

AMD CPU之路-Chiplets
描述
在AMD的ZEN架构出现一开始,就是定义一个基本原则,一个core的架构,从laptop到desktop到server,这个也符合2015年AMD的股价,基本上没有钱做其他的路线了,而它的金主Intel的确风光呀,收购FPGA,AI公司,架构上,mobile,laptop,desktop,server上面都是百花齐放,每个方向至少两个不同的方向。记得我刚进Xilinx的时候,大家说Intel的FPGA的PCIE Gen4一直出不来,主要原因是Intel内部至少有两个team在做PCIE,一个做4.0, 一个做5.0.
这个一招鲜吃遍天的做法,已经被ARM玩得炉火纯青了。一个架构的design,可以在mobile,也可以在server上。当年死在沙滩上的calxeda就是这样的。
因此。对于第一代的ZEN的架构,在Desktop上的确获得很大的成功,但是在server上面让中国的头号云计算玩家甚是失望。一个core的架构,来通吃整个市场,需要通过power和clocking的控制来实现。在下图中,基本也就在Desktop实现了突破。
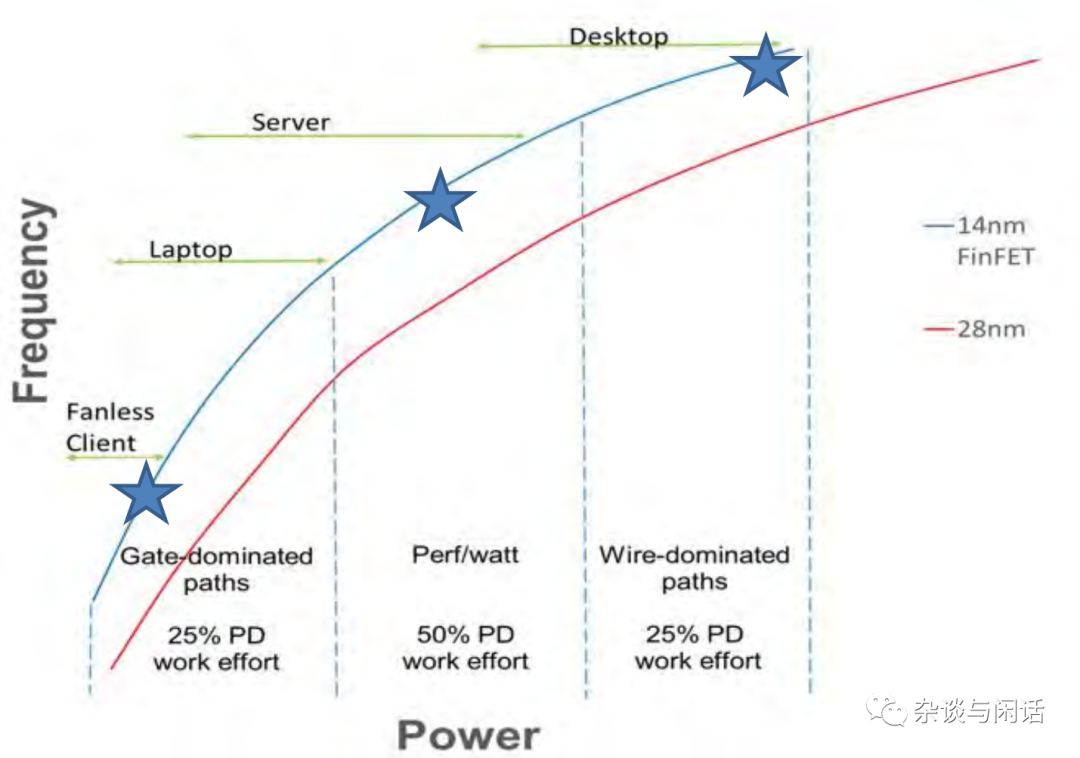
通过小die来提升良率,使用CCX进行互联,这个是没有免费午餐的。但是,AMD因为比较专一,在CCX的设计上的确是翻身了。
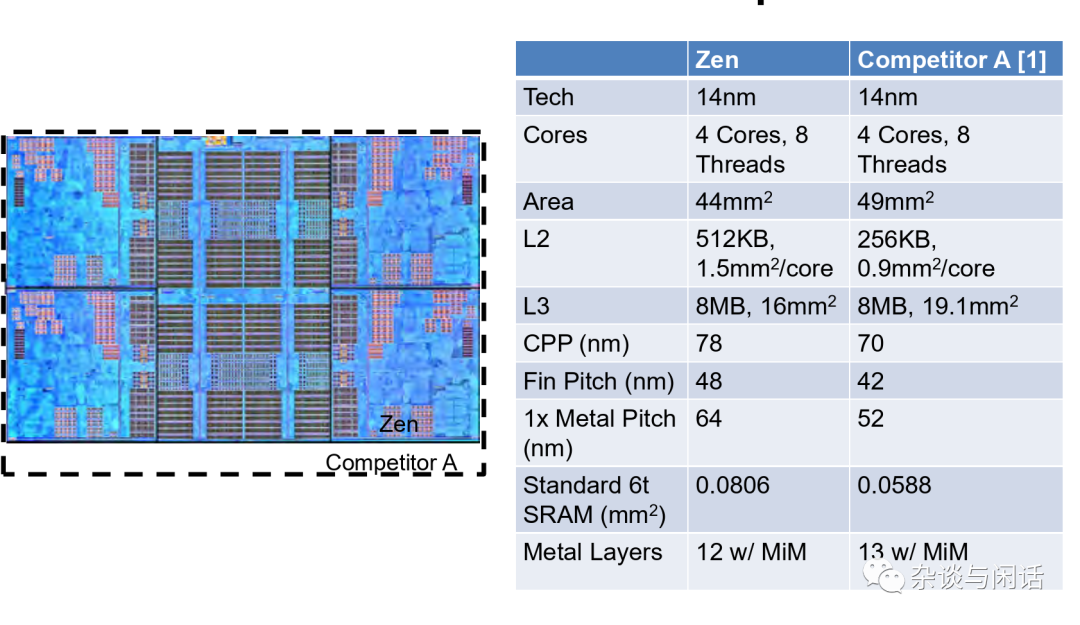
架构上面,和传统的单die的CPU设计也有区别。使用ARM架构常用的Core和IO 分离的架构。
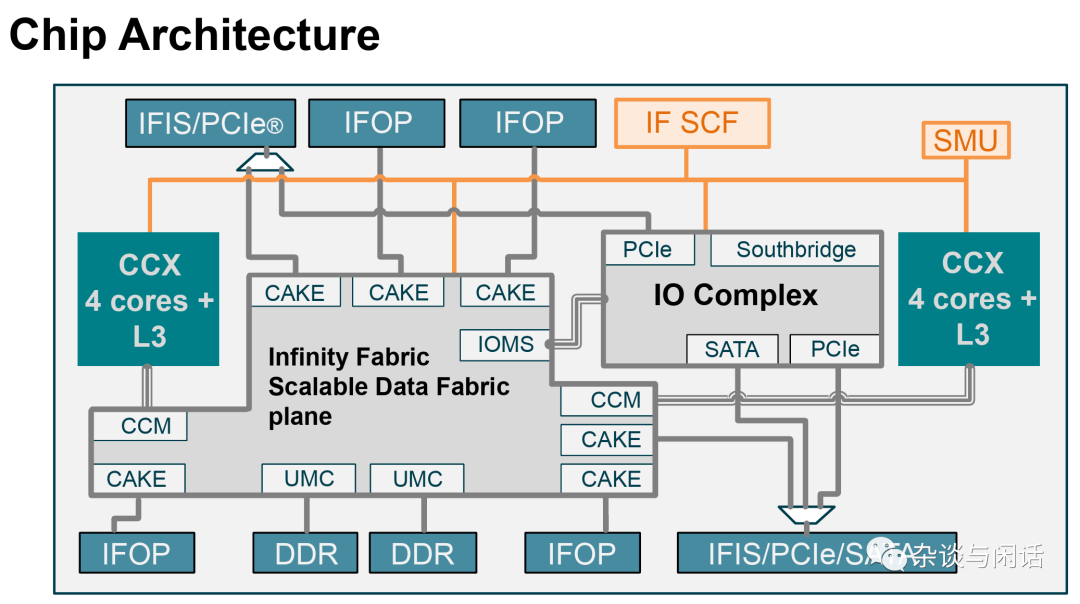
