

基于内部区域压实(IZC)的垃圾回收
描述
01 背景
目前基于闪存的固态硬盘保持着几十年前的块层接口,这在容量超额配置、页面映射表的DRAM、垃圾回收开销以及试图减轻垃圾回收的主机软件复杂性等方面带来了巨大的代价。块层接口向其上层展现出来的是一个一维的LBA数组,每个LBA都可以被读写,其最初的引用是为了隐藏存储介质的不同。然而随着存储介质的迭代,为flash based存储设备维护块层接口语义代价越来越大,如flash based SSDs中FTL的运转需要大量DRAM,GC需要OP空间,并且设备请求命令延迟被GC干扰后有抖动。NVMe区域命名空间(ZNS)的设定为SSD提供了一种全新的接口模式,ZNS作为一种新的存储接口正在出现,逻辑地址空间被划分为固定大小的区域,每个区域必须按顺序写入,以便于闪存访问。
02 问题
1. ZNS的IO栈
一般来说,新的存储接口需要修改软件栈。对于ZNS,需要修改两个主要的IO栈组件,文件系统和IO调度器。首先,原地更新的文件系统,如EXT4,必须被附加记录的文件系统所取代,如日志结构文件系统(LFS),以消除随机更新。因为LFS的一个区段是通过追加记录按顺序写入的,每个区段可以被映射到一个或多个区域。其次,IO调度器必须保证一个区的写请求的有序交付。例如,可以为每个区使用一个无序的队列,调度器只需要确定不同区之间的服务顺序。ZNS的顺序写要求使得ZNS只能适用于特定需求的应用访问。
2. 增加主机开销
在LFS的append logging方案下,脏段的过时块必须通过段压缩(也称为段清理或垃圾收集)来回收,它将段中的所有有效数据转移到其他段,使段变得干净。压实会调用大量的复制操作,特别是当文件系统的利用率很高时。必须进行主机端GC,以换取使用无GC的ZNS SSD,尽管可以避免log-on-log下的重复GC。主机端GC的开销比设备端GC的开销要高,因为主机级块复制需要处理IO请求,主机到设备的数据传输,以及读取数据的页面分配。此外,段压缩需要修改文件系统元数据以反映数据的重新定位。此外,段压缩的数据复制操作是批量进行的,因此,许多待写请求的平均等待时间是相当长的。根据F2FS--广泛使用的日志结构文件系统之一的实验,当文件系统利用率为90%时,分段压缩的性能损失约为20%。因此,可以说目前的ZNS只关注SSD方面的好处,而没有考虑到主机的复杂性增加。为了简化SSD的设计,所有复杂的东西都被传递给主机。
此外,当我们通过嵌入更多的闪存芯片来增加SSD的带宽时,ZNS存储系统将涉及收益递减。ZNS设备的区域大小将被确定为足够大,以利用SSD内部闪存芯片的并行性。因此,更高带宽的ZNS SSD将提供更大的区域大小,而文件系统必须相应地使用更大的段大小。然后,主机遭受到更严重的段压缩开销,因为开销通常与段大小成比例增加。为了提高IO性能,克服收益递减的问题,需要进行主机-设备联合设计,将段压缩的每个子任务放在最合适的位置,而不损害原始ZNS的利益,而不是简单地将GC开销从SSD转移到主机。
03 方法
为了降低主机端做垃圾回收所带来的开销,本文提出三种方法通过协同垃圾回收优化来降低开销。
1. 基于内部区域压实(IZC)的垃圾回收
传统的段压实过程如图1(a)所示,待回收区域中所有的有效数据都需要读取到主机端,再写到目标区域中。这个过程需要大量的读写以及元数据更新操作,会占用主机端的资源带来性能的下降。相比于传统的段压实,基于IZC的垃圾回收通过将未修改的有效数据的复制交付给SSD,并且利用SSD的copyback操作进行内部的数据复制,从而降低主机端的资源占用,优化系统性能。图1(b)是IZC方案下的压实过程,过程如下:普通段压实的数据拷贝任务被拷贝卸载(3)所取代,它发送zone_compaction命令来传输块拷贝信息(即源和目标LBA)。因为目标数据没有被加载到主机页面缓存中,所以不需要相应的页面缓存分配。固态硬盘内部控制器可以有效地安排几个读和写操作,同时最大限度地提高闪存芯片的利用率。因此,段压实的延迟可以大大减少。此外,存储内的块复制可以利用copyback操作。更为具体的执行流程建议阅读原文相关部分。
