

百问网V853开发板端侧部署YOLOV5全流程教程
描述
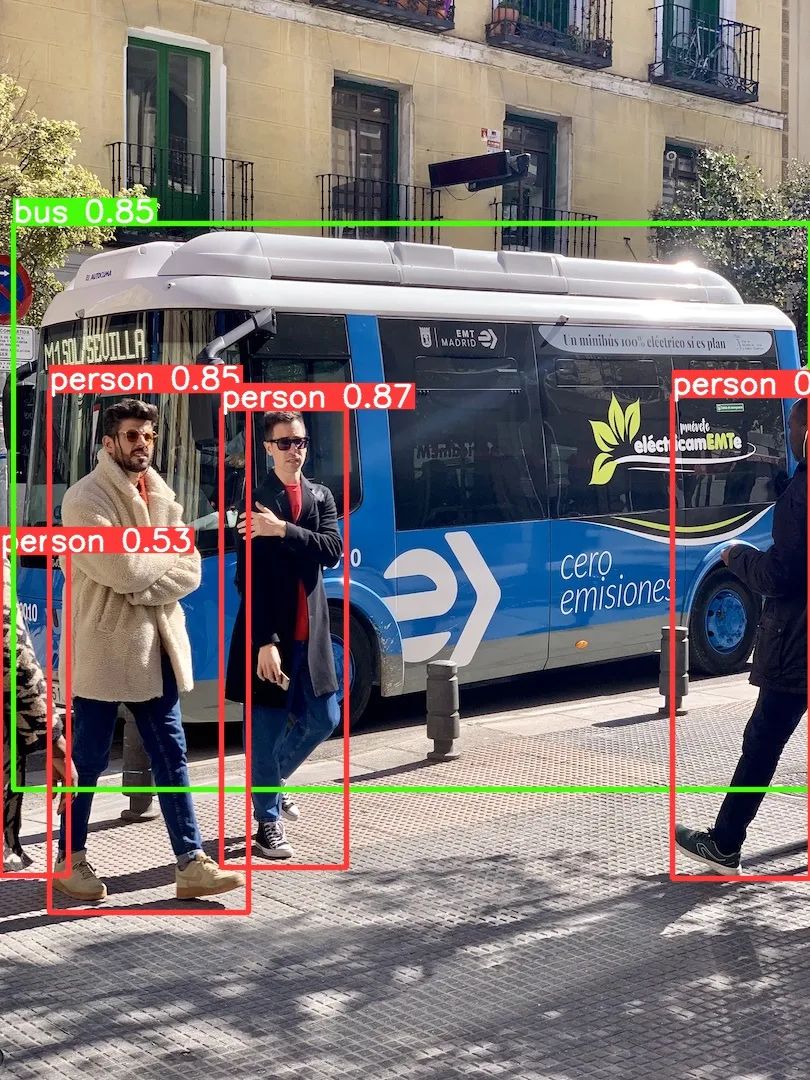
下面展示100ASK_V853-PRO开发板部署YOLOV5模型的效果图:



百问网100ASK_V853-PRO开发板购买,请使用淘宝扫一扫下面二维码:

下面展示100ASK-V853-PRO开发板端侧部署YOLOV5模型的全流程教程
1.配置yolov5环境
yolov5搭建环境指南:https://forums.100ask.net/t/topic/3670
yolov5官方网址为:https://github.com/ultralytics/yolov5
使用Git工具在任意目录下获取源码V6.0版本,输入
git clone -b v6.0 https://github.com/ultralytics/yolov5
如果您使用Git下载出现问题,也可以直接点击下面网址直接下载源码压缩包,下载完成解压即可正常使用。
https://github.com/ultralytics/yolov5/archive/refs/tags/v6.0.zip
等待下载完成,下载完成后会在当前目录下,查看到yolov5项目文件夹
100askTeam@DESKTOP-F46NFJT MINGW64 /d/Programmers/ModelDeployment/2.yolov5 $ ls yolov5/ 100askTeam@DESKTOP-F46NFJT MINGW64 /d/Programmers/ModelDeployment/2.yolov5 $ cd yolov5/ 100askTeam@DESKTOP-F46NFJT MINGW64 /d/Programmers/ModelDeployment/2.yolov5/yolov5 (master) $ ls CITATION.cff README.zh-CN.md detect.py requirements.txt tutorial.ipynb CONTRIBUTING.md benchmarks.py export.py segment/ utils/ LICENSE classify/ hubconf.py setup.cfg val.py README.md data/ models/ train.py
打开Anaconda Prompt (Anaconda3)软件,进入yolov5项目目录中,输入以下命令
(base) C:Users100askTeam>D: (base) D:>cd D:ProgrammersModelDeployment2.yolov5yolov5 (base) D:ProgrammersModelDeployment2.yolov5yolov5>
使用conda创建yolov项目环境,输入
conda create -n my-yolov5-env python=3.7
激活yolov5环境
