

为什么 MySQL 单表不能超过 2000 万行?
电子说
描述
最近看到一篇《我说 MySQL 每张表最好不要超过 2000 万数据,面试官让我回去等通知》的文章,非常有趣。
文中提到,他朋友在面试的过程中说,自己的工作就是把用户操作信息存到 MySQL 里,因为数据量超大(5000 万条左右),需要每天定时生成 3 张表,然后将数据取模分别存到这三张表里。
接下来是两人的对话:

面试后续暂且不论,不过,互联网江湖上的确流传着一个说法:单表数据量超过 500 万行时就要进行分表分库,已经超过 2000 万行时 MySQL 的性能就会急剧下降。
那么,MySQL 一张表最多能存多少数据?
今天我们就从技术层面剖析一下,MySQL 单表数据不能过大的根本原因是什么?
猜想 1,是索引深度吗?
很多人认为:数据量超过 500 万行或 2000 万行时,引起 B+tree 的高度增加,延长了索引的搜索路径,进而导致了性能下降。事实果真如此吗?
我们先理一下关系,MySQL 采用了索引组织表的形式组织数据,叶子节点存储数据,非叶子节点存储主键与页面号的映射关系。若用户的主键长度是 8 字节时,MySQL 中页面偏移占 4 个字节,在非叶子节点的时候实际上是 8+4=12 个字节,12 个字节表示一个页面的映射关系。
MySQL 默认是 16K 的页面,抛开它的配置 header,大概就是 15K,因此,非叶子节点的索引页面可放 15*1024/12=1280 条数据,按照每行 1K 计算,每个叶子节点可以存 15 条数据。同理,三层就是 15*1280*1280=24576000 条数据。只有数据量达到 24576000 条时,深度才会增加为 4,所以,索引深度没有那么容易增加,详细数据可参考下表:
搜索路径延长导致性能下降的说法,与当时的机械硬盘和内存条件不无关系。
之前机械硬盘的 IOPS 在 100 左右,而现在普遍使用的 SSD 的 IOPS 已经过万,之前的内存最大几十 G,现在服务器内存最大可达到 TB 级。
因此,即使深度增加,以目前的硬件资源,IO 也不会成为限制 MySQL 单表数据量的根本性因素。
那么,限制 MySQL 单表不能过大的根本性因素是什么?
猜想 2,是 SMO 无法并发吗?
我们可以尝试从 MySQL 所采用的存储引擎 InnoDB 本身来探究一下。
