

Linux环境中常用的VXLAN实现实例
嵌入式技术
描述
云计算环境的一个典型属性是多租户共享物理资源。其中每个租户可以构建自己专属的虚拟逻辑网络,而每个逻辑网络都需要由唯一的标识符来标识。不同的逻辑网络默认情况下相互隔离。传统上,网络工程师一般使用VLAN来隔离不同二层网络,但VLAN的标识符命名空间只有12位,只能提供4096个标识符,这无法满足大型云计算环境的需求。
另外,使用VLAN隔离虚拟逻辑网络,往往需要对底层物理网络设备进行手动配置,这无法满足云计算环境的自动化需求。为了解决VLAN在网络虚拟化环境中应用存在的种种问题,Cisco,VMware等厂商提出了新的网络协议VXLAN来隔离虚拟逻辑网络。
VxLAN基本原理
VXLAN的全称为Virtual eXtensible LAN,从名称看,它的目标就是扩展VLAN协议。802.1Q的VLAN TAG只占12位,只能提供4096个网络标识符。而在VXLAN中,标识符扩展到24位,能提供16777216个逻辑网络标识符,VXLAN的标识符称为VNI(VXLAN Network Identifier)。另外,VLAN只能应用在一个二层网络中,而VXLAN通过将原始二层以太网帧封装在IP协议包中,在IP基础网络之上构建overlay的逻辑大二层网络。
我们来看具体协议包结构。VXLAN将二层数据帧封装在UDP数据包中,构建隧道在不同节点间通信。包结构如图:
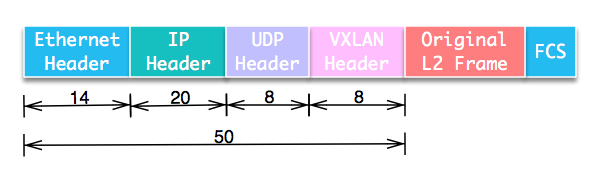
从包结构上可以看到,VXLAN会额外消耗50字节的空间。为了防止因数据包大小超过网络设备的MTU值而被丢弃,需要将VM的MTU减少50甚至更多,或者调整中间网络设备的MTU。
VXLAN协议中将对原始数据包进行封装和解封装的设备称为VTEP(VXLAN Tunnel End Point),它可以由硬件设备实现,也可以由软件实现。
VXLAN的整体应用示意拓朴结构如图:
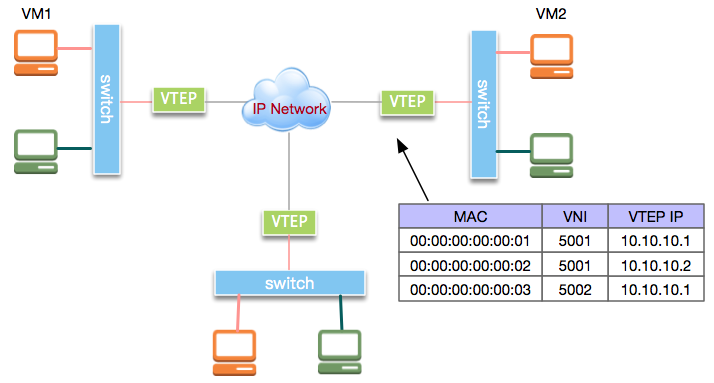
我们来看VXLAN的通信过程。在上图的虚拟机VM1和VM2处于逻辑二层网络中。VM1发出的二层以太网帧由VTEP封装进IP数据包,之后发送到VM2所在主机。VM2所在主机接收到IP报文后,解封装出原始的以太网帧再转发给VM2。
然而,VM1所在主机的VTEP做完数据封装后,如何知道要将封装后的数据包发到哪个VTEP呢?实际上,VTEP通过查询转发表来确定目标VTEP地址,而转发表通过泛洪和学习机制来构建。目标MAC地址在转发表中不存在的流量称为未知单播(Unknown unicast)。广播(broadcast)、未知单播(unknown unicast)和组播(multicast)一般统称为BUM流量。VXLAN规范要求BUM流量使用IP组播进行洪泛,将数据包发送到除源VTEP外的所有VTEP。目标VTEP发送回响应数据包时,源VTEP从中学习MAC地址、VNI和VTEP的映射关系,并添加到转发表中。后续VTEP再次发送数据包给该MAC地址时,VTEP会从转发表中直接确定目标VTEP,从而只发送单播数据到目标VTEP。
OpenvSwitch没有实现IP组播,而是使用多个单播来实现洪泛。洪泛流量本身对性能有一定影响,可以通过由controller收集相应信息来填充转发表而避免洪泛。
Linux环境中常用的VXLAN实现有两种:
Linux内核实现
OpenvSwitch实现接下来分别以实例来说明。
Linux 的实现
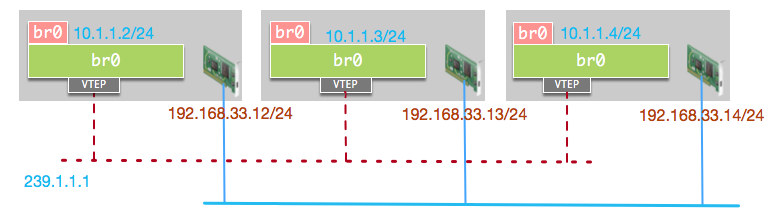
首先看Linux内核实现实例。我们的测试环境有三台主机,物理网卡IP分别为192.168.33.12/24, 192.168.33.13/24和192.168.33.14/24。我们在每台机器上创建一个Linux Bridge, 三台主机上的Linux Bridge默认接口的IP分别设置为10.1.1.2/24, 10.1.1.3/24和10.1.1.4/24。此时三台主机的Linux网桥处于同一虚拟二层网络,但由于没有相互连接,所以无法互相访问。我们通过建立VXLAN隧道使其可互相访问实现虚拟二层网络10.1.1.0/24。网络结构如图:
首先在主机1上创建Linux网桥:
brctl addbr br0
给网桥接口设置IP并启动:
ip addr add 10.1.1.2/24 dev br0 ip link set up br0
我们从主机1访问主机2上的虚拟二层网络IP, 访问失败:
[root@localhost vagrant]# ping 10.1.1.3 PING 10.1.1.3 (10.1.1.3): 56 data bytes ^C --- 10.1.1.3 ping statistics --- 1 packets transmitted, 0 packets received, 100.0% packet loss
