

基于LRU-K模型如何实现高效的元数据缓存?
描述
对于存储来说,性能是绕不开的话题。当提到性能,可靠、高效的缓存策略是极其重要的。在计算机领域,缓存技术一般是指,用一个更快的存储设备存储一些经常用到的数据,供用户快速访问。用户不需要每次都与慢设备去做交互,因此可以提高访问效率。凡是位于速度相差较大的两种硬件之间,用于协调两者数据传输速度差异的结构,均可称之为缓存。缓存是提升访问性能的一个重要技术。缓存通过减少系统对数据库的访问量来提高系统性能。
存储层使用缓存的优势
目前缓存分为两种模式,一种是文件缓存,一种是内存缓存,文件缓存即缓存数据存放在服务器的硬盘空间中,内存缓存即缓存数据存放在服务器的内存空间中。在分布式文件存储中,客户端就能提供文件缓存,那为什么存储层还需要缓存呢?以下是存储层使用缓存的优势因素:
- 客户端资源有限,无法缓存海量的文件,而后端存储则可以线性扩展,可以缓存更多的数据。
- 后端存储可以根据整个存储情况提供更全面的缓存,比如说多个客户端同时访问热点。
- 分布式文件存储中,客户端散布各个终端节点,存储层的缓存可以保证一致性,更加安全可靠。
- 存储层可以根据我们数据在物理机上的分布特点,灵活调配缓存大小和策略。
存储层的缓存能力是提升分布式存储性能非常重要的部分,今天我们主要讨论利用 LRU-K 模型如何实现高效的元数据缓存?
LRU-K 模型的优势及运作模式
内存中的读写速度很快,基于此很多缓存技术都喜欢将数据存在内存中,但是内存空间是有限的,当到达一定量后需要将一些不常用的缓存数据删除或者落盘。缓存淘汰算法顺应而生,其中 LRU、LRU-K 就是比较常见的,目的都是为了高效地维护缓存数据。
LRU 的基本思想是如果数据最近被访问过,那么将来被访问的几率更高。我们实现 LRU 时,要维护一个队列,第一次访问的数据直接入队,重复访问的缓存,将该数据移至队尾,需要删除时删除队头的数据,这样就能保持队列越往后,数据再次被访问的可能性就越大。LRU 缓存变换之快这是它的优点也是它的缺点,因为只需要一次访问就能成为最新鲜的数据,当出现很多偶发数据时,这些偶发的数据也会被当作最新鲜的,从而成为缓存。但其实这些偶发数据以后并不会被经常访问到。在文件系统里,这个现象会更加明显,绝大部分文件/目录只在业务过程中单次去查询,而热点往往集中在少量文件。
LRU-K 的主要目的是为了解决 LRU 算法"缓存污染"的问题,其核心思想是将"最近使用过 1 次"的判断标准扩展为"最近使用过 K 次"。LRU-K 提供两个 LRU 队列,一个是访问计数队列,一个是标准的 LRU 队列,两个队列都按照 LRU 规则淘汰数据。当访问一个数据时,数据先进入访问计数队列,当数据访问次数超过 K 次后,才会进入标准 LRU 队列。标准的 LRU 算法相当于 LRU-1;LRU-K 具有 LRU 的优点,同时能够避免 LRU 的缺点,实际应用中 LRU-2 是综合各种因素后最优的选择,LRU-3 或者更大的 K 值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