conda activate my-yolov5-env
安装依赖
pip install -U -r requirements.txt -i https://pypi.doubanio.com/simple/
FAQ:
搭建环境时由于版本的不同会遇各种问题,下面我会提供我配置好的环境所需的包文件版本,文件位于压缩包的requirements文件夹中的conda-yolov5_6-env.yaml。在Conda终端中创建新环境,执行
conda env create -f conda-yolov5_6-env.yaml

执行python detect.py,测试环境是否搭建成功,执行后会自动下载模型权重文件
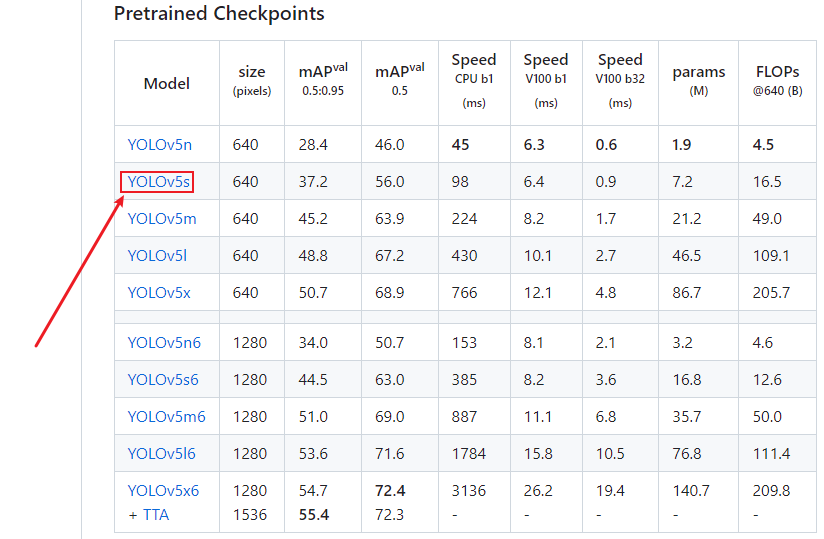
这里下载速度可能会很慢,建议直接访问官网下载https://github.com/ultralytics/yolov5/tree/v6.0,点击下图红框处的YOLOV5s。这里我下载 v6.0 版本的 yolov5s.onnx 模型作为示例。
下载地址:https://github.com/ultralytics/yolov5/releases/download/v6.0/yolov5s.pt
点进入后会进去yolov5资源中心,往下找到V6.0版本的资源下载界面,找到您所需的资源即可。

将该模型文件放在yolov5项目文件夹下,如下图所示:
在conda终端中输入python detect.py,可得到如下执行结果
(my-yolov5-env) D:ProgrammersModelDeployment2.yolov5yolov5-6.0>python detect.py detect: weights=yolov5s.pt, source=dataimages, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runsdetect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False YOLOv5 2021-10-12 torch 2.0.1+cpu CPU Fusing layers... D:Anaconda3envsmy-yolov5-envlibsite-packages orchfunctional.py UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at C:actions-runner\_workpytorchpytorchuilderwindowspytorchatensrcATen ativeTensorShape.cpp:3484.) return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined] Model Summary: 213 layers, 7225885 parameters, 