接下来,我们添加VTEP虚拟接口vxlan0, 并加入组播IP:239.1.1.1, 后续发送到该组播IP的数据包,该VTEP都可以接收到:
ip link add vxlan0 type vxlan id 1 group 239.1.1.1 dev eth1 dstport 4789
将虚拟接口vxlan0连接到网桥:
brctl addif br0 vxlan0
在另外两台主机上也完成相似配置后,我们开始测试。
首先在主机1查看VTEP的转发表,可以看到此时只有一条组播条目,所有发出流量都将发送给该组播IP:
[root@localhost vagrant]# bridge fdb show dev vxlan0 000000:00 dst 239.1.1.1 via eth1 self permanent
我们再次从主机1上访问主机2上的网桥IP, 此时访问成功:
[root@localhost vagrant]# ping 10.1.1.3 PING 10.1.1.3 (10.1.1.3) 56(84) bytes of data. 64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=1.58 ms 64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.610 ms ^C --- 10.1.1.3 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1001ms rtt min/avg/max/mdev = 0.610/1.096/1.582/0.486 ms
此时再次在主机1上查看VTEP转发表,可以看到转发表中已经学习到10.1.1.3所在主机的VTEP地址:192.168.33.13,下次再发送数据给10.1.13所对应的MAC该直接发送到192.168.33.13:
[root@localhost vagrant]# bridge fdb show dev vxlan0 000000:00 dst 239.1.1.1 via eth1 self permanent 2ea27b:31 dst 192.168.33.13 self
我们根据主机2上tcpdump的抓包结果来分析具体过程:
1454.330846 IP 192.168.33.12.38538 > 239.1.1.1.4789: VXLAN, flags [I] (0x08), vni 1 ARP, Request who-has 10.1.1.3 tell 10.1.1.2, length 28
10.1.1.2所在主机不知道10.1.1.3对应的MAC地址,因而发送ARP广播,ARP数据包发送至VTEP,VTEP进行封装并洪泛给组播IP:239.1.1.1。
1454.330975 IP 192.168.33.13.58823 > 192.168.33.12.4789: VXLAN, flags [I] (0x08), vni 1 ARP, Reply 10.1.1.3 is-at 2ea27b:31, length 28
主机2收到数据包之后解封装,VTEP会学习数据包的MAC及VTEP地址,将其添加到转发表,并将解封后的数据帧发送到网桥接口10.1.1.3。10.1.1.3的接口发送ARP响应。
1454.332055 IP 192.168.33.12.48980 > 192.168.33.13.4789: VXLAN, flags [I] (0x08), vni 1 IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 4478, seq 1, length 64
主机1之后开始发送ICMP数据包,从这里可以看出外层IP地址不再为组播IP,而是学习到的192.168.33.13。
1454.332225 IP 192.168.33.13.55921 > 192.168.33.12.4789: VXLAN, flags [I] (0x08), vni 1 IP 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 4478, seq 1, length 64
接着,10.1.1.3发送回ICMP响应包。
OvS 的实现
下面再来说明OpenvSwitch实现实例。
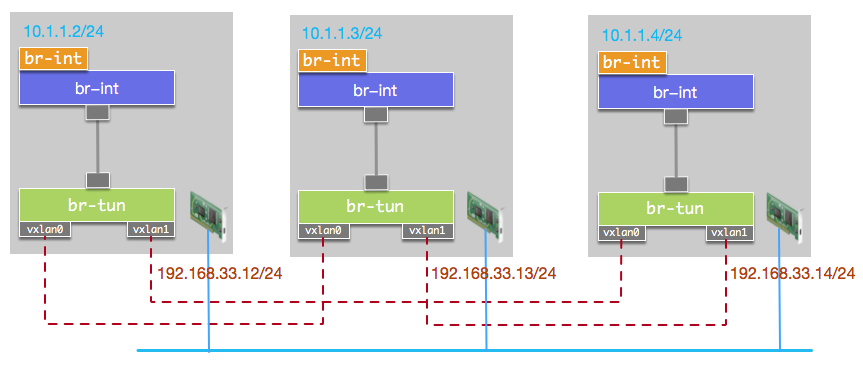
OVS不支持组播,需要为任意两个主机之间建立VXLAN单播隧道。与上边示例的拓朴结构相比,我们使用了两个OVS网桥,将虚拟逻辑网络的接口接入网桥br-int,将所有VXLAN接口接入br-tun。两个网桥使用PATCH类型接口进行连接。由于网桥br-tun上有多个VTEP,当BUM数据包从其中某个VTEP流入时,数据包会从其他VTEP接口再流出,这会导致数据包在主机之间无限循环。因而我们需要添加流表使VTEP流入的数据包不再转发至其他VTEP。若逻辑网络接口与VTEP连接同一网桥,配置流表将比较繁琐。单独将逻辑网络接口放到独立的网桥上,可以使流表配置非常简单,只需要设置VTEP流入的数据包从PATCH接口流出。
