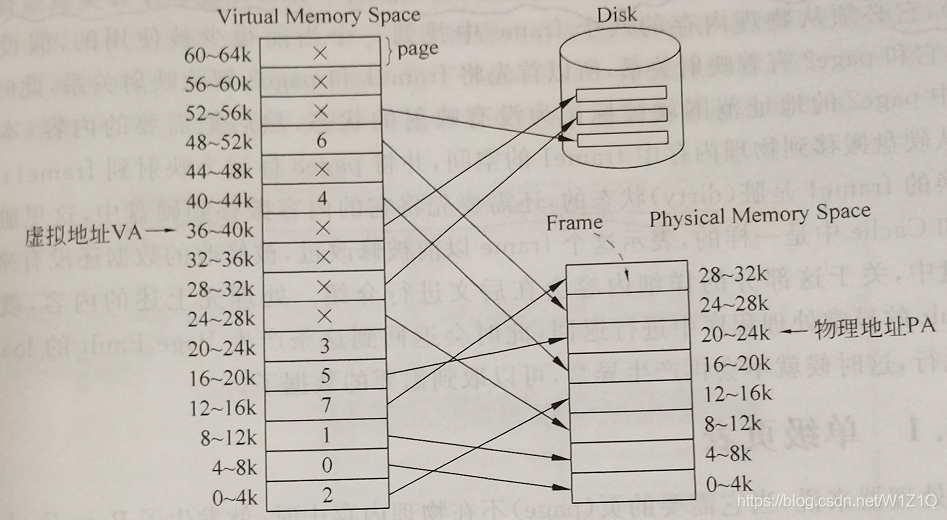
图3 地址转换的一个例子
对于从虚拟地址到物理地址的转换来说,指示对VPN进行操作,页内的偏移是不需要进行转化的,也就是说,页是进行地址转换的最小单位。为了便于理解,以load指令为例行描述:
Load R2, 5[R1]; //假设R1的值为0
这条load指令在执行的时候,得到的取数据的虚拟地址是R1+5=5,也就是地址5会被送到MMU中,从图3中可以看到,地址5落在了page0(它的范围是0-4095)的范围内,而page0被映射到物理地址空间中的frame2(它的地址范围是8192-12287),因此MMU将虚拟地址5转换为物理地址8192+5=8197,并把这个地址送到物理内存中取数据,物理内存并不知道MMU做了什么映射,它只是看到了一个对地址8197进行读操作的任务。
对于图3中,如果虚拟地址是32780,则落在了page8范围内,而page8还并没有一个有效的映射,即此时page8的内容没有存在于物理内存中,而是存在于硬盘中。
MMU发现这个页没有被映射之后,就产生一个Page Fault的异常送给处理器,这时候处理器就需要转到Page Fault对应的异常处理程序中处理整个事情(这个异常处理程序其实就是操作系统的代码),它必须偶从物理内存的八个frame中找到一个当前很少被使用的,假设选中了frame1,它和page2有着映射关系,所以首先将frame1和page2解除映射关系,此时虚拟地址空间中page2的地址范围就被标记为没有映射的状态,然后把需要的内容(本例是page8)从硬盘搬移到物理内存中frame1的空间,并将page8标记为映射到frame1;
如果这个被替换的fram1是脏(dirty)状态的,还需要先将它的内容搬移到硬盘中,这里脏的概念和Cache中是一样的,表示这个frame以前被修改过,被修改的数据还没有来得及更新到硬盘中,处理完上述的内容,就可以从Page Fault的异常处理程序中返回,此时会返回到这条产生Page Fault的load指令,并重新执行,这时候就不会再有产生异常,可以取到需要的数据了。
2.1 单级页表
在使用虚拟存储器的系统中,都是使用一张表格来存储从虚拟地址到物理地址(实际上是VPN到PFN)的对应关系,这个表格称为页表(Page Table,PT)。
这个表格一般是放在物理内存中,使用虚拟地址来寻址,表格中被寻址到的内容就是这个虚拟地址对应的物理地址。每个程序都有自己的页表,用来将这个程序中的虚拟地址映射到物理内存中的某个地址,为了指示一个程序的页表在物理内存中的位置,在处理器中一般都会包括一个寄存器,用来存放当前运行程序的页表在物理内存中的起始地址,这个寄存器称为页表寄存器(Page Table Register,PTR),每次操作系统将一个程序调入物理内存中执行的时候,就会将寄存器PTR设置好,当然,上面的这种机制可以工作的前提是页表位于物理内存中一片连续的地址空间内。
图4表示了如何使用PTR从物理内存中定位到一个页表,并使用虚拟地址来寻址页表,从而找到对应的物理地址的过程。其实,使用PTR和虚拟地址共同来寻址页表,这就相当于使用它们两个共同组成一个地址,使用这个地址来寻址物理内存。
图4中仍然假设每个页的大小是4KB,使用PTR和虚拟地址共同来寻址页表,找到对应的表项(entry),当这个表项对应的有效位(valid)为1时,就表示这个虚拟地址所在的4KB空间已经被操作系统映射到了物理内存中,可以直接从物理内存中找到这个虚拟地址对应的数据,其实,这时候访问当前页内任意的地址,就是访问物理内存中被映射的那个4KB的空间了。
相反,如果页表中这个被寻址的表项对应的有效位是0,则表示这个虚拟地址对应的4KB空间还没有被操作系统映射到物理内存中,则此时就产生了Page Fault类型的异常,需要操作系统从更下一级的存储器(例如硬盘或闪存)将这个页对应的4KB内容搬移到物理内存中。

图4 通过页表进行地址转换
图4使用了32位的虚拟地址,页表在物理内存中的起始地址是用PTR来指示的。虚拟地址的寻址空是232字节,也就是4GB;物理地址的寻址空间时232字节,也就是1GB,这就是对应着实际物理地址的寻址空间。在页表中的一个表项(entry)能够映射4KB的大小,为了能够映射整个4GB的空间,需要表项的个数应该是4GB/4KB=1M,也就是220,因此需要20位来寻址,也就是虚拟地址中除了Page Offset之外的其它部分,也就是说32位的虚拟地址中将人为分成两部分,低12bit用来寻址一个页内的内容,高20bit用来寻址哪个页,因此真正寻址页表只需要VPN就够了。从页表中找到的内容也不是整个物理地址,而只是PFN。