目录的结构是树形的,这就决定了我们不能平等地去看待每一个目录,越接近树顶的目录,它的访问概率越高,访问频次越高,这些是最值得保存的数据。所以 LRU-K 更适合海量目录场景下的缓存淘汰。
采用 LRU-K 模型实现目录的缓存:
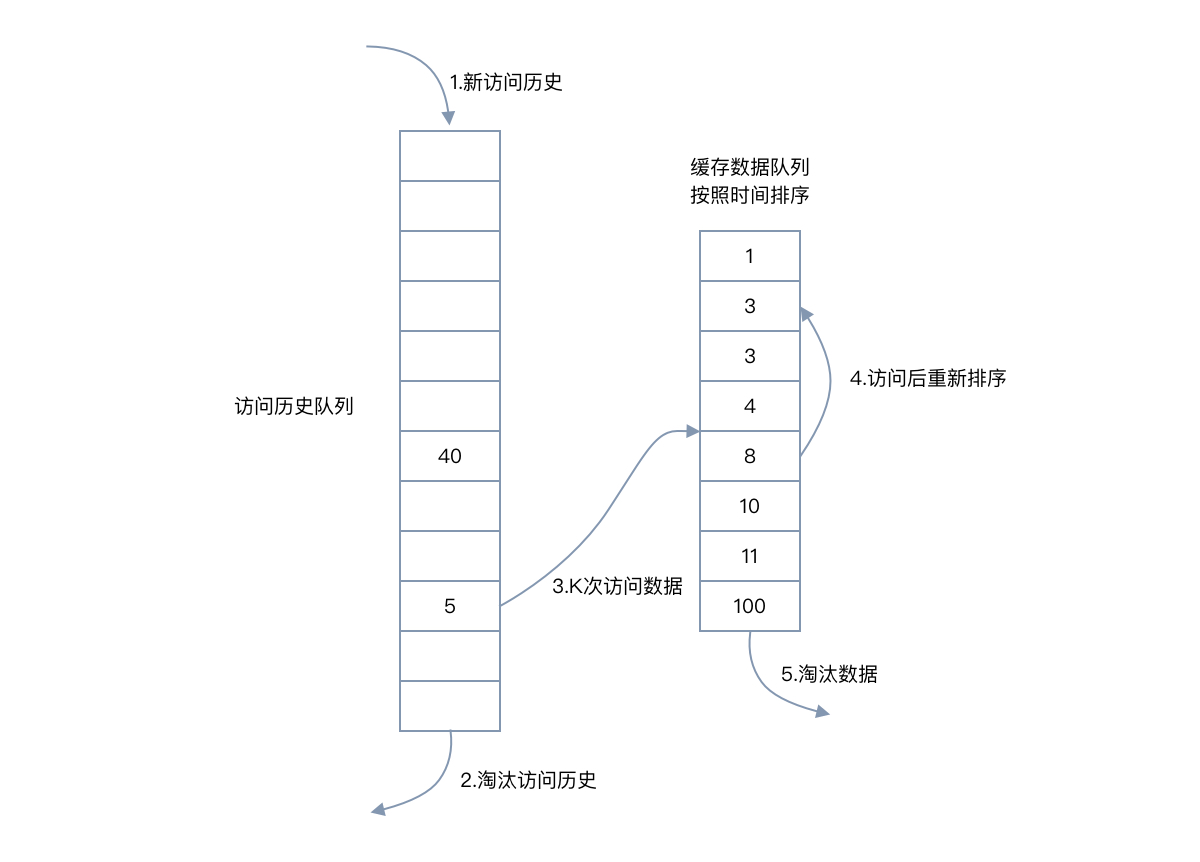
- 数据第一次被访问,加入到访问历史列表;
- 如果数据在访问历史列表里后没有达到 K 次访问,则按照一定规则(LRU)淘汰;
- 当访问历史队列中的数据访问次数达到 K 次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
- 缓存数据队列中被再次访问后,重新排序;
- 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第 K 次访问离现在最久”的数据。
存储层使用缓存加速元数据性能是一种有效的方法,它可以提高分布式文件存储的访问效率和一致性,同时减少对数据库的压力。LRU-K 模型是一种适合海量目录场景下的缓存淘汰算法,它可以避免缓存污染的问题,保证缓存数据的热度和新鲜度。焱融分布式文件存储 YRCloudFile 提供元数据服务的组件是 MDS,在海量目录百亿级文件规模场景下实现了高效的存储层的元数据缓存,能够提供卓越的性能和可靠性,满足用户对文件存储的各种需求,实测性能成倍提升,为用户提供了高性能、高可靠、高扩展的存储服务。
-
LRU缓存模块最佳实践2023-09-30 1924
-
Redis的LRU实现和应用2023-12-15 1554
-
脉冲神经元模型的硬件实现2025-10-24 311
-
KeepAlive:组件缓存实现深度解析2026-03-05 1107
-
【原创】Android开发—Lru核心数据结构实现突破缓存框架2016-06-21 2703
-
高速缓存/海量缓存的设计实现2020-12-04 1685
-
架构设计应用级缓存回收策略2021-01-14 1591
-
高速数据采集系统中高速缓存与海量缓存的实现2009-04-23 836
-
Ceph文件系统的数据缓存备份2018-02-08 1170
-
基于OpenFlow分组缓存管理模型2018-02-26 800
-
适用于命名数据网络的缓存内容分类模型2021-05-12 777
-
设计并实现一个满足LRU约束的数据结构2023-06-07 1701
-
Redis的LRU与LFU算法实现2023-07-11 2167
-
redis的lru原理2023-12-05 1374
-
关于LRU(Least Recently Used)的逻辑实现2024-11-12 1926
全部0条评论

快来发表一下你的评论吧 !