0 gradients image 1/2 D:ProgrammersModelDeployment2.yolov5yolov5-6.0dataimagesus.jpg: 640x480 4 persons, 1 bus, Done. (0.274s) image 2/2 D:ProgrammersModelDeployment2.yolov5yolov5-6.0dataimageszidane.jpg: 384x640 2 persons, 1 tie, Done. (0.189s) Speed: 4.5ms pre-process, 231.3ms inference, 2.8ms NMS per image at shape (1, 3, 640, 640) Results saved to runsdetectexp1
FAQ:
如果您执行此命令时,遇到如下报错:
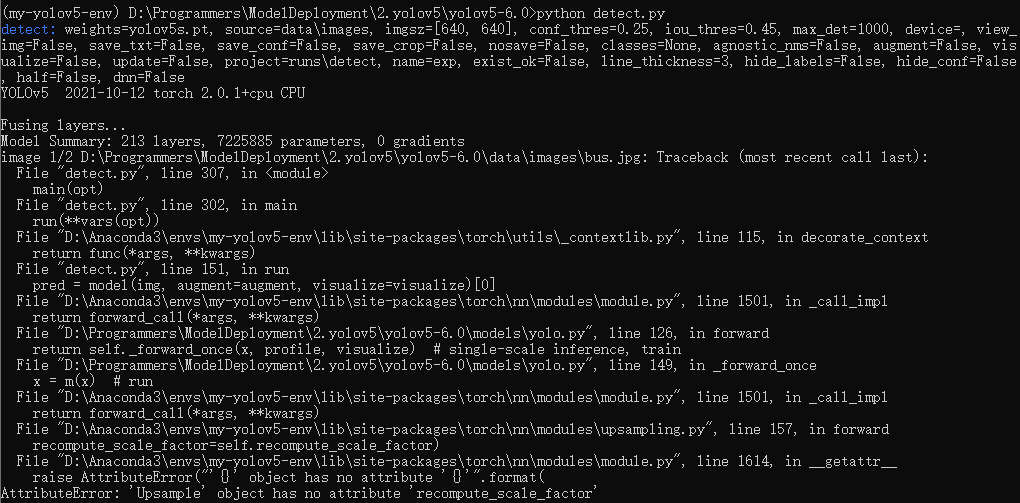
原因:torch版本过高,可以通过修改代码或者降低版本。
下面我使用修改代码的方式解决:
修改
D:Anaconda3envsmy-yolov5-envlibsite-packages orch nmodulesupsampling.p
文件中的Upsample类中forward函数的返回值。
原本:
def forward(self, input: Tensor) -> Tensor:
return F.interpolate(input, self.size, self.scale_factor, self.mode, self.align_corners,
recompute_scale_factor=self.recompute_scale_factor)
修改后:
def forward(self, input: Tensor) -> Tensor:
return F.interpolate(input, self.size, self.scale_factor, self.mode, self.align_corners)
修改结果如下图所示:

执行python detect.py完成后,可以在yolov5项目文件夹下的runsdetectexp1目录下找到执行后的输出结果,如下所示。
2.导出yolov5 ONNX模型
2.1 export程序导出模型
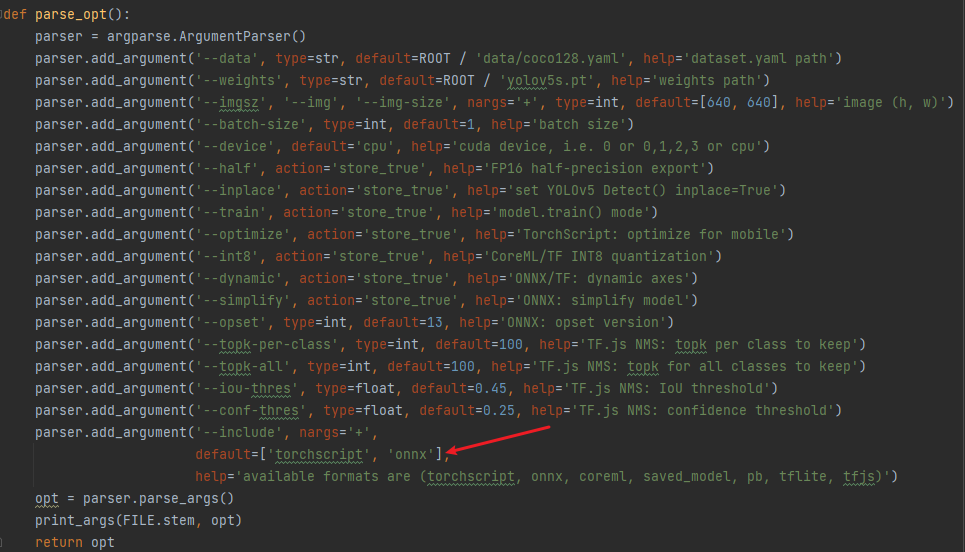
在export.py程序找到parse_opt函数,查看默认输出的模型格式。如果默认支持有onnx格式,就无需修改,如果默认没有填写onnx,修改默认格式为onnx格式。
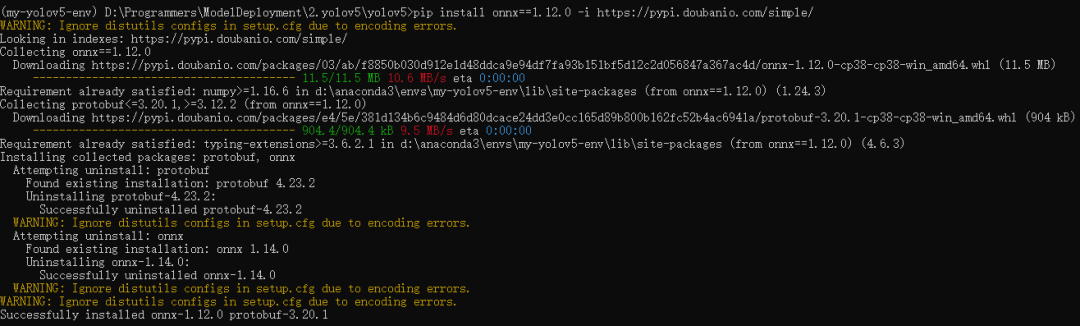
执行export.py函数前需要需要确保已经安装了onnx包,可手动安装,如下所示
pip install onnx==1.12.0 -i https://pypi.doubanio.com/simple/