从图4来看,页表中的每个表项似乎只需要18bit的PFN和1bit的有效位(valid),也就是总共19bit就够了。实际上因为页表是放到物理内存中,而物理内存中的数据位宽都是32bit的,所以导致页表中每个表项的大小也就是32bit,剩余的位用于表示一些其他的信息,如每个页的属性信息(是否可读或可写)等,这样页表的大小就是4B×1M=4MB,也就是说,按照目前的描述,一个程序在运行的时候,需要在物理内存中划分出4MB的连续空间来存储它的页表,然后才可以正常地运行这个程序。
需要注意的是,页表的结构是不同于cache的,在页表中包括了所有VPN的映射关系,所以可以直接使用VPN对页表进行寻址,而不需要使用Tag。
在处理器中,一个程序对应的页表,连同PC和通用寄存器一起,组成了这个程序的状态,如果在当前程序执行的时候,想要另外一个程序使用这个处理器,就需要将当前程序的状态进行保存,这样就可以在一段时间之后将这个程序进行恢复,从而使这个程序可以继续执行,在操作系统中,通常将这样的程序称为进程(process),当一个进程被处理器执行的时候,称这个进程是活跃的(active),否则就称之为不活跃(inactive)。操作系统通过将一个进程的状态加载到处理器中,就可以使这个进程进入活跃的状态。
可以说,进程是一个动态的概念,当一个程序只是放在硬盘中,并没有被处理器执行的时候,它只是一个由一条条指令组成的静态文件,只有当这个程序被处理器执行时,例如用户打开了一个程序,此时才有了进程,需要操作系统为其分配物理内存中的空间,创建页表和堆栈等,这时候一个静态的程序就变为了动态的进程,这个进程可能是一个,也可能是多个,这取决于程序本身,当然进程是有生命期的,一旦用户关闭了这个程序,进程也就不存在了,它所占据的物理内存也会被释放掉。
一个进程的页表指定了它能够在物理内存中访问的地址空间,这个页表当然也是位于内存中的,在一个进程进行状态保存的时候,其实并不需要保存整个的页表,只需要将这个页表对应的PTR进行保存即可。因为每个进程都拥有全部的虚拟存储器空间,因此不同的进程肯定会存在相同的虚拟地址,操作系统需要负责将这些不同的进程分配到物理内存中不同的地方,并将这些映射(mapping)信息更新到页表中(使用store指令就可以完成这个任务),这样不同的进程使用的物理内存就不会产生冲突了。
如果按以上方法,每个进程都要占用4MB的物理空间来存储页表,那运行上百个进程时,那物理内存将完全不够用。但事实上,一个程序很难用完整4GB的虚拟存储器空间,大部分程序只是用了很多一部分,这就造成了页表中大部分内容其实都是空的,并没有被实际地使用,这样整个页表的利用效率其实是很低的。
可以采用很多方法来减少一个进程的页表对于存储空间的需求,最常用的方法是多级页表(Hierarchical Page Table),这种方法可以减少页表对于物理存储空间的占用,而且非常容易使用硬件实现,与之对应的,本节所讲述的页表就称为单级页表(Single Page Table),也被称为线性页表(Linear Page Table)。
2.2 多级页表
在多级页表的设计中,将2.1节介绍的一个4MB的线性页表划分为若干个更小的页表,称它们为子页表,处理器在执行进程的时候,不需要一下子把整个线性页表都放入物理内存中,而是根据需要逐步地放入这些子页表。而且,这些子页表不再需要占用连续的物理内存空间了,也就是说,两个相邻的子页表可以放在物理内存中不连续的位置,这样也提高了物理内存的利用效率。但是,由于所有的子页表是不连续地放在物理内存中,所以仍旧需要一个表格,来记录每个子页表在物理内存中存储的位置,称这个表格为第一级页表(Level1 Page Table),而那些子页表则为第二级页表(Level2 Page Table),如图5所示。
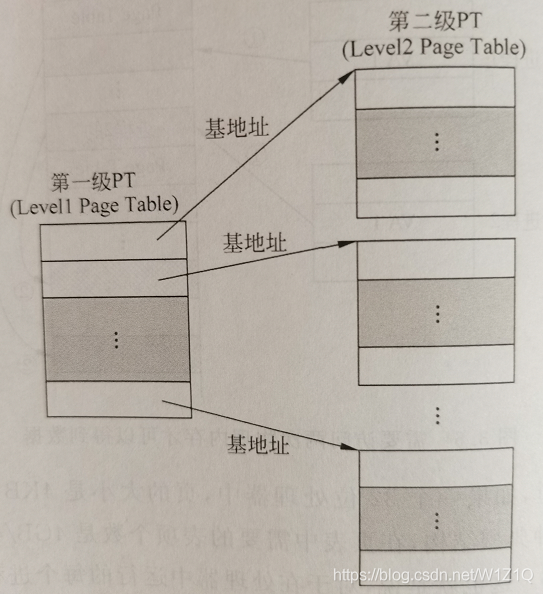
图5 两级页表
这样,要得到一个虚拟地址对应的数据,首先需要访问第一级页表,得到这个虚拟地址所属的第二级页表的基地址,然后再去第二级页表中才可以得到这个虚拟地址对应的物理地址,这时候就可以在物理内存中取出相应的数据。
举例来说,对于一个32位虚拟地址、页大小为4KB的系统来说,如果采用线性页表,则页表的表项个数是220,将其分为1024(210)等份,每个等份就是一个第二级页表,共有1024个第二级页表,对应着第一级页表的1024个表项。也就是说,第一级页表需要10位地址进行寻址。每个二级页表中,表项的个数是220/210=210个,也需要10位地址才能寻址第二级页表,如图6所示过程的示意图。