大家知道 InnoDB 引擎使用的是索引组织表,它是通过索引来组织数据的,而它采用 B+tree 作为索引的数据结构。B+Tree 操作非原子,所以当一个线程做结构调整(SMO,Struction-Modification-Operation)时一般会涉及多个节点的改动。
SMO 动作过程中,此时若有另一个线程进来可能会访问到错误的 B+Tree 结构,InnoDB 为了解决这个问题采用了乐观锁和悲观锁的并发控制协议。
InnoDB 对于叶子节点的修改操作如下:
方法一,先采用乐观锁的方式尝试进行修改。
对根节点加 S 锁(shared lock,叫共享锁,也称读锁),依次对非叶子节点加 S 锁。
如果叶子节点的修改不会引起 B+Tree 结构变动,如分裂、合并等操作,那么只需要对叶子节点进行加 X 锁(exclusive lock,叫排他锁,也称为写锁)即可完成修改。如下图中所示 :
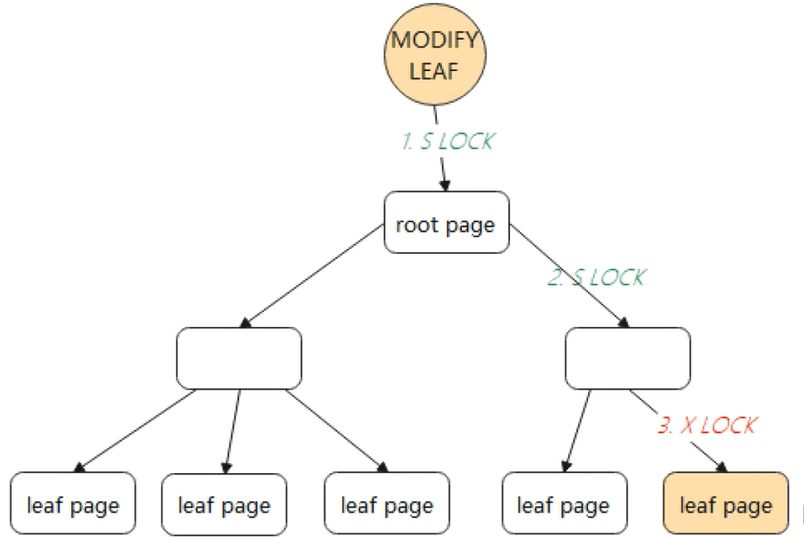
方式二,采用悲观锁的方式
如果对叶子结点的修改会触发 SMO,那么会采用悲观锁的方式。
采用悲观锁,需要重新遍历 B+Tree,对根节点加全局 SX 锁(SX 锁是行锁),然后从根节点到叶子节点可能修改的节点加 X 锁)。在整个 SMO 过程中,根节点始终持有 SX 锁(SX 锁表示有意向修改这个保护的范围,SX 锁与 SX 锁、X 锁冲突,与 S 锁不冲突),此时其他的 SMO,则需要等待。
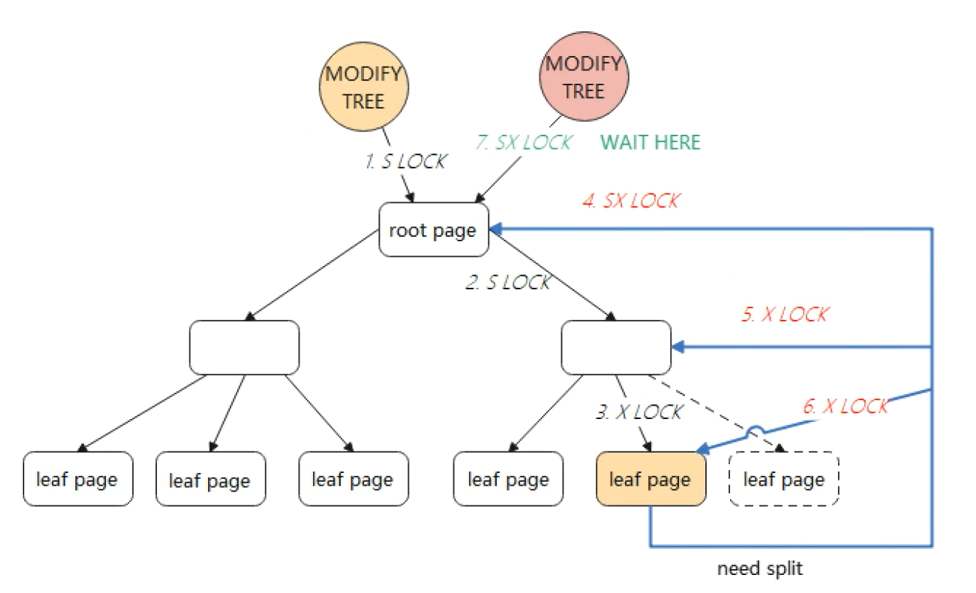
因此,InnoDB 对于简单的主键查询比较快,因为数据都存储在叶子节点中,但对于数据量大且改操作比较多的 TP 型业务,并发会有很严重的瓶颈问题。
在对叶子节点的修改操作中,InnoDB 可以实现较好的 1 与 1、1 与 2 的并发,但是无法解决 2 的并发。因为在方式 2 中,根节点始终持有 SX 锁,必须串行执行,等待上一个 SMO 操作完成。这样在具有大量的 SMO 操作时,InnoDB 的 B+Tree 实现就会出现很严重的性能瓶颈。
解决方案
目前业界有一个更好的方案 B-Link Tree,与 B+Tree 相比,B-Link Tree 优化了 B+Tree 结构调整时的锁粒度,只需要逐层加锁,无需对 root 节点加全局锁,因此,可以做到在 SMO 过程中写操作的并发执行,保持高并发下性能的稳定。