执行export.py函数导出yolov5的onnx格式动态模型,在conda终端输入
python export.py --weights yolov5s.pt --include onnx --dynamic
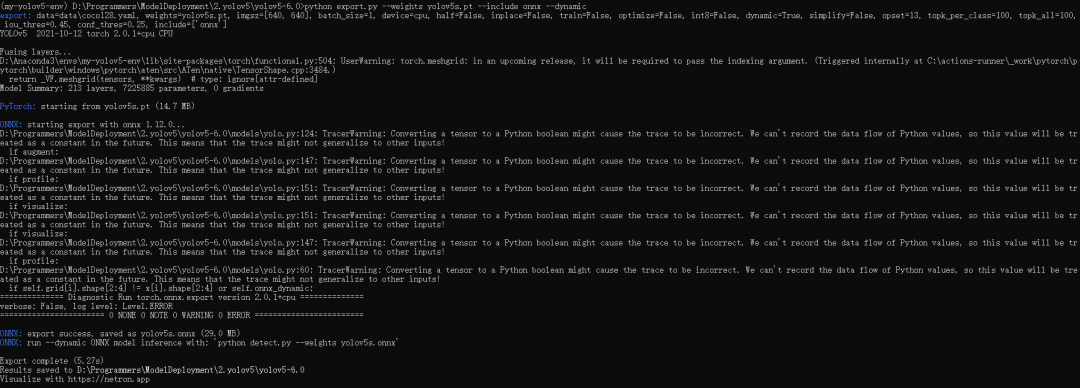
执行完成后会在yolov5项目目录中生成一个名称为yolov5s.onnx的文件,如下图所示:
2.2 简化模型
由于转换的模型是动态 Shape 的,不限制输入图片的大小,对于 NPU 来说会增加处理工序,所以这里我们需要转换为静态 Shape 的模型。
需要安装 onnxsim 工具,在conda终端输入
pip install onnxsim -i https://pypi.doubanio.com/simple/
然后使用这条命令转换:
python -m onnxsim yolov5s.onnx yolov5s-sim.onnx --input-shape 1,3,640,640

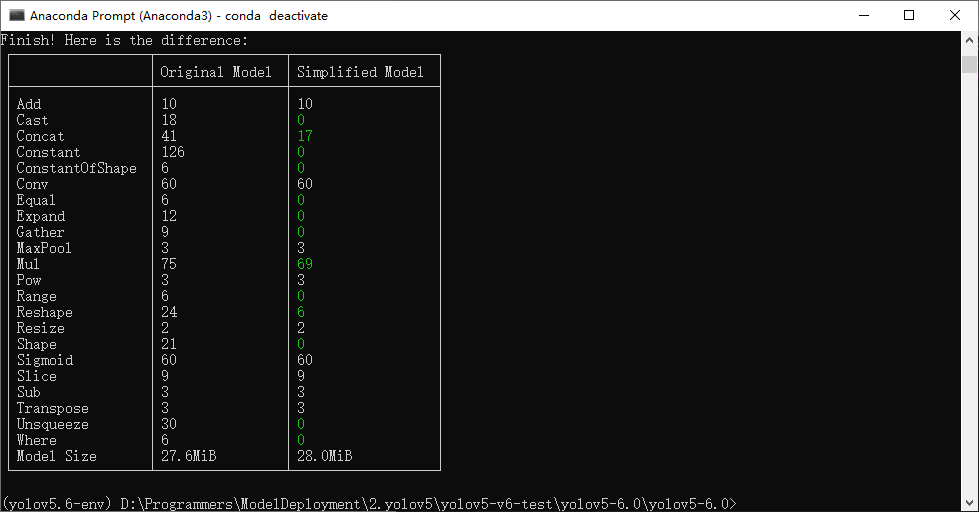
执行完成后会导出名为yolov5s-sim.onnx文件,文件位于yolov5项目文件夹下,如下图所示:
2.3 查看模型
使用开源网站Netron网站
https://netron.app/
访问上面网址查看模型结构。

选择yolov5s-sim.onnx文件,点击打开。
查看如下图所示输出节点
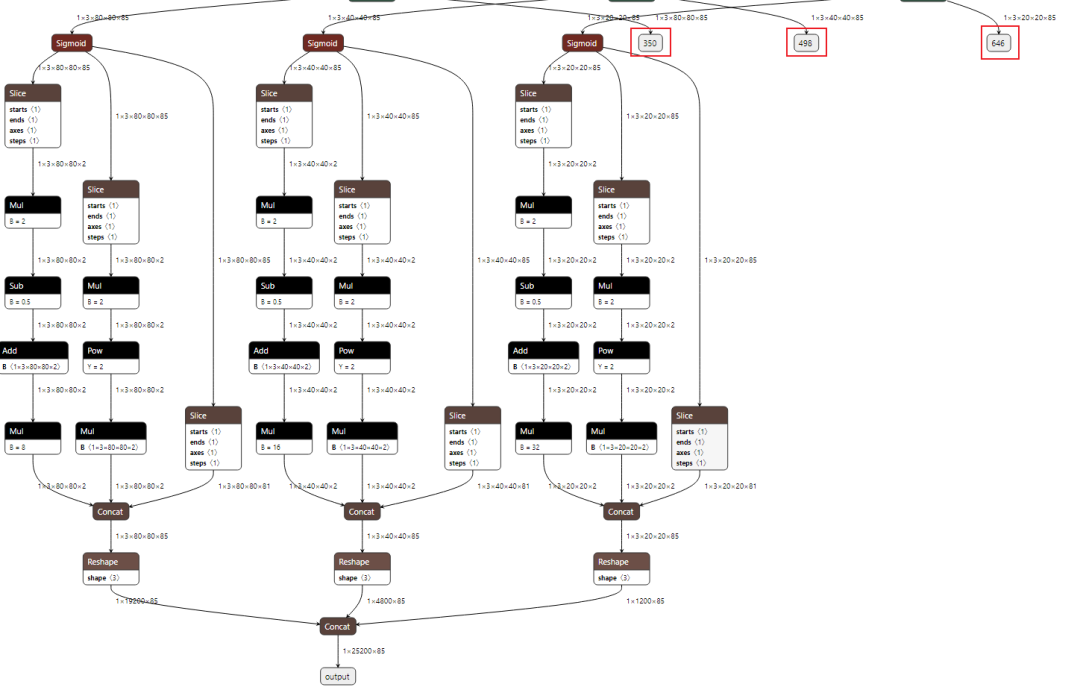
可看到模型有 4 个输出节点,其中 ouput 节点为后处理解析后的节点;在实际测试的过程中,发现 NPU 量化操作后对后处理的运算非常不友好,输出数据偏差较大,所以我们可以将后处理部分放在 CPU 运行;因此保留 350,498,646 三个后处理解析前的输出节点即可,后文在导入模型时修改输出节点。
3.转换NPU模型
3.1 创建转换目录
打开NPU工具包的虚拟机Ubuntu20.04,创建yolov5-6.0文件夹,存放模型和量化图像等。
ubuntu@ubuntu2004:~$ mkdir yolov5-6.0
进入yolov5模型转换目录。
ubuntu@ubuntu2004:~$ cd yolov5-6.0/
创建data目录存放量化图像
mkdir data
将量化图像传入data文件夹下,例如,传入test01.jpg图像到data
ubuntu@ubuntu2004:~/yolov5-test$ ls data test01.jpg
在yolov5模型转换目录中创建dataset.txt
ubuntu@ubuntu2004:~/yolov5-6.0$ touch dataset.txt
修改dataset.txt文件
ubuntu@ubuntu2004:~/yolov5-6.0$ vi dataset.txt
在dataset.txt文件中增加量化图片的路径.