在图6中,一个页表中的表项简称为PTE(Page Table Entry),当操作系统创建一个进程时,就在物理内存中为这个进程找到一块连续的4KB空间(4Bx210=4KB),存放这个进程的第一级页表,并且将第一级页表在物理内存中的起始地址放到PTR寄存器中。通常这个寄存器都是处理器中的一个特殊寄存器,例如ARM中的TTB寄存器,x86中的CR3寄存器等。随着这个进程的执行,操作系统会逐步在物理内存中创建第二级页表,每次创建一个第二级页表,操作系统就要将它的起始地址放到第一级页表对应的表项中,如表1所示为一个进程送出的虚拟地址和第一级页表、第二级页表的对应关系。
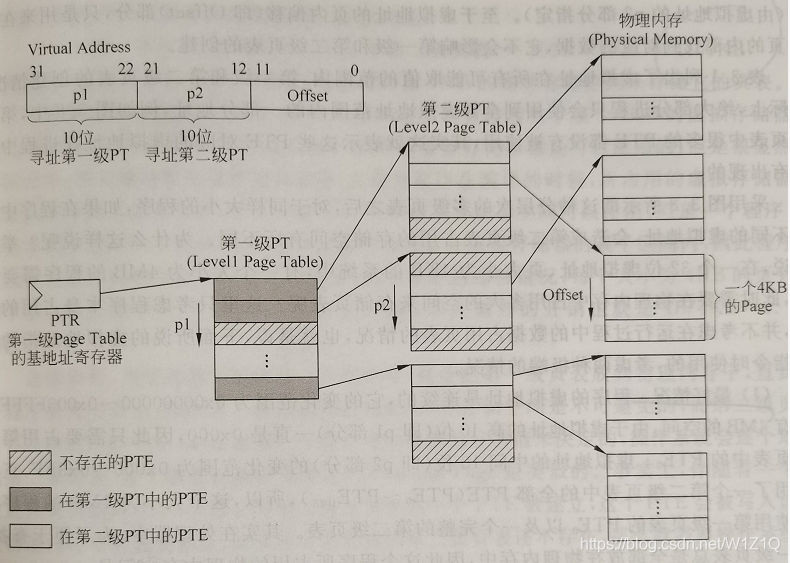
图6 使用两级页表进行地址转换的一个例子
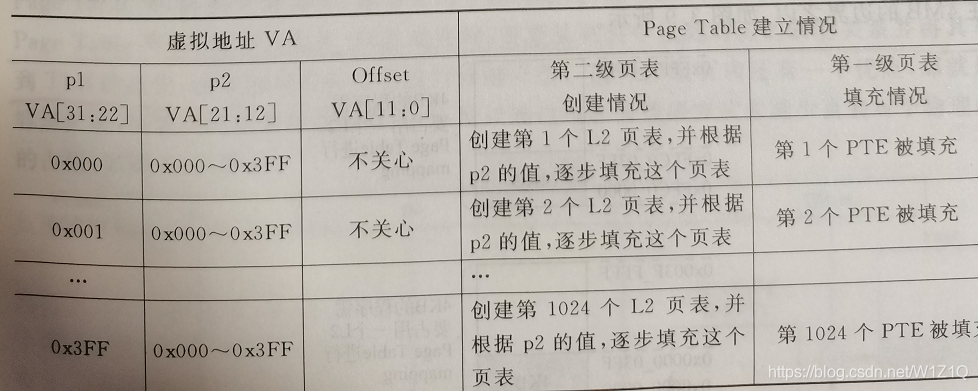
表1 虚拟地址和第一级页表、第二级页表的关系
在图6中,由于虚拟地址(VA)的p1部分和p2部分的宽度都是10位,因此它们的变化范围都是0x000-0x3FF,每次当虚拟地址的p!部分变化时,操作系统就需要在物理内存中创建一个新的第二级页表,并将这个页表的其实渎职写到第一级页表对应的PTE中(由虚拟地址的p1部分指定)。
当虚拟地址的p1部分不发生变化,只是p2部分的变化范围在0x000-0x3FF之内时,此时不需要创建新的第二级页表。每当虚拟地址中的p2部分发生变化,就表示要使用一个新的页,操作系统将这个新的页从下级存储器中(如硬盘)取出来并放到物理内存中,然后将这个页在物理内存中的起始地址填充到第二级页表对应的PTE中(由虚拟地址的p2部分指定)。至于虚拟地址的页内偏移(即Offset)部分,只是用来在一个页的内部找到对应的数据,它不会影响第一级和第二级页表的创建。
总体来看,当处理器开始执行一个程序时,就会把第一级页表放到物理内存中,直到整个程序被关闭为止,因此第一级页表所占用的4KB存储空间是不可避免的,而第二级页表是否在物理内存当中,则是根据一个程序当中虚拟地址的值来决定,操作系统会逐个地创建第二级页表。事实上,伴随着一个页表被放入到物理内存中,必然会有第二级页表中的一个PTE被建立,这个PTE会被写入该页在物理内存中的起始地址,如果这个页对应的第二级页表还不存在,那么就需要操作系统建立一个新的第二级页表。
多级页表有个优点就是容易扩展,当处理器的位数增加时,可以通过增加级数的方式来减少页表对于物理内存的占用。如图7所示。
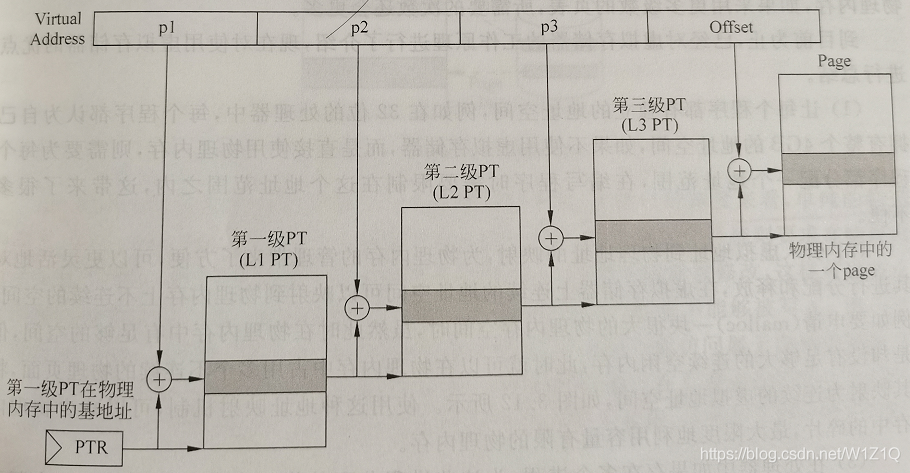
图7 使用多级页表进行地址转换
在处理器中如果存在多个进程,为这些进程分配的物理内存之和可能大于实际可用的物理内存,虚拟存储器的管理使得这些情况下各个进程仍能够正常运行,此时为各个进程分配的只是虚拟存储器的页,这些页有可能存在于物理内存中,也可能临时存在于更下一级的硬盘中,在硬盘中这部分空间称为swap空间。
当物理内存不够用时,将物理内存中的一些不常用的页保存在硬盘上的swap空间,而需要用到这些页时,再将其从硬盘的swap空间加载到物理内存,因此,处理器中等效可以使用的物理内存的总量是物理内存的大小 + 硬盘中swap空间的大小。
将一个页从物理内存中写到硬盘的swap空间的过程称为Page Out,将一个页从硬盘的swap空间放回物理内存的过程称为Page In,如图8所示为这两个过程的示意图。
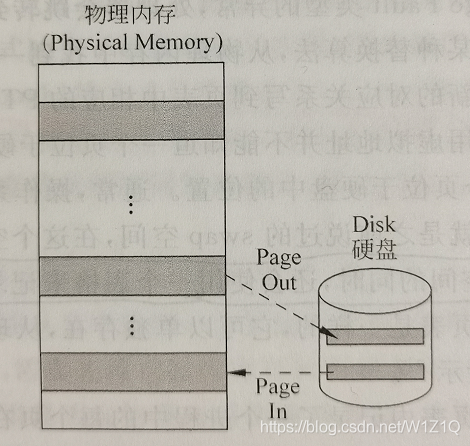
图8 Page In和Page Out
利用虚拟存储器,可以管理每一个页的访问权限,从硬件的角度来看,单纯的物理内存本身不具有各种权限的属性,它的任何地址都可以被读写,而操作系统则要求在物理内存中实现不同的访问权限,例如一个进程的代码段(text)一般不能够被修改,这样可以防止程序错误地修改自己,因此它的属性就要是可读可执行(r/x),但是不能够被写入;而一个进程的数据段(data)要求是可读可写的(r/w);同时用户进程不能访问属于内核的地址空间。这些权限的管理就是通过页表(Page Table)来实现的,通过在页表中设置每个页的属性,操作系统和内存管理单元(MMU)可以控制每个页的访问权限,这样就实现了程序的权限管理。
2.3 Page Fault
如果一个进程中的虚拟地址在访问页表时,发现对应的PTE中,有效位(valid)为0,这就表示这个虚拟地址所属的页还没有被放到物理内存中,因此在页表中就没有存储这个页的映射关系,这时候就说发生了Page Fault,需要从下级存储器(例如硬盘)将这个页取出来,放到物理内存中,并将这个页在物理内存中的起始地址写到页表中。Page Fault是异常(exception)的一种,通常它的处理过程不是由硬件完成的,而是由软件完成的,确切的说,是由操作系统完成的,因为操作系统也是软件。
在有Page Fault时,处理器会跳转到这个异常处理程序的入口地址,异常处理程序会根据某种替换算法,从物理内存中找到一个空闲的地方,将需要的页从硬盘中搬移进来,并将这个新的对应关系写到页表中相应的PTE内。