通过IF互联的代价也很明确,就是天生NUMA。这个也是AMD的系统优化一直强调的NPS (NUMA Nodes per Socket)。local 和remote 之间的差距有点不忍直视。但是,既然走了这一步,AMD拼命加L3 cache的行为就说明他们还是明白“失之东隅 收之桑榆”的祖训的。
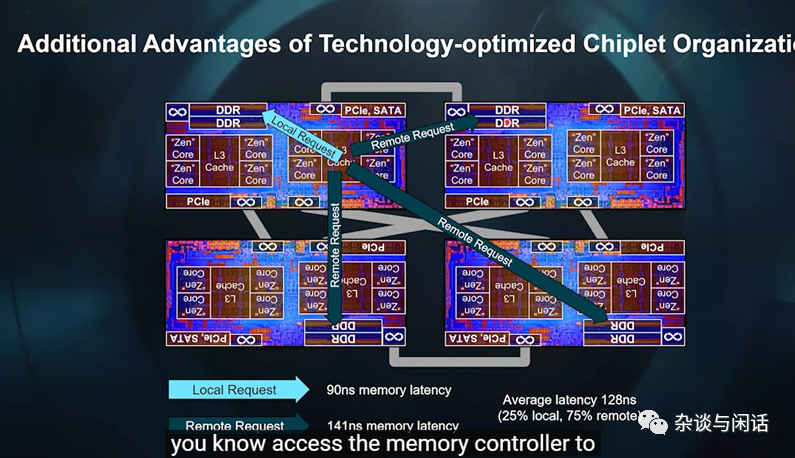
本文的重点是Chiplets,在AMD ISCA2021的paper 中,说明了Fabless公司面临的恶劣环境。
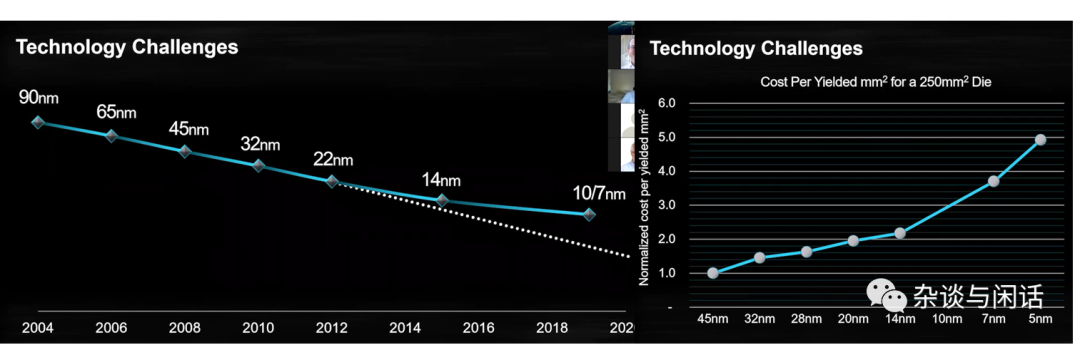
Mooer定律没死,但是的确老了,14nm之后的成本曲线变了。因此AMD早在14nm就开始改架构了。这个是AMD Zen成功的关键。

Die的大小增加了10%,但是成本只有6成,漂亮。
这个时候,最大的32Core 已经被对手的28好不少了,但是AMD的已经看到了ARM 服务器那种夸张的数量。怎么才能拉垮等等呢?
