

一种免反向传播的 TTA 语义分割方法
电子说
描述
我们已经介绍过两篇关于 TTA 的工作,可以在 GiantPandaCV 公众号中找到,分别是:
Continual Test-Time 的领域适应
CVPR 2023 中的领域适应: 通过自蒸馏正则化实现内存高效的 CoTTA
推荐对领域适应不了解的同学先阅读前置文章。目前的 TTA 方法针对反向传播的方式可以大致划分为:
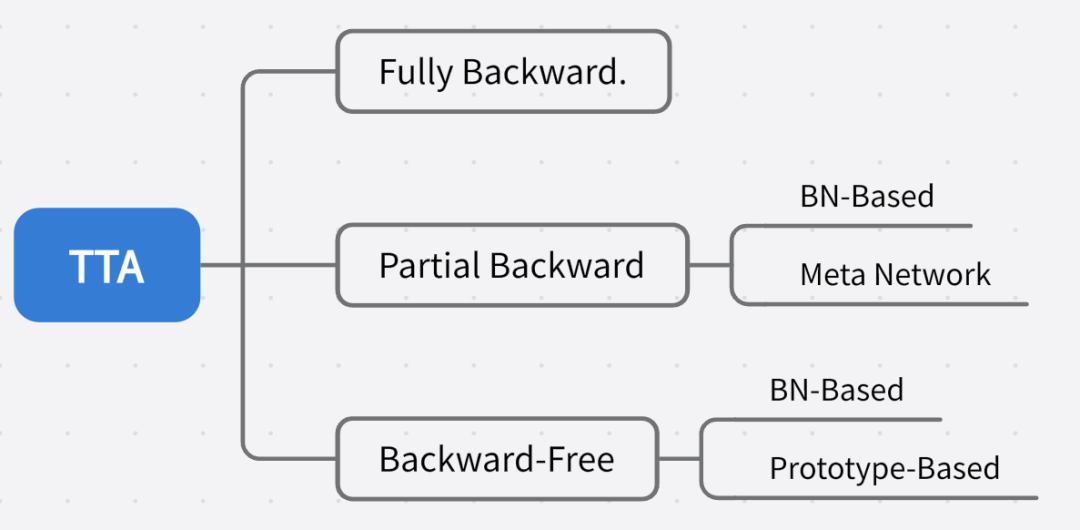 请添加图片描述
请添加图片描述
之前介绍过的 CoTTA 可以属于 Fully Backward,EcoTTA 划分为 Partial Backward 中的 Meta Network 类别,这次要介绍的方法属于 Backward-Free 中的 BN-Based 和 Prototype-Based 的混合。下图是一些 TTA 语义分割方式的比较,在(a)中是最朴素的重新做反向传播优化目标域模型梯度的方法,效率低,存在误差积累,且会导致长期遗忘。(b)是直接用每个实例的统计数据替代源统计数据(通过修改 Instance Normalization),但由于丢弃了基本的源知识,因此对目标变化非常敏感,导致不稳定。(c)研究了通过实例统计数据以固定动量或动态波动动量更新历史统计数据的影响(相当于(b)的集群),然而,这种方法也容易受到误差积累的影响。(d)表示这篇工作提出的方法,主要思想是以非参数化的方式利用每个实例来动态地进行自适应,这种方法既高效又能在很大程度上避免误差积累问题。具体来说,计算 BN 层中源统计数据和当前统计数据的加权和,以适应目标分布,从而使模型获得更健壮的表示,还通过将历史原型与实例级原型混合构建动态非参数分类头。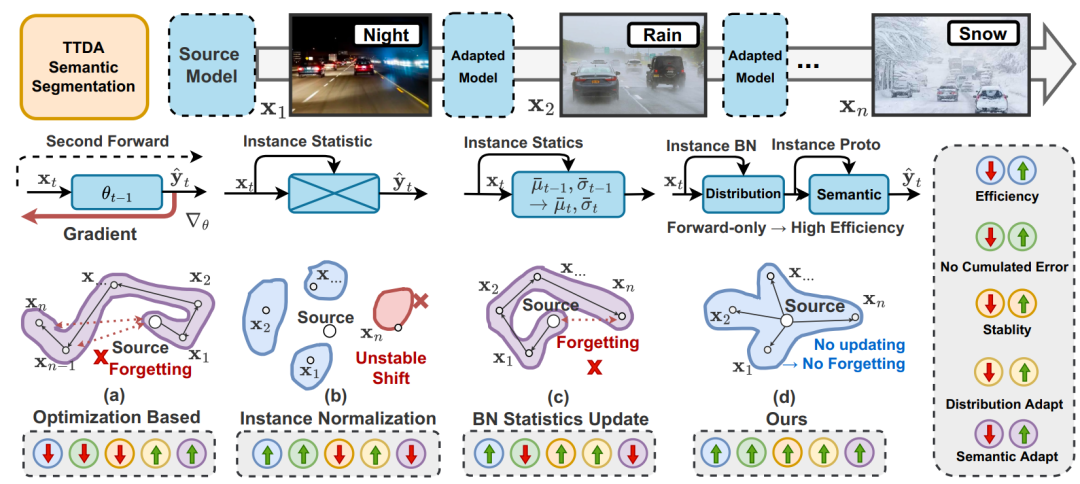
下面看下具体实现。
DIGA 概述
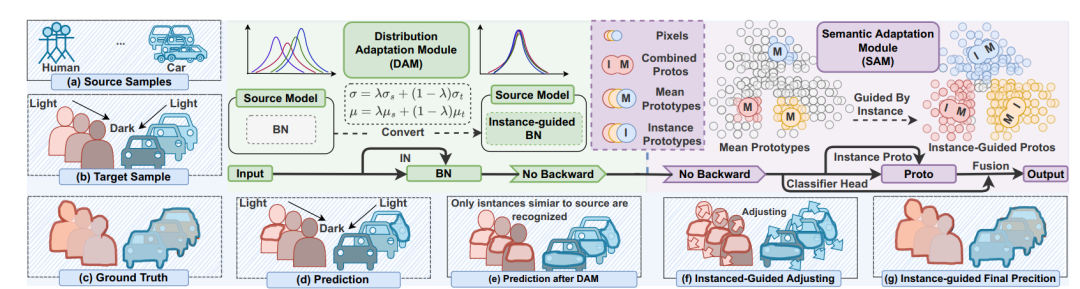
TTA 在语义分割中的应用,效率和性能都至关重要。现有方法要么效率低(例如,需要反向传播的优化),要么忽略语义适应(例如,分布对齐)。此外,还会受到不稳定优化和异常分布引起的误差积累的困扰。为了解决这些问题,这篇工作提出了不需反向传播优化的 TTA 语义分割方法,被叫做称为动态实例引导自适应(DynamicallyInstance-Guided Adaptation, DIGA)。DIGA 的原则是以非参数化的方式利用每个实例动态引导其自身的适应,从而避免了误差累积问题和昂贵的优化成本(内存)。具体而言,DIGA 由分布适应模块(DAM)和语义适应模块(SAM)组成。DAM 将实例和源 BN 层统计信息混合在一起,以鼓励模型捕获不变的表示。SAM 将历史原型与实例级原型结合起来调整语义预测,这可以与参数化分类头相关联。具体细节在后文介绍。