需要注意的是,直接使用虚拟地址并不能知道一个页位于硬盘的哪个位置,也需要一个机制来记录一个进程的每个页位于硬盘中的位置。
通常,操作系统会在硬盘中为一个进程的所有页开辟一块空间,这就是之前说过的swap空间,在这个空间中存储一个进程所有的页,操作系统在开辟swap空间的同时,还会使用一个表格来记录每个页在硬盘中存储的位置,这个表格的结构其实和页表是一样的,它可以单独存在,从理论上来讲也可以和页表合并在一起,如图9所示。
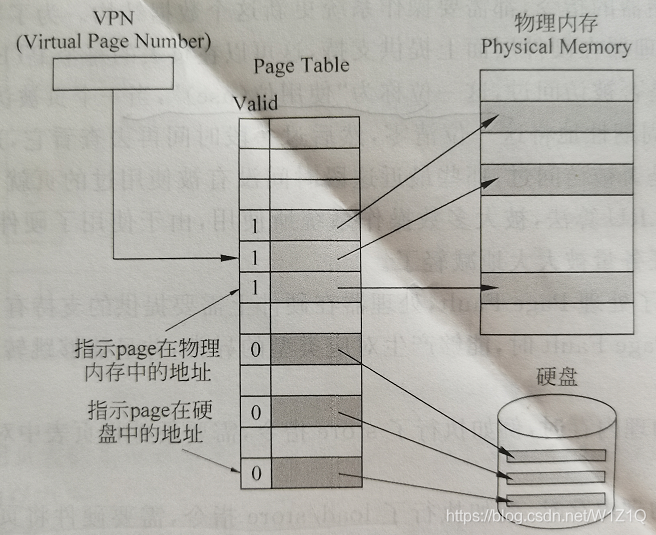
图9 同一个页表中记录了所有的内容
图9所示在一个页表内记录了一个进程中的每个页在物理内存或在硬盘中的位置,当页表中某个PTE的有效位(valid)为1时,就表示它对应的页在物理内存中,访问这个页不会发生Page Fault;相反,如果有效位是0,则表示它对应的页位于硬盘中,访问这个页就会发生Page Fault,此时操作系统需要从硬盘中将这个页搬移到物理内存中,并将这个页在物理内存的起始地址更新到页表中对应的PTE内。
虽然图9中,映射到物理内存的页表和映射到硬盘的页表可以放到一起,但在实际当中,物理上它们是分开放置的,因为不管一个页是不是在物理内存中,操作系统都必须记录一个进程的所有页在硬盘中的位置,因此需要单独地使用一个表格来记录它。
物理内存相当于是硬盘的Cache,因为对一个程序来说,它的所有内容其实都存在于硬盘中,只有最近被使用的一部分内容存在物理内存中,这样符合Cache的特征。因为一个程序的某些内容既存在于硬盘中,也存在于物理内存中,当物理内存中某个地址的内容被改变时(例如执行一条store指令,改变了程序中的某个变量),对于这个地址来说,在硬盘中的存储的内容就过时了,这种情况再Cache中也出现过,有两种处理方法。
写通(Write Through):将这个改变的内容马上写回硬盘中,考虑到硬盘的访问时间非常慢,这样的做法是不现实的;
写回(Write Back):只有等到这个地址的内容在物理内存中要被替换时,才将这个内容写回到硬盘中,这种方式减少了硬盘的访问次数,因此被广泛使用。
其实,写通(Write Through)的方式只可能在L1 Cache和L2 Cache之间使用,因此L2 Cache的访问时间在一个可以接受的范围之内,而且这样可以降低Cache一致性的管理难度,但是更下层的存储器需要的访问时间越来越长,因此只有写回(Write Back)方式才是可以接受的方法。
既然在虚拟存储器的系统中采用了写回的方式,当发生Page Fault并且物理内存已经没有空间时,操作系统需要从其中找到一个页进行替换,如果这个页的某些内容被修改过,那么在覆盖这个页之前,需要先将它的内容写回到硬盘中,然后才能进行覆盖。
为了支持这个功能,需要记录每个页是否在物理内存中被修改过,通常是在页表的每个PTE中增加一个脏(dirty)的状态位,当一个页的某个地址被写入时,这个脏的状态位会被置为1。
当操作系统需要将一个页进行替换之前,会首先去页表中检查它对应的PTE脏状态位,如果为1,则需要先将这个页的内容写回到硬盘中;如果为0,则表示这个页从来没有被修改过,那么就可以直接将其覆盖了,因为在硬盘中还保存着这个页的内容。
从一个时间点来看物理内存,会存在很多的页处于脏的状态,这些页都被写入了新的内容,当然,一旦这些脏的页被写回到硬盘中,它们在物理内存中也就不再是脏的状态了。
为了帮助操作系统在发生Page Fault的时候,从物理内存中找到一个页进行替换(当物理内存没有空闲的空间时),需要处理器在硬件层面上提供支持,这可以在页表的每一个PTE中增加一位,用来记录每个页最近是否被访问过,这一位称为“使用位(use)”,当一个页被访问时,“使用位”被置为1,操作系统周期性地将这一位清零,然后过一段时间再去查看它,这样就能够知道每一个页在这段时间是否被访问过,那么最近这段时间没有被使用过的页就可以被替换了。
这种方式是近似的LRU算法,被大多数操作系统所使用,由于使用了硬件来实现“使用位”,所以操作系统的任务量被大大地减轻了。
总结来说,为了处理Page Fault,处理器在硬件上需要提供的支持有如下几种:
在发现Page Fault时,能够产生对应类型的异常,并且能够跳转到它的异常处理程序的入口地址;
当要写物理内存时,例如执行了store指令,需要硬件将页表中对应PTE的脏状态位置为1;
当访问物理内存时,例如执行了store指令,需要硬件将页表中对应PTE的“使用位”置为1,表示这个页最近被访问过。
需要注意的是,在写回(Write Back)类型的Cache中,load/store指令在执行的时候,只会对D-Cache起作用,对物理内存中页表的更新可能会有延迟,当操作系统需要查询页表中的这些状态位时,首先需要将D-Cache中的内容更新到物理内存中,这样才能够使用到页表中正确的状态位。