./data/test01.jpg
将yolov5s-sim.onnx模型传入yolov5模型转换文件夹下。例如:
ubuntu@ubuntu2004:~/yolov5-6.0$ ls data dataset.txt yolov5s-sim.onnx
工作目录的文件如下所示:
ubuntu@ubuntu2004:~/yolov5-6.0$ tree . ├── data │ └── test01.jpg ├── dataset.txt └── yolov5s-sim.onnx 1 directory, 3 files
3.2 导入模型
导入模型前需要知道我们要保留的输出节点,由之前查看到我们输出的三个后处理节点为:350,498,646 。
pegasus import onnx --model yolov5s-sim.onnx --output-data yolov5s-sim.data --output-model yolov5s-sim.json --outputs 350 498 646
导入生成两个文件,分别是是 yolov5s-sim.data 和 yolov5s-sim.json 文件,两个文件是 YOLO V5 网络对应的芯原内部格式表示文件,data 文件储存权重,cfg 文件储存模型。
3.3生成 YML 文件
YML 文件对网络的输入和输出的超参数进行描述以及配置,这些参数包括,输入输出 tensor 的形状,归一化系数 (均值,零点),图像格式,tensor 的输出格式,后处理方式等等
pegasus generate inputmeta --model yolov5s-sim.json --input-meta-output yolov5s-sim_inputmeta.yml
pegasus generate postprocess-file --model yolov5s-sim.json --postprocess-file-output yolov5s-sim_postprocess_file.yml
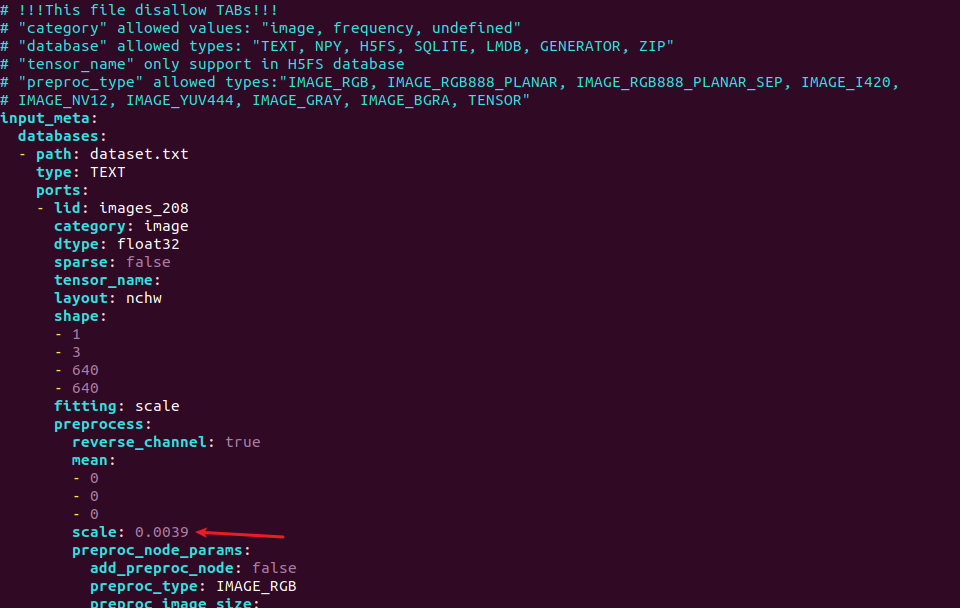
修改 yolov5s-sim_inputmeta.yml 文件中的的 scale 参数为 0.0039216(1/255),目的是对输入 tensor 进行归一化,和网络进行训练的时候是对应的。
vi yolov5s-sim_inputmeta.yml
3.4 量化
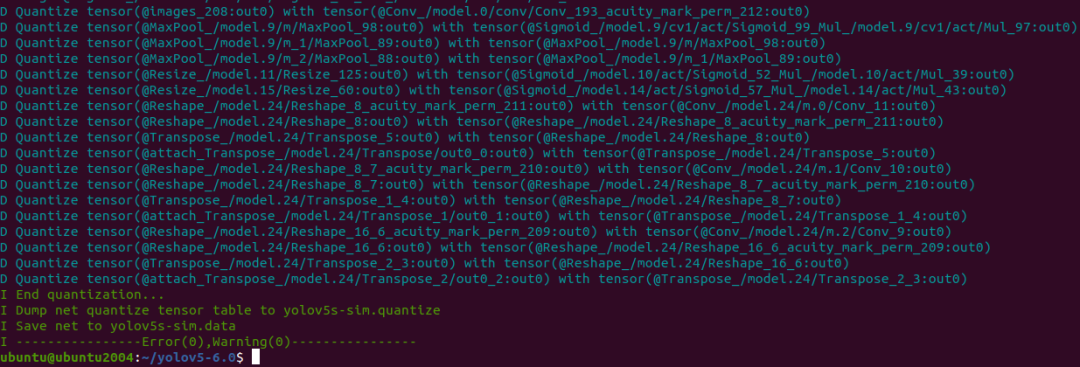
生成量化表文件,使用非对称量化,uint8,修改 --batch-size 参数为你的 dataset.txt 里提供的图片数量。
pegasus quantize --model yolov5s-sim.json --model-data yolov5s-sim.data --batch-size 1 --device CPU --with-input-meta yolov5s-sim_inputmeta.yml --rebuild --model-quantize yolov5s-sim.quantize --quantizer asymmetric_affine --qtype uint8
3.5 预推理
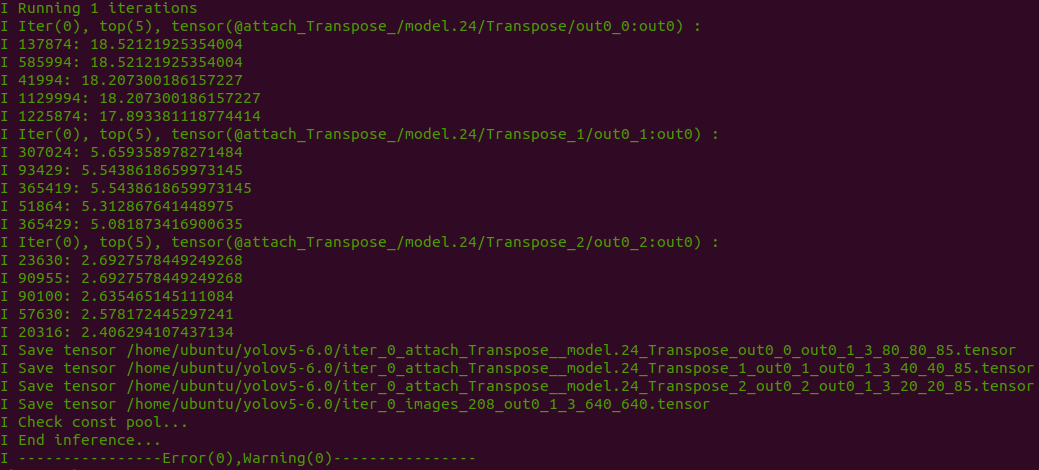
利用前文的量化表执行预推理,得到推理 tensor