拓朴结构如图:
首先在主机1上创建网桥br-int和br-tun:
ovs-vsctl add-br br-int ovs-vsctl add-br br-tun
创建PATCH接口连接br-int和br-tun:
ovs-vsctl add-port br-int patch-int -- set interface patch-int type=patch options:peer=patch-tun ovs-vsctl add-port br-tun patch-tun -- set interface patch-tun type=patch options:peer=patch-int
创建单播VTEP连接主机2:
ovs-vsctl add-port br-tun vxlan0 -- set interface vxlan0 type=vxlan options:remote_ip=192.168.33.13
创建单播VTEP连接主机3:
ovs-vsctl add-port br-tun vxlan1 -- set interface vxlan1 type=vxlan options:remote_ip=192.168.33.14
接下来,我们给br-tun添加流表来处理流量。
首先查看br-tun上各接口的PORT ID,从结果看到Patch Port为1,VTEP分别为5和6:
[root@localhost vagrant]# ovs-ofctl show br-tun OFPT_FEATURES_REPLY (xid=0x2): dpid:00006e12f4fd6949 n_tables:254, n_buffers:256 capabilities: FLOW_STATS TABLE_STATS PORT_STATS QUEUE_STATS ARP_MATCH_IP actions: output enqueue set_vlan_vid set_vlan_pcp strip_vlan mod_dl_src mod_dl_dst mod_nw_src mod_nw_dst mod_nw_tos mod_tp_src mod_tp_dst 1(patch-tun): addrfafbbf config: 0 state: 0 speed: 0 Mbps now, 0 Mbps max 5(vxlan0): addr6585ea config: 0 state: 0 speed: 0 Mbps now, 0 Mbps max 6(vxlan1): addr38fa98 config: 0 state: 0 speed: 0 Mbps now, 0 Mbps max LOCAL(br-tun): addr12fd49 config: PORT_DOWN state: LINK_DOWN speed: 0 Mbps now, 0 Mbps max OFPT_GET_CONFIG_REPLY (xid=0x4): frags=normal miss_send_len=0
清空br-tun流表:
ovs-ofctl del-flows br-tun
数据包进入br-tun后开始匹配table 0的流。我们使用table 0区分流量来源。来源于br-int的数据包由table 1处理,VTEP流入的数据交由table 2处理, 并丢弃其他PORT进入的数据包:
ovs-ofctl add-flow br-tun "table=0,priority=1,in_port=1 actions=resubmit(,1)” ovs-ofctl add-flow br-tun "table=0,priority=1,in_port=5 actions=resubmit(,2)" ovs-ofctl add-flow br-tun "table=0,priority=1,in_port=6 actions=resubmit(,2)” ovs-ofctl add-flow br-tun "table=0,priority=0,actions=drop”
接着添加table 1的流, table 1用于处理来自br-int的流量,单播数据包交由table 20处理,多播或广播数据包交由table 21处理:
ovs-ofctl add-flow br-tun "table=1,priority=0,dl_dst=000000:00/010000:00,actions=resubmit(,20)” ovs-ofctl add-flow br-tun "table=1,priority=0,dl_dst=010000:00/010000:00,actions=resubmit(,21)”
table 21处理广播流量,将数据包从所有VTEP的PORT口发出:
ovs-ofctl add-flow br-tun "table=21,priority=0,actions=output:5,output:6”
table 2处理VTEP流入的数据包,在这里我们实现学习机制。来自VTEP的数据包到达后,table 2从中学习MAC地址,VNI、PORT信息,并将学习到的流写入table 20中,并将流量由PATCH口发送到br-int上, 并将学习到的流优先级设为1:
ovs-ofctl add-flow br-tun "table=2,priority=0,actions=learn(table=20,hard_timeout=300,priority=1,NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[],load:NXM_NX_TUN_ID[]->NXM_NX_TUN_ID[],output:NXM_OF_IN_PORT[]), output:1”
table 20处理单播流量,我们将默认流优先级设置为0。因为学习到的流优先级设置为1,因而只有匹配不到目标MAC的未知单播交由table 21处理,table 21将流量广播到所有VTEP:
ovs-ofctl add-flow br-tun "table=20,priority=0,actions=resubmit(,21)"
整体处理逻辑如图:
我们查看流表, 发现table 20中只有一条默认添加的流:
[root@localhost vagrant]# ovs-ofctl dump-flows br-tun table=20 NXST_FLOW reply (xid=0x4): cookie=0x0, duration=1.832s, table=20, n_packets=0, n_bytes=0, idle_age=1, priority=0 actions=resubmit(,21)
我们从主机1访问主机3上的虚拟网络IP,访问成功:
[root@localhost vagrant]# ping 10.1.1.4 -c 2 PING 10.1.1.4 (10.1.1.4) 56(84) bytes of data. 64 bytes from 10.1.1.4: icmp_seq=1 ttl=64 time=1.45 ms 64 bytes from 10.1.1.4: icmp_seq=2 ttl=64 time=0.538 ms --- 10.1.1.4 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1002ms rtt min/avg/max/mdev = 0.538/0.994/1.451/0.457 ms
我们再次查看流表, 发现table 20中已经多了一条学习到的流,下次再向该MAC发送数据包,数据将直接从PORT 6中发出:
[root@localhost vagrant]# ovs-ofctl dump-flows br-tun table=20 NXST_FLOW reply (xid=0x4): cookie=0x0, duration=164.902s, table=20, n_packets=36, n_bytes=3360, hard_timeout=300, idle_age=19, hard_age=19, priority=1,dl_dst=ee090e:46 actions=load:0->NXM_NX_TUN_ID[],output:6 cookie=0x0, duration=223.811s, table=20, n_packets=1, n_bytes=98, idle_age=164, priority=0 actions=resubmit(,21)
本文简要介绍了VXLAN的原理和实例。
编辑:黄飞
-
什么是VXLAN?为什么需要VXLAN?2023-12-07 2013
-
Linux中常用的MySQL运维脚本2023-09-07 1091
-
Linux中常用的压缩和解压缩命令介绍2023-07-31 2873
-
Linux中常用的6种SSH身份验证方法2023-05-12 4077
-
VXLAN是什么,VXLAN 解决了什么问题2022-03-05 2085
-
labview定时器实现实例分享2022-01-11 1422
-
嵌入式linux系统中常用的文件系统有哪些2021-11-04 1024
-
嵌入式Linux常用GUI系统2021-11-01 955
-
Linux环境下常用的四种文件系统2020-05-23 2792
-
常用的linux命令盘点2019-07-22 1362
-
数据库实战教程之PLSQL环境中常用命令的详细资料说明2019-03-07 1542
-
搭建测试环境常用linux命令_linux下web测试环境的搭建2018-01-31 12894
全部0条评论

快来发表一下你的评论吧 !