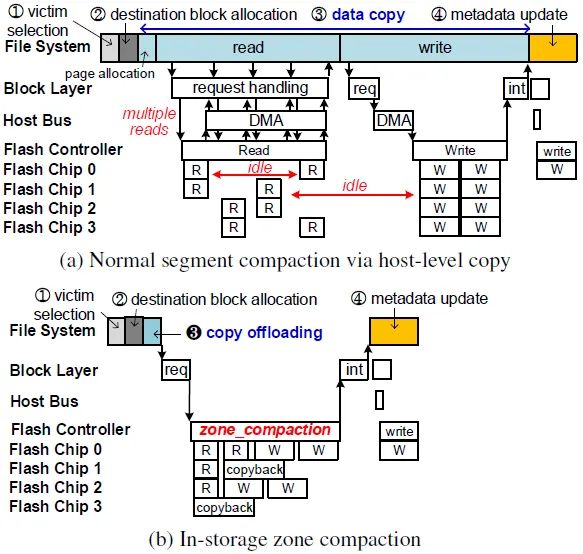
图1 段压实过程对比图
2. 稀疏的顺序重写,对F2FS的Threaded Logging提供支持
为了消除传统段压实的开销,F2FS提出的Threaded Logging机制为段压实提供了全新的思路。由于ZNS SSD不支持随机写的功能,所以F2FS都是关闭Threaded Logging机制。本文提出了影子映射的方式,使得ZNS SSD对Threaded Logging提供支持,从而优化段压实的开销。通过TL_open命令打开的zone会分配一个影子zone,并通过映射表来记录对应关系,同时维护一个bitmap记录有效信息。例如,在图2中,SSD为zone 1(1)分配了一个LogFBG,FBG 15。对于TL_opened区,该区的数据块被分配到两个FBG中,即原始FBG(FBG6)和LogFBG(FBG 15)。因此,这两个FBG必须作为该区的映射FBG来维护。为了处理一个读取请求,SSD通过比较目标LBA和WP来识别最新数据的块位置。如果目标LBA在WP后面(目标LBA < WP),则访问LogFBG。否则,原始FBG将被访问,以满足读取请求。当TL_opened区最终被关闭时,LogFBG取代了原来的FBG,它被重新分配以备将来使用。
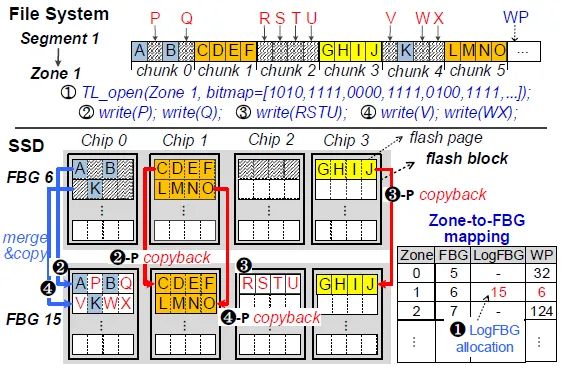
图2 Threaded Logging支持示意图
考虑插入顺序,有两种模式:
以LBA为顺序插入:如图2,当SSD收到对第0块的两个写请求时,它从FBG 6读取A和B的跳过的块,将它们与主机发送的P和Q的块合并,并在LogFBG处写下一个完整的块。在处理完对第0块的写请求后,SSD可以通过检查该区的有效位图来感知第1块将被跳过。为了让WP提前准备好对第2块的写请求,被跳过的那块必须被复制到LogFBG中。因此,在处理一个写请求后,如果以下逻辑块在有效位图中被标记为有效,ZNS+ SSD在调整WP的同时将它们复制到LogFBG。这种类型的插入被称为LBA有序插入(LP),每次插入都是在区的当前WP进行,以遵循LBA有序的写入约束。
以PPA为顺序插入:在图2的例子中,在0号和2号的写入请求到达之前,3号可以被复制,因为它们使用不同的闪存芯片。如果第1块已经被复制,即使第2块和第4块的写请求还没有到达,第5块也可以被复制。我们称这种技术为PPA有序插入(PP),它只考虑PPA有序的写约束。每当一个闪存页在LogFBG被编程时,PPA-ordered plugging就会检查对应的闪存块中映射到下面闪存页的块的有效性,并提前发出该闪存块的所有可能的插入操作。然而,如果发出过多的插入操作,可能会干扰用户的IO请求处理。为了解决这个问题,当目标闪存芯片处于空闲状态时,插入操作将在后台进行处理。如果没有足够的空闲时间,当该区的WP必须通过跳过的区块位置时,它们就会被处理。
3. 混合段回收策略
通过上述的两个策略,目前有两种垃圾回收的方式。为了权衡在垃圾回收时选取哪种方式,本文提出了两种垃圾回收策略的cost-benefit计算公式,在垃圾回收时总是选取开销最小的垃圾回收方式。Npre-inv和Nvalid分别表示pre-invalid块的数量和有效块的数量。fplugging(N)是N个区块的存储内插入成本。Nnode和Nmeta分别表示修改后的节点块和元数据块的数量。 fcopy(N)和fwrite(N)分别是N块的复制成本和写入成本。Bcold表示预测的未来冷块迁移的收益。公式中部分值很难计算或者无法计算,本文对这些值采取近似估计。