因此,本节现在为止,页表中每个PTE的内容如图10所示。
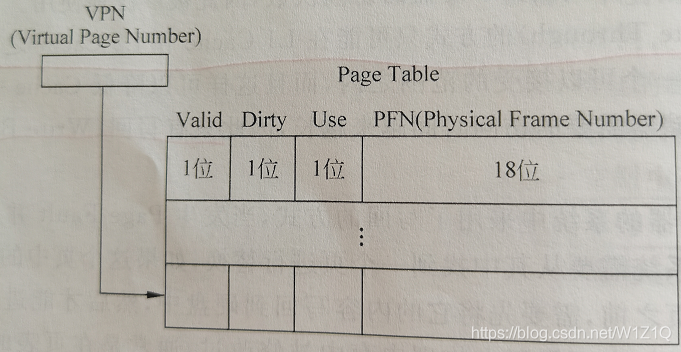
图10 页表中包括的内容
三 程序保护
在现代处理器运行的环境中,存在着操作系统和许多的用户进程,操作系统和用户对于存储空间需要有不同的访问权限,因此可以在页表上来实现这个功能,因为要访问存储器的内容必须要经过页表,所以在页表中对各个页规定不同的访问权限是很自然的事。
需要注意的是操作系统本身也需要指令和数据,但是考虑到它需要能够访问物理内存中所有的空间,所以操作系统一般不会使用页表,而是直接可以访问物理内存,在物理内存中有一部分地址范围专门供操作系统使用,不允许别的进程随便访问它。
在Arm处理器中,采用了两级页表的方法,第二级页表的每个PTE中都有一个AP部分,在Arm v7架构中,AP部分直接决定了每个页的访问权限,如表2所示。
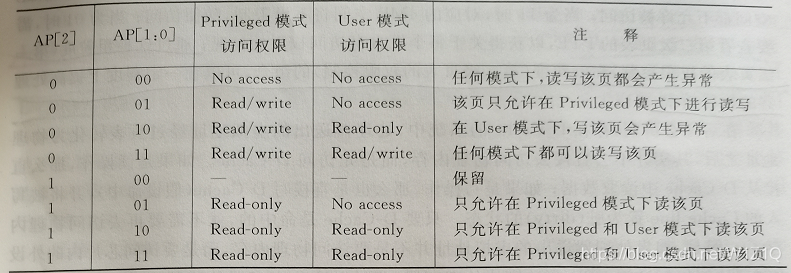
表2 Arm中每个页的权限管理
在Arm v7架构中,规定处理器可以工作在User模式和Privileged模式,在Privileged模式下,可以访问处理器内部所有的资源,因此操作系统会运行在这种模式下,而普通的用户程序则是运行在User模式下。在表2中,AP[2:0]位于PTE中,通过它,第二级页表可以控制每个页的访问权限,这样可以使一个页对于不同的进程有着不同的访问权限。
既然在页表中规定了每个页的访问权限,那么一旦发现当前的访问不符合规定,例如一个页不允许用户进程访问,但是当前的用户进程却要读取这个页的某个地址,这样就发生了非法访问,会产生给异常(exception)来通知处理器,使处理器跳转到异常处理程序中,这个处理程序一般是操作系统的一部分,由操作系统决定如何处理这种非法的访问,例如操作系统可以终止当前的用户进程,以防止恶意的程序对系统造成的破坏,图11为地址转换的过程中加入了权限检查的过程,注意此时在PTE中多了用来进行权限控制的AP部分。
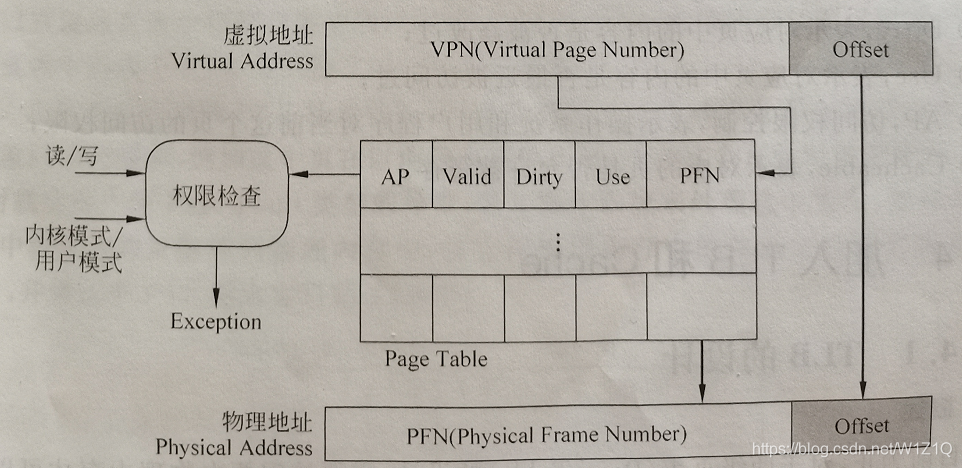
图11 加入程序保护之后的地址转换
当然如果采用了两级页表的结构,那么图11只给出了第二级页表的工作过程,事实上在第一级页表中叶可以进行权限控制,而且可以控制更大的地址范围。
举例来说,在前文讲述的页大小为4KB的系统中,第一级页表中每个PTE都可以映射一个完整的第二级页表,也就是4KBx1024=4MB的地址范围。
也就是说,第一级页表中的每个PTE都可以控制4MB的地址范围,这样可以更高效地对大片地址进行权限设置和检查。例如可以在第一级页表的每个PTE中设置一个两位的权限控制位,当其为00时,它对应的整个4MB空间都不允许被访问;当为11时,对应的4MB空间将不设限制,随便访问;当为01时,需要查看第二级页表的PTE,以获得关于每个页自身访问权限的情况;通过这种粗粒度(第一级页表的权限控制)和细粒度(第二级页表的权限控制)的组合,可以在一定程度上提高处理器的执行效率。
如果存在D-Cache的系统中,处理器送出的虚拟地址经过页表转换为物理地址之后,其实并不会直接去访问物理内存,而是先访问D-Cache。
如果是读操作,那么直接从D-Cache中读取数据;如果是写操作,那么也是直接写D-Cache(假设命中),并将被写入的Cacheline置为脏(dirty)状态。只要D-Cache是命中的,就不需要再去访问物理内存了。
但是,如果处理器送出的虚拟地址并不是访问物理内存,而是要访问芯片内的外设寄存器,例如要访问LCD驱动模块的寄存器,此时对这些寄存器的读写是为了对外设进行操作,因此这些地址是不允许经过D-Cache被缓存的,如果被缓存了,那么这些操作将只会在D-Cache中起作用,并不会传递到外设寄存器中而真正对外设模块进行操作,这样显然是不可以的,因此在处理器的存储器映射(memory map)中,总会有一块区域,是不可以被缓存的。例如MIPS处理器的kseg1区域就不允许被缓存,它的属性是uncached,这个属性也应该在页表中加以标记,在访问页表从而得到物理地址时,会对这个地址对应的页是否允许缓存进行检查,如果发现这个页的属性是不允许缓存的,那么就需要直接使用刚刚得到的物理地址来访问外设或物理内存;如果这个页的属性是允许被缓存,那么就可以直接使用物理地址对D-Cache进行寻址。
到本小结为止,总结起来,在页表中的每个PTE都包括如下的内容:
PFN,表示虚拟地址对应的物理地址的页号;
Valid,表示对应的页当前是否在物理内存中;
Dirty,表示对应页中的内容是否被修改过;
Use,表示对应页中的内容是否最近被访问过;
AP,访问权限控制,表示操作系统和用户程序对当前这个页的访问权限;