TSMC的7nm是生逢其时。
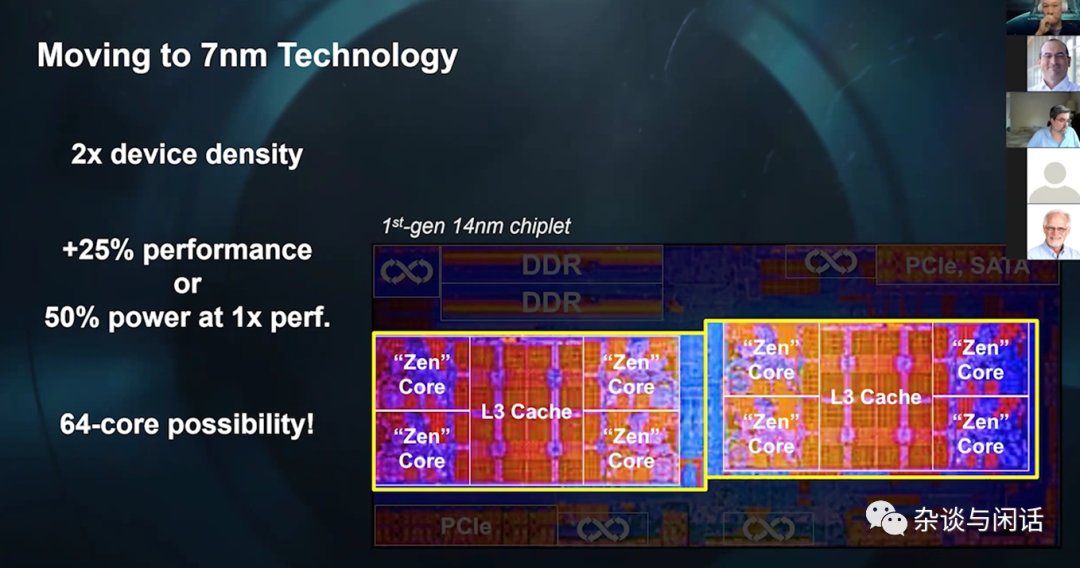
另一个关键的因素是剥离了IO,让IO 和Core独立发展。原因很简单,因为IO部分拿到的制成红利不多。

因此,在这个里面也充分说明了AMD精打细算的特质。在有人问到为什么要CPU上chiplets,而不是GPU时, 人家说了大实话,一个cpu的计算单元很大,8个少一个,就是损失了12%, 但是GPU里面的计算单元很很多,少几个没啥关系,不是有什么1080/1070/1060/1050/1040吗?
因此2代Zen真的是省上加省。
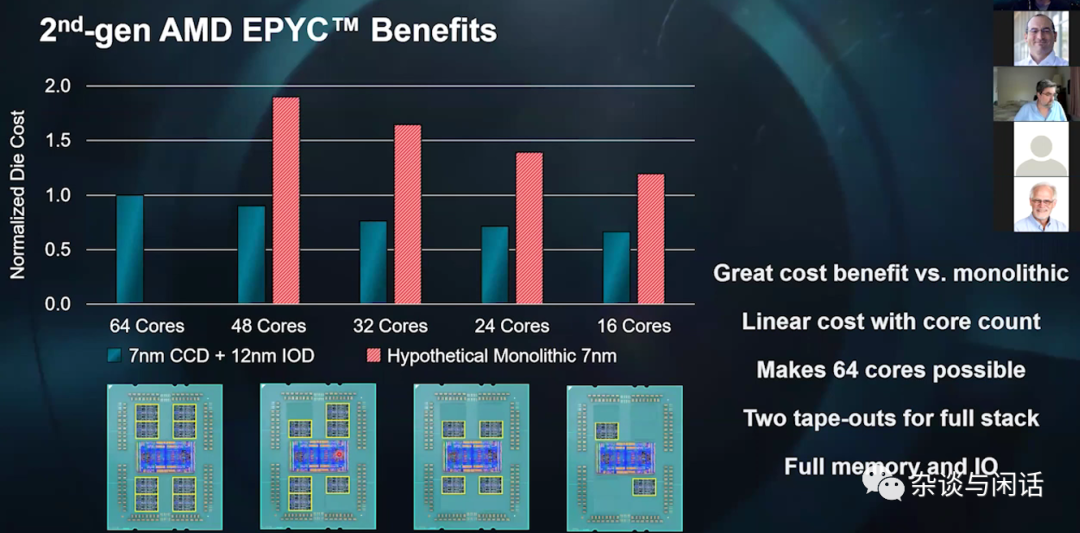
同时,增加了IO Die,对于访存延时也有了改观。
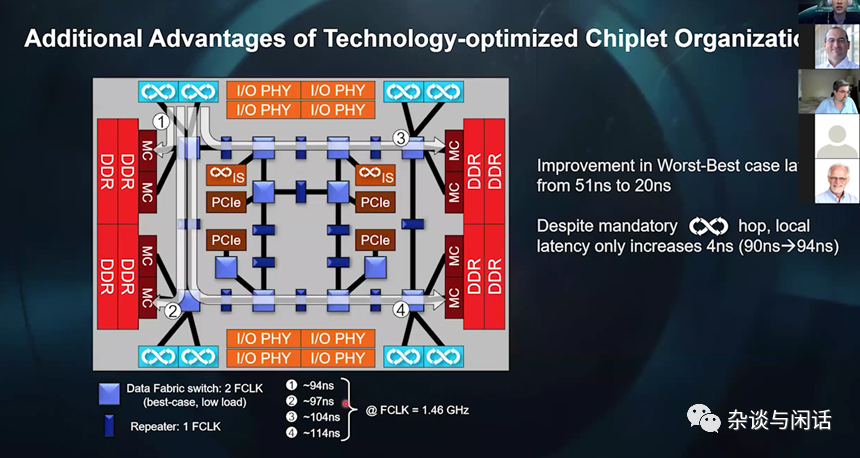
虽然本地的延时大了4ns,但是remote的降低了,满足全世界人民的愿望:“不患寡,患不均”。大家都一起拉垮吧。
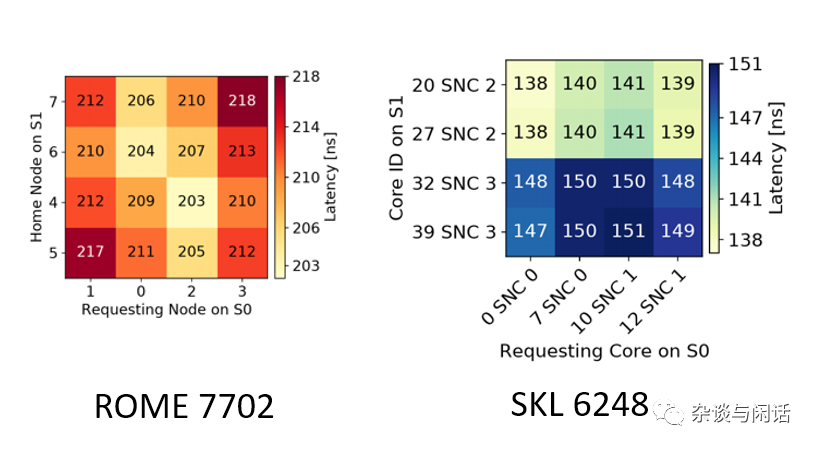
因此,Zen2 在desktop,laptop和Server上做到了复兴,南海边的Hyperscale大获成功,据说他们的口号是“省一半”。