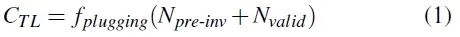
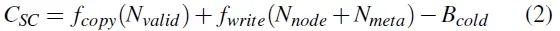
图3 cost-benefit权衡公式
04 实验结果
评估实验是基于FEMU的SSD仿真器评估了ZNS+ SSD的性能。相关延迟配置如下:
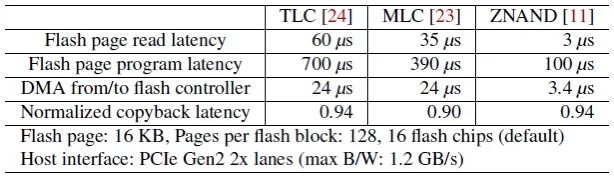
表1 实验平台设置
实验性能对比包含三个方面,分别为段压实、Threaded Logging和SSD内部芯片利用率。
段压实性能:该实验主要基于IZC的垃圾回收策略效果进行评估。通过将copy操作卸载到SSD内部,并且利用copyback操作,优化垃圾回收过程,降低垃圾回收开销。实验结果验证了IZC策略可以很好的降低垃圾回收开销。
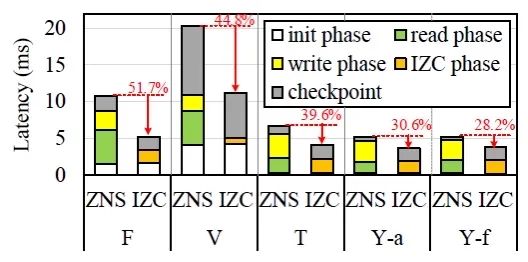
图4 段压实实验结果
Threaded Logging性能:该实验主要对支持Threaded Logging后垃圾回收的性能评估。ZNS+在所有基准上都优于ZNS和IZC。ZNS+的吞吐量比ZNS高约1.33-2.91倍。与IZC相比,ZNS+将varmail工作负载的节点和元数据写入流量减少了约48%。在所有的工作负载中,超过85.8%的回收段是由ZNS+的线程记录处理的,因为定期检查点方案限制了预无效块的数量。
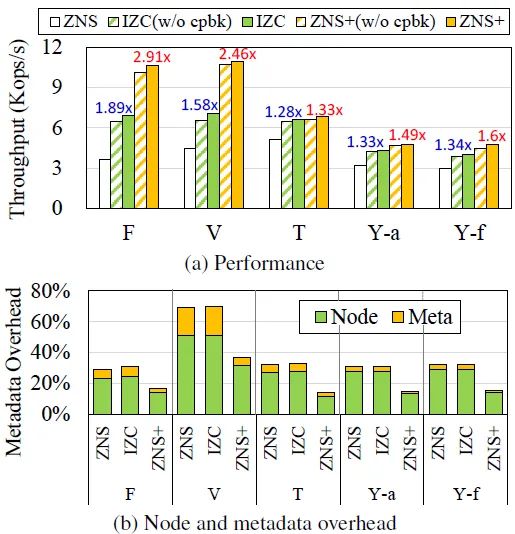
图5 支持Threaded Logging实验结果
SSD内部芯片利用率:该实验主要对SSD内部芯片利用率进行评估。在所有的工作负载中,IZC和ZNS+的芯片利用率都比ZNS高。ZNS+(LP)可以利用两个连续的写请求之间的空闲时间,而ZNS+(PP)可以通过利用空闲的闪存芯片,将插入操作与正常的写请求处理重叠起来。因此,与ZNS+(PP)相比,ZNS+(LP)显示出更高的芯片利用率。
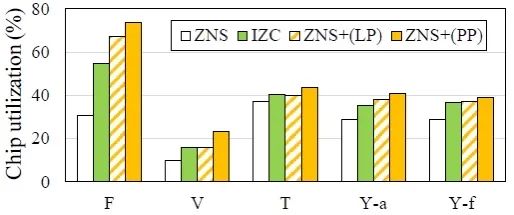
图6 ZNS SSD vs Stream SSD性能对比实验结果
05 总结
目前的ZNS接口在主机上施加了很高的存储回收开销,以简化SSD。为了优化整体的IO性能,必须将每个存储管理任务放在最合适的位置,并使主机和SSD合作。为了将块复制操作卸载到SSD上,本文设计了ZNS+,它支持存储区内的压实和Threaded Logging。与传统的段压实相比,在性能和SSD内部芯片利用率有很大的改进。
-
智能垃圾回收箱功能实验2024-05-24 1769
-
智能垃圾回收箱及其控制系统2024-04-13 3161
-
使用图像识别来识别可回收和不可回收的垃圾2023-06-20 875
-
JVM入门之垃圾回收算法2023-02-10 1671
-
Kubernetes容器垃圾回收的策略2022-08-15 2491
-
详解JVM的垃圾回收算法和垃圾回收器2022-03-29 2377
-
生活垃圾数据化分类回收方法及其回收系统(机械部分)2021-11-05 914
-
智能垃圾回收机器人的应用优势有哪些2021-08-17 5022
-
智能垃圾回收机器人的应用优势是什么2021-07-22 2788
-
交大发布可回收物垃圾分拣机器人,实现助力全国垃圾分类回收工作2020-06-04 3962
-
Jvm垃圾回收机制及性能调优实战2018-04-03 930
-
电子垃圾回收产业的隐秘世界2018-01-22 11988
-
基于逻辑区间热度的垃圾回收算法2017-12-05 839
-
固态硬盘垃圾回收方法2017-12-03 1971
全部0条评论

快来发表一下你的评论吧 !