Cacheable,表示对应的页是否允许被缓存。
四 加入TLB和Cache
4.1 TLB的设计
4.1.1 概述
对两级页表来说,需要访问两次物理内存才可以得到虚拟地址对应的物理地址,而物理内存的运行速度相对于处理器本身来说,有几十倍的差距,因此整体下来速度很慢的。此时可以借鉴Cache的设计理念,使用一个速度比较快的缓存,将页表中最近使用的PTE缓存下来,因为它们在以后还可能继续使用,尤其对于取指令来说,考虑到程序本身的串行性,会顺序地从一个页内取指令,此时将PTE缓存起来是大有益处的,能够加快一个页内4KB内容的地址转换速度。
由于历史原因,缓存PTE的部件一般不称为Cache,而是称之为TLB(Translation Lookaside buffer),在TLB中存储了页表中最近被使用过的PTE,从本质上来讲,TLB就是页表的Cache。但是TLB又不同于一般的cache,它只有时间相关性(Temporal Locality),也就是说,现在访问的页,很有可能在以后继续被访问,至于空间相关性(Temporal Locality),TLB并没有明显的规律,因为在一个页内有很多情况,都可能使程序跳转到其他不相邻的页中取指令或数据,也就是说,虽然当前在访问一个页,但未必会访问它相邻的页,正因为如此,Cache设计中很多的优化方法,例如预取(prefetching),是没有办法应用于TLB中的。
既然TLB本质上是Cache,那么就有三种组织方法:直接相连、组相连和全相连。一般为了减少TLB缺失率,会用全相连来设计TLB,但容量过小的TLB会影响处理器的性能,因此在现代的处理器中,很多都采用两级TLB,第一级TLB采用哈佛结构,分为指令TLB(I-TLB)和数据TLB(D-TLB),一般采用全相连的方式;第二级TLB是指令和数据共享,一般采用组相连的方式,这种设计方法和多级Cache是一样的。
因为TLB是页表的Cache,那么TLB的内容是完全来自于页表的,如图12为一个全相连方式的TLB,从处理器送出的虚拟地址首先送到TLB中进行查找,如果TLB对应的内容是有效的(即valid位为1),则表示TLB命中,可以直接使用从TLB得到的物理地址来寻址物理内存;如果TLB缺失(即valid位为0),那么就需要访问物理内存中的页表,此时有如下两种情况:
(1) 在页表中找到的PTE是有效的,即这个虚拟地址所属的页存在于物理内存中,那么就可以直接从页表中找到对应的物理地址,使用它来寻址物理内存从而得到需要的数据,同时将页表中的这个PTE写回到TLB中,供以后使用;
(2) 在页表中找到的PTE是无效的,即这个虚拟地址所属的页不在物理内存中,造成这种现象的原因很多,例如这个页在以前没有被使用过,或者这个页已经被交换到了硬盘中等,此时就应该产生Page Fault类型的异常,通知操作系统来处理这个情况,操作系统需要从硬盘中将相应的页搬移到物理内存中,将它在物理内存中的首地址放到页表内对应的PTE中,并将这个PTE的内容写到TLB中。

图12 TLB内容
在图12中,因为TLB采用了全相连的方式,所以相比页表多了一个Tag的项,它保存了虚拟地址的VPN,用来对TLB进行匹配查找,TLB中其它的项完全来自于页表,每当发生TLB缺失时,将PTE从页表中搬移到TLB内。
4.1.2 TLB缺失
当一个虚拟地址查找TLB,发现需要的内容不在其中时,就发生了TLB缺失(miss),由于TLB本身的容量很小,所以TLB缺失发生的频率比较高,很多情况下都可以发生TLB缺失,主要有以下几种:
(1) 虚拟地址对应的页不在物理内存中,所以页表也没有对应的PTE,自然TLB中也不可能有的;
(2) 虚拟地址对应的页在物理内存中,所以页表中有对应的PTE,但这个PTE还没有放到TLB中,这种情况也经常发生,毕竟TLB的内容远小于页表;
(3) 虚拟地址对应的页在物理内存中,所以页表中有对应的PTE,这个PTE也曾存在于TLB中,但后来被替换出去了,现在这个也又重新使用了,此时这个PTE就存在于页表中,但不在TLB内。
解决TLB缺失的本质就是要从页表中找到对应的映射关系,并将其写回到TLB内,这个过程称为Page Table Walk,可以使用硬件状态机来完成这个事情,也可以使用软件来做这个事情,各有优缺点,各自工作流程如下:
(1) 软件实现Page Table Walk,软件实现可以保证最大的灵活性,但一般也需要硬件配合,来减少工作量,一旦发现TLB缺失,硬件把产生TLB缺失的虚拟地址保存到一个特殊寄存器中,同时产生一个TLB缺失类型的异常,在异常处理程序中,软件使用保存在特殊寄存器当中的虚拟地址去寻址物理内存中的页表,找到对应的PTE,并写回到TLB中,很显然,处理器需要支持直接操作TLB的指令,如写TLB指令和读TLB指令等。