DAM 和 SAM 两者都由实例感知信息引导。如下图所示,给定一个测试样本,首先将其输入到源预训练模型中,并通过 DAM 在每个 BN 层进行分布对齐。分布对齐是通过加权求和源统计和实例统计来实现的。之后,通过 SAM 在最后的特征层级上进行语义适应,通过加权混合历史原型和实例感知原型来构建一个动态非参数化分类头。这使我们能够调整语义预测。最后,我们利用原始参数化分类头和动态非参数化分类头之间的相互优势获得最终的预测结果。
 请添加图片描述
请添加图片描述
Distribution Adaptation Module (DAM)
调整分布可以提高跨域测试性能,由于训练数据有限和反向传播成本高,最常见的方法是对抗训练和分布差距最小化,但是不适合 TTA 任务。通常 BN 层中各域之间的静态不匹配是跨域测试性能下降的主要原因。BN 层是使用可训练参数 gamma 和 beta 进行缩放和移动。对于每个 BN 层,给定输入特征表示 F,相应的输出由以下公式给出:
E[F] 和 Var[F] 分别代表输入特征 F 的期望值和方差。在实践中,由于批次训练过程,它们的值通过 running mean 在训练期间计算:
所以,有一种方法源域的 running mean 的最后一个值被冻结,用作测试阶段测试数据的预期值和方差的估计。但是,源统计信息仍会严重影响性能。还有一种方法提出了一种动态学习模块,将 BN 层的统计信息 γ、β 调整为目标域(更新 γ、β)。尽管该方法具有高效性,但其性能仍然不理想。可能的原因之一是模型更新速率通常较小,并且在每个实例评估过程中没有充分考虑实例级别的信息。
所以 DAM 考虑到了利用实例级别的信息。DAM 不是直接更新 γ、β,而是通过动态地合并(加权求和)源统计信息和实例级别的 BN 统计信息来计算 E[F] 和 Var[F] 的估计值。
其中, 和 是在测试期间使用第 t 个实例计算的均值和方差。
Semantic Adaptation Module (SAM)
DAM 是与类别无关的,如上所述,因为它仅在全局上对特征图的分布进行调整。然而,对于分割自适应任务来说,类别特定性也很重要,因为即使在同一张图像中,每个类别的分布也会有很大变化。为了解决这一点,之前的工作提出了两种直观的方法,熵最大化和伪标签。然而,它们都需要基于梯度的反向传播,因此限制了测试效率,和我们的思路背道而驰。受少样本学习和域自适应中基于原型的方法(Prototype-Based)的启发,引入了用于类别特定自适应的 SAM。具体做法,总结有如下几步,我们用通俗的话解释下,至于论文中的公式,也会贴上。
计算 Instance-aware prototypes:
根据输入图像中每个类别的像素,计算其在特征空间中的中心点(prototypes),称为实例感知原型。这些原型表示了每个类别的特征分布。
通过对不同实例的原型进行平均计算,得到历史原型。历史原型是在大量目标实例上计算得到的,具有较高的稳定性。
Ensemble historical prototypes:
将历史原型与实例感知原型进行集成,以进一步提高分类的准确性和稳定性。