主要改进点有 2 个:
1.中间节点增加 link 指针,指向右兄弟节点;
2.每个节点内增加字段 high key,存储该节点中最大的 key 值。
新增的 link 指针便是为了解决 SMO 过程中并发写的问题,在 SMO 过程中,B-Link Tree 对修改节点逐层加锁,修改完一层即可放锁,然后去加上一层节点的锁继续修改。这样在 InnoDB 引擎中被 SMO 阻塞的写操作可以有机会再 SMO 操作过程中并发进行。
如下图所示,在节点 2 分裂为节点 2 和 4 的过程中,只需要在最后一步将父节点 1 指向新节点 4 时,对父节点 1 加锁,其他操作均无需对父节点加锁,更无需对 root 节点加锁,因此,大大提升了 SMO 过程中写操作的并发度。
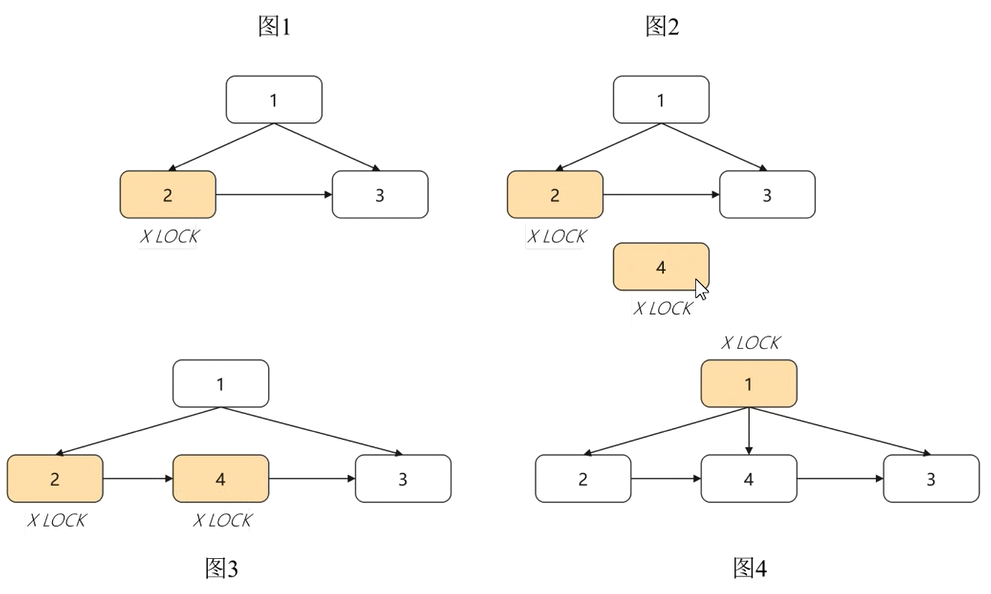
由此可见,和 B+Tree 全局加锁对比起来,B-Link Tree 在高并发操作下的性能是显著优于 B+Tree 的。华为云 GaussDB 当前采用的就是 B-Link Tree 索引数据结构。
InnoDB 的索引组织表更容易触发 SMO
索引组织表的叶子节点,存储主键以及应对行的数据,InnoDB 默认页面为 16K,若每行数据的大小为 1000 字节,每个叶子节点仅能存储 16 行数据。
在索引组织表中,当叶子节点的扇出值过低时,SMO 的触发将更加频繁,进而放大了 SMO 无法并发写的缺陷。
目前业界有一个堆组织表的数据组织方案,也是华为云数据库 GaussDB 采用的方案。它的叶子节点存储索引键以及对应的行指针(所在的页面编号及页内偏移),堆组织表叶子节点可以存更多的数据,分析可得在同样的数据量与业务并发量下,堆组织表会比索引组织表发生 SMO 概率低许多。
性能对比
在 8U32G 的两台服务器分别搭建了 MySQL(B+Tree 和索引组织表)与 GaussDB(B-Link Tree 和堆组织表)的环境,进行了如下性能验证:
实验场景:在基础表的场景上,测试增量随机插入性能。
1.基础表总大小 10G,包含主键随机分布的 1000w 行数据,每行数据 1k;