对于超标量处理器,对异常处理时,会将流水线中所有的指令抹掉,这样会产生一些性能上缺失,但可以实现灵活的TLB替换算法,MIPS和Alpha处理器一般采用这种方法处理TLB缺失。为了防止在处理TLB缺失的异常处理程序再次发生TLB缺失,一般将这段异常处理程序放到一个不需要进行地址转换的预取,这样就可以直接使用物理地址来取指令和数据,避免再次发生TLB缺失的情况。软件处理TLB缺失的过程如图13所示。
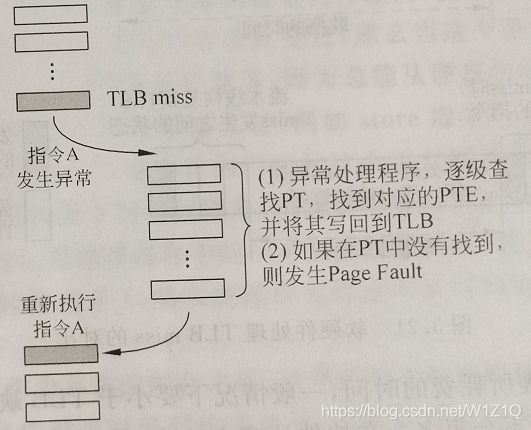
图13 软件处理TLB miss的流程
(2) 硬件实现Page Table Walk,硬件实现一般由内存管理单元(MMU)完成,当发现TLB缺失时,MMU自动使用当前的虚拟地址去寻址物理内存中的页表,前面说过,多级页表的最大优点就是容易使用硬件进行查找,只需要使用一个状态机逐级进行查找就可以,如果从页表中找到的PTE是有效的,那么将它写回到TLB中,这个过程全部由硬件自动完成的。
当然如果MMU发现查找到的PTE是无效的,那么就只能产生Page Fault类型的异常,由操作系统来处理整个情况。使用硬件处理TLB缺失更适合超标量处理器,它不需要打断流水线,因此从理论上来说,性能会好一点,但是这需要操作系统保证页表已经在物理内存中建立好了,并且操作系统也需要将页表的基地址预先写到处理器内部的寄存器中(例如PTR寄存器),这样才能保证硬件可以正确地寻址页表,Arm、PowerPC和x86处理器都采用了这种方法。
对于组相连或全相连结构的TLB,当一个新的PTE被写到TLB中时,如果当前TLB中没有空闲的位置了,那么就要考虑将其中的一个表项(entry)进行替换。理论上说,Cache中使用的替换方法在TLB里也可以,例如最少使用算法(LRU),但是实际上对于TLB来说,随机替换(Random)算法可以是一种比较合适的方法,通常可以采用时钟算法(Clock Algorithm)来实现近似的随机。
4.1.3 TLB的写入
当一个页从硬盘搬移到物理内存之后,操作系统需要知道这个页中的内容在物理内存中是否被改变过。如果没有被改变过,当这个页需要被替换时可以直接进行覆盖,因为总能从硬盘中找到这个页的备份;如果已经被修改过了,需要先将它从物理内存中写回到硬盘,因此需要在页表中,对每个被修改的页加以标记,称为脏状态位(dirty)。当物理内存中的一个页要被替换时,需要首先检查它在页表中对应PTE的脏状态位,如果它是1,那么就需要先将这个页写回到硬盘中,然后才能将其覆盖。
如果采用写回(Write Back)的TLB,那么使用位(use)和脏状态位(dirty)改变的信息并不会马上从TLB中写回到页表,只有等到TLB中的一个表项要被替换的时候,才会将它对应的信息写回到页表中,这种方式会给操作系统进行页表替换带来问题,因为页表中记录的状态位(use和dirty)可能是过时的。一种比较容易的解决办法就是操作系统在Page Fault发生时,首先将TLB中的内容写回到页表,然后就可以根据页表中的信息进行后续处理了。在实际上,操作系统完全可以认为被TLB记录的所有页都是需要被使用的,这些页在物理内存中不能够被替换。操作系统可以使用一系诶办法来记录页表中哪些PTE被放到了TLB中来实现。
如果在系统中使用了D-Cache,那么物理内存中每个页的最新内容都可能存在于D-Cache中,要将这个页的内容写回到硬盘,首先需要确认D-Cache中s会否保留着这个页的数据。因此在进行页表替换时,操作系统就必须有能力从D-Cache中找出这个页的内容,并将其写回到物理内存中,这部分后面会介绍的。
虽然对于TLB和D-Cache都是Cache,但在操作系统对物理内存进行页表替换时,所采取的的方法措施有点不同的,TLB中存在的页表在物理内存中不会替换,D-Cache中存在数据所对应地址的页表在物理内存中仍然会被替换,所以此时也需要将D-Cache的内容clean掉,切记两者的不同之处。
4.1.4 对TLB进行控制
如果由于某些原因导致一个页的映射关系在页表中不存在了,那么它在TLB中也不应该存在,而操作系统在一些情况下,会把某些页的映射关系从页表中抹掉,例如:
(1) 当一个进程结束时,这个进程的指令(code)、数据(data)和堆栈(stack)所占据的页表就需要变为无效,这样也就释放了这个进程所占据的物理内存空间。
但是,此时在I-TLB中可能存在这个进程的程序(code)对应的PTE,在D-TLB中可能还存在着这个进程的数据和堆栈的PTE,此时就需要将I-TLB和D-TLB中和这个进程相关的所有内容置为无效,如果没有使用ASID,最简单的做法就是将I-TLB和D-TLB中的全部内容都置为无效,这样保证新的进程可以使用一个干净的TLB;如果实现了ASID,那么只将这个进程对应的内容在TLB中置为无效就可以的;