pegasus inference --model yolov5s-sim.json --model-data yolov5s-sim.data --batch-size 1 --dtype quantized --model-quantize yolov5s-sim.quantize --device CPU --with-input-meta yolov5s-sim_inputmeta.yml --postprocess-file yolov5s-sim_postprocess_file.yml
3.6 导出模板代码与模型
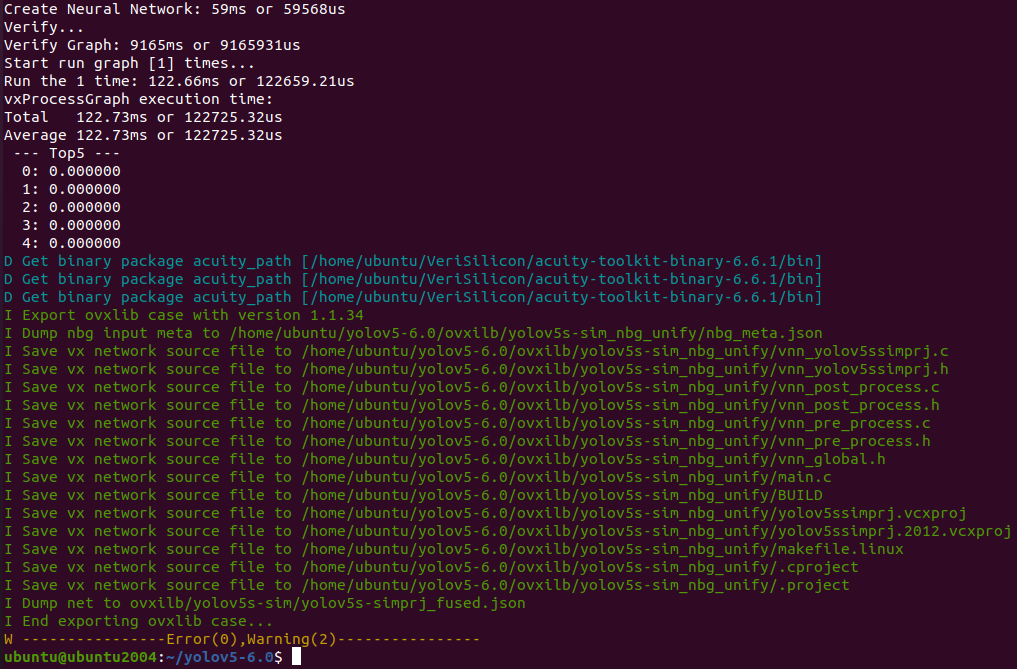
输出的模型可以在 ovxilb/yolov5s-sim_nbg_unify 文件夹中找到network_binary.nb文件。
pegasus export ovxlib --model yolov5s-sim.json --model-data yolov5s-sim.data --dtype quantized --model-quantize yolov5s-sim.quantize --batch-size 1 --save-fused-graph --target-ide-project 'linux64' --with-input-meta yolov5s-sim_inputmeta.yml --output-path ovxilb/yolov5s-sim/yolov5s-simprj --pack-nbg-unify --postprocess-file yolov5s-sim_postprocessmeta.yml --optimize "VIP9000PICO_PID0XEE" --viv-sdk ${VIV_SDK}
将生成的network_binary.nb文件拷贝出来备用。
4.YOLOV5端侧部署
4.1 配置yolov5端侧部署环境
在进行端侧部署前,由于后处理需要使用OpenCV库,所以请先按照如下步骤
-
配置NPU拓展包:https://forums.100ask.net/t/topic/3224
-
配置OpenCV库:https://forums.100ask.net/t/topic/3349
配置完成后才能编译端侧部署程序。
下载source压缩包中的yolov5.tar.gz,将该压缩包拷贝到虚拟机中,解压压缩包
tar -xzvf yolov5.tar.gz
将解压出来的文件夹拷贝到tina-v853-open/openwrt/package/npu/目录下
cp yolov5/ ~/workspaces/tina-v853-open/openwrt/package/npu/ -rf
注意:上面的~/workspaces/tina-v853-open/openwrt/package/npu/目录需要更换为您自己的SDK实际的目录。
拷贝完成后,如下所示:
book@100ask:~/workspaces/tina-v853-open/openwrt/package/npu$ ls lenet viplite-driver vpm_run yolov3 yolov5
4.2 编译端侧部署代码
配置编译环境
book@100ask:~/workspaces/tina-v853-open$ source build/envsetup.sh
...