2.插入主键随机分布的 1000w 行数据,每行数据大小 1k,测试并发插入性能。
结论:随着并发数的上升,GaussDB 能稳步提升系统的 TPS,而 MySQL 并发数的提高并不能带来 TPS 的显著提升。
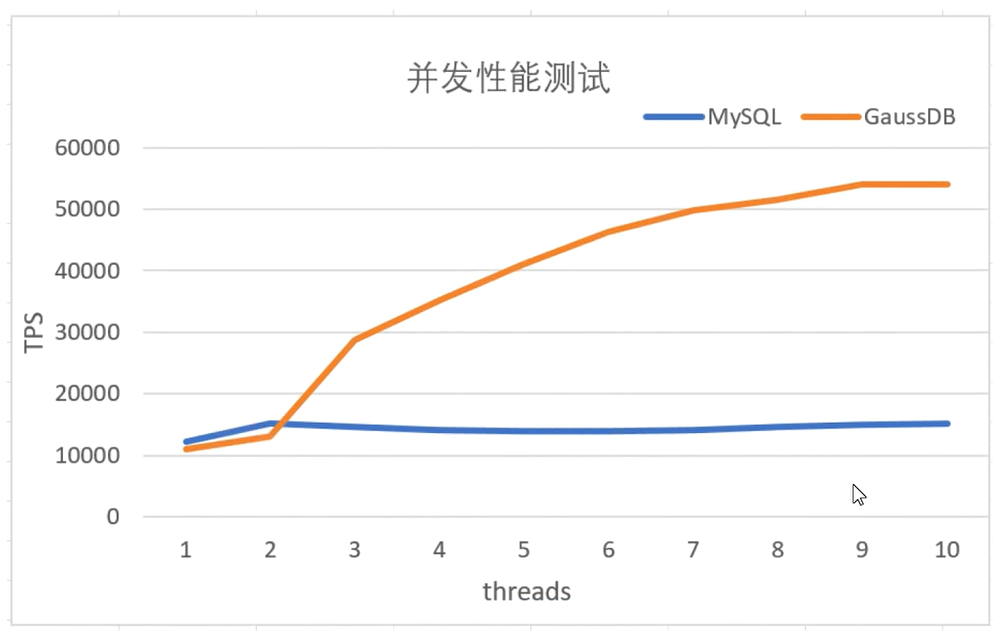
总结
MySQL 无法支持大数据量下并发修改的根本原因,是因为其索引并发控制协议的缺陷造成的,而 MySQL 选择索引组织表,又放大了这一缺陷。所以,开源 MySQL 数据库更适用于主键查询为主的简单业务场景,如互联网类应用,对于复杂的商业场景限制比较明显。
相比之下,采用 B-Link Tree 和堆组织表的 GaussDB 数据库在性能和场景应用方面更胜一筹。
审核编辑 黄宇
-
谁说MySQL单表行数不要超过2000W?2023-12-15 2256
-
新版架构师系列-ShardingJDBC分库分表mysql数据库实战2026-05-18 59
-
v90绝对值伺服,在断电后不能超过半圈为什么2026-05-25 54
-
PoE交换机供电的功率为什么不能超过30瓦?2016-03-17 9335
-
800万行代码的鸿蒙系统,在世界上处于什么水平?2020-09-29 3997
-
【HarmonyOS】800万行代码的鸿蒙系统,在世界上处于什么水平?2020-10-27 2005
-
阿里巴巴推出每秒撰写2万行广告文案的AI新工具2018-07-07 3604
-
涛思数据开源TDengine,10多万行C代码,登顶GitHub!2019-07-31 14256
-
一个函数究竟能不能超过50行呢?2021-06-11 5121
-
MySQL单表数据最大不要超过多少行2023-06-02 1477
-
MySQL单表数据最大不要超过多少行?为什么?2023-07-06 2174
-
再创新高!深开鸿OpenHarmony社区代码贡献量超过200万行!2023-10-13 1443
-
社区代码贡献企业启新篇,深开鸿代码贡献量超过200万行2023-10-18 1631
-
MySQL单表数据量限制:为何2000万行成为瓶颈?2024-02-27 8599
-
丝杆模组为什么行程不能超过两米?2024-12-24 1150
全部0条评论

快来发表一下你的评论吧 !