(2) 当一个进程占用的物理内存过大时,操作系统可能会将这个进程中的一部分不经常使用页写回到硬盘中,这些页在页表中对应的映射关系也应该置为无效,此时当然也需要将I-TLB和D-TLB中对应的内容置为无效,但是,一般操作系统会尽量避免将存在于TLB中的页置为无效,因为这些页在以后很可能会被继续使用。
因此,抽象出来,对TLB的管理需要包括的内容有如下几点:
能够将I-TLB和D-TLB的所有表项(entry)置为无效;
能够将I-TLB和D-TLB中某个ASID对应的所有表项置为无效;
能够将I-TLB和D-TLB中某个VPN对应的表项置为无效;
不同的处理器有着不同的方法来对TLB进行管理,本节以Arm为例进行说明。在Arm处理器中,使用系统控制协处理器(Arm称之为CP15)中的寄存器对TLB进行控制,因此处理器只需要使用访问协处理器的指令(MCR和MRC)来向CP15中对应的寄存器写入相应的值,就可以对TLB进行操作。CP15中提供了如下的控制寄存器(以I-TLB和D-TLB分开的架构为例)。
(1) 用来管理I-TLB的控制寄存器,主要包括以下几种:
a. 将TLB中VPN匹配的表项置为无效的控制寄存器,但是VPN相等并不是唯一的条件,还需要满足两个条件:
① 如果TLB中一个表项的Global位无效,则需要ASID也相等;
② 如果TLB中一个表项的Global位有效,则不需要进行ASID比较。这个控制寄存器如图14所示。

图14 控制TLB的寄存器——使用VPN
b. 将TLB中ASID匹配的所有表项置为无效的控制寄存器,但是TLB中那些Global位有效的表项不会受影响,这个控制寄存器如图15所示。

图15 控制TLB的寄存器——使用ASID
c. 将TLB中所有未锁定(unlocked)状态的表项置为无效,那些锁定(locked)状态的表项则不会受到影响。为了加快处理器中某些关键程序的执行时间,可以将TLB中的某些表项设为锁定状态,这些内容将不会被替换掉,这样保证了快速的地址转换。
(2) 用来管理D-TLB的控制寄存器,他们和I-TLB控制寄存器的工作原理一样,也可以通过VPN和ASID对TLB进行控制,此处不再赘述;
(3) 为了便于对TLB的内容进行控制和观察,还需要能够将TLB中的内容进行读出和写入,如图16所示。
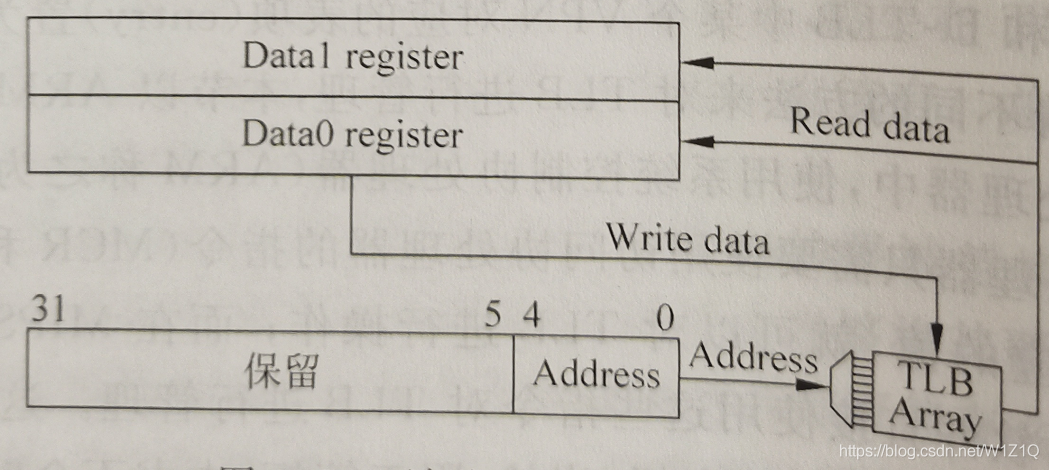
图16 读取TLB和写入TLB
由于TLB中一个表项的内容大于32位,所有使用两个寄存器来对应一个表项,如图16中的data0和data1寄存器,在Arm的Cortex A8处理器中,这两个寄存器位于协处理器CP15中。当读取TLB时,被读取的表项内容会放到这两个寄存器中;而在写TLB时,这两个寄存器中的内容会写到TLB中,当然,要完成这个过程,还需要给出寻址TLB的地址,例如一个表项个数为32的TLB,需要5位的地址来寻址,这个地址放在指令中指定的一个通用寄存器中。一般在调试处理器的时候,才会使用图15所示的功能。
总结来说,在Arm处理器中对TLB的控制是通过协处理器来实现的,因此只需要使用访问协处理器的指令(MCR和MRC)就可以了,其实不仅是对于TLB,在Arm处理器中对于存储器的管理,例如Cache和BTB等部件,都是通过协处理器来实现的,这种方式虽然比较灵活,但不容易使用。
4.2 Cache的设计
4.2.1 Cache的设计
Cache如果使用物理地址进行寻址,就称为物理Cache(Physical Cache),使用TLB和物理Cache一起进行工作的过程如图17所示。

图17 Physical Cache

图18 Virtual Cache
-
ARM的存储器映射与存储器重映射2014-03-24 3274
-
虚拟存储器组成部分2019-08-07 1743
-
基于虚拟存储器的USB下载线该如何去设计?2021-05-27 1715
-
虚拟存储体系由哪几级存储器构成2021-12-22 1451
-
虚拟存储器具有哪些功能和特征呢2021-12-23 2038
-
聊聊存储器的相关知识2022-02-11 1359
-
存储器的分类及原理2008-08-17 1188
-
虚拟存储器部件原理解析2010-04-15 3693
-
计算机的存储器主要作用_计算机的存储器的分类介绍2018-05-17 12611
-
存储器虚拟化的不同形式解析2020-07-20 1304
-
一文知道虚拟存储器的特征2020-11-15 5738
-
什么是虚拟存储器,虚拟存储器的特征2020-11-25 16887
-
简述存储器的层次结构及其分层原因2024-02-05 4137
-
虚拟存储器的概念和特征2024-05-24 5172
-
简述非易失性存储器的类型2024-09-10 4214
全部0条评论

快来发表一下你的评论吧 !