book@100ask:~/workspaces/tina-v853-open$ lunch
You're building on Linux
Lunch menu... pick a combo:
1 v853-100ask-tina
2 v853-vision-tina
Which would you like? [Default v853-100ask]: 1
...
进入Tina配置界面
book@100ask:~/workspaces/tina-v853-open$ make menuconfig
进入如下目录,选中yolov5后即可编译端侧部署程序
> 100ask > NPU <*> yolov5....................................................... yolov5 demo <*> yolov5-model...................................... yolov5 test demo model
注意:yolov5-model该选择后会将yolov5_model.nb打包进镜像中,该模型文件会在/etc/models/目录下。
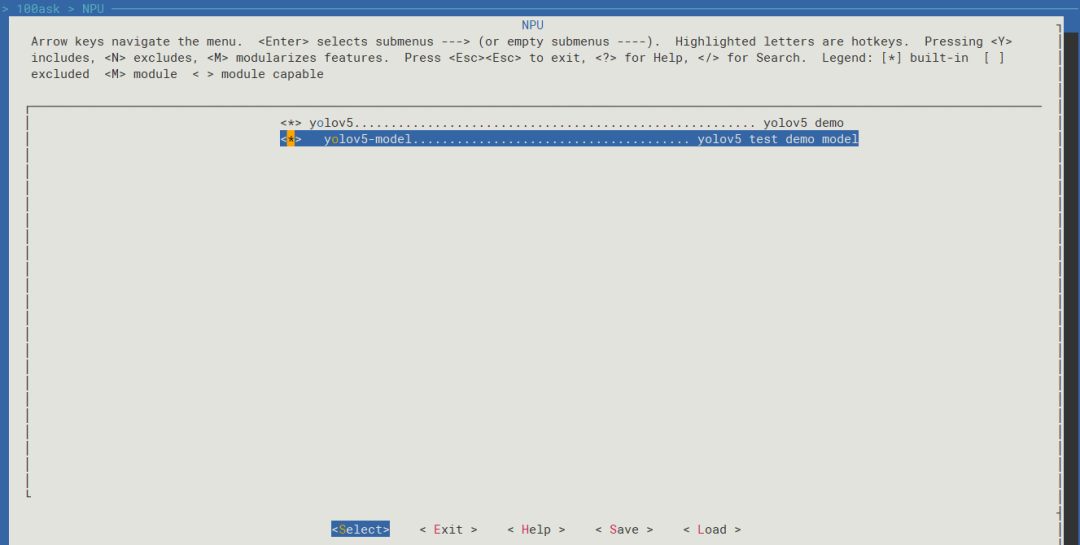
保存并退出Tina配置界面。
编译Tina SDK镜像,编译完成后打包生成镜像
book@100ask:~/workspaces/tina-v853-open$ make ... book@100ask:~/workspaces/tina-v853-open$ pack
注意:如果您将模型打包进镜像中,可能会出现文件系统大小设置值太小的问题们可以参考https://forums.100ask.net/t/topic/3158解决。
打包完成后,使用全志烧写工具进行烧写新镜像,如果您还不会烧写系统,请参考:https://forums.100ask.net/t/topic/3403
4.3 测试yolov5端侧部署
测试图像文件要求:
-
图片
-
尺寸:640*640
开发板端:
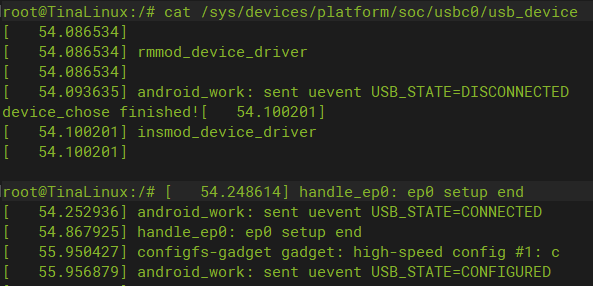
使用ADB将测试图片传输到开发板上,将USB0的模式切换到 Device 模式
cat /sys/devices/platform/soc/usbc0/usb_device
主机端:
将ADB设备连接上虚拟机,并将虚拟机中的测试图片传输到开发板中,查看ADB设备
book@100ask:~/workspaces/testImg$ adb devices List of devices attached 20080411device
查看需要传输的文件
book@100ask:~/workspaces/testImg$ ls bus_640-640.jpg bus_640-640.jpg
传输文件到开发板中
book@100ask:~/workspaces/testImg$ adb push bus_640-640.jpg /mnt/UDISK bus_640-640.jpg: 1 file pushed. 0.7 MB/s (97293 bytes in 0.128s)
开发板端:
进入测试图像目录
root@TinaLinux:/# cd /mnt/UDISK/ root@TinaLinux:/mnt/UDISK# ls bus_640-640.jpg lost+found overlay
yolov5程序参数要求:yolov5 <模型文件路径> <测试图像路径>
如果您打包了默认的yolov5模型文件,可以输入
yolov5 /etc/models/yolov5_model.nb ./bus_640-640.jpg
如果您需要选择自己的模型文件进行测试,可以将上面的/etc/models/yolov5_model.nb更换为自己的模型路径,下面我以默认的模型文件进行测试。
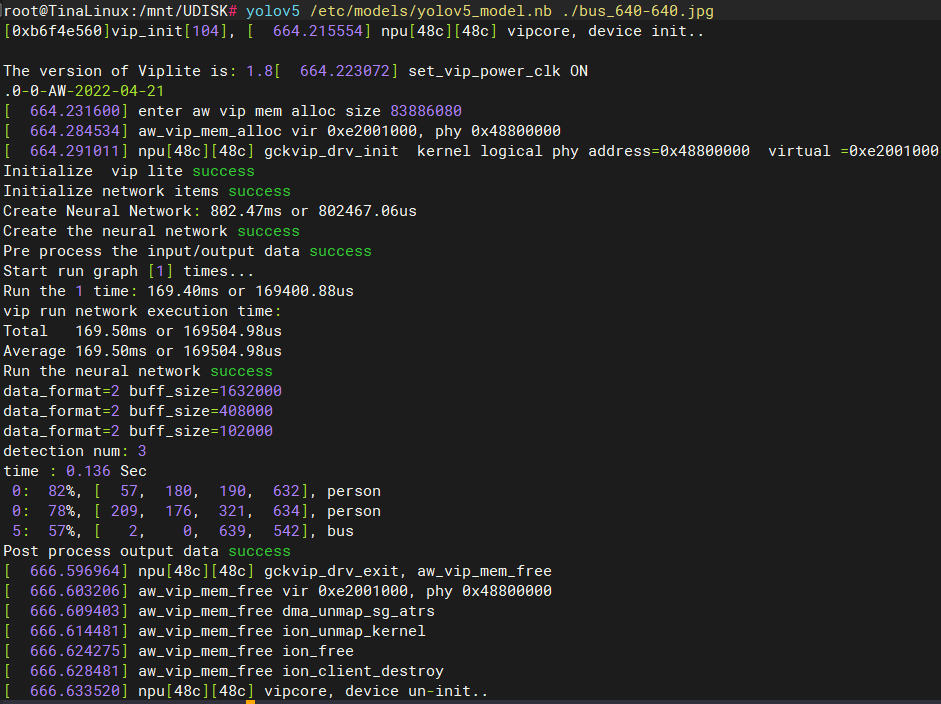
查看输出图像文件yolov5_out.jpg
root@TinaLinux:/mnt/UDISK# ls bus_640-640.jpg lost+found overlay yolov5_out.jpg
主机端:
拉取输出文件yolov5_out.jpg到当前文件夹下
book@100ask:~/workspaces/testImg$ adb pull /mnt/UDISK/yolov5_out.jpg ./ /mnt/UDISK/yolov5_out.jpg: 1 file pulled. 0.9 MB/s (184894 bytes in 0.202s)

-
 jf_47987487
2024-04-30
0 回复 举报source在哪里呢 收起回复
jf_47987487
2024-04-30
0 回复 举报source在哪里呢 收起回复
-
 WWIWWI
2023-09-01
1 回复 举报配置完OpenCV库后,下在source,source在哪里啊哥?? 收起回复
WWIWWI
2023-09-01
1 回复 举报配置完OpenCV库后,下在source,source在哪里啊哥?? 收起回复
-
全志V853开发板原理图2024-01-12 5623
-
全志V853开发板双目摄像头模组原理图202206242022-10-19 1429
-
【全志V853开发板试用】全志V853开发板试用测评报告2022-08-29 4567
-
每日推荐 | 全志V853开发板试用连载,RISC-V中国峰会2022-08-22 6293
-
全志V853开发板试用之一(Tina Linux 5.0编译 和NPU使用)2022-08-21 11505
-
小成本的V853 AI小开发板DIY设计2022-08-10 4002
-
【免费试用】全新Tina Linux v5.0释放,价值1799元V853开发板等你来拿!2022-07-24 3047
-
全志V853开发板参数规格概述2022-07-22 7607
-
【免费试用04期】全志V853开发板试用活动2022-07-21 26503
-
全志V853开发板的主要部件及其原理图2022-07-10 4809
-
带大家来一次全志V853开发板沉浸式开箱!2022-07-04 2206
-
全志V853开发板发布!开发板试用同步开放申请!2022-07-01 3618
全部0条评论

快来发表一下你的评论吧 !