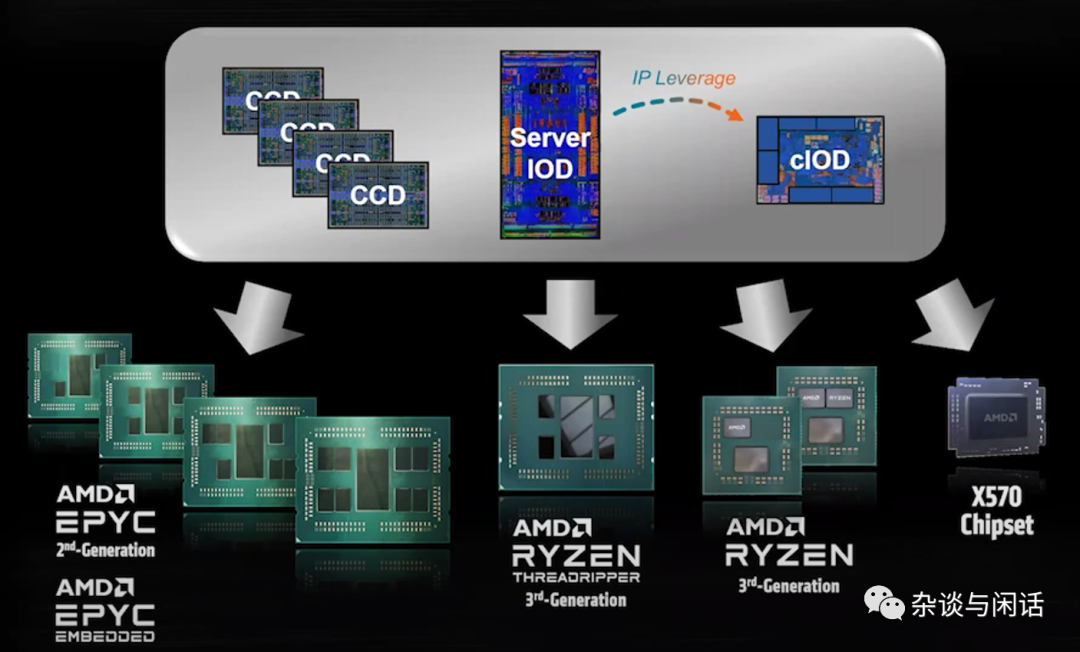
说到省,另一个没有想到的是Desktop 的io die也被拿去了做chipset。这个太高明了,以后ARM服务器出来之后,估计大部分的人IO Die可以直接做PCIE switch。
因此,在中国打压吃喝玩乐,单投硬科技的场景下,Chiplets成了一个香饽饽,这国人最迷信的“弯道超车”的白日梦中,chiplets一级本炒的火热了。好多没做过个芯片的,都要做先整个chiplets。但是chiplets真的好吗?请看AMD诚实的告白:

What,你的Core不一样?
但是,AMD的用户和超市排队买便宜鸡蛋的大妈一样,我们有时间,有兴趣折腾。老板这个时候说了,便宜是硬道理,你们工程师自己去适配,这样不就锻炼了队伍吗? 同样,我这个系列就不放引用了,你们读了文章,还自己去找出处,也锻炼了大脑和翻墙的技巧。
审核编辑:刘清
-
acer Aspire 4220 AMD CPU驱动下载2008-10-11 655
-
AMD双核CPU优化驱动2010-01-26 1108
-
AMD双核CPU优化程序AMD Dual-Core Opti2010-04-09 733
-
AMD CPU核心2009-12-17 1169
-
AMD移动CPU2009-12-18 670
-
AMD CPU核心简介2009-12-24 1281
-
AMD走上复兴之路 将打造公平竞争的产业环境2010-01-21 1053
-
CPU补丁不兼容 微软:是AMD文档问题2018-01-09 1619
-
AMD与Intel的CPU插槽区别2019-06-25 11572
-
AMD和Intel为什么不推出双路CPU2019-12-26 3543
-
2022年AMD Zen4处理器会升级到5nm工艺2020-09-24 2638
-
UCIe技术:实现Chiplets封装集成的动机2022-07-25 1599
-
为什么Chiplets对处理器的未来如此重要?2023-06-05 1389
-
AMD计划生产基于Arm架构的CPU2023-10-27 2233
-
值得入手的AMD Radeon 显卡推荐—— AMD Radeon RX 7900 XT2024-01-04 3186
全部0条评论

快来发表一下你的评论吧 !