Cal prototype-based classification result:
使用计算得到的实例感知原型和历史原型,通过比较输入像素与原型之间的相似度,进行分类预测。这种基于原型的分类方法可以更好地适应不同类别的变化。
Classifier Association
SAM 本质上是 prototype-based classification。在最后的部分,可以得到两种类型的预测:一种来自原始的参数化分类器(pˆ),另一种来自引入的非参数原型分类器(p ̃)。为了利用它们之间的互补性,DIGA 还是通过加权求和来获得最终的预测结果,表示为:
实验
在实验的部分,我们更关心的是这些组合的有效性。下表是对 DAM 和 SAM 的消融实验,最后一行表示分类器关联。对于 BN 分支和语义分支,都分别比较出最佳和次佳。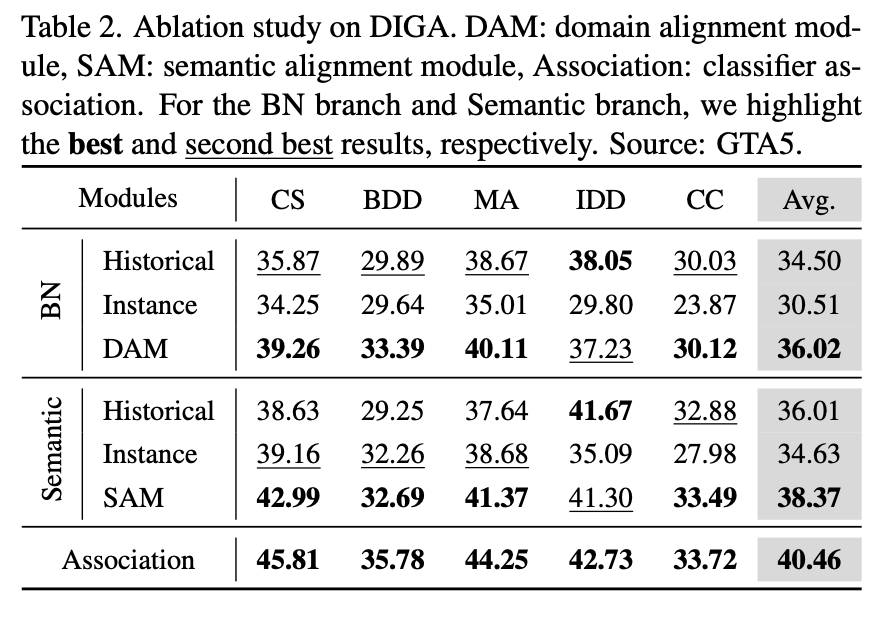 和直接使用源域模型、其他的 SOTA TTA 方法的可视化比较如下,可以发现在 cityscapes 上的优化效果是最明显的。
和直接使用源域模型、其他的 SOTA TTA 方法的可视化比较如下,可以发现在 cityscapes 上的优化效果是最明显的。
 在这里插入图片描述
在这里插入图片描述
总结
这篇工作提出了一种名为动态实例引导适应(DIGA)的方法来解决 TTA 语义分割问题,该方法兼备高效性和有效性。DIGA 包括两个适应性模块,即分布适应模块(DAM)和语义适应模块(SAM),两者均以非参数方式受实例感知信息引导。此外,这是第三篇关于 TTA 的论文解读了,后面出现有趣的工作还会继续这个系列的。
-
一种新的粘连字符图像分割方法2009-09-19 4154
-
一种带验证的自适应镜头分割算法2009-12-16 871
-
一种目标飞机分割提取方法2017-11-10 1022
-
一种自动生成反向传播方程的方法2018-08-14 4568
-
MIT提出语义分割技术,电影特效自动化生成2018-08-23 4711
-
Facebook AI使用单一神经网络架构来同时完成实例分割和语义分割2019-04-22 3774
-
语义分割方法发展过程2020-12-28 6030
-
分析总结基于深度神经网络的图像语义分割方法2021-03-19 1483
-
基于深度神经网络的图像语义分割方法2021-04-02 1652
-
图像语义分割的概念与原理以及常用的方法2023-04-20 7325
-
CVPR 2023 中的领域适应: 一种免反向传播的TTA语义分割方法2023-06-30 1864
-
一种在线激光雷达语义分割框架MemorySeg2023-11-21 1540
-
图像分割与语义分割中的CNN模型综述2024-07-09 3482
-
图像语义分割的实用性是什么2024-07-17 1727
-
什么是BP神经网络的反向传播算法2025-02-12 2134
全部0条评论

快来发表一下你的评论吧 !
